SciPy - 快速指南
SciPy - 简介
SciPy,发音为 Sigh Pi,是一个科学的 Python 开源库,在 BSD 许可库下分发,用于执行数学、科学和工程计算。
SciPy 库依赖于 NumPy,它提供方便快捷的 N 维数组操作。SciPy 库专为与 NumPy 数组配合使用而构建,并提供许多用户友好且高效的数值实践,例如数值积分和优化例程。它们一起运行在所有流行的操作系统上,安装快捷,并且免费。NumPy 和 SciPy 易于使用,但功能强大,足以让一些世界领先的科学家和工程师信赖。
SciPy 子包
SciPy 分为涵盖不同科学计算领域的子包。这些总结在下表中 −
| scipy.cluster | 矢量量化/Kmeans |
| scipy.constants | 物理和数学常数 |
| scipy.fftpack | 傅里叶变换 |
| scipy.integrate | 积分例程 |
| scipy.interpolate | 插值 |
| scipy.io | 数据输入和输出 |
| scipy.linalg | 线性代数例程 |
| scipy.ndimage | n 维图像包 |
| scipy.odr | 正交距离回归 |
| scipy.optimize | 优化 |
| scipy.signal | 信号处理 |
| scipy.sparse | 稀疏矩阵 |
| scipy.spatial | 空间数据结构和算法 |
| scipy.special | 任何特殊的数学函数 |
| scipy.stats | 统计数据 |
数据结构
SciPy 使用的基本数据结构是 NumPy 模块提供的多维数组。NumPy 提供了一些用于线性代数、傅里叶变换和随机数生成的函数,但不具备 SciPy 中等效函数的通用性。
SciPy - 环境设置
标准 Python 发行版不附带任何 SciPy 模块。一种轻量级的替代方法是使用流行的 Python 包安装程序安装 SciPy,
pip install pandas
如果我们安装 Anaconda Python 包,Pandas 将默认安装。以下是包和在不同操作系统中安装它们的链接。
Windows
Anaconda(来自 https://www.continuum.io)是 SciPy 堆栈的免费 Python 发行版。它也适用于 Linux 和 Mac。
Canopy (https://www.enthought.com/products/canopy/) 可免费使用,也可以用于商业发行,其中包含适用于 Windows、Linux 和 Mac 的完整 SciPy 堆栈。
Python (x,y) − 它是一个免费的 Python 发行版,带有适用于 Windows 操作系统的 SciPy 堆栈和 Spyder IDE。 (可从 https://python-xy.github.io/ 下载)
Linux
各个 Linux 发行版的包管理器用于在 SciPy 堆栈中安装一个或多个包。
Ubuntu
我们可以使用以下路径在 Ubuntu 中安装 Python。
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipython-notebook python-pandas python-sympy python-nose
Fedora
我们可以使用以下路径在 Fedora 中安装 Python。
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy python-nose atlas-devel
SciPy - 基本功能
默认情况下,所有 NumPy 函数都可通过 SciPy 命名空间使用。导入 SciPy 时,无需明确导入 NumPy 函数。NumPy 的主要对象是同质多维数组。它是一个元素表(通常是数字),所有元素均为同一类型,由正整数元组索引。在 NumPy 中,维度称为轴。轴的数量称为等级。
现在,让我们回顾一下 NumPy 中向量和矩阵的基本功能。由于 SciPy 建立在 NumPy 数组之上,因此了解 NumPy 基础知识是必要的。由于线性代数的大部分内容只处理矩阵。
NumPy 向量
向量可以通过多种方式创建。下面介绍其中一些方法。
将 Python 数组类对象转换为 NumPy
让我们考虑以下示例。
import numpy as np list = [1,2,3,4] arr = np.array(list) print arr
上述程序的输出如下。
[1 2 3 4]
内在 NumPy 数组创建
NumPy 具有用于从头开始创建数组的内置函数。下面将解释其中一些函数。
使用 zeros()
zeros(shape) 函数将创建一个具有指定形状的数组,其中填充了 0 个值。默认 dtype 为 float64。让我们考虑以下示例。
import numpy as np print np.zeros((2, 3))
上述程序的输出如下。
array([[ 0., 0., 0.], [ 0., 0., 0.]])
使用ones()
ones(shape)函数将创建一个填充1值的数组。它在所有其他方面与零相同。让我们考虑以下示例。
import numpy as np print np.ones((2, 3))
上述程序的输出将如下所示。
array([[ 1., 1., 1.], [ 1., 1., 1.]])
使用 arange()
arange() 函数将创建具有定期递增值的数组。让我们考虑以下示例。
import numpy as np print np.arange(7)
上述程序将生成以下输出。
array([0, 1, 2, 3, 4, 5, 6])
定义值的数据类型
让我们考虑以下示例。
import numpy as np arr = np.arange(2, 10, dtype = np.float) print arr print "Array Data Type :",arr.dtype
上述程序将生成以下输出。
[ 2. 3. 4. 5. 6. 7. 8. 9.] Array Data Type : float64
使用linspace()
linspace() 函数将创建具有指定数量元素的数组,这些元素将在指定的起始值和结束值之间等距分布。让我们考虑以下示例。
import numpy as np print np.linspace(1., 4., 6)
上述程序将生成以下输出。
array([ 1. , 1.6, 2.2, 2.8, 3.4, 4. ])
矩阵
矩阵是一种特殊的二维数组,通过运算保留其二维性质。它具有某些特殊运算符,例如 *(矩阵乘法)和 **(矩阵幂)。让我们考虑以下示例。
import numpy as np
print np.matrix('1 2; 3 4')
上述程序将生成以下输出。
matrix([[1, 2], [3, 4]])
矩阵的共轭转置
此功能返回自身的(复数)共轭转置。让我们考虑以下示例。
import numpy as np
mat = np.matrix('1 2; 3 4')
print mat.H
上述程序将生成以下输出。
matrix([[1, 3], [2, 4]])
矩阵转置
此功能返回自身的转置。让我们考虑以下示例。
import numpy as np
mat = np.matrix('1 2; 3 4')
mat.T
上述程序将生成以下输出。
matrix([[1, 3],
[2, 4]])
当我们转置矩阵时,我们会创建一个新矩阵,其行是原始矩阵的列。另一方面,共轭转置会交换每个矩阵元素的行和列索引。矩阵的逆矩阵是如果与原始矩阵相乘,则得到单位矩阵的矩阵。
SciPy - 聚类
K 均值聚类是一种在一组未标记数据中查找聚类和聚类中心的方法。直观地讲,我们可以将聚类视为 - 由一组数据点组成,这些数据点之间的距离与聚类外部点之间的距离相比较小。给定一组初始的 K 个中心,K 均值算法将迭代以下两个步骤 −
对于每个中心,将识别出距离它最近的训练点子集(其聚类)。
计算每个聚类中数据点的每个特征的平均值,该均值向量将成为该聚类的新中心。
迭代这两个步骤,直到中心不再移动或分配不再改变。然后,可以将新点 x 分配给最近原型的聚类。SciPy 库通过 cluster 包提供了 K-Means 算法的良好实现。让我们了解如何使用它。
SciPy 中的 K-Means 实现
我们将了解如何在 SciPy 中实现 K-Means。
导入 K-Means
我们将看到每个导入函数的实现和用法。
from SciPy.cluster.vq import kmeans,vq,whiten
数据生成
我们必须模拟一些数据来探索聚类。
from numpy import vstack,array from numpy.random import rand # 具有三个特征的数据生成 data = vstack((rand(100,3) + array([.5,.5,.5]),rand(100,3)))
现在,我们必须检查数据。上述程序将生成以下输出。
array([[ 1.48598868e+00, 8.17445796e-01, 1.00834051e+00],
[ 8.45299768e-01, 1.35450732e+00, 8.66323621e-01],
[ 1.27725864e+00, 1.00622682e+00, 8.43735610e-01],
…………….
