生成式 AI 中的自动编码器
自动编码器是机器学习和深度学习领域中必不可少的工具。它们是一种特殊类型的无监督前馈神经网络,旨在学习数据的有效表示,以实现降维、特征提取和生成新数据的目的。
自动编码器由两个组件组成:编码器网络和解码器网络。编码器网络充当压缩单元,将输入数据压缩为低维表示。另一方面,解码器网络通过重建压缩的输入数据来对其进行解压缩。阅读本章以了解自动编码器、其架构、工作原理、训练过程和超参数调整。
什么是自动编码器?
自动编码器专为无监督学习而设计,是一类人工神经网络。与任何其他神经网络一样,它由三种不同类型的层组成 - 输入、隐藏和输出。输入层中的输入单元数量与输出层中的输出单元数量完全相同。但中间层,即该网络中的隐藏层,其单元数量少于输入层和输出层。
它首先将输入数据压缩为低维表示。由于隐藏层的单元数量较少,因此它保存这种低维表示。最后,在输出层,根据输入的简化表示重建输出。
自动编码器也称为自监督 ML 模型,因为它们是作为监督 ML 模型进行训练的,但在使用时,它们作为无监督 ML 模型工作。
自动编码器的架构
自动编码器的核心架构分为编码器、解码器和瓶颈层,如下图所示 −
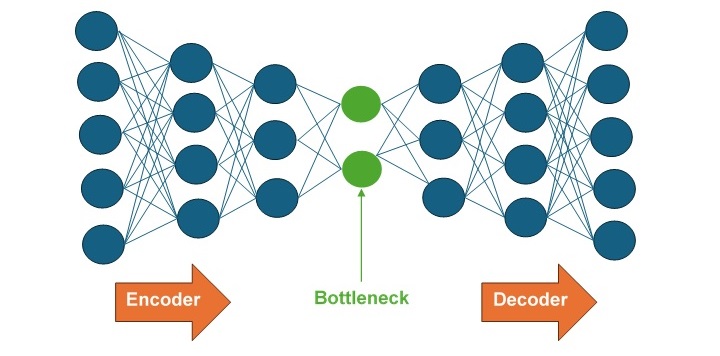
- 编码器 − 编码器是一个完全连接的前馈神经网络 (FFNN),可将输入数据压缩为低维表示。
- 瓶颈层 −瓶颈层包含要输入到解码器的输入的低维表示。
- 解码器 − 解码器是一个完全连接的前馈神经网络 (FFNN),可将输入重建回原始维度。
自动编码器如何工作?
自动编码器工作原理是训练神经网络从低维表示重建其输入数据。这涉及两个主要组件:编码器网络和解码器网络。
编码器网络
编码器网络将输入压缩为低维表示。此过程涉及以下步骤 −
- 输入层 −输入数据通过输入层输入到网络中。
- 隐藏层 − 输入数据现在经过几个隐藏层,其中每层首先应用线性变换,然后应用非线性激活函数。每层的神经元都比前一层少,这逐渐降低了输入数据的维数。
- 瓶颈层(潜在空间表示) − 瓶颈层是编码器网络的最后一层,存储输入的压缩表示。这一层有助于网络学习输入的最重要特征,因为它的维数比输入数据低得多。
解码器网络
解码器网络从低维表示中重建原始输入数据。此过程基本上是编码过程的逆过程。它涉及以下步骤 −
- 瓶颈层(潜在空间表示) − 瓶颈层存储的压缩数据用作解码器网络的输入。
- 隐藏层 − 输入数据现在经过几个隐藏层,其中每个层首先应用线性变换,然后应用非线性激活函数。每层都比前一层具有更多的神经元,从而逐渐将输入数据的维数扩展回原始输入大小。
- 输出层 −输出层是解码器网络的最后一层,它重建数据以匹配原始输入维度。
训练过程
网络从低维表示重建其输入数据的训练过程涉及以下步骤 −
- 初始化 − 首先随机初始化网络的权重。
- 前向传播 − 在此步骤中,输入数据首先通过编码器将其转换为较低维度,然后通过解码器将输入重建为原始数据。
- 损失计算 − 损失函数用于测量原始输入数据与其重建输出之间的差异。一些常见的损失函数是用于连续数据的均方误差 (MSE) 或用于二进制数据的二进制交叉熵。
- 反向传播 − 在此步骤中,为了最小化损失函数,网络会调整其权重。您可以使用梯度下降或任何其他优化算法。
超参数调整
自动编码器中的超参数调整是选择控制自动编码器工作方式的最佳参数集的过程。适当的超参数调整可以提高自动编码器的效率和准确性。
下面列出了一组需要考虑的关键超参数 −
- 学习率 − 它确定在使用优化算法最小化损失函数时的步长。较高的学习率可以加快收敛速度,但稳定性较差。另一方面,较低的学习率可以减缓收敛速度,但稳定性较高。
- 批量大小 − 它指定每次迭代使用的训练示例数量。较大的批量大小可以提供更准确的梯度估计,但需要更多的内存和计算资源。
- 层数 − 它指定自动编码器架构的深度。更多的层数可以捕获更复杂的特征,但可能会导致过度拟合。
- 每层神经元数量 − 它决定了每层的单元数量。每层神经元数量越多,可以学习更多细节,但会增加模型的复杂性。
- 激活函数 − 这些是应用于每层输出的数学函数。不同的激活函数(如 ReLU、Sigmoid、Tanh)会影响模型的性能。
结论
自动编码器将输入数据压缩为低维表示,然后从输入的这种简化表示重建输出。我们已经讨论了自动编码器的工作原理及其架构。了解自动编码器的架构及其工作原理后,机器学习从业者可以解锁数据分析的新可能性并提高模型性能。
我们还讨论了自动编码器中的超参数调整。一些关键的超参数是学习率、批量大小、层数、每层神经元数量和激活函数。这些超参数的调整会影响自动编码器的效率和准确性。


