BigQuery - 快速指南
BigQuery - 概述
BigQuery 是 Google Cloud Platform (GCP) 的结构化查询语言 (SQL) 引擎。BigQuery 允许用户使用无服务器云基础架构即时查询、创建和操作数据集。因此,学生、专业人士和组织能够以几乎无限的规模存储和分析数据。
与 Google 的其他几项计划一样,BigQuery 最初是 Google 开发人员用来处理和分析大型数据集的内部工具。自 2006 年以来,Google 员工一直在使用 BigQuery 及其前身 Dremel。在 Google 内部取得成功后,GCP 于 2010 年首次发布了 BigQuery 测试版,并于 2011 年广泛推出该工具。
BigQuery 如何超越竞争对手?
尽管在 BigQuery 发布时市场上有许多 SQL 引擎和集成开发环境 (IDE),但 BigQuery 利用了多项竞争优势,其中包括 −
- 开创了基于插槽(Slot)的查询系统,该系统可以根据用户需求自动分配计算能力或"插槽(Slot)位"
- 提供与各种 API 集成从 Python 到 JavaScript 的编程语言
- 为用户提供训练、运行和部署用 SQL 编写的机器学习模型的能力
- 与 Google Data Studio(已弃用)和 Looker 等可视化平台无缝集成
- 存储和查询 ARRAY 和 STRUCT 类型(两种复杂的 SQL 数据类型)的能力
为了帮助学生和专业人士,BigQuery 维护了有关函数、公共数据集和可用集成的强大文档。
Google BigQuery 用例
如果使用得当,Google BigQuery 可以用作个人或组织数据仓库。但是,由于 BigQuery 面向 SQL,因此最好将其用于具有结构化数据而非非结构化数据的来源。
Google 的云架构有助于实现可靠的存储,并实现几乎无限的可扩展性。这使得 BigQuery 成为一种受欢迎的企业选择,尤其是对于生成或提取大量数据的组织而言。
要真正了解 BigQuery 的强大功能,了解不同数据团队角色之间的用例差异会很有帮助。
- 数据分析师 − 使用 BigQuery 与 Tableau 或 Looker 等数据可视化工具结合使用,为组织领导层创建头条报告。
- 数据科学家 − 利用 BigQuery 的机器学习功能 Big ML 来创建和实施 ML 模型。
- 数据工程师 −使用 BigQuery 作为数据仓库,并构建视图和用户定义函数等工具,使最终用户能够在清理、预处理的数据集中发现见解。
当结合使用时,BigQuery 提供了优化存储和生成细微见解的机会,从而提高增长和收入。
在 BigQuery 中加载数据
在 BigQuery 中加载数据简单直观,云开发人员可以使用多种选项。BigQuery 可以提取多种形式的数据,包括 −
- CSV
- JSON
- Parquet
BigQuery 还可以与 Google Sheets 等 Google 集成同步以创建实时连接的表格。而且 BigQuery 可以加载存储在 Google Cloud Storage 等云存储库中的文件。
开发人员还可以利用以下方法将数据干净地加载到 BigQuery −
- BigQuery Transfers,这是一种无代码数据管道,可与 Google Analytics 等 GCP 数据集成。
- 基于 SQL 的管道,具有用于创建、删除或删除表的 CRUD 语句。
- 利用 BigQuery API 执行批量或流式加载作业的管道。
- 提供 BigQuery 连接的第三方管道(如 Fivetran)。
定期从上述来源加载数据使下游利益相关者能够可靠地访问及时、准确的数据数据。
BigQuery 查询基础知识
虽然了解 BigQuery 用例以及如何正确加载数据很有帮助,但学习 BigQuery 的初学者很可能会从查询层开始。
BigQuery 中的表引用约定
在编写第一个 SELECT 语句之前,了解 BigQuery 中的表引用约定会很有帮助。
BigQuery 语法与其他 SQL 方言不同,因为正确的 BigQuery SQL 要求开发人员将表引用括在单引号中,例如 − ' '。
表引用涉及三个元素 −
- Project
- Dataset
- Table
总而言之,在 SQL 查询或脚本中引用 BigQuery 表时,其形式如下 −
'my_project.dataset.table'
基本的 BigQuery 查询形式如下 −
SELECT * FROM 'my_project.dataset.table.'
旧版 SQL 和标准 SQL
BigQuery SQL 与其他类型的 SQL 之间的一个重要区别是,BigQuery 支持两种 SQL 分类:旧版 和 标准。
- 旧版 SQL 允许用户使用较旧的、可能已弃用的 SQL 函数。
- 标准 SQL 代表了对 SQL 的更新解释。
出于我们的目的,我们将使用标准 SQL 名称。
在 BigQuery 中编写查询时的注意事项
与其他 SQL 环境不同,当您在 BigQuery 中编写查询时,UI 会自动告诉您查询是否会运行以及它将处理多少数据。请注意,处理的数据量和预计的执行时间之间几乎没有明确的相关性。
- 执行后,您的查询将返回在 UI 中可见的结果,这类似于查看电子表格或 Pandas 数据框。
- 您还可以选择下载结果为 CSV 或 JSON 文件,这两种文件都提供了一种简单的方法来保存数据以供以后使用。
- 如果您需要保存查询文本以供以后运行或编辑,BigQuery 还提供了一个选项,可以使用版本控制保存查询来帮助跟踪更改。
在企业级运行 BigQuery
在具有多个 BigQuery 用户的组织中运行查询时,务必牢记几个因素,以确保您的查询运行不中断或不会对其他用户造成拥塞−
- 避免在使用高峰时段执行查询。
- 尽可能使用 WHERE 子句缩小处理的数据量。
- 对于大型表,创建用户可以更轻松、更高效地查询的视图。
从学习 BigQuery 过渡到在企业级运行查询需要时间来了解特定于您的组织的变量,例如插槽(Slot)使用情况和计算资源消耗。
但是,首先,有必要更深入地了解在 BigQuery 中构建和优化查询。
BigQuery - 初始设置
要尝试以下一些概念,必须创建一个 Google Cloud Platform 帐户。通过创建 GCP 帐户,您将可以访问 Google 的云应用程序套件,包括 BigQuery。
为了向广大受众展示 GCP 产品,Google 为其许多旗舰产品(包括 BigQuery)添加了免费使用套餐。无论定价计划如何,BigQuery 用户每月都可以查询最多 1 TB 的数据并免费存储最多 10 GB 的数据。
但是,为了避免必须将信用卡附加到您的帐户并产生甚至偶然的费用,新用户可以注册 90 天的免费试用期。免费试用附带价值 300 美元的 GCP 信用额度。说实话,除非用户正在运行虚拟机等计算密集型进程或部署 ML 模型,否则这已经足够了。
据 Google 称,用户只要符合以下条件即可参加该计划:−
- 从未成为 Google Cloud 或附属产品的付费客户
- 之前未注册过 Google Cloud Platform 免费试用版
要注册 BigQuery 的 90 天试用版,请执行以下步骤:导航至 cloud.google.com/free 您应该会看到此页面。
单击"免费开始"(中心页面)
登录您的 Google 帐户 −
完成注册流程后,您将可以访问 Google Cloud Platform。

每次登录时,您首先会看到带有"欢迎"字样的 GCP 徽标。在"欢迎"页面的底部,您将看到指向您常用的 GCP 应用程序的"快速访问"链接。

此外,您将能够访问本教程将重点介绍和探索的 BigQuery 的所有功能。
BigQuery 与本地 SQL 引擎
虽然 SQL 已经存在 40 多年,但 BigQuery 并不是第一个 SQL 环境。在 BigQuery 发布之前,SQL 开发人员主要使用本地或"on-prem"数据库。
允许开发人员管理和与数据库交互的系统称为数据库管理系统 (DBMS)。
在"云工程师"或"数据工程师"职位名称流行起来并得到广泛使用之前,使用 DBMS 工具的人拥有"架构师"之类的头衔。通常,这个头衔的使用非常直接,因为使用数据库的人维护物理和数字基础设施。
数据建模
随着数据库技术的发展,架构师的职责主要涉及一项称为数据建模的任务。
虽然 INSERT() 之类的函数可以很容易地从源中获取数据并将其添加到数据库中,但在采用数据建模的组织中,需要花很多心思来考虑如何存储和塑造数据。
流行的数据建模概念包括"星型模式"或"规范化"和"范式"等短语。
BigQuery 与任何传统 DBMS 有何不同?
虽然仍建议在创建 BigQuery 表时遵循最佳实践,但 BigQuery 比传统 DBMS 接口更具开箱即用性。
BigQuery 与更"传统"的 DBMS 有以下不同之处 −
- 可扩展性 − 得益于 Google 数据中心提供的惊人数量的云存储,BigQuery 可以扩展以满足几乎任何存储或查询需求。
- API 集成 − BigQuery 的 SQL 引擎可以通过编程方式利用,而 Postgre 等 DBMS 只能运行本机 SQL 查询。
- ML/AI 功能,与 Vertex AI 集成。
- 更多特定数据类型可用于长期存储。
- Google 特定的 SQL 方言 Google 查询语言 (GQL) 包含比更多传统 SQL 方言更专业的功能。
从用户的角度来看,BigQuery 还提供了有关执行统计数据和用户活动的更多可见性 −
- 允许用户在执行随附的 SQL 之前查看查询是否可接受
- 提供执行计划和查询沿袭
- 扩展的元数据存储,以提供有关查询使用情况、存储和成本的洞察
BigQuery 确实是基于云的 SQL 查询的标准,它始于Google Cloud Console。
BigQuery - Google Cloud Console
由于 BigQuery 是基于云的数据仓库和查询工具,因此可以通过 Google Cloud Console 在任何位置访问它。与 PostgreSQL 或 MySQL 等本地化数据库不同,Google 并未为 BigQuery 创建应用。相反,BigQuery 存在于 Google Cloud Console 中的"云端"。
Google Cloud Console:所有 GCP 应用程序的主页
如果您已创建 Google 帐户和关联的 GCP 项目,则可以访问 Google Cloud Console。
要导航到 BigQuery,您可以在搜索栏中输入"BigQuery",也可以从 Google Cloud Console 左侧的弹出菜单中选择它,您可以在"分析"类别下找到它。
为确保在整个教程中都能访问,建议您将其固定以将"BigQuery"指定为您的固定产品环境。
通过控制台,您将能够访问 BigQuery 的各个方面,包括 −
- BigQuery Studio
- BigQuery API
- 日志和与 BigQuery 相关的错误
- BigQuery 插槽(Slot)使用计费
就像您设置 IDE 以满足您的舒适度和效率标准一样,强烈建议您花时间自定义 Google Cloud Console 体验,以便能够快速可靠地访问相关的 BigQuery 资源。
BigQuery - Google Cloud 层次结构
在继续之前,重要的是要掌握与 BigQuery 及其相关流程相关的基本概念和词汇。
首先,重要的是要了解,即使云计算提供了几乎无限的处理能力,但如果需要 BigQuery 用户执行以下活动,他们也会遇到问题 −
- 执行计算繁重的 SQL 操作,如交叉联接或笛卡尔联接。
- 尝试在未指定目标表的情况下运行大型查询。
- 运行在高峰使用时执行大量查询(如果以企业用户身份使用 BigQuery)。
- 按需或"临时"查询可能会造成僵局,尤其是在与预定的进程争夺执行时段时。
Google Cloud 层次结构
如果您预计在 BigQuery 中创建和填充数据源,请务必注意 Google Cloud 层次结构 −
- 组织
- 项目
- 数据集
- 表
1. 组织层
除非您是帐户所有者、高管或决策者,否则您不太可能需要担心组织层。将其视为包含您在浏览 BigQuery Studio 并在 SQL 环境中编写 SQL 查询时会遇到的其他元素的实体。
2. Google Cloud 组织内的多个项目
任何 Google Cloud 组织都可以有多个项目。有时,公司或企业用户(我们在这里故意避免使用"组织"一词以避免混淆)会创建不同的项目来区分暂存环境和生产环境。
其他时候,这些高级用户会创建不同的项目,以便更好地控制潜在的敏感数据,例如个人身份信息 (PII) 和机密收入信息。
无论哪种情况,当您开始使用 BigQuery 时,您都会创建或获得以具有特定权限和角色范围的用户身份访问 BigQuery 的权限。
3. 项目内的数据集和表
在项目中,要记住的最重要的实体是数据集和表。需要澄清的是,数据集包含一个表或多个表。为了在技术讨论中保持准确性,请尽量避免交替使用这些术语。
您将在数据集中看到的其他元素包括 −
- 例程
- 模型
- 视图
这些额外的数据元素将在以下章节中进行更深入的讨论。
什么是 Dremel?
BigQuery 并不是一个无限的工具。事实上,最好不要将 BigQuery 视为一个众所周知的黑匣子。为了加深您的理解,有必要"深入了解"并检查 BigQuery 引擎的一些内部工作原理。
Google 的 Dremel:分布式计算框架
BigQuery 基于一个名为 Dremel 的分布式计算框架,Google 在 2010 年的白皮书中对此进行了更深入的解释:"Dremel:Web 规模数据集的交互式分析。"
白皮书描述了定义现代 BigQuery 的许多核心特征的愿景,例如即席查询系统、几乎无限的计算能力以及对处理大数据(TB 和 PB 级)的重视。
Dremel 如何工作?
由于 Dremel 最初是内部产品(自 2006 年以来在 Google 内部使用),它结合了搜索和并行数据库管理系统的各个方面。
为了执行查询,Dremel 使用了一种"树状"结构,其中查询的每个阶段都按顺序步骤执行,并且可以并行执行多个查询。 Dremel 将 SQL 查询转换为执行树。
Slots:BigQuery 执行的基础单元
在"查询执行"标题下,作者描述了 BigQuery 执行的基础单元:slot。
- Slot 是一种表示可用处理单元的抽象。
- Slot 是有限的,这就是为什么项目中的任何僵局通常都是由于缺乏可用的 Slot 造成的。
- 由于 Slot 的使用会根据处理的数据量和一天中的时间等多种因素而变化,因此可以想象,当天早些时候快速执行的查询现在可能需要几分钟。
Slot 的抽象可能是 Dremel 论文中表达的最适用的概念;其他信息很有帮助,但主要描述了 BigQuery 产品的早期迭代。
BigQuery:定价和使用模型
无论您是练习第一次 BigQuery 查询的学生还是强大的决策者,了解定价对于定义您可以在 BigQuery 中存储、访问和操作的内容的限制都至关重要。
要彻底了解 BigQuery 定价,最好将成本分为两个部分 −
- 使用(BigQuery 的文档将其称为"计算")
- 存储
使用涵盖您能想到的几乎所有 SQL 活动,从运行简单的 SELECT 查询到部署 ML 模型或编写复杂的用户定义函数。
对于任何与使用相关的活动,BigQuery 提供以下选择 −
- 按使用量付费或"按需"模式。
- 批量插槽(Slot)或"容量"模式,客户按插槽(Slot)小时付费。
哪种定价模式最适合您?
在两种定价模式之间做出选择时,重要的是要考虑以下因素 −
- 查询的数据量
- 产生的用户流量量
"按需"模式按每 TB 定价,这意味着对于拥有许多大型(多个 TB)表的用户来说,这可能是一种直观且方便的跟踪费用的方式。
"容量"或插槽(Slot)模型对于正在发展其数据基础设施且可能没有固定数据量来帮助他们计算可靠的每月费率的组织或个人很有帮助。问题不再是担心每个资源生成多少数据,而是转向完善最佳实践,将查询时间分配给预定的流程和单独的临时查询。
本质上,插槽(Slot)模型遵循 Dremel 项目建立的框架,其中插槽(Slot)(服务器)被保留并相应定价。
什么是 BigQuery Studio?
在建立了基础产品知识和理论后,是时候返回 Google Cloud Console 并进入 BigQuery Studio 了。 BigQuery Studio 曾被简称为"SQL 工作区",用户不仅可以在其中运行 BigQuery 查询,还可以在其中运行一系列其他数据和 AI 工作流。
BigQuery 的目标是提供一个与 GitHub 类似的空间,让用户能够编写和部署 SQL、Spark 甚至 Python 代码,同时保留版本历史记录并促进数据团队之间的协作。
SQL 查询、Python Notebook、数据画布
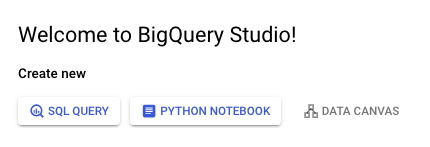
第一次打开 BigQuery Studio 时,会让人联想到任何其他 SQL IDE。但是,与本地 SQL IDE 不同的是,BigQuery 打开时会为您提供三种操作选择 −
- SQL 查询
- Python 笔记本
- 数据画布
单击 SQL 查询应打开一个空白页,您可以在其中编写和运行查询。因此,SQL 查询和 Python 笔记本选项应该是不言自明的。数据画布是一种 AI 集成,本教程不会介绍它。
假设您已经创建或有权访问 BigQuery 项目,在左侧菜单中,您将看到项目名称的下拉菜单,后跟该项目范围内的任何数据集。
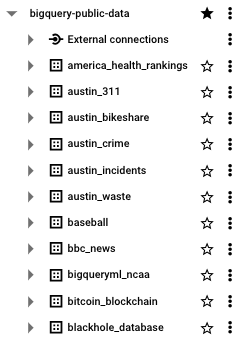
单击其中任何数据集,您将看到在该数据集内创建的表。