按每个特征对一组观测值进行归一化。在运行 K-Means 之前,最好使用白化重新调整观测集的每个特征维度。每个特征除以其在所有观测值中的标准差,以赋予其单位方差。
对数据进行白化
我们必须使用以下代码对数据进行白化。
# 数据白化 data = whiten(data)
使用三个聚类计算 K-Means
现在让我们使用以下代码使用三个聚类计算 K-Means。
# 使用 K = 3(2 个聚类)计算 K-Means centroids,_ = kmeans(data,3)
上述代码对形成 K 个聚类的一组观测向量执行 K-Means。 K-Means 算法会调整质心,直到无法取得足够的进展,即失真的变化,因为最后一次迭代小于某个阈值。在这里,我们可以通过使用下面给出的代码打印质心变量来观察集群的质心。
print(centroids)
上述代码将生成以下输出。
print(centroids)[ [ 2.26034702 1.43924335 1.3697022 ]
[ 2.63788572 2.81446462 2.85163854]
[ 0.73507256 1.30801855 1.44477558] ]
使用下面给出的代码将每个值分配给一个集群。
# 将每个样本分配给一个集群 clx,_ = vq(data,centroids)
vq 函数将"M"乘"N"obs 数组中的每个观测向量与质心进行比较,并将观测分配给最近的集群。它返回每个观测的集群和失真。我们也可以检查失真。让我们使用以下代码检查每个观测的集群。
# 检查观测集群 print clx
上述代码将生成以下输出。
array([1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 2, 0, 2, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 1, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2], dtype=int32)
上述数组的不同值 0、1、2 表示聚类。
SciPy - 常量
SciPy 常量包提供了广泛的常量,可用于一般科学领域。
SciPy 常量包
scipy.constants 包提供了各种常量。我们必须导入所需的常量并根据要求使用它们。让我们看看如何导入和使用这些常量变量。
首先,让我们通过以下示例比较"pi"值。
#从两个包导入 pi 常量
from scipy.constants import pi
from math import pi
print("sciPy - pi = %.16f"%scipy.constants.pi)
print("math - pi = %.16f"%math.pi)
上述程序将生成以下输出。
sciPy - pi = 3.1415926535897931 math - pi = 3.1415926535897931
常量列表可用
下表简要描述了各种常数。
数学常数
| 序号 | 常数 | 描述 |
|---|---|---|
| 1 | pi | pi |
| 2 | golden | Golden Ratio |
物理常数
下表列出了最常用的物理常数。
| 序号 | 常数 &描述 |
|---|---|
| 1 | c 真空中的光速 |
| 2 | speed_of_light 真空中的光速 |
| 3 | h 普朗克常数 |
| 4 | Planck 普朗克常数 h |
| 5 | G 牛顿引力常数 |
| 6 | e 基本电荷 |
| 7 | R 摩尔气体常数 |
| 8 | Avogadro 阿伏伽德罗常数 |
| 9 | k 玻尔兹曼常数 |
| 10 | electron_mass(OR) m_e 电子质量 |
| 11 | proton_mass (OR) m_p 质子质量 |
| 12 | neutron_mass(OR)m_n 中子质量 |
单位
下表列出了 SI 单位。
| 序号 | 单位 | 值 |
|---|---|---|
| 1 | milli | 0.001 |
| 2 | micro | 1e-06 |
| 3 | kilo | 1000 |
这些单位范围从尧、泽、艾、拍、太……千、赫……纳、皮……到泽普托。
其他重要常量
下表列出了 SciPy 中使用的其他重要常量。
| Sr.编号 | 单位 | 值 |
|---|---|---|
| 1 | gram | 0.001 千克 |
| 2 | atomic mass | 原子质量常数 |
| 3 | degree | 弧度 |
| 4 | minute | 一分钟等于几秒 |
| 5 | day | 一天等于几秒秒 |
| 6 | inch | 一英寸等于多少米 |
| 7 | micron | 一微米等于多少米 |
| 8 | light_year | 一光年等于多少米 |
| 9 | atm | 标准大气压等于多少帕斯卡 |
| 10 | acre | 一英亩等于多少平方米 |
| 11 | liter | 一升等于立方米 |
| 12 | gallon | 一加仑换算成立方米 |
| 13 | kmh | 公里每小时换算成米每秒 |
| 14 | degree_Fahrenheit | 一华氏度换算成开尔文 |
| 15 | eV | 一电子伏特换算成焦耳 |
| 16 | hp | 一马力换算成瓦特 |
| 17 | dyn | 1 达因(牛顿) |
| 18 | lambda2nu | 将波长转换为光频率 |
记住所有这些有点难。获取哪个键对应哪个函数的简单方法是使用 scipy.constants.find() 方法。让我们考虑以下示例。
import scipy.constants res = scipy.constants.physical_constants["alphaarticle mass"] print res
上述程序将生成以下输出。
[ 'alpha particle mass', 'alpha particle mass energy equivalent', 'alpha particle mass energy equivalent in MeV', 'alpha particle mass in u', 'electron to alpha particle mass ratio' ]
此方法返回键列表,如果关键字不匹配,则不返回任何内容。
SciPy - FFTpack
傅里叶变换是在时域信号上计算的,以检查其在频域中的行为。傅里叶变换在信号和噪声处理、图像处理、音频信号处理等学科中得到应用。SciPy 提供 fftpack 模块,让用户计算快速傅里叶变换。
以下是正弦函数的示例,它将用于使用 fftpack 模块计算傅里叶变换。
快速傅里叶变换
让我们详细了解快速傅里叶变换是什么。
一维离散傅里叶变换
长度为 N 的序列 x[n] 的长度为 N 的 FFT y[k] 由 fft() 计算,逆变换由 ifft() 计算。让我们考虑以下示例
#从 fftpackage 导入 fft 和逆 fft 函数 from scipy.fftpack import fft #创建一个包含随机 n 个数字的数组 x = np.array([1.0, 2.0, 1.0, -1.0, 1.5]) #应用 fft 函数 y = fft(x) print y
上述程序将生成以下输出。
[ 4.50000000+0.j 2.08155948-1.65109876j -1.83155948+1.60822041j -1.83155948-1.60822041j 2.08155948+1.65109876j ]
让我们看另一个例子
#FFT 已经在工作区中,使用相同的工作区进行逆变换 yinv = ifft(y) print yinv
上述程序将生成以下输出。
[ 1.0+0.j 2.0+0.j 1.0+0.j -1.0+0.j 1.5+0.j ]
scipy.fftpack 模块允许计算快速傅里叶变换。举例来说,(嘈杂的)输入信号可能如下所示 −
import numpy as np time_step = 0.02 period = 5. time_vec = np.arange(0, 20, time_step) sig = np.sin(2 * np.pi / period * time_vec) + 0.5 *np.random.randn(time_vec.size) print sig.size
我们正在创建一个时间步长为 0.02 秒的信号。最后一条语句打印信号 sig 的大小。输出结果如下 −
1000
我们不知道信号频率;我们只知道信号 sig 的采样时间步长。信号应该来自实函数,因此傅里叶变换将是对称的。 scipy.fftpack.fftfreq() 函数将生成采样频率,scipy.fftpack.fft() 将计算快速傅里叶变换。
让我们借助一个例子来理解这一点。
from scipy import fftpack sample_freq = fftpack.fftfreq(sig.size, d = time_step) sig_fft = fftpack.fft(sig) print sig_fft
上述程序将生成以下输出。
array([ 25.45122234 +0.00000000e+00j, 6.29800973 +2.20269471e+00j, 11.52137858 -2.00515732e+01j, 1.08111300 +1.35488579e+01j, …….])
离散余弦变换
离散余弦变换 (DCT) 用以不同频率振荡的余弦函数之和来表示有限数据点序列。SciPy 提供具有函数 dct 的 DCT 和具有函数 idct 的相应 IDCT。让我们考虑以下示例。
from scipy.fftpack import dct print dct(np.array([4., 3., 5., 10., 5., 3.]))
上述程序将生成以下输出。
array([ 60., -3.48476592, -13.85640646, 11.3137085, 6., -6.31319305])
逆离散余弦变换从其离散余弦变换 (DCT) 系数重建一个序列。idct 函数是 dct 函数的逆。让我们通过以下示例来理解这一点。
from scipy.fftpack import dct print idct(np.array([4., 3., 5., 10., 5., 3.]))
