生成对抗网络 (GAN) 如何工作?
生成对抗网络 (GAN) 是一种强大的生成建模方法。GAN 基于深度神经网络架构,可生成类似于原始训练数据的新复杂输出。
GAN 通常使用卷积神经网络 (CNN) 等架构。事实上,ChatGPT 与其他基于深度学习的 LLM(大型语言模型)一样,是 GAN 的一个出色应用。本章涵盖了您需要了解的有关 GAN 及其工作原理的所有信息。
什么是生成对抗网络?
生成对抗网络 (GAN) 是一种用于无监督学习的人工智能框架。GAN 由两个神经网络组成:生成器和鉴别器。 GAN 使用对抗性训练来生成与实际数据相似的人工数据。
GAN 可以分为 三个组件 −
- 生成式 − 此组件专注于学习如何通过理解数据集中的潜在模式来生成新数据。
- 对抗式 − 简单来说,"对抗式"意味着将两件事对立起来。在 GAN 中,生成的数据与数据集中的真实数据进行比较。这是使用经过训练的模型来区分真实数据和虚假数据来完成的。该模型称为鉴别器。
- 网络 −为了实现学习过程,GAN 使用深度神经网络。
在了解 GAN 的工作原理之前,让我们先讨论一下它的两个主要部分:生成器模型和鉴别器模型。
生成器模型
生成器模型的目标是生成新的数据样本,这些样本旨在与数据集中的真实数据相似。
- 它将随机输入数据作为输入,并将其转换为合成数据样本。
- 转换后,生成器的另一个目标是生成与真实数据相同的数据,当这些数据呈现给鉴别器时。
- 生成器被实现为神经网络模型。根据生成的数据的类型,它使用全连接层,如密集层或卷积层。
鉴别器模型
鉴别器模型的目标是评估输入数据,并尝试区分数据集中的真实数据样本和生成器模型生成的虚假数据样本。
- 它获取输入数据并预测其是真实的还是虚假的。
- 鉴别器模型的另一个目标是正确地将输入数据的来源分类为真实的或虚假的。
- 与生成器模型一样,鉴别器模型也是作为神经网络模型实现的。它还使用密集层或卷积层。
在 GAN 训练期间,生成器和鉴别器同时进行训练,但方式相反,即相互竞争。
GAN 如何工作?
要了解 GAN 的工作原理,首先看一下此图表,该图表显示了 GAN 的不同组件如何生成与真实数据非常相似的新数据样本 −
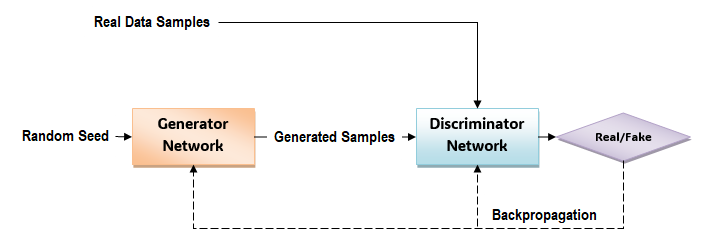
GAN 有两个主要组件:生成器网络和鉴别网络。下面给出了 GAN 工作所涉及的步骤 −
初始化
GAN 由两个神经网络组成:生成器(称为 G)和鉴别器(称为 D)。
- 生成器的目标是生成与数据集中的真实数据非常相似的新数据样本,如图像或文本。
- 鉴别器扮演批评者的角色,其目标是区分真实数据和生成器生成的数据。
训练循环
训练循环涉及交替训练生成器和鉴别器。
训练鉴别器
在训练鉴别器时,每次迭代 −
- 首先,从数据集中选择一批真实数据样本。
- 接下来,生成使用当前生成器生成一批假数据样本。
- 生成后,在真实和假数据样本上训练鉴别器。
- 最后,鉴别器通过调整权重来最小化分类误差,从而学会区分真实数据和假数据。
训练生成器
在训练生成器时,每次迭代 −
- 首先,使用生成器生成一批假数据样本。
- 接下来,训练生成器生成鉴别器分类为真实数据的假数据。为此,我们需要将虚假数据传递给鉴别器,并根据鉴别器的分类误差更新生成器的权重。
- 最后,生成器将通过调整权重来学习生成更逼真的虚假数据,以最大化鉴别器在对其生成的样本进行分类时的误差。
对抗性训练
随着训练的进行,生成器和鉴别器都以对抗性的方式(即相反的方式)提高其性能。
生成器在创建类似于真实数据的虚假数据方面做得越来越好,而鉴别器在区分真实数据和虚假数据方面做得越来越好。
借助生成器和鉴别器之间的这种对抗关系,两个网络都试图不断改进,直到生成器生成与真实数据相同的数据。
评估
训练结束后,生成器可以用于生成与数据集中的真实数据相似的新数据样本。
我们可以通过目视检查样本或使用相似性分数或分类器准确度等定量指标来评估生成数据的质量。
微调和优化
根据应用程序,您可以微调经过训练的 GAN 模型以提高其性能或使其适应特定任务或数据集。
结论
生成对抗网络 (GAN) 是最突出和使用最广泛的生成模型之一。在本章中,我们解释了 GAN 的基础知识以及它如何使用神经网络来生成类似于实际数据的人工数据。
GAN 的工作步骤包括:初始化、训练循环、训练鉴别器、训练生成器、对抗训练、评估以及微调和优化。