在底部,您将看到与您运行的 SQL 作业相关的信息。这些作业分为"个人"作业(由您的个人资料创建和运行的查询)或"项目"作业(允许您查看项目内运行的作业的所有元数据)。
在 BigQuery Studio 中保存工作可以通过没有版本历史记录、"经典"保存查询或有版本历史记录来实现。保存功能还允许轻松创建视图,这将在后面的章节中更深入地介绍。
BigQuery - 数据集
数据集是存在于项目中的实体。数据集充当 BigQuery 表以及视图、例程和机器学习模型的容器。
表不能独立于数据集存在,因此在 BigQuery Studio 中创建新数据源时,必须创建数据集。
除了人类可读的名称等属性外,开发人员还需要在授权创建数据集时指定位置。这些位置与 Google 数据中心在世界各地的物理位置相对应。
指定位置时,您需要指定单个区域或多区域。例如,您不必选择芝加哥的数据中心,而是指定"us-central-1"。
将数据集建立为多区域实体具有额外的优势,即当特定区域没有足够的资源来满足当前需求时,BigQuery 会转移位置。当前的多区域位于美洲(美国)或欧盟(欧洲)。
在 BigQuery 中创建数据集的步骤
要创建数据集,请按照以下步骤操作。首先,导航到您的项目名称并点击三个点,这将触发一个带有"创建数据集" −
的弹出窗口
单击"创建数据集"后,系统将提示您输入 −
- dataset_id
- 位置类型(区域与多区域)。
- 默认表到期时间(表到期前多少天)。
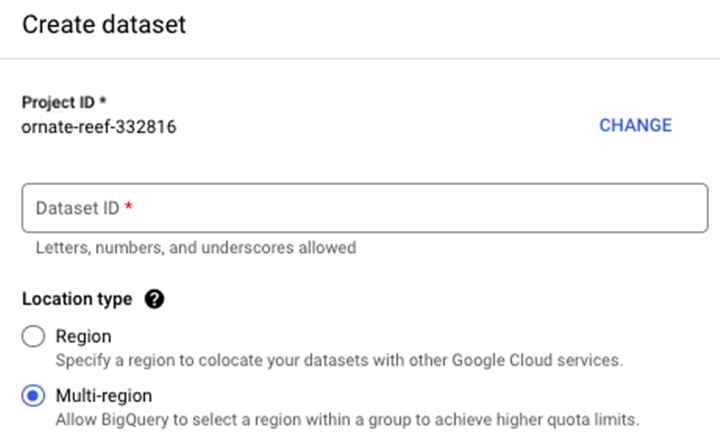
最终结果是一个数据集,它可作为未来表、视图和物化视图的容器。
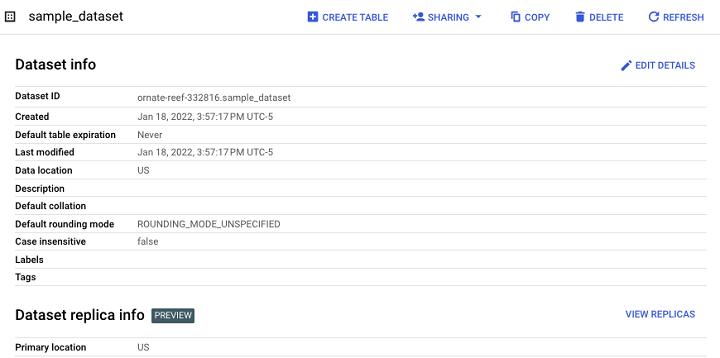
"共享"选项允许开发人员管理对数据集的访问控制,以限制未经授权的用户。
BigQuery:公共数据集
如果您是 BigQuery 新手,并且可能不熟悉 SQL,则可能没有生成要存储和操作的数据。这是使用 BigQuery Studio 作为 SQL 沙盒的优势之一。除了无服务器基础架构外,BigQuery 还提供了数 TB 的示例数据,学生和专业人士可以使用这些数据来学习和完善他们的 SQL 技能。
- 通过 Google Cloud 公共数据集计划发布的 BigQuery 公共数据集存储在其自己的通用可访问项目中:bigquery-public-data。
- 根据按 TB 付费的定价模型,开发者每月最多可以免费查询 1 TB 的数据。
- 与许多库存数据集不同,表格中包含的数据是真实的,也就是"混乱的",有时需要进行重大转换才能产生可操作的见解。
BigQuery 还提供了几个独立于其 BigQuery 公共数据集的示例表,这些示例表可以在 bigquery-public-data:samples 表数据集中找到 −
- gsod
- github_nested
- github_timeline
- natality
- shakespeare
- trigrams
- wikipedia
访问 BigQuery 公共数据集的最大优势可能在于数据来自真实数据源,例如 BBC、Hacker News 和约翰霍普金斯大学。
BigQuery - 表格
表格是 BigQuery 的基础数据源。BigQuery 是一个 SQL 数据存储,因此数据以结构化(而非非结构化或 NoSQL)方式存储。 BigQuery SQL 表是列式的,遵循与电子表格类似的结构,属性或字段映射到列,记录填充行。
与数据集不同,创建表时,用户不必指定位置。
BigQuery 中的表类型
BigQuery 中有两种重要的表类型 −
- 标准表(与任何面向 SQL 的表一样)。
- 视图(可以像标准表一样查询的半永久表)。
表示例
表创建将在后面的章节中介绍。但与此同时,认识和识别上面讨论的表格类型是有帮助的。
这是标准表的示例 −
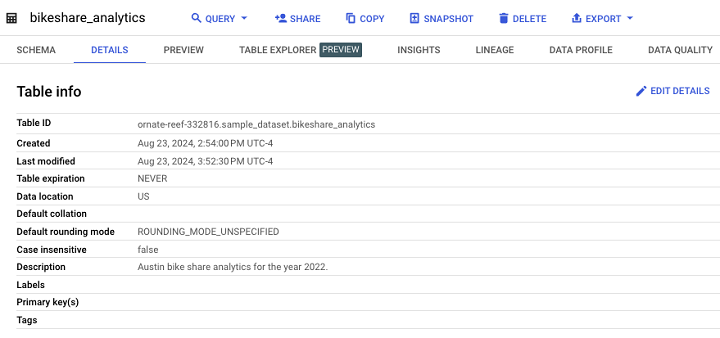
值得注意的是,用户可以看到元数据属性"Description",该属性可立即告知开发人员和用户表格中包含哪些数据。
查看示例
创建或访问表格使开发人员能够基于此数据源构建后续资源。您无疑会遇到并使用的一种表类型是视图。
这就是视图在 BigQuery 中的显示方式。

其架构和在 UI 中的外观与标准表几乎相同。
最后,使用视图定义创建视图,这实际上只是一个具体化查询。

BigQuery - 视图
SQL 中的视图是什么?
在 SQL 中,视图是一个虚拟化表,它不包含数据源(如 CSV 文件)的输出,而是包含预执行查询,该查询会在有新数据可用时更新。
由于视图仅包含预先过滤的数据,因此它们是减少处理量范围的常用方法,并且还可以减少某些数据源的执行时间。
- 虽然表是数据源的整体,但视图代表已保存查询生成的一部分数据。
- 虽然查询可能会从给定表中选择所有内容,但视图可能仅包含最近一天的数据。
创建 BigQuery 视图
可以通过数据操作语言 (DML) 语句创建 BigQuery 视图 −
CREATE OR REPLACE VIEW project.dataset.view
以下是示例,用于创建仅包含 2022 年 Austin Bikeshare 站点数据(来自同名 BigQuery 公共数据集)的视图定义。
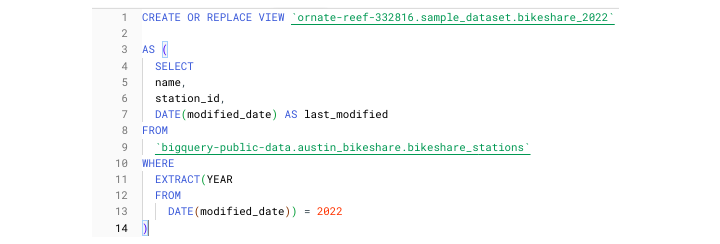
或者,BigQuery 用户可以在 BigQuery 用户界面 (UI) 中创建视图。单击数据集后,无需选择"创建表",只需选择"创建视图"。 BigQuery 提供了单独的图标来区分标准表和视图,以便开发人员一眼就能看出区别。
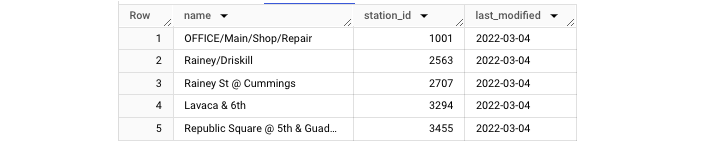
要访问我们上面创建的视图,只需运行 SELECT 语句,就像您用来访问标准表中生成的数据一样。