上述程序将生成以下输出。
array([ 39.15085889, -20.14213562, -6.45392043, 7.13341236, 8.14213562, -3.83035081])
SciPy - 积分
当一个函数无法解析积分,或者解析积分非常困难时,通常会求助于数值积分方法。SciPy 有许多用于执行数值积分的例程。它们中的大多数都可以在同一个 scipy.integrate 库中找到。下表列出了一些常用函数。
| Sr No. | 函数 &描述 |
|---|---|
| 1 | quad 单次积分 |
| 2 | dblquad 两次积分 |
| 3 | tplquad 三次积分 |
| 4 | nquad n倍多次积分 |
| 5 | fixed_quad 高斯求积,n 阶 |
| 6 | quadrature 高斯求积至公差 |
| 7 | romberg Romberg 积分 |
| 8 | trapz 梯形法则 |
| 9 | cumtrapz 梯形法则用于累积计算积分 |
| 10 | simps Simpson 法则 |
| 11 | romb Romberg积分 |
| 12 | polyint 解析多项式积分 (NumPy) |
| 13 | poly1d polyint 的辅助函数 (NumPy) |
单积分
Quad 函数是 SciPy 积分函数中的主力。数值积分有时也称为求积,因此得名。它通常是对函数 f(x) 在给定的从 a 到 b 的固定范围内进行单次积分的默认选择。
$$\int_{a}^{b} f(x)dx$$
quad 的一般形式是 scipy.integrate.quad(f, a, b),其中"f"是要积分的函数的名称。而"a"和"b"分别是下限和上限。让我们看一个在 0 和 1 范围内积分的高斯函数的例子。
我们首先需要定义函数 → $f(x) = e^{-x^2}$ ,这可以使用 lambda 表达式来完成,然后在该函数上调用 quad 方法。
import scipy.integrate from numpy import exp f= lambda x:exp(-x**2) i = scipy.integrate.quad(f, 0, 1) print i
上述程序将生成以下输出。
(0.7468241328124271, 8.291413475940725e-15)
quad 函数返回两个值,其中第一个数字是积分的值,第二个值是积分值的绝对误差的估计值。
注意 − 由于 quad 需要函数作为第一个参数,因此我们不能直接传递 exp 作为参数。Quad 函数接受正无穷和负无穷作为极限。 Quad 函数可以对单个变量的标准预定义 NumPy 函数进行积分,例如 exp、sin 和 cos。
多重积分
双重和三重积分的机制已包含在函数 dblquad、tplquad 和 nquad 中。这些函数分别对四个或六个参数进行积分。所有内部积分的极限都需要定义为函数。
双重积分
dblquad 的一般形式是 scipy.integrate.dblquad(func, a, b, gfun, hfun)。其中,func 是需要积分的函数的名称,"a"和"b"分别是 x 变量的下限和上限,而 gfun 和 hfun 是定义 y 变量下限和上限的函数的名称。
作为示例,让我们执行双重积分方法。
$$\int_{0}^{1/2} dy \int_{0}^{\sqrt{1-4y^2}} 16xy \:dx$$
我们使用 lambda 表达式定义函数 f、g 和 h。请注意,即使 g 和 h 是常量(在许多情况下可能如此),也必须将它们定义为函数,就像我们在此处对下限所做的那样。
import scipy.integrate from numpy import exp from math import sqrt f = lambda x, y : 16*x*y g = lambda x : 0 h = lambda y : sqrt(1-4*y**2) i = scipy.integrate.dblquad(f, 0, 0.5, g, h) print i
上述程序将生成以下输出。
(0.5, 1.7092350012594845e-14)
除了上面描述的例程之外,scipy.integrate 还有一个许多其他积分例程,包括执行 n 倍多重积分的 nquad,以及实现各种积分算法的其他例程。但是,quad 和 dblquad 可以满足我们对数值积分的大部分需求。
SciPy - 插值
在本章中,我们将讨论插值在 SciPy 中的用途。
什么是插值?
插值是在一条直线或曲线上的两点之间寻找值的过程。为了帮助我们记住它的含义,我们应该将单词的第一部分"inter"理解为"输入",这提醒我们要查看我们最初拥有的数据的"内部"。插值这一工具不仅在统计学中很有用,在科学、商业或需要预测两个现有数据点之间的值时也很有用。
让我们创建一些数据,看看如何使用 scipy.interpolate 包进行插值。
import numpy as np from scipy import interpolate import matplotlib.pyplot as plt x = np.linspace(0, 4, 12) y = np.cos(x**2/3+4) print x,y
上述程序将生成以下输出。
(
array([0., 0.36363636, 0.72727273, 1.09090909, 1.45454545, 1.81818182,
2.18181818, 2.54545455, 2.90909091, 3.27272727, 3.63636364, 4.]),
array([-0.65364362, -0.61966189, -0.51077021, -0.31047698, -0.00715476,
0.37976236, 0.76715099, 0.99239518, 0.85886263, 0.27994201,
-0.52586509, -0.99582185])
)
现在,我们有两个数组。假设这两个数组是空间中点的两个维度,让我们使用以下程序进行绘图并查看它们的样子。
plt.plot(x, y,'o') plt.show()
上述程序将生成以下输出。
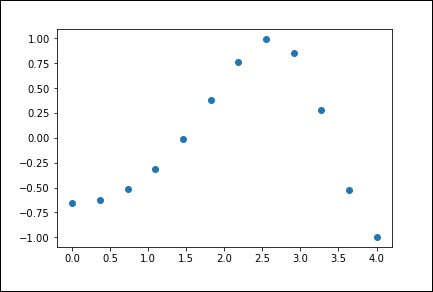
1-D 插值
scipy.interpolate 中的 interp1d 类是一种基于固定数据点创建函数的便捷方法,可以使用线性插值在给定数据定义的域内的任何位置对其进行评估。
通过使用上述数据,让我们创建一个插值函数并绘制一个新的插值图。
f1 = interp1d(x, y,kind = 'linear') f2 = interp1d(x, y, kind = 'cubic')
使用 interp1d 函数,我们创建了两个函数 f1 和 f2。对于给定的输入 x,这两个函数返回 y。第三个变量 kind 表示插值技术的类型。'Linear'、'Nearest'、'Zero'、'Slinear'、'Quadratic'、'Cubic' 是几种插值技术。
现在,让我们创建一个更长的新输入,以查看插值的明显差异。我们将对新数据使用与旧数据相同的函数。
xnew = np.linspace(0, 4,30) plt.plot(x, y, 'o', xnew, f(xnew), '-', xnew, f2(xnew), '--') plt.legend(['data', 'linear', 'cubic','nearest'], loc = 'best') plt.show()
上述程序将生成以下输出。
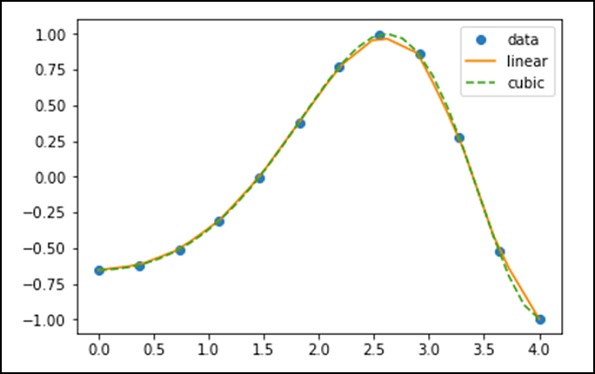
样条线
为了通过数据点绘制平滑曲线,绘图员曾经使用薄的柔性木条、硬橡胶、金属或塑料条(称为机械样条线)。要使用机械样条线,需要在设计中沿曲线合理选择的点上放置销钉,然后弯曲样条线,使其接触到每个销钉。
显然,通过这种构造,样条线会在这些销钉处插入曲线。它可用于在其他绘图中重现曲线。销钉所在的点称为结点。我们可以通过调整结点的位置来改变样条线定义的曲线的形状。
单变量样条线
一维平滑样条线拟合给定的一组数据点。scipy.interpolate 中的 UnivariateSpline 类是一种方便的方法,用于基于固定数据点类创建函数 - scipy.interpolate.UnivariateSpline(x, y, w = None, bbox = [None, None], k = 3, s = None, ext = 0, check_finite = False)。
参数 − 以下是单变量样条线的参数。
这将 k 度样条线 y = spl(x) 拟合到提供的 x、y 数据。
'w' −指定样条拟合的权重。必须为正数。如果没有(默认),则权重全部相等。
's' − 通过指定平滑条件来指定结点数。
'k' − 平滑样条的次数。必须为 <= 5。默认值为 k = 3,即三次样条。
Ext −控制不在结点序列定义的间隔内的元素的外推模式。
如果 ext = 0 或"extrapolate",则返回外推值。
如果 ext = 1 或"zero",则返回 0
如果 ext = 2 或"raise",则引发 ValueError
如果 ext = 3 或"const",则返回边界值。
check_finite – 是否检查输入数组是否仅包含有限数字。
让我们考虑以下示例。
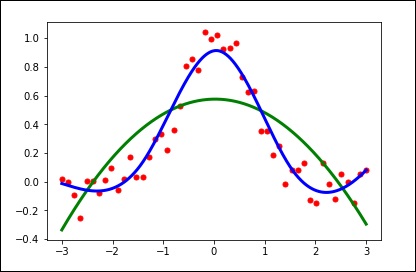
import matplotlib.pyplot as plt from scipy.interpolate import UnivariateSpline x = np.linspace(-3, 3, 50) y = np.exp(-x**2) + 0.1 * np.random.randn(50) plt.plot(x, y, 'ro', ms = 5) plt.show()
