NumPy - 指数分布
NumPy 中的指数分布
指数分布是一种连续概率分布,用于对以恒定平均速率发生的独立事件之间的时间进行建模。
它由一个参数 (lambda) 定义,该参数为速率参数,其中事件之间的平均时间为 1/。这种分布通常用于诸如队列中到达间隔时间之类的场景。
例如,如果事件平均每 5 分钟发生一次(=1/5),则指数分布可以对这些事件之间的间隔时间进行建模。
指数分布的概率密度函数 (PDF) 定义为 −
f(x; ) = * exp(-x),当 x 为 0 时,否则为 0
其中,
- : 速率参数(平均值的倒数)。
- x: 事件间隔时间。
- exp: 指数函数。
NumPy 中的指数分布
NumPy 提供了numpy.random.exponential() 函数从指数分布生成样本。您可以指定比例参数 (1/) 和生成样本的大小。
示例
在此示例中,我们从速率参数 =2(scale=0.5)的指数分布中生成 10 个随机样本 -
import numpy as np
# 从比例参数 =2(scale=0.5)的指数分布中生成 10 个随机样本
samples = np.random.exponential(scale=0.5, size=10)
print("指数分布的随机样本:", sample)
以下是获得的输出 -
指数分布的随机样本:[0.49251018 0.14301367 0.48682864 0.09396999 0.11923932 0.28674142 0.14285472 0.11916798 1.59846326 0.27175065]
可视化指数分布
可视化指数分布有助于更好地理解其特性。我们可以使用 Matplotlib 等库来创建直方图,以显示生成样本的分布。
示例
在下面的示例中,我们首先从指数分布中生成 1000 个随机样本,样本量为 =2(尺度为 0.5)。然后我们创建一个直方图来可视化此分布 -
import numpy as np
import matplotlib.pyplot as plt
# 从指数分布中生成 1000 个随机样本,样本数 =2(scale=0.5)
samples = np.random.exponential(scale=0.5, size=1000)
# 创建一个直方图来可视化此分布
plt.hist(samples, bins=30, edgecolor='black', density=True)
plt.title('指数分布')
plt.xlabel('事件间隔时间')
plt.ylabel('频率')
plt.show()
直方图显示了指数试验中事件间隔时间的频率。条形表示每种可能结果的概率,构成指数分布的特征形状 -
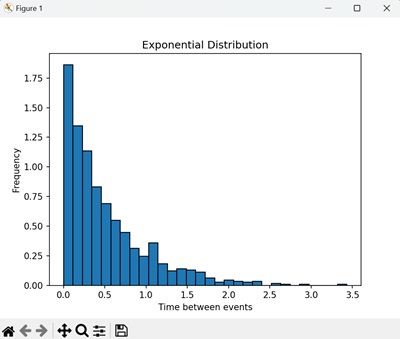
指数分布的应用
指数分布在各个领域都有应用,用于模拟泊松过程中事件之间的时间。以下是一些实际应用 -
- 可靠性分析: 对机械系统故障间隔时间进行建模。
- 排队论: 对排队中顾客到达的间隔时间进行建模。
- 生存分析: 对事件(例如死亡或故障)发生之前的时间进行建模。
生成累积指数分布
有时,我们对指数分布的累积分布函数 (CDF) 感兴趣,它给出了区间内发生最多 x 个事件(包括 x 个事件)的概率。
NumPy 没有内置的指数分布 CDF 函数,但我们可以使用循环和 SciPy 库中的 scipy.stats.expon.cdf() 函数来计算它。库。
示例
以下是在 NumPy 中生成累积指数分布的示例 -
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import expon
# 定义速率参数
lam = 2
# 生成累积分布函数 (CDF) 值
x = np.linspace(0, 3, 100)
cdf = expon.cdf(x, scale=1/lam)
# 绘制 CDF 值
plt.plot(x, cdf, marker='o', linestyle='-', color='b')
plt.title('累积指数分布')
plt.xlabel('事件间隔时间')
plt.ylabel('累积概率')
plt.grid(True)
plt.show()
该图显示了指数试验中每次事件间隔时间的累积概率。 CDF 是一条平滑曲线,随着事件间隔时间的增加而增加到 1。-
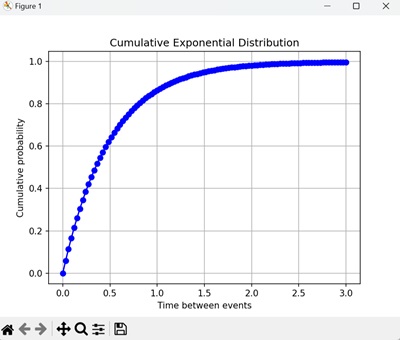
指数分布的性质
指数分布有几个关键性质,它们是:-
- 无记忆性:事件在未来发生的概率与已经过去的时间无关。
- 均值和方差:指数分布的均值为 1/,方差为 1/2。
- 偏度:分布向右偏斜,尾部较长。
假设的指数分布测试
指数分布常用于假设检验,尤其是在事件间隔时间的检验中。
一种常见的检验方法是指数检验,用于确定事件间隔的观测时间是否与预期时间存在显著差异。以下是使用 scipy.stats.expon() 函数的示例:
示例
在此示例中,我们执行指数检验来确定事件间隔的观测时间 (0.8) 是否与预期速率 (=2) 存在显著差异。 p值表示假设零假设成立,获得至少与观察结果同样极端的结果的概率 -
from scipy.stats import expon
# 观察事件间隔时间
observed_time = 0.8
# 预期速率参数 ()
expected_rate = 2
# 执行指数检验
p_value = expon.sf(observed_time, scale=1/expected_rate)
print("指数检验的P值:", p_value)
得到的输出如下所示 -
指数检验的P值:0.20189651799465538
重复性播种
为确保可重复性,您可以在生成指数分布之前设置特定的种子。这样可以确保每次运行代码时都会生成相同的随机数序列。
示例
通过设置种子,可以确保每次执行代码时随机生成的结果都相同,如下例所示 -
import numpy as np
# 设置种子以确保可重复性
np.random.seed(42)
# 从指数分布中生成 10 个随机样本,其中 2 个样本的 scale 为 0.5
samples = np.random.exponential(scale=0.5, size=10)
print("种子为 42 的随机样本:", sample)
生成的结果如下 -
种子为 42 的随机样本:[0.23463404 1.50506072 0.65837285 0.45647128 0.08481244 0.08479815 0.02991938 1.00561543 0.45954108 0.61562503]