使用此查询,您将获得一个输出表,如下所示 −
物化视图
除了标准视图外,BigQuery 用户还可以创建物化视图。物化视图位于视图和标准表之间。
BigQuery 文档将物化视图定义为:"[预]重新计算的视图,定期缓存视图查询的结果。缓存的结果存储在 BigQuery 存储中。"
需要注意的是,标准视图不会无限期地存储数据,因此不会产生长期存储费用。
BigQuery - 创建表
要开始利用 BigQuery 的强大功能,必须创建一个表。在本章中,我们将演示如何在 BigQuery 中创建表。
创建 BigQuery 表的要求
创建 BigQuery 表的要求是 −
- 表源("创建表")
- 项目
- 数据集
- 表名称
- 表类型
示例:创建 BigQuery 表
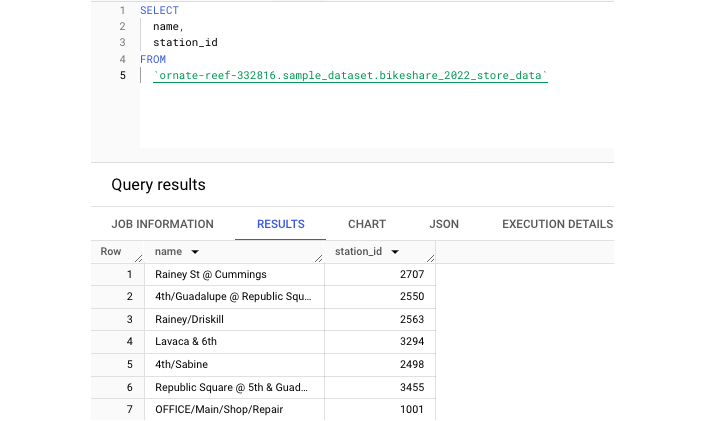
返回 Austin Bikeshare 数据集,我们可以运行此 CREATE TABLE 语句。
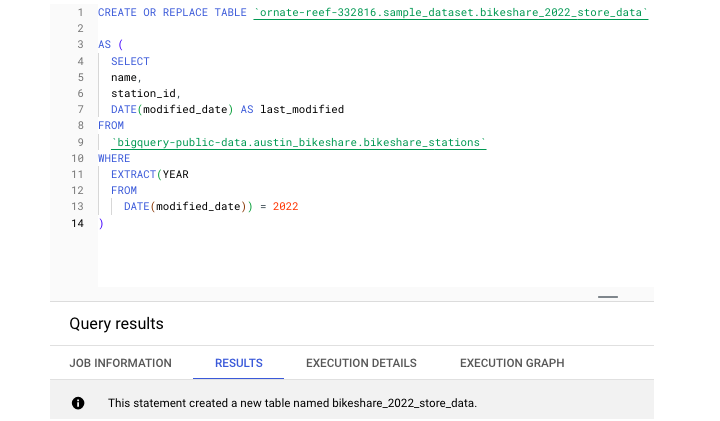
此语句创建了一个名为 bikeshare_2022_store_data 的新表。接下来,让我们运行查询来从这个新创建的表中提取一些数据 −
此外,表可以进行分区和聚类,这两种存储方法都有助于提高表存储和查询的效率。
最后,表会生成并包含有用的元数据,以便开发人员了解其内容的最后更改时间(上次修改字段),提供表用途的简要说明,甚至指示表数据过期的时间(分区过期天数)。
BigQuery - 基本架构设计
与 Excel 电子表格不同,SQL 表不会自动接受所呈现的数据。数据源和表必须就数据的范围和类型达成一致,然后才能成功提取数据。类型必须一致,并且必须采用 BigQuery 可以解析并在 BigQuery Studio 中提供的格式。
什么是架构?
为此,开发人员必须提供架构。本质上,架构是属性及其对应类型的有序列表。
在 BigQuery 中,列顺序和列数很重要,因此任何提供的架构都必须与源表的架构相匹配。
指定架构的三种方法
在 BigQuery 中,有三种指定架构的方法 −
- 在"创建表"步骤期间在 UI 中创建架构。
- 以 JSON 文本文件的形式编写或上传架构。
- 告诉 BigQuery 自动推断架构。
自动推断架构
虽然自动推断架构对于开发人员来说是最少的工作,但这也会给数据管道带来最大的风险。
即使数据类型在一次运行时是一致的,它们也可能会发生变化意外地。如果没有固定的架构,BigQuery 必须"弄清楚"要接受哪种数据类型,这可能会导致架构不匹配错误。
创建架构的 UI 方法
由于创建架构的 UI 方法相当直观,下一部分将重点介绍如何将架构创建为 JSON 文件。
将架构创建为 JSON 文件
JSON 架构的格式是列表"[ ]"内的字典"{ }"。每个字段可以有三个属性 −
- 字段名称
- 列类型
- 列模式
默认列模式为"NULLABLE",这意味着该列接受 NULL 值。在讨论嵌套数据类型时将介绍其他列模式。
一行 JSON 架构的示例如下 −
{"name": "id", "type": "STRING", "mode": "NULLABLE"}
如果您只是添加一列或更改现有列的类型,则可以使用此查询生成现有表的架构 −
[生成架构查询]
只需确保结果设置为"JSON"即可复制/下载生成的 JSON 文件。
GCP Cloud Shell:创建表
Cloud Shell 是 Google Cloud Platform 的命令行界面 (CLI) 工具,允许用户直接从终端窗口与数据源交互。就像可以使用 GCP Console 中的 BigQuery UI 创建表一样,也可以通过 CLI 使用类似 Linux 的语法快速创建表。
与在本地机器上配置 CLI 不同,只要您登录 Google 帐户,就会自动登录 Cloud Shell,因此可以在终端中与 BigQuery 资源进行交互。也可以(但更复杂)在本地 IDE 中配置 gcloud CLI。
"bq"命令行
无论哪种情况,BigQuery cloud shell 集成都取决于一个命令:bq。 bq 命令行 是一个与 Cloud Shell 兼容的基于 Python 的命令行工具。
要创建表,需要将 "bq" 与 "mk" 结合使用 −
--bq mk
此语法与 "–table"或"-t"标志结合使用。还有指定多个参数的选项,就像在 BigQuery UI 中创建表时一样。
可用的参数包括 −
- 过期规则(过期时间,以秒为单位)
- 描述
- 标签
- 添加标签(策略标签)
- 项目 ID
- 数据集 ID
- 表名称
- 架构
以下是示例 −
注意 − 提供了内联架构。
Bq mk -t sample_dataset.bikeshare_table_cli name:STRING,station_id:STRING,modified_date:TIMESTAMP
成功执行后,您将获得类似这样的输出 −

选择 Cloud Shell 而不是 UI 时,性能没有优势;这完全取决于用户偏好。但是,在创建重复或自动化流程时,以这种方式创建表会很有用。
BigQuery - 更改表
在整个 SQL 开发过程中,几乎肯定有必要以某种形式编辑您已经完成的工作。这可能意味着更新查询或优化视图。然而,通常,这意味着更改 SQL 表以满足新要求或促进新数据的传输。
ALTER 命令的用例
为了更改现有表,BigQuery 提供了一个 ALTER 关键字,允许对表结构和元数据进行强大的操作。
在 SQL 环境中更改任何表的语法是"ALTER TABLE"。 ALTER 命令的用例包括 −
- 添加列
- 删除列
- 重命名表
- 添加表描述
- 添加分区到期天数
现在让我们逐一讨论这些情况。
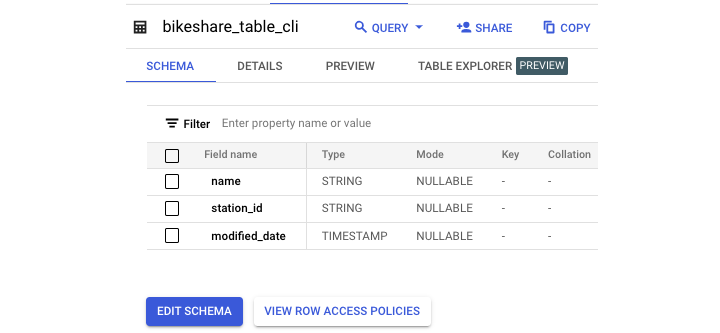
添加列
这是修改前的原始表架构。
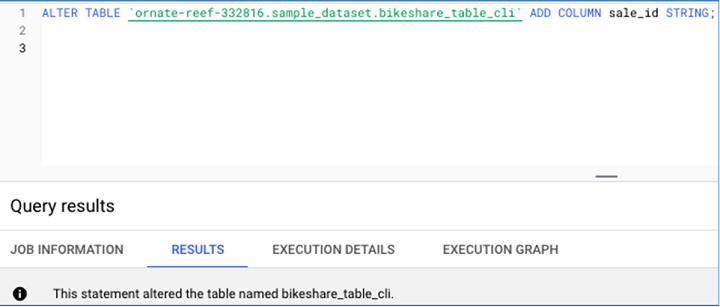
这是用于添加列 的SQL 语句 −
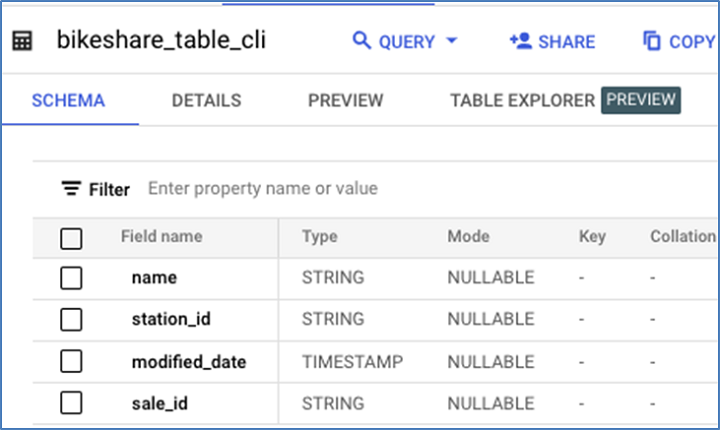
这是添加新列后的表结构。
删除列
这是删除 sale_id 之前的现有表结构。
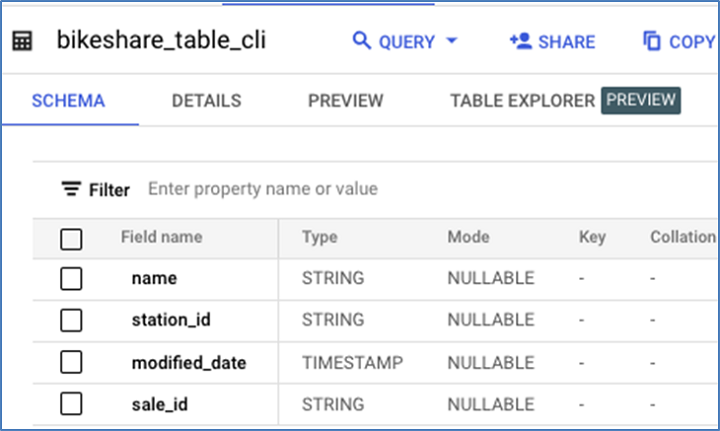
这是 drop sale_id 的 DML −
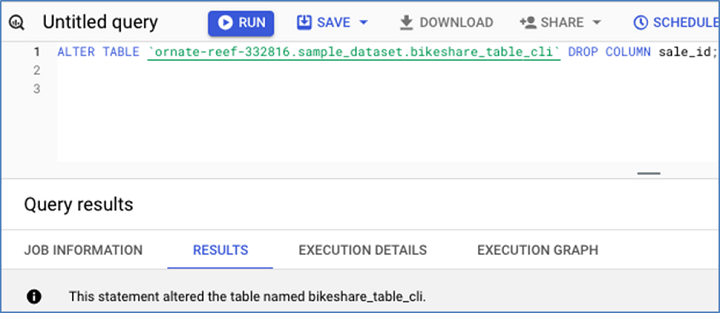
以下是结果模式 −
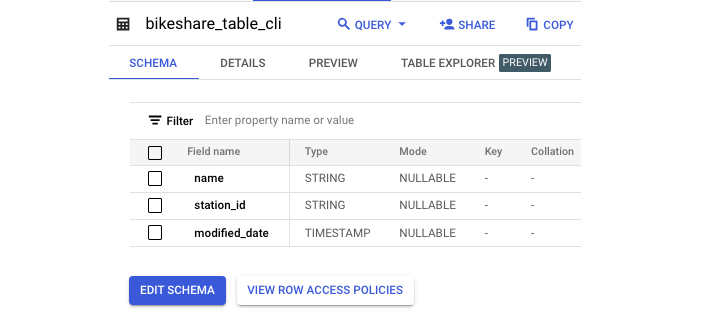
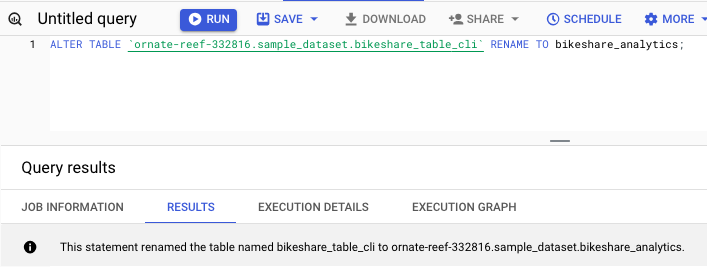
重命名表
您可以使用以下命令重命名表 −
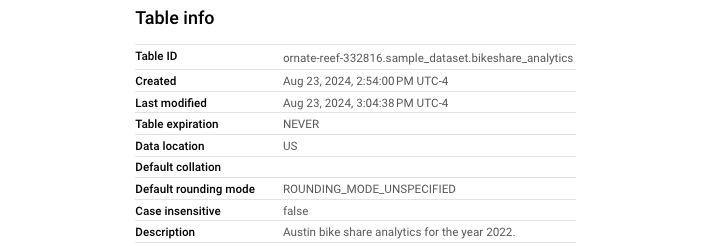
添加表描述
使用以下查询添加表描述 −
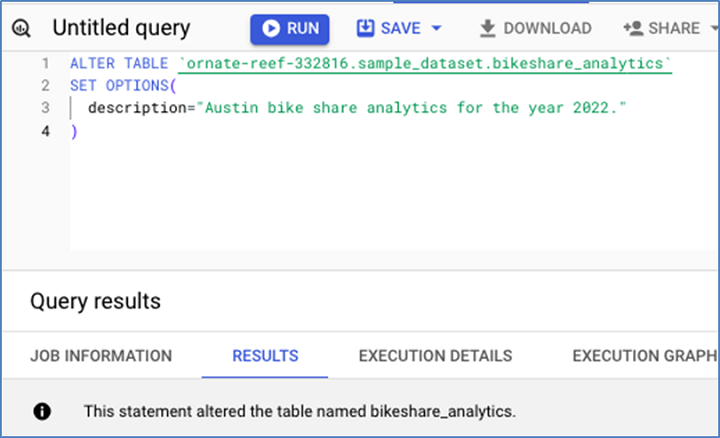
您可以在以下屏幕截图中看到此语句已成功向表添加描述。
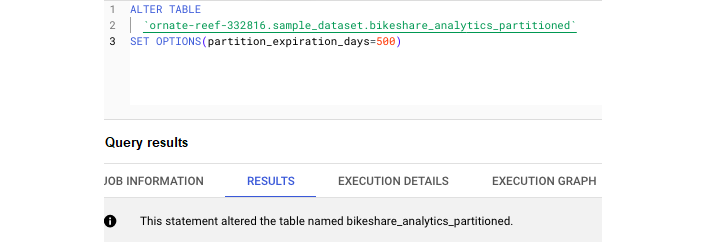
添加分区到期天数
使用以下查询添加分区到期天数 −
与 SELECT 语句不同,任何以 ALTER 开头的 SQL 代码都会从根本上改变给定表的结构或元数据。
注意 −您应该非常谨慎地使用这些查询。
BigQuery - 复制表
SQL 表可以根据需要进行复制或删除,就像桌面上的文件一样。
复制表可以采用两种形式 −
- 复制/重新创建表
- 克隆表
让我们了解克隆表与复制表有何不同。
在 BigQuery 中克隆表
在 BigQuery 中对现有表进行完美复制称为克隆表。此任务可以通过 BigQuery Studio UI 或通过 SQL 复制过程完成。
无论哪种情况,请务必记住,任何新创建的表(即使是克隆的表)仍将产生长期存储和使用费用。
在 BigQuery 中复制表
复制表会保留其所有当前属性,包括 −
- 存储的所有数据
- 分区规范
- 聚类规范
- 元数据(如描述)
- 敏感数据保护策略标签
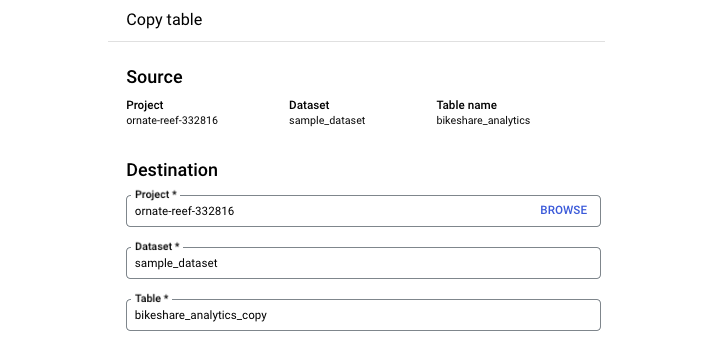
要在 BigQuery Studio UI 中复制表,请导航到查询环境。点击要复制的表。选择"复制"。