使用平滑参数的默认值。
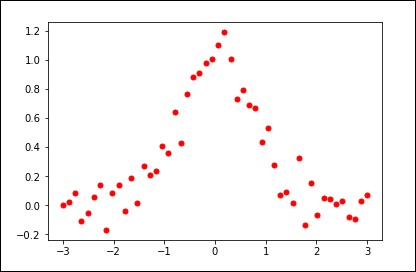
spl = UnivariateSpline(x, y) xs = np.linspace(-3, 3, 1000) plt.plot(xs, spl(xs), 'g', lw = 3) plt.show()
手动更改平滑量。
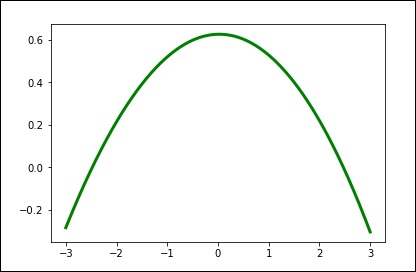
spl.set_smoothing_factor(0.5) plt.plot(xs, spl(xs), 'b', lw = 3) plt.show()
SciPy - 输入和输出
Scipy.io(输入和输出)包提供了广泛的函数来处理不同格式的文件。其中一些格式是 −
- Matlab
- IDL
- Matrix Market
- Wave
- Arff
- Netcdf 等
让我们详细讨论最常用的文件格式 −
MATLAB
以下是用于加载和保存 .mat 文件的函数。
| Sr.编号 | 函数与说明 |
|---|---|
| 1 | loadmat 加载 MATLAB 文件 |
| 2 | savemat 保存 MATLAB 文件 |
| 3 | whosmat 列出 MATLAB 文件中的变量 |
让我们考虑以下示例。
import scipy.io as sio
import numpy as np
#保存 mat 文件
vect = np.arange(10)
sio.savemat('array.mat', {'vect':vect})
#现在加载文件
mat_file_content = sio.loadmat('array.mat')
打印 mat_file_content
上述程序将生成以下输出。
{
'vect': array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]), '__version__': '1.0',
'__header__': 'MATLAB 5.0 MAT-file Platform: posix, Created on: Sat Sep 30
09:49:32 2017', '__globals__': []
}
我们可以看到数组以及元信息。如果我们想检查 MATLAB 文件的内容而不将数据读入内存,请使用 whosmat 命令,如下所示。
import scipy.io as sio
mat_file_content = sio.whosmat('array.mat')
print mat_file_content
上述程序将生成以下输出。
[('vect', (1, 10), 'int64')]
SciPy - Linalg
SciPy 是使用优化的 ATLAS LAPACK 和 BLAS 库构建的。它具有非常快速的线性代数功能。所有这些线性代数例程都需要一个可以转换为二维数组的对象。这些例程的输出也是一个二维数组。
SciPy.linalg 与 NumPy.linalg
scipy.linalg 包含 numpy.linalg 中的所有函数。此外,scipy.linalg 还具有 numpy.linalg 中没有的一些其他高级函数。与 numpy.linalg 相比,使用 scipy.linalg 的另一个优点是它始终使用 BLAS/LAPACK 支持进行编译,而对于 NumPy,这是可选的。因此,根据 NumPy 的安装方式,SciPy 版本可能会更快。
线性方程
scipy.linalg.solve 功能可求解线性方程 a * x + b * y = Z,其中 x、y 值为未知值。
例如,假设需要求解以下联立方程。
x + 3y + 5z = 10
2x + 5y + z = 8
2x + 3y + 8z = 3
要求解上述方程中的 x、y、z 值,我们可以使用矩阵逆来找到解向量,如下所示。
$$\begin{bmatrix} x\ y\ z \end{bmatrix} = \begin{bmatrix} 1 & 3 & 5\ 2 & 5 & 1\ 2 & 3 & 8 \end{bmatrix}^{-1} \begin{bmatrix} 10\ 8\ 3 \end{bmatrix} = \frac{1}{25} \begin{bmatrix} -232\ 129\ 19 \end{bmatrix} = \begin{bmatrix} -9.28\ 5.16\ 0.76 \end{bmatrix}.$$
但是,最好使用 linalg.solve 命令,该命令速度更快,数值更稳定。
solve 函数接受两个输入"a"和"b",其中"a"表示系数,"b"表示相应的右侧值,并返回解决方案数组。
让我们考虑以下示例。
#导入 scipy 和 numpy 包 from scipy import linalg import numpy as np #声明 numpy 数组 a = np.array([[3, 2, 0], [1, -1, 0], [0, 5, 1]]) b = np.array([2, 4, -1]) #将值传递给 resolve 函数 x = linalg.solve(a, b) #打印结果数组 print x
上述程序将生成以下输出。
array([ 2., -2., 9.])
查找行列式
方阵 A 的行列式通常表示为 |A|,是线性代数中经常使用的量。在 SciPy 中,这是使用 det() 函数计算的。它以矩阵作为输入并返回标量值。
让我们考虑以下示例。
#导入 scipy 和 numpy 包 from scipy import linalg import numpy as np #声明 numpy 数组 A = np.array([[1,2],[3,4]]) #将值传递给 det 函数 x = linalg.det(A) #打印结果 print x
上述程序将生成以下输出。
-2.0
特征值和特征向量
特征值-特征向量问题是最常用的线性代数运算之一。我们可以通过考虑以下关系 − 来找到方阵 (A) 的特征值 (λ) 和相应的特征向量 (v)。
Av = λv
scipy.linalg.eig 根据普通或广义特征值问题计算特征值。此函数返回特征值和特征向量。
让我们考虑以下示例。
#导入 scipy 和 numpy 包 from scipy import linalg import numpy as np #声明 numpy 数组 A = np.array([[1,2],[3,4]]) #将值传递给 eig 函数 l, v = linalg.eig(A) #打印特征值的结果 print l #打印特征向量的结果 print v
上述程序将生成以下输出。
array([-0.37228132+0.j, 5.37228132+0.j]) #--Eigen Values
array([[-0.82456484, -0.41597356], #--Eigen Vectors
[ 0.56576746, -0.90937671]])
奇异值分解
奇异值分解 (SVD) 可以看作是特征值问题对非方阵的扩展。
scipy.linalg.svd 将矩阵"a"分解为两个酉矩阵"U"和"Vh"以及奇异值(实数,非负)的一维数组"s",使得 a == U*S*Vh,其中"S"是具有主对角线"s"的适当形状的零矩阵。
让我们考虑以下示例。
#导入 scipy 和 numpy 包 from scipy import linalg import numpy as np #声明 numpy 数组 a = np.random.randn(3, 2) + 1.j*np.random.randn(3, 2) #将值传递给 eig 函数 U, s, Vh = linalg.svd(a) #打印结果 print U, Vh, s
上述程序将生成以下输出。
(
array([
[ 0.54828424-0.23329795j, -0.38465728+0.01566714j,
-0.18764355+0.67936712j],
[-0.27123194-0.5327436j , -0.57080163-0.00266155j,
-0.39868941-0.39729416j],
[ 0.34443818+0.4110186j , -0.47972716+0.54390586j,
0.25028608-0.35186815j]
]),
array([ 3.25745379, 1.16150607]),
array([
[-0.35312444+0.j , 0.32400401+0.87768134j],
[-0.93557636+0.j , -0.12229224-0.33127251j]
])
)
SciPy - Ndimage
SciPy ndimage 子模块专用于图像处理。此处,ndimage 表示 n 维图像。
图像处理中一些最常见的任务如下 &miuns;
- 输入/输出,显示图像
- 基本操作 − 裁剪、翻转、旋转等。
- 图像过滤 − 去噪、锐化等。
- 图像分割 −标记与不同对象相对应的像素
- 分类
- 特征提取
- 配准
让我们讨论一下如何使用 SciPy 实现其中一些功能。
打开和写入图像文件
SciPy 中的 misc 包 附带一些图像。我们使用这些图像来学习图像处理。让我们考虑以下示例。
from scipy import misc
f = misc.face()
misc.imsave('face.png', f) # 使用图像模块 (PIL)
import matplotlib.pyplot as plt
plt.imshow(f)
plt.show()
The above program will generate the following output.

