Plotly - 点图和表格
在这里,我们将了解 Plotly 中的点图和表格函数。首先,让我们从点图开始。
点图
点图以非常简单的比例显示点。它仅适用于少量数据,因为大量的点会使它看起来非常混乱。点图也称为克利夫兰点图。它们显示两个(或更多)时间点之间或两个(或更多)条件之间的变化。
点图类似于水平条形图。但是,它们可以不那么混乱,并且可以更轻松地比较条件。该图绘制了散点图,并将模式属性设置为标记。
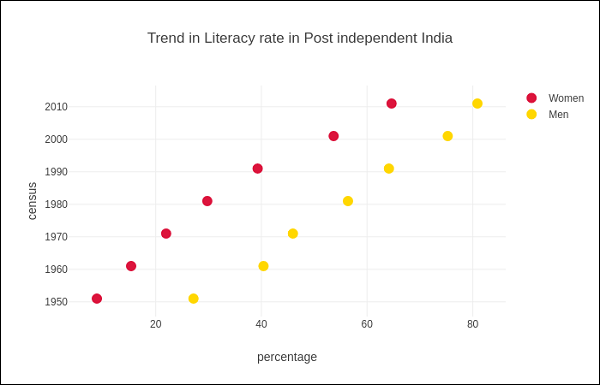
以下示例显示了印度独立后每次人口普查中记录的男性和女性识字率的比较。图中的两条轨迹分别代表 1951 年至 2011 年每次人口普查中男性和女性的识字率。
from plotly.offline import iplot, init_notebook_mode init_notebook_mode(connected = True) census = [1951,1961,1971,1981,1991,2001, 2011] x1 = [8.86, 15.35, 21.97, 29.76, 39.29, 53.67, 64.63] x2 = [27.15, 40.40, 45.96, 56.38,64.13, 75.26, 80.88] traceA = go.Scatter( x = x1, y = census, marker = dict(color = "crimson", size = 12), mode = "markers", name = "Women" ) traceB = go.Scatter( x = x2, y = census, marker = dict(color = "gold", size = 12), mode = "markers", name = "Men") data = [traceA, traceB] layout = go.Layout( title = "Trend in Literacy rate in Post independent India", xaxis_title = "percentage", yaxis_title = "census" ) fig = go.Figure(data = data, layout = layout) iplot(fig)
输出结果如下所示 −
Plotly 中的表格
Plotly 的表格对象由 go.Table() 函数返回。表格轨迹是一个图形对象,可用于在行和列的网格中查看详细数据。表格使用列优先顺序,即网格表示为列向量的向量。
go.Table() 函数的两个重要参数是 header(表格的第一行)和 cells(构成其余行)。这两个参数都是字典对象。 headers 的 values 属性是列标题列表和列表列表,每个列表对应一行。
通过 linecolor、fill_color、font 和其他属性可以进一步自定义样式。
以下代码显示了最近结束的 2019 年世界杯循环赛阶段的积分表。
trace = go.Table(
header = dict(
values = ['Teams','Mat','Won','Lost','Tied','NR','Pts','NRR'],
line_color = 'gray',
fill_color = 'lightskyblue',
align = 'left'
),
cells = dict(
values =
[
[
'India',
'Australia',
'England',
'New Zealand',
'Pakistan',
'Sri Lanka',
'South Africa',
'Bangladesh',
'West Indies',
'Afghanistan'
],
[9,9,9,9,9,9,9,9,9,9],
[7,7,6,5,5,3,3,3,2,0],
[1,2,3,3,3,4,5,5,6,9],
[0,0,0,0,0,0,0,0,0,0],
[1,0,0,1,1,2,1,1,1,0],
[15,14,12,11,11,8,7,7,5,0],
[0.809,0.868,1.152,0.175,-0.43,-0.919,-0.03,-0.41,-0.225,-1.322]
],
line_color='gray',
fill_color='lightcyan',
align='left'
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)
输出如下所示 −
表格数据也可以从 Pandas 数据框中填充。让我们创建一个逗号分隔的文件 (points-table.csv),如下所示 −
| Teams | Mat | Won | Lost | Tied | NR | Pts | NRR |
|---|---|---|---|---|---|---|---|
| India | 9 | 7 | 1 | 0 | 1 | 15 | 0.809 |
| Australia | 9 | 7 | 2 | 0 | 0 | 14 | 0.868 |
| England | 9 | 6 | 3 | 0 | 0 | 14 | 1.152 |
| New Zealand | 9 | 5 | 3 | 0 | 1 | 11 | 0.175 |
| Pakistan | 9 | 5 | 3 | 0 | 1 | 11 | -0.43 |
| Sri Lanka | 9 | 3 | 4 | 0 | 2 | 8 | -0.919 |
| South Africa | 9 | 3 | 5 | 0 | 1 | 7 | -0.03 |
| Bangladesh | 9 | 3 | 5 | 0 | 1 | 7 | -0.41 |
Teams,Matches,Won,Lost,Tie,NR,Points,NRR India,9,7,1,0,1,15,0.809 Australia,9,7,2,0,0,14,0.868 England,9,6,3,0,0,12,1.152 New Zealand,9,5,3,0,1,11,0.175 Pakistan,9,5,3,0,1,11,-0.43 Sri Lanka,9,3,4,0,2,8,-0.919 South Africa,9,3,5,0,1,7,-0.03 Bangladesh,9,3,5,0,1,7,-0.41 West Indies,9,2,6,0,1,5,-0.225 Afghanistan,9,0,9,0,0,0,-1.322
我们现在从这个 csv 文件构建一个数据框对象,并使用它来构建表格跟踪,如下所示 −
import pandas as pd
df = pd.read_csv('point-table.csv')
trace = go.Table(
header = dict(values = list(df.columns)),
cells = dict(
values = [
df.Teams,
df.Matches,
df.Won,
df.Lost,
df.Tie,
df.NR,
df.Points,
df.NRR
]
)
)
data = [trace]
fig = go.Figure(data = data)
iplot(fig)