请务必注意,此复制过程不是自动的。单击"复制"时,您需要指定要将新表复制到的数据集并提供新表名称。
注意 − 默认命名约定是 GCP 在原始表名称末尾附加"_copy"。
BigQuery 不支持"SQL COPY"命令。相反,开发人员可以使用几种不同的方法复制表格。
创建或替换表格
CREATE OR REPLACE TABLE 通常被视为 BigQuery 中的默认创建表格语句,可以兼作事实上的 COPY。
CREATE OR REPLACE TABLE project.dataset.table
需要使用 AS 关键字 − 提供某种查询
CREATE OR REPLACE TABLE project.dataset.table AS ( )
要执行复制,您只需"SELECT * from"现有表即可。

为了创建完美的克隆,开发人员可以使用"CREATE TABLE CLONE"关键字。此命令可创建现有表的完美副本,而无需提供查询。
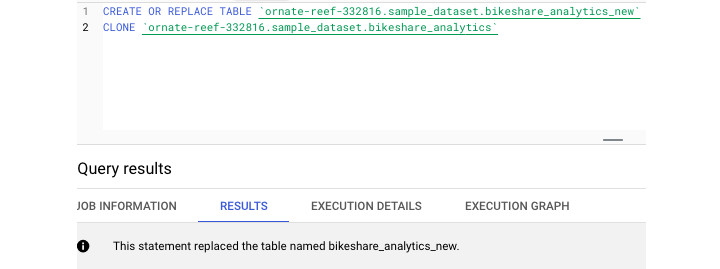
在 UI 和支持的 SQL 语法之间,BigQuery 提供了与复制和克隆表相关的灵活性。
BigQuery - 删除和恢复表
删除表提供相同的两个选项:UI 和 SQL 语法。要在 UI 中删除表,只需选择要删除的表并选择"删除表"。由于这是一项永久性操作,因此系统会提示您在删除之前输入表名。
注意 −您还可以在 SQL 环境中删除表。
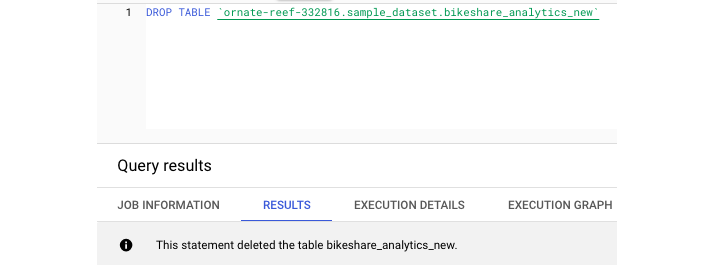
要仅删除表的内容并保留其中的数据,您可以使用需要 WHERE 子句的 DELETE 命令。
要删除任何不带参数的内容,您可以使用以下查询 −
DELETE FROM project.dataset.table WHERE 1=1
注意 −请谨慎使用此查询。
在 BigQuery 中恢复表
尽管删除过程分为两步,但仍然很有可能意外删除或删除表。因此,BigQuery 的创建者意识到可能需要为用户提供一种恢复过早删除的表的方法。
BigQuery 表快照
在 SQL 环境中创建和使用表时,这一点并不明显,但在后台,BigQuery 会自动保存您的工作 – 在一定程度上。
BigQuery 使用"快照"定期保存表,以便在需要时提供即时备份。需要注意的是,如果用户从快照中恢复表,他们实际上并没有恢复其原始表 – 他们只是恢复到表的快照或副本。
此工具并非没有限制。 BigQuery 表快照仅持续 7 天。因此,只能在初始删除后的 7 天内恢复已删除的表。
两种恢复表的方法
BigQuery 提供了两种恢复表的方法。顺便说一句,它们都不使用 BigQuery SQL。它们需要通过 gcloud 命令行 或通过 访问 API 以编程方式访问 BigQuery。任何一条语句都取决于选择要恢复到的快照的正确时间戳。
1. Gcloud Command
Here, the command "bq cp" is "bq copy". "No-clobber" is a parameter that will instruct the command to fail if a destination table does not already exist.
bq cp \ – restore \ – no-clobber \ –snapshot_project_id.snapshot_dataset_id.snapshot_table_id \ –target_project_id.target_dataset_id.target_table_id
2. Python 函数
理想情况下,开发人员将采取预防措施以避免需要恢复。但是,如果发生最坏的情况,BigQuery 会提供这种故障保护。
BigQuery - 填充表
首次学习 BigQuery 时,立即使用其功能并编写 SQL 查询 的最快方法之一是提供现有数据源。最容易上传和开始使用的数据源之一是静态文件。
BigQuery 中接受的文件类型
BigQuery 将从文件创建的任何表视为外部表。
BigQuery 接受来自 GCP 的 Google Cloud Storage 中的本地上传或云存储的文件输入。
接受的文件类型包括 −
- CSV(逗号分隔值)
- JSONL(换行符分隔的 JSON)
- Parquet
- Avro
- ORC
就像创建空表一样,要填充数据,必须指定架构。提醒一下,架构可以推断(自动生成),也可以在 UI 中提供,也可以作为 JSON 文件提供。
检查 BigQuery 是否支持数据类型
使用外部文件(尤其是 CSV)的挑战之一是 BigQuery 对某些数据类型有特殊要求。
在上传文件之前,最好检查 BigQuery 是否支持数据类型并相应地调整输入。例如,BigQuery 对如何提取时间戳数据非常讲究,希望每个值都有两个整数而不是一个整数,即使对于缩写日期也是如此。
BigQuery 如何避免文件上传错误?
开发人员在将文件加载到任何 SQL 表中时遇到的另一个挑战是存在特殊字符,例如换行符" "。虽然删除这些字符并通过编程充分清理数据始终是明智之举,但 BigQuery 提供了过滤或完全忽略可能导致文件上传错误的行的方法。
- 首先,BigQuery 允许开发人员指定一个整数值,表示允许的错误数。如果有一个特定的坏行不包含任何后续数据,这可能会很有帮助。
- 此外,BigQuery 提供了一个参数,用于跳过标题行,包括带引号的换行符以及允许锯齿状或格式错误的行。
不幸的是,即使有了这些选项,确定文件是否上传的唯一方法也只是反复试验。
BigQuery Studio:通过 SQL 语句填充表
根据情况,有两种方法可以从"头"填充表,即简单的 SQL 语句。
1. CREATE OR REPLACE 命令
第一个命令 CREATE OR REPLACE 已经介绍过了。在这种情况下,开发人员正在创建一个全新的表,并且除了表内容之外还必须定义表架构。通常,CREATE OR REPLACE 最适合在聚合或扩展 SQL 表中已存在的数据时使用。
2. INSERT 命令
如果您发现自己拥有一个表的"外壳",包括定义良好的架构,但尚未添加数据,并且您没有外部文件或 API 负载等源,则可以通过 INSERT 命令添加数据。
在这种情况下,要正确使用 INSERT,不仅需要定义列、类型和模式,还需要提供要插入的数据。
在 SQL 范围内定义数据涉及提供值和列别名。例如 −

3. UNION 命令
要添加多行,请使用 UNION 命令。对于不熟悉 UNION 的人来说,它类似于 Pandas 的 concat,本质上是将行条目"堆叠"在一起,而不是在公共键上进行连接。
有两种 UNION −
- UNION ALL
- UNION DISTINCT

为了确保使用 UNION 正确插入数据,必须确保数据类型彼此一致。例如,由于我为 station_id 提供了一个 STRING 值,因此我无法将以下行的类型更改为 INTEGER。