任何原始格式的图像都是由矩阵格式的数字表示的颜色组合。机器仅根据这些数字来理解和处理图像。 RGB 是一种流行的表示方式。
让我们看看上面图片的统计信息。
from scipy import misc face = misc.face(gray = False) print face.mean(), face.max(), face.min()
上面的程序将生成以下输出。
110.16274388631184, 255, 0
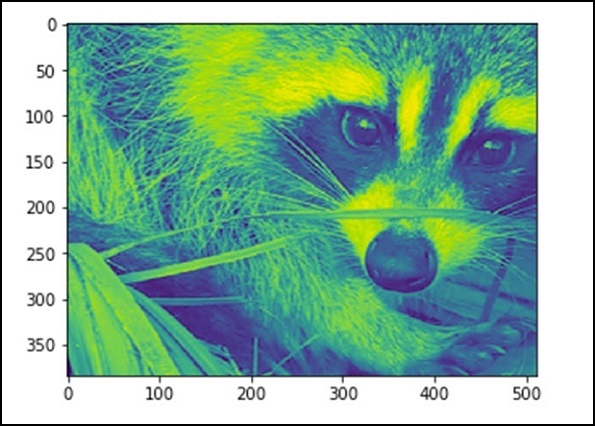
现在,我们知道图像是由数字组成的,因此数字值的任何变化都会改变原始图像。让我们对图像执行一些几何变换。基本的几何操作是裁剪
from scipy import misc face = misc.face(gray = True) lx, ly = face.shape # 裁剪 crop_face = face[lx / 4: - lx / 4, ly / 4: - ly / 4] import matplotlib.pyplot as plt plt.imshow(crop_face) plt.show()
上述程序将生成以下输出。
我们还可以执行一些基本操作,例如如下所述将图像上下翻转。
# up <->向下翻转 from scipy import misc face = misc.face() flip_ud_face = np.flipud(face) import matplotlib.pyplot as plt plt.imshow(flip_ud_face) plt.show()
上述程序将生成以下输出。

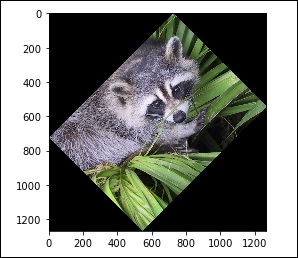
除此之外,我们还有 rotate() 函数,它可以以指定的角度旋转图像。
# 旋转 from scipy import misc,ndimage face = misc.face() rotate_face = ndimage.rotate(face, 45) import matplotlib.pyplot as plt plt.imshow(rotate_face) plt.show()
上述程序将生成以下输出。
过滤器
让我们讨论一下过滤器如何帮助图像处理。
图像处理中的过滤是什么?
过滤是一种修改或增强图像的技术。例如,您可以过滤图像以强调某些特征或删除其他特征。使用过滤实现的图像处理操作包括平滑、锐化和边缘增强。
过滤是一种邻域操作,其中输出图像中任何给定像素的值都是通过对相应输入像素邻域中的像素值应用某种算法来确定的。现在让我们使用 SciPy ndimage 执行一些操作。
模糊
模糊被广泛用于减少图像中的噪声。我们可以执行过滤操作并查看图像中的变化。让我们考虑以下示例。
from scipy import misc face = misc.face() blurred_face = ndimage.gaussian_filter(face, sigma=3) import matplotlib.pyplot as plt plt.imshow(blurred_face) plt.show()
上述程序将生成以下输出。

sigma 值以 5 为单位表示模糊程度。我们可以通过调整 sigma 值来查看图像质量的变化。有关模糊的更多详细信息,请单击 → DIP(数字图像处理)教程。
边缘检测
让我们讨论一下边缘检测如何帮助图像处理。
什么是边缘检测?
边缘检测是一种用于查找图像中物体边界的图像处理技术。它通过检测亮度的不连续性来工作。边缘检测用于图像处理、计算机视觉和机器视觉等领域的图像分割和数据提取。
最常用的边缘检测算法包括
- Sobel
- Canny
- Prewitt
- Roberts
- 模糊逻辑方法
让我们考虑以下示例。
import scipy.ndimage as nd import numpy as np im = np.zeros((256, 256)) im[64:-64, 64:-64] = 1 im[90:-90,90:-90] = 2 im = ndimage.gaussian_filter(im, 8) import matplotlib.pyplot作为 plt plt.imshow(im) plt.show()
上述程序将生成以下输出。
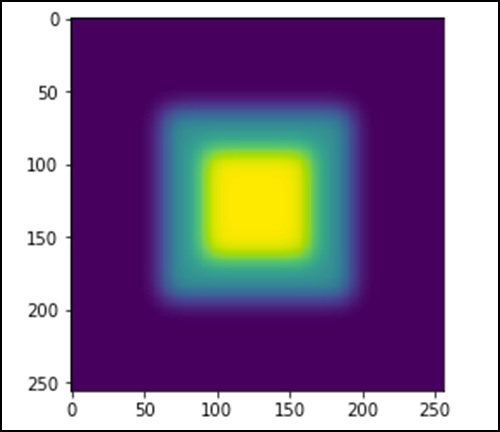
图像看起来像一个方形的彩色块。现在,我们将检测这些彩色块的边缘。这里,ndimage 提供了一个名为 Sobel 的函数来执行此操作。而 NumPy 提供了 Hypot 函数将两个结果矩阵合并为一个。
让我们考虑以下示例。
import scipy.ndimage as nd import matplotlib.pyplot as plt im = np.zeros((256, 256)) im[64:-64, 64:-64] = 1 im[90:-90,90:-90] = 2 im = ndimage.gaussian_filter(im, 8) sx = ndimage.sobel(im, axis = 0, mode = 'constant') sy = ndimage.sobel(im, axis = 1, mode = 'constant') sob = np.hypot(sx, sy) plt.imshow(sob) plt.show()
上述程序将生成以下输出。
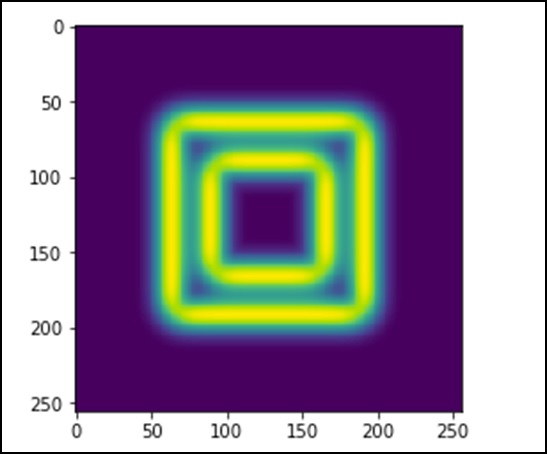
SciPy - 优化
scipy.optimize 包提供了几种常用的优化算法。该模块包含以下方面 −
使用各种算法(例如 BFGS、Nelder-Mead 单纯形、牛顿共轭梯度、COBYLA 或 SLSQP)对多元标量函数进行无约束和约束最小化(minimize())
全局(强力)优化例程(例如 anneal()、basinhopping())
最小二乘最小化 (leastsq()) 和曲线拟合 (curve_fit()) 算法
标量单变量函数最小化器 (minimize_scalar()) 和根查找器 (newton())
使用各种算法(例如混合 Powell、 Levenberg-Marquardt 或大规模方法(如 Newton-Krylov)
多元标量函数的无约束和约束最小化
minimize() 函数为 scipy.optimize 中的多元标量函数的无约束和约束最小化算法提供了一个通用接口。为了演示最小化函数,请考虑最小化 NN 变量 Rosenbrock 函数的问题 −
$$f(x) = \sum_{i = 1}^{N-1} \:100(x_i - x_{i-1}^{2})$$
此函数的最小值为 0,当 xi = 1 时可实现。
Nelder–Mead 单纯形算法
在下面的示例中,minimize() 例程与 Nelder-Mead 单纯形算法 (method = 'Nelder-Mead')(通过 method 参数选择)一起使用。让我们考虑以下示例。
import numpy as np from scipy.optimize import minimize def rosen(x): x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2]) res = minimize(rosen, x0, method='nelder-mead') print(res.x)
上述程序将生成以下输出。
[7.93700741e+54 -5.41692163e+53 6.28769150e+53 1.38050484e+55 -4.14751333e+54]
单纯形算法可能是最小化相当良好函数的最简单方法。它只需要函数评估,是简单最小化问题的不错选择。但是,由于它不使用任何梯度评估,因此可能需要更长时间才能找到最小值。
另一种只需要函数调用即可找到最小值的优化算法是 Powell 方法,可通过在 minimal() 函数中设置 method = 'powell' 来获得。
最小二乘法
解决变量有界的非线性最小二乘问题。给定残差 f(x)(n 个实变量的 m 维实函数)和损失函数 rho(s)(标量函数),最小二乘法找到成本函数 F(x) 的局部最小值。让我们考虑以下示例。
在此示例中,我们找到独立变量没有界的 Rosenbrock 函数的最小值。
#Rosenbrock Function def fun_rosenbrock(x): return np.array([10 * (x[1] - x[0]**2), (1 - x[0])]) from scipy.optimize import least_squares input = np.array([2, 2]) res = least_squares(fun_rosenbrock, input) print res
请注意,我们仅提供残差向量。该算法将成本函数构建为残差平方和,从而得出 Rosenbrock 函数。确切的最小值位于 x = [1.0,1.0]。
上述程序将生成以下输出。
active_mask: array([ 0., 0.])