在专业环境中,INSERT 不用于一次插入一行。相反,INSERT 通常用于插入数据分区,通常按日期插入,即最近一天的数据。
从连接的工作表中填充表格
现在很明显,在 BigQuery 中查询与在本地环境中编写 SQL 不同,部分原因是开发人员能够将 BigQuery 数据与 GCP 的基于云的工具同步。最强大和最直观的集成之一是将 BigQuery 与 Google 表格结合使用。
探索外部表格源的下拉菜单将显示"表格",开发人员可以使用该源来填充表格数据。

Google 表格作为主要数据源
使用 Google 表格作为主要数据源非常有用,因为与静态 CSV 不同,表格是动态实体。这意味着对连接表格中的行所做的任何更改都将反映在关联的 BigQuery 表中 - 所有这些都是实时的。
要将 Google 表格连接到 BigQuery 表,请按照原始的创建表流程进行操作。您需要选择"驱动器"作为源,而不是选择从上传创建表。尽管 Google 表格是在表格 UI 中创建的,但它们存在于 Google Drive 中。
与 CSV 一样,连接表格必须具有定义的标题。但是,与 CSV 不同的是,开发人员可以指定要包含和省略的列。
语法类似于创建和执行 Excel 公式。只需输入列字母和行号即可。要选择给定行之后的所有行,请在列前面加上感叹号。
Like: !A2:M
使用相同的语法,您甚至可以在提供的工作表中选择不同的选项卡。例如 −
"Sheet2 !A2:M"
与使用 CSV 一样,您可以指定要忽略哪些行和标题,以及是否允许引用新行或锯齿行。
重要警告
INSERT 或 DROP 等 DML 语句不适用于连接的工作表。要省略某一列,您需要在工作表中隐藏它或在初始配置中指定它。
BigQuery 标准 SQL 与旧版 SQL
虽然 SQL 没有像 Python(或任何其他脚本语言)那样的底层依赖项,但您选择的 BigQuery SQL 版本存在差异。
由于 Google Cloud Platform 认识到开发人员熟悉不同的 SQL 方言,因此他们为那些可能习惯使用更传统或"旧版"SQL 版本的用户提供了选项。
标准 SQL 与旧版 SQL 之间的区别
标准 SQL 与旧版 SQL 之间的主要区别在于类型映射。虽然旧版 SQL 支持与通用数据类型更接近的类型,但标准 SQL 类型更特定于 BigQuery。例如,BigQuery 标准 SQL 支持的时间戳值范围要窄得多。
其他差异包括 −
- 使用反引号而不是括号来转义特殊字符。
- 表引用使用冒号而不是点。
- 不支持通配符。
在 BigQuery SQL 环境中在标准和旧版 SQL 之间切换很容易。在编写和执行 SQL 查询之前,只需在第 1 行添加注释:"#legacy"即可。
BigQuery 的标准 SQL 优势
与衍生的旧版 SQL 方言相比,标准 SQL 使 SQL 开发人员能够以更高的灵活性和效率编写查询。标准 SQL 通过提供在处理专业环境中遇到的"混乱"数据时有用的函数和框架,提供了更多"现实世界"实用性。
标准 SQL 有助于实现以下功能 −
- 更灵活的 WITH 子句,使用户能够在脚本中多次重复使用子查询和 CTE。
- 可以用 SQL 或 JavaScript 编写的用户定义函数。
- SELECT 子句中的子查询。
- 相关子查询。
- 复杂数据类型(ARRAY 和 STRUCT 类型)。
标准 SQL 与旧版 SQL 之间的不兼容性
通常,标准 SQL 与旧版 SQL 操作之间的不兼容性不会引发问题。但是,有一种情况适用于 AirFlow 用户。
如果使用 BigQueryExecuteQuery 运算符,则可以指定是否使用旧版 SQL。要使用标准 SQL,请设置 "use_legacy_sql = FALSE"。
但是,如果开发人员未能做到这一点并使用仅与标准 SQL 兼容的函数,如 TIMESTAMP_MILLIS()(时间戳转换函数),则整个查询可能会失败。
BigQuery - 编写第一个查询
可以在查询编辑器中打开一个空白页,但最好直接从表选择步骤编写第一个查询以避免语法错误。
要以这种方式编写第一个查询,请首先导航到包含您要查询的表的数据集。单击"查看表"。在上面的面板中,选择"查询"。按照此过程将打开一个新窗口,其中已填充表名以及创建者添加的任何限制。
例如,一个表可能需要一个 WHERE 子句,或者一个建议的查询可能会限制用户只能查询 1000 行。为了遵循最佳实践,请将" * "替换为您要查询的列的名称。

- 如果在 SELECT 中添加任何聚合,请注意包含 GROUP BY 子句
- 如果您想特别注意语法错误,还可以通过单击提供的架构中的列名来选择它们。
如果您按照这些步骤操作,则无需编写表名。但是,要养成制定正确表引用的习惯,请记住公式为:project.dataset.table。这些元素都括在反引号(而不是引号)中。
BigQuery Studio 的一个独特元素是 IDE 会告诉您查询是否会运行。这将通过绿色复选标记表示。

确认一切正确后,点击运行。查询运行时,您将看到执行指标,例如处理的数据、运行查询所需的时间和所需的步骤数。如果您查看底部面板,您还会看到运行所需的插槽(Slot)数量。

在 Cloud Shell 终端上编写您的第一个查询
与在 UI 中查询一样,在 Cloud Shell 终端中查询遵循类似的结构,并允许用户使用 SQL 语法访问和操作数据。
"bq"查询及其常用标志
使用命令 bq query,在 Cloud Shell 中编写和执行查询非常简单。在同一行中,用户可以提供指示执行某些方面的标志。
bq query 命令的一些更常见标志包括 −
- –allow-large-results(不会因结果过大而取消作业)
- –batch = {true | false
- –clustering-fields = [ ]
- –destination-table = table_name
您可能会注意到,所有这些参数都对应于在 UI 中创建表或运行查询时出现的下拉菜单。
要在 Cloud Shell 中运行查询 −
- 登录 GCP
- 进入 Cloud Shell 终端
- 身份验证(自动完成)
- 编写并执行查询
看起来像 −
(ornate-reaf-332816)$ bq query --use_legacy_sql=false \ 'SELECT * FROM ornate-reef-332816.sample_dataset.bikeshare_2022_stsore_date';
结果显示为终端输出。虽然结果不像 BigQuery UI 结果那样呈现,但输出仍然整洁且易于理解。
BigQuery - CRUD 操作
CRUD 代表 CREATE、REPLACE、UPDATE 和 DELETE,是基础 SQL 概念。与传统查询不同,传统查询只会在临时表中返回数据,运行 CRUD 操作,并且表的结构和架构会发生根本性变化。
CREATE OR REPLACE 查询
BigQuery 将 CRUD 的 C 和 R 与其语句 CREATE OR REPLACE 结合在一起。
CREATE OR REPLACE 可与 BigQuery 的各种实体一起使用,例如 −
- 表
- 视图
- 用户定义函数 (UDF)
使用 CREATE OR REPLACE 命令的语法是 −
CREATE OR REPLACE project.dataset.table
虽然创建操作将创建一个全新的实体,但 UPDATE 语句将在行(而非表)级别更改记录。
UPDATE 查询
与 CREATE OR REPLACE 不同,UPDATE 使用了另一种语法 SET。最后,UPDATE 必须与 WHERE 子句一起使用,以便 UPDATE 知道要更改哪些记录。
放在一起,看起来像这样 −

上述查询更新了表,但仅影响日期等于当前日期的行。如果是这种情况,它会将日期更改为昨天。

DELETE 命令
与 UPDATE 一样,DELETE 也需要 WHERE 子句。 DELTE 查询的语法很简单 −
DELETE FROM project.dataset.table WHERE condition = TRUE

ALTER 命令
除了 CRUD 语句之外,BigQuery 还有之前介绍的 ALTER 语句。提醒一下,ALTER 用于 −
- 添加列
- 删除列
- 重命名表
谨慎使用这些函数,尤其是在处理生产数据时。
BigQuery - 分区和聚类
由于本教程中已经使用了"分区"和"聚类",因此提供更多背景信息会很有帮助。
什么是分区和聚类?
这两个术语用于描述优化数据存储和处理的两种方法。
分区是开发人员对数据进行分段的方式,通常(但并非总是)按日期元素(如年、月或日)进行分段。聚类描述了数据在指定分区内的排序方式。
要使用任一存储方法,您必须定义所需的字段。只有一个字段可用于分区,但多个字段可用于聚类。
需要注意的是,要应用分区或聚类,您必须在构建的"创建表"阶段执行此操作。否则,您将需要使用更新的分区/聚类规范删除/重新创建表。
如何对表应用分区或聚类
要在创建表时对表应用分区和/或聚类,请运行以下命令 −
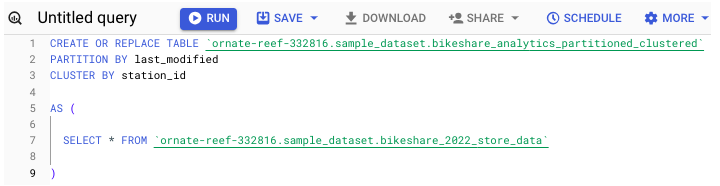
您也可以在 UI 中指定这些说明。在点击"创建表"之前,请花点时间填写架构创建框正下方的字段。
如果正确应用分区/聚类,它可以显著减少长期存储成本和处理时间,尤其是在查询大型表时。
BigQuery - 数据类型
在加载和查询数据时,了解 BigQuery 的数据类型用法和解释至关重要。如架构章节中所示,加载到 BigQuery 中的每个列都必须具有已定义的可接受类型。
BigQuery 接受其他 SQL 方言使用的许多数据类型,并且还提供 BigQuery 独有的数据类型。
跨 SQL 方言的常见数据类型
跨 SQL 方言的常见数据类型包括 −
- STRING
- INTEGER
- FLOAT
- BOOLEAN
BigQuery 还支持特殊数据类型,例如 JSON 数组,这将在后面的章节中讨论。
注意 − 如果在加载过程中未提供架构或未指定类型,BigQuery 将推断类型。不过,对于依赖不可预测的上游数据的集成来说,这不一定是一个积极的结果。
与分区和聚类列一样,类型必须在创建表时指定。
使用 CAST() 函数更改类型
可以在查询中更改类型(临时或永久)。为此,请使用 CAST() 函数。CAST 使用以下语法 −
CAST(column_name AS column_type)
例如 −
CAST(id AS STRING)
就像指定错误的类型一样,尝试强制 CAST 不兼容的类型可能会令人沮丧并导致基础设施中断。
对于转换类型的更可靠方法,请使用 SAFE_CAST(),它将为不兼容的行返回 NULL,而不是完全破坏 −
SAFE_CAST(id AS STRING)
对 BigQuery 如何解释给定输入的类型有扎实的理解对于创建强大的 SQL 查询至关重要。
BigQuery 数据类型 STRING
在 SQL 开发人员使用的最常见数据类型中,STRING 类型BigQuery 通常很容易识别。但是,字符串的操作或解释偶尔会出现一些怪癖。
通常,字符串类型由字母数字字符组成。虽然字符串类型可以包含整数类数字和符号,但如果指定类型为 STRING,则此信息将像常规字符串一样存储。
新开发人员遇到的一个棘手情况是处理包含带符号的 INTEGER 或 FLOAT 值的行,例如货币的情况。
虽然可能会因为小数点而假设 $5.00 是 FLOAT,但美元符号使其成为字符串。因此,在加载带有美元符号的行时,BigQuery 会期望它在您的架构中定义为 STRING 类型。
DATE 数据类型
STRING 类型的一个子集是 DATE 数据类型。
- 尽管 BigQuery 对日期值有自己的指定,但日期值本身默认表示为字符串。
- 对于使用 Python 中的 Pandas 的人来说,这类似于日期字段在数据框中表示为对象的方式。
- 有各种专用于解析 STRING 数据的函数。
STRING 函数
值得注意的 STRING 函数包括 −
- LOWER() −将字符串中的所有内容转换为小写
- UPPER() − lower 的逆操作;将值转换为大写
- INITCAP() − 仅将每个句子的首字母大写;即句子大小写
- CONCAT() − 组合字符串元素
重要的是,BigQuery 中的数据类型默认为 STRING。除了常规字符串元素外,这还包括开发人员未指定 REPEATED 模式的列表。
INTEGER 和 FLOAT
如果您在企业(业务)规模上使用 BigQuery,则很可能会处理涉及数字的数据。这可能是从出勤数据到营业收入的任何数据。
无论如何,STRING 数据类型对于这些用例没有意义。这不仅是因为这些数字没有美元符号或欧元等货币符号,还因为要生成有用的见解,它需要利用特定于数字数据的函数。
注意 INTEGER 和 FLOAT 之间的区别标记很简单:"。"
在许多 SQL 方言中,当涉及到指定数值时,开发人员需要告诉 SQL 引擎需要多少位数字。这就是传统 SQL 获得 BIGINT 等名称的地方。
BigQuery 将 FLOAT 类型编码为 64 位实体。这就是为什么当您将列 CAST() 为 FLOAT 类型时,您会这样做 −
CAST(column_name AS FLOAT64)
值得注意的 INTEGER 和 FLOAT 函数
其他值得注意的 INTEGER 和 FLOAT 函数包括 −
- ROUND()
- AVG()
- MAX()
- MIN()
注意事项
FLOAT 类型的一个重要警告是,除了指定句点分隔的数字外,FLOAT 类型也是 NULL 的默认类型。
如果使用 SAFE_CAST(),最好包含额外的逻辑以将任何返回的 NULL 值从 FLOAT 转换为所需的类型。
BigQuery - 复杂数据类型
BigQuery 除了支持"常规"数据类型(如 STRING)之外, INTEGER 和 BOOLEAN 还支持所谓的复杂数据。通常,这也被称为嵌套数据,因为数据不适合传统的平面表,必须存在于列的子集中。
复杂数据结构很常见
对嵌套架构的支持允许更简化的加载过程。尽管 Google Cloud 将以下数据类型的各种教程列为"高级",但嵌套数据非常常见。
了解如何扁平化和使用这些数据类型对于任何面向 SQL 的开发人员来说都是一项有用的技能。
这些数据结构很常见的原因是源数据(如 API 的 JSON 输出)通常以这种格式返回数据 −
[{data: "id": '125467", "name": "Acme Inc.", "locations":
{"store_no": 4, "employee_count": 15}}]
- 请注意"id"和"name"都处于同一引用级别。可以使用"data"作为键来访问它们。
- 但是,要获取"store_no"等字段和"employee_count",不仅需要访问数据键,还需要展平"locations"数组。
这就是 BigQuery 的复杂数据类型支持有用的地方。数据工程师无需编写脚本来迭代和取消嵌套"locations",而是可以将这些数据按原样加载到 BigQuery 表中。
BigQuery 中的复杂数据结构
BigQuery 支持以下三种类型的复杂或嵌套数据 −
- STRUCT
- ARRAY
- JSON
处理这些类型的策略将在下一章中解释。
BigQuery - STRUCT 数据类型
STRUCT 和 ARRAY 是开发人员在 BigQuery 的列式结构中存储嵌套数据的方式。
什么是结构?
STRUCT 是具有指定类型(必需)和字段名称(可选)的字段集合。值得注意的是,与 ARRAY 不同,STRUCT 类型可以包含多种数据类型。
为了更好地理解 STRUCT 类型,请再看一下上一章中的示例,现在有一些变化。
"locations": [
{"store_no": 4, "employee_count": 15, "store_name": "New York 5th Ave"},
{"store_no": 5, "employee_count": 30, "store_name": "New York Lower Manh"}
]
虽然以前"locations"是相同类型的dict(以 JSON 表示),但现在它包含两个类型为 <INTEGER, INTEGER, STRING> 的 STRUCT。
- 尽管支持 STRUCT 类型,但 BigQuery 在表创建阶段没有可用的明确标签 STRUCT。
- 相反,STRUCT 被指示为具有 NULLABLE 模式的 RECORD。
注意 − 将 STRUCT 视为容器而不是专用数据类型。
在架构中定义时,STRUCT 内的元素将用"。"表示和选择。此处,模式 应为 −
{"locations", "RECORD", "NULLABLE"},
{"locations.store_no", "INTEGER", "NULLABLE},
{"locations.employee_count", "INTEGER", "NULLABLE"},
{"locations.store_name", "STRING", "NULLABLE"}
点符号
要选择 STRUCT 元素,必须在 FROM 子句中使用 点符号 −

执行查询时,您可能会得到如下 输出 −
BigQuery - ARRAY 数据类型
与允许包含不同类型的数据的 STRUCT 类型不同,ARRAY 数据类型必须包含相同类型的元素。
- 在 Python 等编程语言中,ARRAY(也称为列表)用括号表示:[ ]。
- STRUCT 类型可以包含其他结构(以创建高度嵌套的数据),ARRAY 不能包含另一个 ARRAY。
- 但是,ARRAY 可以包含 STRUCT,因此开发人员可能会遇到嵌入了多个 STRUCT 的 ARRAY内。
BigQuery 不会将列标记为显式 ARRAY 类型。相反,它会以不同的模式表示。虽然常规 STRING 类型具有"NULLABLE"模式,但 ARRAY 类型具有"REPEATED"模式。

可以使用点选择 STRUCT 类型,但是 ARRAY 类型在表面级操作方面受到更多限制。
可以选择 ARRAY 作为分组元素:

但是,使用点或任何其他方法选择数组元素是不可能的,因此这不起作用 −

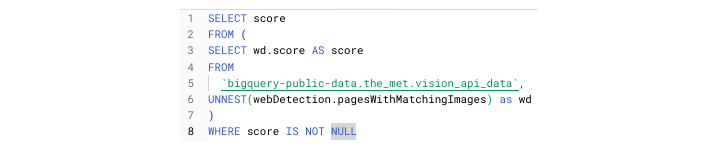
UNNEST() 函数
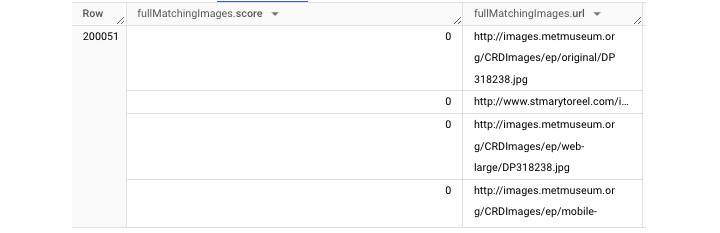
要从 store_information 中访问名称,必须执行一个额外的步骤:UNNEST(),该函数将扁平化数据,使其更易于访问。
UNNEST() 函数在 FROM 子句中与逗号一起使用。上下文:逗号代表隐式 CROSS JOIN。
要正确访问此 ARRAY,请使用以下查询 −
它将为您获取一个 输出 表,如下所示 −
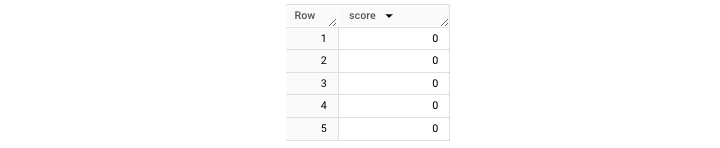
除了使用 UNNEST(),还可以为记录设置别名。然后可以使用生成的别名 "wd" 来访问未嵌套的数据。
BigQuery - JSON 数据类型
JSON 是 BigQuery 支持的最新数据类型。与 STRUCT 和 ARRAY 类型不同,JSON 相对容易识别。
对于使用脚本语言处理数据或解析过 API 响应的开发人员来说,JSON 数据会很熟悉。
JSON 数据用大括号表示:{ },类似于 Python 字典。
注意 −在 BigQuery 引入对 JSON 类型的支持之前,JSON 对象需要表示为具有 NULLABLE 模式的 STRING。
开发人员可以在 UI 和基于文本的架构定义中指定 JSON −
不将 JSON 数据存储为 JSON 类型并不一定会导致加载失败,因为 BigQuery 可以支持 JSON 数据的 STRING 类型。
但是,不正确存储 JSON 数据意味着开发人员无法访问强大的 JSON 特定功能。
强大的 JSON 函数
得益于内置函数,在 BigQuery 中使用 JSON 数据的开发人员无需编写脚本来扁平化 JSON 数据。相反,他们可以使用 JSON_EXTRACT 提取 JSON 对象的内容,然后处理和操作结果数据。
其他强大的 JSON 函数包括 −
- JSON_EXTRACT_ARRAY()
- PARSE_JSON()
- TO_JSON()
能够准确直观地在 BigQuery 中查询 JSON 数据,开发人员无需使用复杂的 CASE 逻辑或编写自定义函数来提取有价值的数据。
BigQuery - 表元数据
虽然能够分析和理解组织数据的范围和内容很重要,但对于 SQL 开发人员来说,了解使用 BigQuery 的性能和存储成本方面也是必不可少的。
这是在查询 BigQuery 时表元数据对开发人员很有用,对于寻求充分利用 SQL 引擎的组织来说更是无价之宝。
对于那些没有广泛使用元数据的人来说:元数据,顾名思义,就是关于数据的数据。通常,这与资源性能或监控等统计数据有关。
BigQuery 提供多个元数据存储,用户可以查询这些元数据存储以更好地了解他们的项目如何消耗资源,其中一些元数据存储包括以下内容 −
- INFORMATION_SCHEMA
- __TABLES__ 视图
- BigQuery 审核日志
这些表中的每一个都可以像存储数据一样进行查询。
对于 INFORMATION_SCHEMA 和 __TABLES__,请注意表引用的语法不同。
INFORMATION_SCHEMA 和 __TABLES__ 都不遵循典型的:project.dataset.table 表示法,而是都在结束反引号后引用元素。
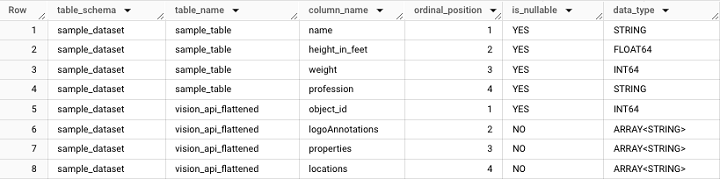
INFORMATION_SCHEMA 是一个数据源,它有几个分支资源,如 COLUMNS 或 JOBS_BY_PROJECT
例如,引用 INFORMATION_SCHEMA 如下所示 −

它将获取以下输出 −
TABLES 视图
TABLES 视图提供表级别的信息,例如表创建时间和最后访问表的用户。值得注意的是,TABLES 视图可在数据集级别访问。

它将获取以下输出 −
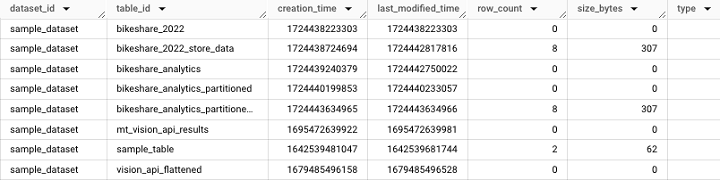
基于现有表创建模式
INFORMATION_SCHEMA.COLUMNS 的一个有用用例是能够使用此查询基于现有表创建模式 −