cost: 9.8669242910846867e-30
fun: array([ 4.44089210e-15, 1.11022302e-16])
grad: array([ -8.89288649e-14, 4.44089210e-14])
jac: array([[-20.00000015,10.],[ -1.,0.]])
message: '`gtol` termination condition is satisfied.'
nfev: 3
njev: 3
optimality: 8.8928864934219529e-14
status: 1
success: True
x: array([ 1., 1.])
求根
让我们了解求根在 SciPy 中的帮助。
标量函数
如果有一个单变量方程,有四种不同的求根算法可以尝试。每种算法都需要一个区间的端点,在这个区间中根是预期的(因为函数会改变符号)。一般来说,brentq 是最佳选择,但其他方法在某些情况下或出于学术目的可能有用。
定点求解
与寻找函数零点密切相关的问题是寻找函数的不动点的问题。函数的不动点是函数求值返回点的点:g(x) = x。显然,gg 的不动点是 f(x) = g(x)−x 的根。等价地,ff 的根是 g(x) = f(x)+x 的 fixed_point。如果给出了起点,则常规 fixed_point 提供了一种使用 Aitkens 序列加速 的简单迭代方法来估计 gg 的不动点。
方程组
可以使用 root() 函数 来查找一组非线性方程的根。有几种方法可用,其中hybr(默认)和 lm 分别使用 Powell 的混合方法 和 MINPACK 中的 Levenberg-Marquardt 方法。
以下示例考虑单变量超越方程。
x2 + 2cos(x) = 0
其根可按如下方式找到 −
import numpy as np from scipy.optimize import root def func(x): return x*2 + 2 * np.cos(x) sol = root(func, 0.3) print sol
上述程序将生成以下输出。
fjac: array([[-1.]])
fun: array([ 2.22044605e-16])
message: 'The solution converged.'
nfev: 10
qtf: array([ -2.77644574e-12])
r: array([-3.34722409])
status: 1
success: True
x: array([-0.73908513])
SciPy - Stats
所有统计函数都位于子包 scipy.stats 中,可以使用 info(stats) 函数获取这些函数的相当完整的列表。还可以从 stats 子包的 docstring 中获取可用的随机变量列表。此模块包含大量概率分布以及不断增长的统计函数库。
每个单变量分布都有自己的子类,如下表 − 所述
| Sr. No. | Class &描述 |
|---|---|
| 1 | rv_continuous 用于子类化的通用连续随机变量类 |
| 2 | rv_discrete 用于子类化的通用离散随机变量类 |
| 3 | rv_histogram 生成由直方图给出的分布 |
正态连续随机变量
随机变量 X 可以取任意值的概率分布是连续随机变量。位置 (loc) 关键字指定平均值。尺度 (scale) 关键字指定标准偏差。
作为 rv_continuous 类的一个实例,norm 对象从中继承了一组通用方法,并使用特定于此特定分布的细节来完成它们。
要计算多个点的 CDF,我们可以传递一个列表或一个 NumPy 数组。让我们考虑以下示例。
from scipy.stats import norm import numpy as np print norm.cdf(np.array([1,-1., 0, 1, 3, 4, -2, 6]))
上述程序将生成以下输出。
array([ 0.84134475, 0.15865525, 0.5 , 0.84134475, 0.9986501 , 0.99996833, 0.02275013, 1. ])
要找到分布的中位数,我们可以使用百分点函数 (PPF),它是 CDF 的倒数。让我们使用以下示例来理解。
from scipy.stats import norm print norm.ppf(0.5)
上述程序将生成以下输出。
0.0
要生成随机变量序列,我们应该使用 size 关键字参数,如以下示例所示。
from scipy.stats import norm print norm.rvs(size = 5)
上述程序将生成以下输出。
array([ 0.20929928, -1.91049255, 0.41264672, -0.7135557 , -0.03833048])
上述输出不可重现。要生成相同的随机数,请使用种子函数。
均匀分布
可以使用均匀函数生成均匀分布。让我们考虑以下示例。
from scipy.stats import uniform print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)
上述程序将生成以下输出。
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
构建离散分布
让我们生成一个随机样本,并将观察到的频率与概率进行比较。
二项分布
作为 rv_discrete 类 的一个实例,binom 对象 从中继承了一组通用方法,并用具体细节完成它们对于这个特定的分布。让我们考虑以下示例。
from scipy.stats import uniform print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)
上述程序将生成以下输出。
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
描述性统计
最小值、最大值、平均值和方差等基本统计信息将 NumPy 数组作为输入并返回相应的结果。下表介绍了 scipy.stats 包 中可用的几个基本统计函数。
| Sr. No. | 函数 &描述 |
|---|---|
| 1 | describe() 计算传递的数组的几个描述性统计数据 |
| 2 | gmean() 沿指定轴计算几何平均值 |
| 3 | hmean() 沿指定轴计算调和平均值 |
| 4 | kurtosis() 计算峰度 |
| 5 | mode() 返回众数值 |
| 6 | skew() 测试数据的偏度 |
| 7 | f_oneway() 执行单因素方差分析 |
| 8 | iqr() 沿指定方向计算数据的四分位距axis |
| 9 | zscore() 计算样本中每个值相对于样本平均值和标准差的 z 分数 |
| 10 | sem() 计算输入数组中值的平均值的标准误差(或测量的标准误差) |
这些函数中的几个在 scipy.stats.mstats 中都有类似的版本,适用于掩码数组。让我们通过下面给出的示例来理解这一点。
from scipy import stats import numpy as np x = np.array([1,2,3,4,5,6,7,8,9]) print x.max(),x.min(),x.mean(),x.var()
上述程序将生成以下输出。
(9, 1, 5.0, 6.666666666666667)
T 检验
让我们了解 T 检验在 SciPy 中的作用。
ttest_1samp
计算一组分数平均值的 T 检验。这是针对零假设的双侧检验,即独立观测样本"a"的预期值(平均值)等于给定的总体平均值 popmean。让我们考虑以下示例。
from scipy import stats rvs = stats.norm.rvs(loc = 5, scale = 10, size = (50,2)) print stats.ttest_1samp(rvs,5.0)
上述程序将生成以下输出。
Ttest_1sampResult(statistic = array([-1.40184894, 2.70158009]), pvalue = array([ 0.16726344, 0.00945234]))
比较两个样本
在以下示例中,有两个样本,它们可以来自相同或不同的分布,我们想要测试这些样本是否具有相同的统计特性。
ttest_ind − 计算两个独立分数样本的平均值的 T 检验。这是对两个独立样本具有相同平均值(预期值)的零假设的双侧检验。该检验默认假设总体具有相同的方差。
如果我们观察到来自相同或不同总体的两个独立样本,我们可以使用此检验。让我们考虑以下示例。
from scipy import stats rvs1 = stats.norm.rvs(loc = 5,scale = 10,size = 500) rvs2 = stats.norm.rvs(loc = 5,scale = 10,size = 500) print stats.ttest_ind(rvs1,rvs2)
上述程序将生成以下输出。
Ttest_indResult(statistic = -0.67406312233650278, pvalue = 0.50042727502272966)
您可以使用长度相同但平均值不同的新数组进行相同测试。在 loc 中使用不同的值并进行相同测试。
SciPy - CSGraph
CSGraph 代表压缩稀疏图,专注于基于稀疏矩阵表示的快速图算法。
图表示
首先,让我们了解什么是稀疏图以及它如何帮助图表示。
稀疏图到底是什么?
图只是节点的集合,节点之间有链接。图几乎可以表示任何东西 &min; 社交网络连接,其中每个节点都是一个人并与熟人相连;图像,其中每个节点都是一个像素并与相邻像素相连;高维分布中的点,其中每个节点都与其最近的邻居相连;以及您能想象到的任何其他东西。
表示图形数据的一种非常有效的方法是使用稀疏矩阵:我们称之为 G。矩阵 G 的大小为 N x N,G[i, j] 给出节点"i"和节点"j"之间连接的值。稀疏图主要包含零 − ,也就是说,大多数节点只有几个连接。在大多数情况下,此属性都是正确的。
稀疏图子模块的创建受到 scikit-learn 中使用的几种算法的启发,其中包括以下 −
Isomap − 一种流形学习算法,需要在图中找到最短路径。
层次聚类 −基于最小生成树的聚类算法。
谱分解 − 基于稀疏图拉普拉斯算子的投影算法。
作为一个具体的例子,假设我们想要表示以下无向图 −

此图有三个节点,其中节点 0 和 1 由权重为 2 的边连接,节点 0 和 2 由权重为 1 的边连接。我们可以构建密集、掩蔽和稀疏表示,如下例所示,请记住,无向图由对称矩阵表示。
G_dense = np.array([ [0, 2, 1],
[2, 0, 0],
[1, 0, 0] ])
G_masked = np.ma.masked_values(G_dense, 0)
from scipy.sparse import csr_matrix
G_sparse = csr_matrix(G_dense)
print G_sparse.data
上述程序将生成以下输出。
array([2, 1, 2, 1])

这与上一个图相同,只是节点 0 和 2 由零权重的边连接。在这种情况下,上面的密集表示会导致歧义 − 如果零是一个有意义的值,非边如何表示。在这种情况下,必须使用掩码或稀疏表示来消除歧义。
让我们考虑以下示例。
from scipy.sparse.csgraph import csgraph_from_dense G2_data = np.array ([ [np.inf, 2, 0 ], [2, np.inf, np.inf], [0, np.inf, np.inf] ]) G2_sparse = csgraph_from_dense(G2_data, null_value=np.inf) print G2_sparse.data
上述程序将生成以下输出。
array([ 2., 0., 2., 0.])
使用稀疏图的单词阶梯
单词阶梯是 Lewis Carroll 发明的一种游戏,其中单词通过每一步改变一个字母来连接。例如 −
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
在这里,我们通过七步从"APE"变成了"MAN",每次改变一个字母。问题是 - 我们能否使用相同的规则找到这些单词之间的更短路径?这个问题自然地表示为稀疏图问题。节点将与单个单词相对应,我们将在最多相差一个字母的单词之间建立连接。
获取单词列表
首先,当然,我们必须获取有效单词列表。我正在运行 Mac,Mac 在以下代码块中给出的位置有一个单词词典。如果您使用的是不同的架构,则可能需要搜索一下才能找到您的系统词典。
wordlist = open('/usr/share/dict/words').read().split()
print len(wordlist)
上述程序将生成以下输出。
235886
我们现在要查看长度为 3 的单词,因此让我们只选择那些长度正确的单词。我们还将删除以大写字母(专有名词)开头或包含非字母数字字符(如撇号和连字符)的单词。最后,我们将确保所有内容都为小写,以便稍后进行比较。
word_list = [word for word in word_list if len(word) == 3] word_list = [word for word in word_list if word[0].islower()] word_list = [word for word in word_list if word.isalpha()] word_list = map(str.lower, word_list) print len(word_list)
上述程序将生成以下输出。
1135
现在,我们有了 1135 个有效的三字母单词列表(具体数量可能因使用的特定列表而异)。这些单词中的每一个都将成为我们图中的一个节点,我们将创建连接与每对单词相关的节点的边,这些单词只相差一个字母。
import numpy as np word_list = np.asarray(word_list) word_list.dtype word_list.sort() word_bytes = np.ndarray((word_list.size, word_list.itemsize), dtype = 'int8', buffer = word_list.data) print word_bytes.shape
上述程序将生成以下输出。
(1135, 3)
我们将使用每个点之间的汉明距离来确定哪些单词对是相连的。汉明距离测量两个向量之间不同的条目的分数:任何两个汉明距离等于 1/N1/N 的单词,其中 NN 是单词阶梯中相连的字母数。
来自 scipy.spatial.distance 导入 pdist, squareform 来自 scipy.sparse 导入 csr_matrix hamming_dist = pdist(word_bytes, metric = 'hamming') graph = csr_matrix(squareform(hamming_dist < 1.5 / word_list.itemsize))
比较距离时,我们不使用相等性,因为这对浮点值来说可能不稳定。只要单词列表中没有两个条目相同,不等式就会产生所需的结果。现在,我们的图表已设置完毕,我们将使用最短路径搜索来查找图表中任意两个单词之间的路径。
i1 = word_list.searchsorted('ape')
i2 = word_list.searchsorted('man')
print word_list[i1],word_list[i2]
上述程序将生成以下输出。
ape, man
我们需要检查这些是否匹配,因为如果单词不在列表中,则输出中会出现错误。现在,我们需要做的就是在图表中找到这两个索引之间的最短路径。我们将使用 dijkstra 算法,因为它允许我们仅找到一个节点的路径。
from scipy.sparse.csgraph import dijkstra distances, predecessors = dijkstra(graph, indices = i1, return_predecessors = True) print distances[i2]
上述程序将生成以下输出。
5.0
因此,我们看到"ape"和"man"之间的最短路径仅包含五步。我们可以使用算法返回的前任来重建此路径。
path = [] i = i2 while i != i1: path.append(word_list[i]) i = predecessors[i] path.append(word_list[i1]) print path[::-1]i2]
上述程序将生成以下输出。
['ape', 'ope', 'opt', 'oat', 'mat', 'man']
SciPy - Spatial
scipy.spatial 包可以利用 Qhull 库来计算一组点的三角剖分、Voronoi 图和凸包。此外,它还包含用于最近邻点查询的 KDTree 实现 和用于各种度量的距离计算的实用程序。
Delaunay 三角剖分
让我们了解 Delaunay 三角剖分是什么以及它们在 SciPy 中的使用方式。
什么是 Delaunay 三角剖分?
在数学和计算几何中,对于平面中给定的离散点集 P 的 Delaunay 三角剖分是三角剖分 DT(P),使得 P 中的任何点都不在 DT(P) 中任何三角形的外接圆内。
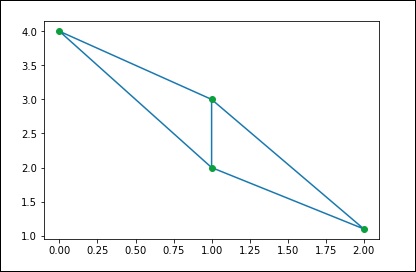
我们可以通过 SciPy 进行相同的计算。让我们考虑以下示例。
from scipy.spatial import Delaunay points = np.array([[0, 4], [2, 1.1], [1, 3], [1, 2]]) tri = Delaunay(points) import matplotlib.pyplot as plt plt.triplot(points[:,0], points[:,1], tri.simplices.copy()) plt.plot(points[:,0], points[:,1], 'o') plt.show()
上述程序将生成以下输出。
共面点
让我们了解共面点是什么以及它们在 SciPy 中的用法。
什么是共面点?
共面点是位于同一平面上的三个或多个点。回想一下,平面是一个平坦的表面,它向所有方向无限延伸。它在数学教科书中通常显示为四边形。
让我们看看如何使用 SciPy 找到它。让我们考虑以下示例。
from scipy.spatial import Delaunay points = np.array([[0, 0], [0, 1], [1, 0], [1, 1], [1, 1]]) tri = Delaunay(points) print tri.coplanar
上述程序将生成以下输出。
array([[4, 0, 3]], dtype = int32)
这意味着点 4 位于三角形 0 和顶点 3 附近,但不包含在三角剖分中。
凸包
让我们了解什么是凸包以及它们在 SciPy 中的使用方式。
什么是凸包?