BigQuery - 用户定义函数
BigQuery 的优势之一是能够创建自定义逻辑来操作数据。在 Python 等编程语言中,开发人员可以轻松编写和定义可在脚本中多个位置使用的函数。
BigQuery 中的持久用户定义函数
许多 SQL 方言(包括 BigQuery)都支持这些函数。BigQuery 将它们称为持久用户定义函数。它们要么是 UDF(用户定义函数),要么是 PUDF(持久性用户定义函数)。
用户定义函数的本质可以分为两个步骤 −
- 定义函数逻辑
- 在脚本中使用函数
定义用户定义函数
定义用户定义函数从一个熟悉的 CRUD 语句开始:CREATE OR REPLACE。
在这里,需要使用 CREATE OR REPLACE FUNCTION,而不是 CREATE OR REPLACE TABLE,然后使用 AS() 命令。
与可以在 BigQuery 中编写的其他 SQL 查询不同,创建 UDF 时需要指定输入字段和类型。
这些输入的定义方式类似于Python 函数 −
(column_name, type)
为了将这些步骤放在一起,我创建了一个简单的临时 UDF,由 TEMP FUNCTION 指定,该函数根据用户输入解析各种 URL。
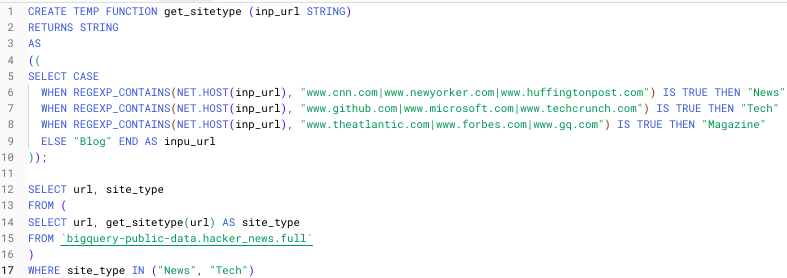
创建上述临时函数的步骤如下 −
- 创建临时函数
- 指定函数名称 (get_sitetype)
- 指定函数输入和类型 (inp_url, STRING)
- 告诉函数要返回什么类型 (STRING)
REGEXP_CONTAINS() 函数在包含所提供 URL 字符串的字符串中搜索匹配项。 NET.HOST() 函数从输入的 URL 字符串中提取主机域。
将其应用于黑客新闻数据集(BigQuery 公共数据集),我们可以生成一个 输出,将存储的 URL 分类为不同的媒体类别 −
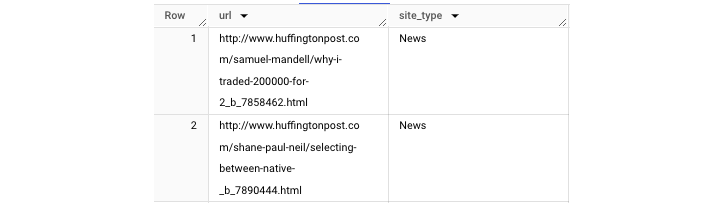
注意 −临时函数后面必须紧跟查询。
BigQuery - 连接到外部源
虽然到目前为止,本教程的大部分内容都涉及 UI 和云终端,但现在是时候探索通过外部源连接到 BigQuery 了。
在 UI 中编写查询的局限性
尽管在 BigQuery Studio 中编写查询可能很方便,但事实是,这只能满足有限的目的 −
- 最初开发 SQL 查询或脚本
- 调试查询
- 进行抽查或质量保证
简单地在 UI 中编写和运行查询并不能帮助提供自动化数据解决方案。这意味着在 BigQuery SQL 环境中,您无法 −
- 访问 BigQuery API
- 与 Airflow 集成
- 创建 ETL 管道
外部 BigQuery 集成
在接下来的章节中,我们将探讨如何将 BigQuery 与其集成 −
- BigQuery 计划查询
- BigQuery API (Python)
- Cloud Composer / Airflow
- Google Sheets
- BigQuery 数据传输
外部 BigQuery 集成使开发人员能够利用 SQL 的强大功能执行以下任务 −
- 创建自动提取加载 (EL)
- 提取转换加载 (ETL)
- 提取加载转换 (ELT)作业
BigQuery - 集成计划查询
除了是与 BigQuery 最直观的外部集成(外部集成,因为该机制依赖于 BigQuery 数据传输服务)之外,计划查询还可以从 BigQuery Studio 进行安排。
如果您愿意,也可以导航到侧边栏上的"计划查询"。但是,即使是这个页面也会提示您"创建查询",然后返回 UI。因此,最好通过 − 从 UI 创建和安排查询
- 在 SQL 工作区中编写查询。
- 验证并运行查询(查询只有在有效的情况下才会运行或安排)。
- 选择"安排查询",这将打开一个下拉菜单。
进入"安排查询"菜单后,您必须填写 −
- 查询的名称
- 计划频率
- 开始时间
- 结束时间
如果您不填写结束时间,查询将永久按照其指定的计划运行。
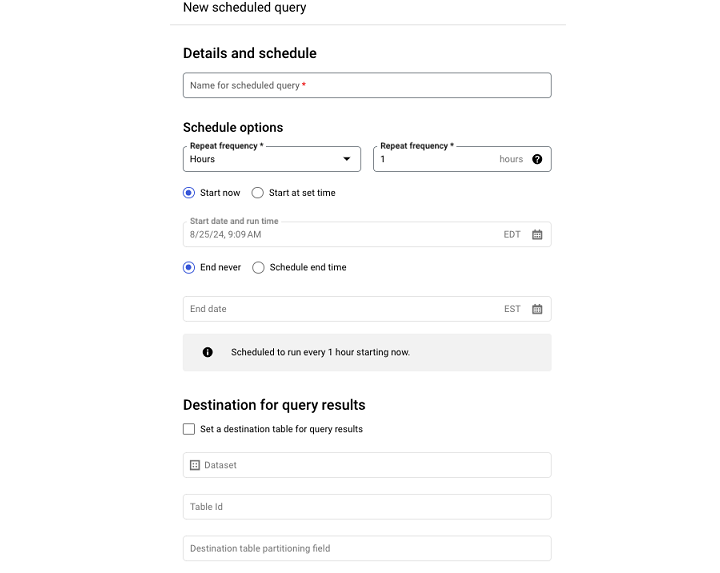
注意 −关于计划查询的一个警告是,一旦计划了查询,查询运行参数的某些方面(例如与查询关联的用户)就无法在 UI 中更改。
为此,需要通过 BigQuery API 或命令行访问计划查询。
集成 BigQuery API
BigQuery API 允许开发人员利用 BigQuery 的处理能力和 Google SQL 数据操作功能来执行重复任务。
BigQuery API 是一个 REST API,支持以下语言 −
由于 Python 是数据科学和数据分析最流行的语言之一,本章将在 Python 环境中探索 BigQuery API。
BigQuery API 部署选项
就像开发人员不能直接部署 SQL 一样从 BigQuery Studio 开始,对于生产工作流,访问 BigQuery API 的代码必须通过相关的 GCP 产品进行部署。
部署选项包括 −
- Cloud Run
- Cloud Functions
- 虚拟机
- Cloud Composer (Airflow)
BigQuery API 需要身份验证
使用 BigQuery API 需要身份验证 −
- 如果在本地运行脚本,则可以下载与运行 BigQuery 的服务帐户关联的凭据文件,然后将该文件设置为环境变量。
- 如果在连接到云的环境中运行 BigQuery,例如在 Vertex AI 笔记本中,则会自动进行身份验证。
为避免下载文件,GCP 还支持大多数应用程序的 Oauth2 身份验证 流程。
经过身份验证后,典型的 BigQuery API 用例包括 −
- 运行包含给定表的 CRUD 操作的 SQL 脚本。
- 检索项目或数据集元数据以创建监控框架。
- 运行 SQL 查询以使用来自其他来源的数据合成或丰富 BigQuery 数据。
".query()"方法
毫无疑问,最流行的 BigQuery API 方法之一是 ".query() 方法"。与 Pandas 的 .to_dataframe() 搭配使用时,它提供了一个强大的选项,可以以可读的形式查询和显示数据。
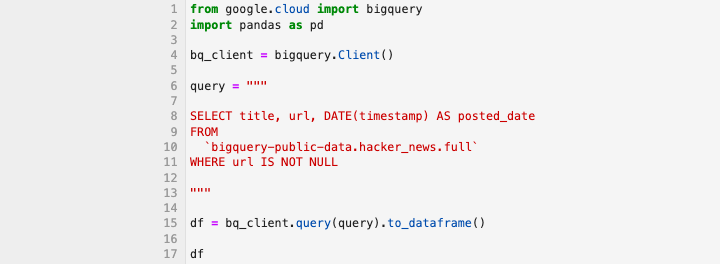
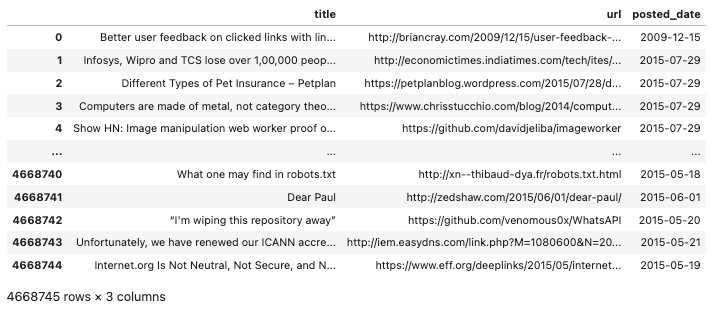
此查询应获取以下 输出 −
BigQuery API 不是黑匣子。除了日志记录(使用 Google Cloud Logging 客户端)之外,开发人员还可以在 UI 中查看按个人用户和项目级别细分的实时作业信息。要解决任何失败的作业问题,这应该是您的第一站。
BigQuery - 集成 Airflow
运行 Python 脚本来加载 BigQuery 表对单个作业很有帮助。但是,当开发人员需要创建多个连续任务时,孤立的解决方案并不是最佳选择。因此,有必要超越简单的执行。编排是必需的。
BigQuery 可以与几种流行的编排解决方案集成,如 Airflow 和 DBT。但是,本教程将重点介绍 Airflow。
有向丙烯酸图 (DAG)
Apache Airflow 允许开发人员创建称为有向丙烯酸图 (DAG) 的执行块。 每个 DAG 都由许多任务组成。
每个任务都需要一个运算符。有两个重要的 BigQuery 兼容运算符 −
- BigQueryCheck 运算符
- BigQueryExecuteQuery 运算符
BigQueryCheck 运算符
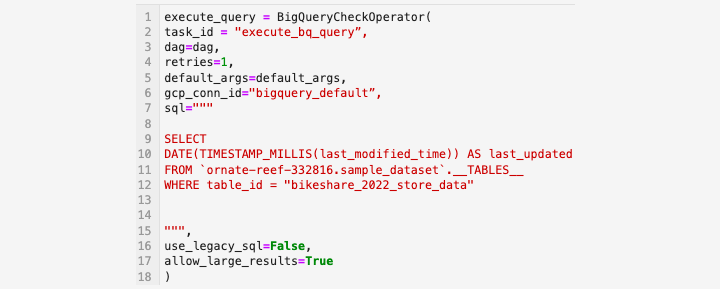
BigQueryCheckOperator 允许开发人员进行上游检查,以确定当天的数据是否已更新。
如果表的架构中没有包含上传时间戳,则可以查询元数据(如前所述)。
开发人员可以通过运行此查询的版本来确定表的上次更新时间 −

BigQueryExecuteQuery 运算符
要执行依赖于上游数据的 SQL 脚本,SQL 开发人员可以使用 BigQueryExecuteQuery 运算符 创建加载作业。
对 Airflow 的更深入解释超出了本教程的范围,但 GCP 为想要了解更多信息的人提供了大量文档。
BigQuery - 集成连接工作表
对于那些选择使用 BigQuery 等云服务作为 数据仓库,将数据从电子表格迁移到数据库通常是一个目标。因此,将数据仓库和电子表格配对似乎有些多余。
但是,将 Google Sheet 连接到 BigQuery 可以无缝地重复"刷新"电子表格数据,因为源是 BigQuery 中的视图或表。
Google Sheets 以两种方式支持 BigQuery 集成 −
- 直接连接到表。
- 连接到自定义查询的结果。
与 BigQuery 不同,BigQuery 在下拉菜单中显示可用的外部数据源,而在 Google Sheets 中查找数据源需要进行一些挖掘。
将 BigQuery 资源连接到 Google Sheets
要将 BigQuery 资源连接到 Google Sheets,请按照以下步骤 −
- 打开新的 Google Sheet
- 单击"数据"选项卡
- 在数据下,导航到数据连接
- 选择现有数据集
- 找到所需的表
- 或者,编写自定义查询
- 单击连接
工作表应从标准电子表格更改为类似于电子表格和 SQL 表混合的 UI。
如何确保同步和安排刷新?
虽然遵循这些步骤可确保连接处于活动状态,但在此处停止并不能确保将来的同步。
- 要自动更新工作表,因为其关联资源已更新,您必须安排刷新。
- 您可以通过导航到"连接设置"来安排刷新。
- 与配置计划查询一样,安排刷新也很简单。选择刷新间隔、开始时间和结束时间。
配置完成后,工作表将按照该计划进行更新,假设数据在 BigQuery 表中可用。
BigQuery - 集成数据传输
BigQuery 数据传输有助于同步来自 Google 关联产品的数据,并将生成的负载导入 BigQuery。由于这些数据传输是在 Google 产品之间进行的,因此它们基于现成的报告。
在配置期间,用户可以选择他们想要导入的报告。不幸的是,这意味着没有上游定制的空间。
虽然担心给定的报告没有特定字段可能是直觉的,但事实往往相反。 Google 的报告通常包含大量数据,因此有必要构建视图以仅提取与您的用例相关的信息。
数据传输需要身份验证
与其他 BigQuery 集成一样,数据传输需要身份验证。
- 幸运的是,由于传输最初是在 UI 中配置的,因此它是一个简单的身份验证流程。
- 使用 Oauth2,设置 BigQuery 传输的用户需要登录并验证连接到 Google Cloud Platform 的帐户。
- 通过身份验证后,开发人员可以从 Google 产品和报告类型下拉列表中进行选择。
为了便于使用结果数据,该过程最重要的方面之一是提供一个令人难忘的名称作为结果表的后缀。
注意 −有些报告(例如账单报告)不允许用户更改所提取表的名称。
报告示例
可以安排为数据传输的报告示例包括 −
- DFP
- Google Ad Manager
- YouTube 频道报告
这些开箱即用的报告可以消除某些与 BigQuery 兼容的数据资源的开发负担。
BigQuery - 物化视图
除了创建表和视图之外,BigQuery 还有助于创建物化视图。
什么是物化视图?
物化视图类似于表,因为它是数据的"快照"。但是,物化视图的不同之处在于,真正的物化视图将动态更新 - 所有这些都无需运行查询。
物化视图的类型
广义上,有两种物化视图 −
- 已保存为表并将从外部源定期更新的视图。
- 在 BigQuery Studio 中创建的"真正"物化视图。
以下是第一种视图的示例架构 −
- SQL 查询现有视图
- 在 Python 脚本中,该视图将转换为数据框
- 数据框将上传到 BigQuery
- 物化视图将被附加或覆盖
由于上述内容概述了一个多步骤流程,BigQuery 简化了物化视图的创建和维护。
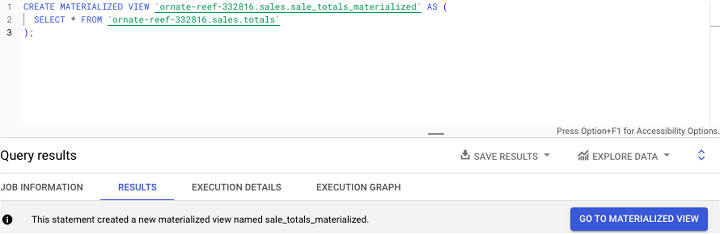
创建 BigQuery 物化视图
用户可以通过运行 CREATE MATERIALIZED VIEW SQL 语句,然后运行来创建 BigQuery 物化视图 −
- 项目
- 数据集
- 新 mv 名称
- SQL 语句
示例
以下是具有假设的现有表的示例销售数据已物化 −
请注意以下限制,根据 BigQuery 文档 −
- 每个表在数据集内限制为 20 个物化视图
- 一个项目内只能有 100 个物化视图
- 一个组织内只能有 500 个物化视图
在 BigQuery 中编写一个简单的 SQL 脚本
现在把所有东西放在一起,是时候编写一个简单的脚本了 −
- 利用动态变量
- 删除昨天的数据
- 将新数据插入表中
- 使用查询选择/加载数据
到目前为止尚未涉及的一个领域是如何在 SQL 脚本中定义和使用变量。
在 BigQuery 中,变量语法如下。 −
DECLARE variable_name TYPE DEFAULT function used to create dynamic variable
作为示例 −
DECLARE 昨天 DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
我们将这样开始以下脚本,该脚本从 Austin bike share 分区表中删除以前的数据并仅插入最新数据。
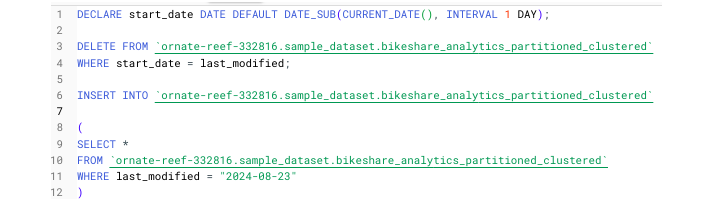
在 BigQuery 中运行此脚本时,由于有分号,SQL 引擎将分阶段运行。单击"查看结果"即可查看最终结果。
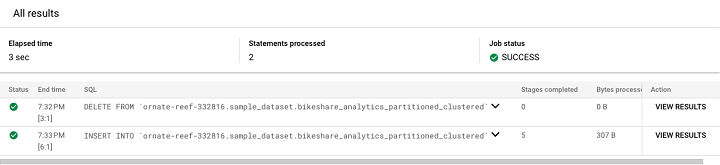
单击"查看结果"会生成此输出。