在数学中,欧几里得平面或欧几里得空间中(或更一般地,在实数上的仿射空间中)的一组点 X 的凸包或凸包络是包含 X 的最小凸集。
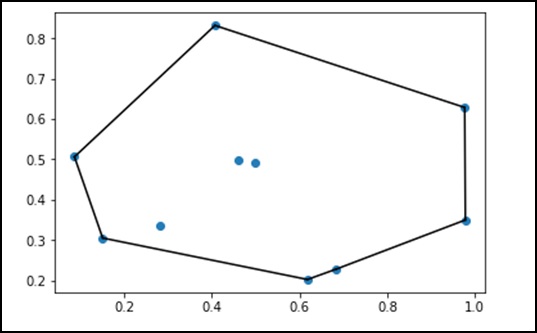
让我们考虑以下示例以详细了解它。
from scipy.spatial import ConvexHull points = np.random.rand(10, 2) # 2-D 中的 30 个随机点 hull = ConvexHull(points) import matplotlib.pyplot as plt plt.plot(points[:,0], points[:,1], 'o') for simplex in hull.simplices: plt.plot(points[simplex,0], points[simplex,1], 'k-') plt.show()
上述程序将生成以下输出。
SciPy - ODR
ODR 代表正交距离回归,用于回归研究。基本线性回归通常用于通过在图表上绘制最佳拟合线来估计两个变量y和x之间的关系。
用于此目的的数学方法称为最小二乘法,旨在最小化每个点的平方误差之和。这里的关键问题是如何计算每个点的误差(也称为残差)?
在标准线性回归中,目的是根据 X 值预测 Y 值 - 因此明智的做法是计算 Y 值的误差(如下图所示的灰线)。但是,有时同时考虑 X 和 Y 的误差更为明智(如下图红色虚线所示)。
例如 −当您知道 X 的测量结果不确定时,或者当您不想关注一个变量相对于另一个变量的误差时。
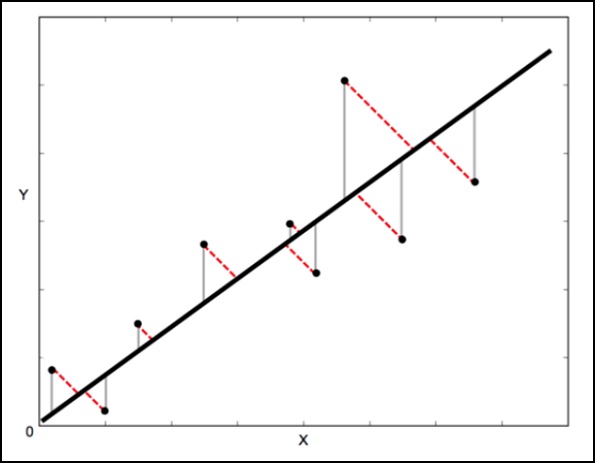
正交距离回归 (ODR) 是一种可以做到这一点的方法(在这种情况下,正交意味着垂直 - 因此它计算垂直于线的误差,而不仅仅是"垂直")。
scipy.odr 单变量回归的实现
以下示例演示了 scipy.odr 单变量回归的实现。
import numpy as np import matplotlib.pyplot as plt from scipy.odr import * import random # 初始化一些数据,使用提供一些随机性random.random()。 x = np.array([0, 1, 2, 3, 4, 5]) y = np.array([i**2 + random.random() for i in x]) # 定义一个函数(在我们的例子中是二次函数)来拟合数据。 def linear_func(p, x): m, c = p return m*x + c # 创建一个拟合模型。 linear_model = Model(linear_func) # 使用我们上面初始化的数据创建一个 RealData 对象。 data = RealData(x, y) # 使用模型和数据设置 ODR。 odr = ODR(data, linear_model, beta0=[0., 1.]) # 运行回归。 out = odr.run() # 使用内置的 pprint 方法为我们提供结果。 out.pprint()
上述程序将生成以下输出。
Beta: [ 5.51846098 -4.25744878] Beta Std Error: [ 0.7786442 2.33126407] Beta Covariance: [ [ 1.93150969 -4.82877433] [ -4.82877433 17.31417201 ]] Residual Variance: 0.313892697582 Inverse Condition #: 0.146618499389 Reason(s) for Halting: Sum of squares convergence
SciPy - 特殊包
特殊包中提供的函数是通用函数,遵循广播和自动数组循环。
让我们来看看一些最常用的特殊函数 −
- 三次根函数
- 指数函数
- 相对误差指数函数
- 对数和指数函数
- 兰伯特函数
- 排列和组合函数
- 伽马函数
现在让我们简要了解一下这些函数。
三次根函数
这个三次根函数的语法是 – scipy.special.cbrt(x)。这将获取 x 的元素立方根。
让我们考虑以下示例。
from scipy.special import cbrt res = cbrt([10, 9, 0.1254, 234]) print res
上述程序将生成以下输出。
[ 2.15443469 2.08008382 0.50053277 6.16224015]
指数函数
指数函数的语法是 – scipy.special.exp10(x)。这将按元素方式计算 10**x。
让我们考虑以下示例。
from scipy.special import exp10 res = exp10([2, 9]) print res
上述程序将生成以下输出。
[1.00000000e+02 1.00000000e+09]
相对误差指数函数
此函数的语法为 – scipy.special.exprel(x)。它生成相对误差指数,(exp(x) - 1)/x。
当 x 接近零时,exp(x) 接近 1,因此 exp(x) - 1 的数值计算可能会遭受灾难性的精度损失。然后实现 exprel(x) 以避免精度损失,当 x 接近零时会发生这种情况。
让我们考虑以下示例。
from scipy.special import exprel res = exprel([-0.25, -0.1, 0, 0.1, 0.25]) print res
上述程序将生成以下输出。
[0.88479687 0.95162582 1. 1.05170918 1.13610167]
对数和指数函数
此函数的语法为 – scipy.special.logsumexp(x)。它有助于计算输入元素指数和的对数。
让我们考虑以下示例。
from scipy.special import logsumexp import numpy as np a = np.arange(10) res = logsumexp(a) print res
上述程序将生成以下输出。
9.45862974443
Lambert 函数
此函数的语法为 – scipy.special.lambertw(x)。它也被称为 Lambert W 函数。Lambert W 函数 W(z) 定义为 w * exp(w) 的反函数。换句话说,对于任何复数 z,W(z) 的值是这样的:z = W(z) * exp(W(z))。
Lambert W 函数是一个具有无限多分支的多值函数。每个分支都给出方程 z = w exp(w) 的单独解。这里,分支由整数 k 索引。
让我们考虑以下示例。这里,Lambert W 函数是 w exp(w) 的逆。
from scipy.special import lambertw w = lambertw(1) print w print w * np.exp(w)
上述程序将生成以下输出。
(0.56714329041+0j) (1+0j)
排列与组合
让我们分别讨论排列和组合,以便清楚地理解它们。
组合 − 组合函数的语法是 – scipy.special.comb(N,k)。让我们考虑以下示例 −
from scipy.special import comb res = comb(10, 3, exact = False,repetition=True) print res
上述程序将生成以下输出。
220.0
注意 − 数组参数仅在 exact = False 的情况下才被接受。如果 k > N、N < 0 或 k < 0,则返回 0。
排列 − 组合函数的语法是 – scipy.special.perm(N,k)。 N 个事物的排列,每次取 k 个,即 N 的 k 个排列。这也称为"部分排列"。
让我们考虑以下示例。
from scipy.special import perm res = perm(10, 3, exact = True) print res
上述程序将生成以下输出。
720
Gamma 函数
对于自然数"n",gamma 函数通常称为广义阶乘,因为 z*gamma(z) = gamma(z+1) 且 gamma(n+1) = n!。
组合函数的语法是 – scipy.special.gamma(x)。对 N 个事物进行一次取 k 个排列,即 N 的 k 个排列。这也称为"部分排列"。
组合函数的语法是 - scipy.special.gamma(x)。对 N 个事物进行一次取 k 个排列,即 N 的 k 个排列。这也称为"部分排列"。
from scipy.special import gamma res = gamma([0, 0.5, 1, 5]) print res
上述程序将生成以下输出。
[inf 1.77245385 1. 24.]