最后,我们可以看到添加到表中的新行。
BigQuery - 角色和权限
在 BigQuery Studio UI 中运行查询看似无缝。由于开发人员已登录其 Google Cloud Platform 帐户,因此无需进行身份验证。然而,在幕后,某些限制和防护措施确保开发人员只能在项目中执行某些操作。
身份访问和管理 (IAM) 角色
这些限制或指定称为角色和权限。在 GCP 中,这些称为身份访问和管理 (IAM) 角色。
广义上,这些角色分为 3 个层级 −
- BigQuery 管理员
- BigQuery 数据编辑者
- BigQuery 用户
1. BigQuery 管理员
BigQuery 管理员可以在项目中执行任何操作,例如创建或删除表以及启动和停止正在运行的作业(即使是由其他用户发起的作业)。
2. BigQuery 数据编辑者
BigQuery 数据编辑者的权限略少。虽然他们可以读取、更新和删除表或视图,但他们缺乏项目级别的控制和权限,无法控制其他用户的作业。
3. BigQuery 用户
BigQuery 用户是 BigQuery IAM 角色中最低级别的角色。在访问和操作资源方面,他们的能力极其有限。他们有限的能力包括:列出表和访问元数据。
自己使用 BigQuery 不需要了解任何这些角色或权限。但是,当您处理企业级数据时,了解角色和权限可以帮助加速解决访问问题或在配置服务帐户时派上用场。
BigQuery:策略标签和PII
就像 BigQuery 管理员可以向具有较低级别访问权限的用户授予权限并施加影响一样,他们也可以控制个人可以查看和交互的数据。这可以使用策略标签来实现。
什么是策略标签?
策略标签本质上是组织数据的审查栏。管理员可以应用此标签来阻止组织内的用户访问敏感数据。虽然确定敏感数据的某些方面是主观的,但也有一个客观的定义。
什么是个人身份信息 (PII)?
在数据治理中,敏感数据称为个人身份信息 (PII)。PII 包括可用于立即和密切识别特定个人的任何属性。它包括以下信息 −
- 电话号码
- 生物识别信息
- 电子邮件
- 社会安全号码(美国)
- 信用卡号码
以上任何一项都被视为极其敏感的信息,必须小心保护。为了指导保护,GCP 在其数据治理产品数据丢失预防的文档中确定了 150 多个 PII 属性。
可以配置策略标签
还可以发布策略标签来保护组织免受不应访问业务关键信息(如收入数据)的内部用户的侵害。
可以通过 − 在 BigQuery 中配置并应用策略标签
- 选择表格
- 点击"编辑架构"
- 选择可能包含敏感信息的所有列
- 应用配置的策略标签
开发人员可以知道何时应用了此类标签,因为它将显示为表架构中字段名称旁边的灰色框。

BigQuery - 查询优化
BigQuery 由云计算提供支持,但这并不意味着计算能力是无限的。这也并不意味着每个查询都会运行完全相同的时间长度,无论一天中的什么时间或有多少进程在竞争时隙。
什么是查询优化?
优化是一个流行词,经常被数据工程和其他编程学科的人使用。
对于SQL,优化有两种形式 −
- 基于代码的优化
- 基于平台的优化
基于代码的优化在概念化和执行方面很复杂。因此,它超出了本教程的范围。相反,我们将专注于 BigQuery 中的工具,使用户能够准确跟踪和主动抑制过度使用。
通过提高可见性和创造性的插槽(Slot)分配,可以维护具有多个用户的 BigQuery 项目,并为所有用户提供足够的存储空间和插槽(Slot)空间。−
- 通过执行图和数据沿袭工具跟踪使用情况。
- 以不同的模式运行查询以减少在给定时间内处理的数据量。
- 利用 BI Engine 等工具对重复违规者(表)进行细分,以主动限制在高流量时段处理的数据范围。
批处理与交互模式
在 BigQuery Studio SQL 环境中编写前几个查询时,似乎所有查询都以相同的方式运行。而且,从某种意义上说,你是对的。所有查询都会使用一定数量的插槽(Slot)位,以执行期间的插槽(Slot)位小时数表示。但是,实际上有两种不同的方法来运行 BigQuery 查询以节省处理和成本。
大多数 BigQuery 查询都是在所谓的交互模式下执行的。事实上,这是 BigQuery 查询的默认执行状态。并且 UI 不会使更改模式的功能可见或明显。要查看或更改查询的执行模式,需要导航到查询设置。
进入该视图后,您可以配置下一次查询运行。除了选择查询模式外,开发人员还可以选择如何保存查询结果,显示的选项包括临时表、新 BigQuery 表或覆盖现有表的内容。这些选项下方是用于选择批处理与交互式的菜单。
虽然交互模式可以立即执行查询,但批处理模式允许用户 −
- 将所需的 BigQuery 作业加入队列。
- 运行优先级较低的查询,而不会影响优先级较高的作业(可能消耗更多资源)。
运行批处理模式作业可帮助用户规避 BigQuery 查询执行限制:用户最多可以运行 20 个并发查询。
如果批处理作业与正在进行的交互式作业争夺插槽(Slot),则批处理作业将被搁置或"排队",直到有可用空间。这有助于节省资源并避免达到对交互式查询施加的硬性速率限制。
BigQuery - BI Engine
除了 BigQuery 中的优化设置外,BigQuery 还提供并发服务 BI Engine,其目的是扫描和优化 BigQuery 查询性能。
- BI Engine 是一种内存服务,可分析正在运行的作业范围与执行时可用的插槽(Slot)数量和计算资源。
- BI Engine 不仅分析查询资源,还在分配可用资源后主动加速其执行(因此称为"引擎")。
- BI Engine 是可配置和可定制的,这意味着开发人员可以选择在其范围内包含哪些表和视图。
- BI Engine 是 BigQuery 中的一款产品。要访问 BI 登陆页面,只需在 Cloud Console 搜索栏中搜索"BI Engine"即可。
BI Engine 页面将提示您创建预留。
单击"创建预留"后,您将能够配置要在 BI Engine 范围内设置的 GB 数,并添加要包含在 BI Engine 性能优化功能范围内的表。
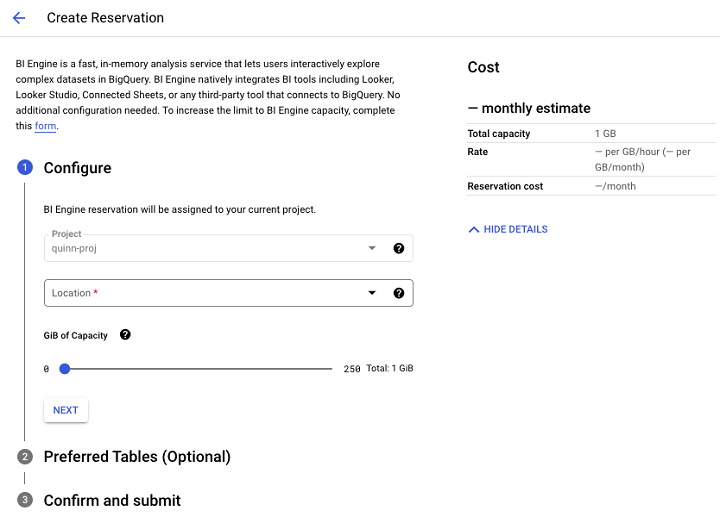
BI Engine 的查询加速
此外,BI Engine 与 BigQuery API 同步,为从中加载、更新或修改的表提供查询加速优势自动化流程。
BI Engine 的最大成就是矢量化运行时,这使其能够利用云 CPU 并使其能够压缩数据以实现无缝运行。
BI Engine 的真正强大之处在于它能够与 BigQuery 相邻的平台和应用程序集成。例如,基于 BigQuery 查询创建数据的 Looker 仪表板将有资格获得BI Engine 加速。
BI Engine 的用例
BI Engine 最有利于拥有经常查询的大量数据表的用户。
BI Engine 用例包括 −
- 由 BigQuery 提供支持的资源密集型可视化。
- 您有特定的大型且经常查询的表。
- 多个用户在相似的时间查询资源并导致性能日志堵塞。
无论如何,对于任何寻求提高流程效率和减少计算密集度的用户来说,BI Engine 仍然是一个强大的优化策略。
BigQuery - 监控使用情况和性能
了解使用情况和性能限制至关重要,尤其是对于在组织内工作的人来说。保持对消耗过多时隙时间的用户和数据源的持续可见性可以帮助 BigQuery 管理员做出明智的决定,限制对资源的访问,并在运行资源密集型作业的团队之间产生富有成效的对话。
性能仪表板
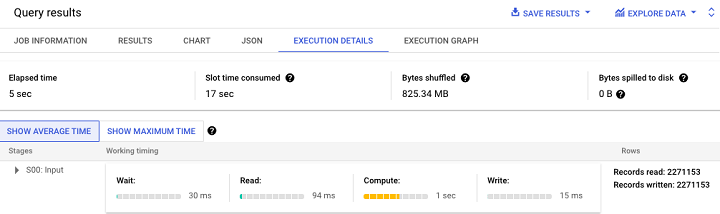
为了实现更透明的实时监控,BigQuery 在 BigQuery Studio UI 中的监控选项卡中提供了性能仪表板。
注意 −每次执行查询时,都会绘制性能图表。
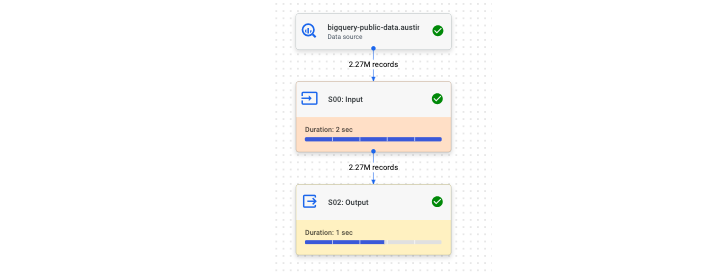
此外,BigQuery 还提供了执行图,以便更直观地解释查询性能。
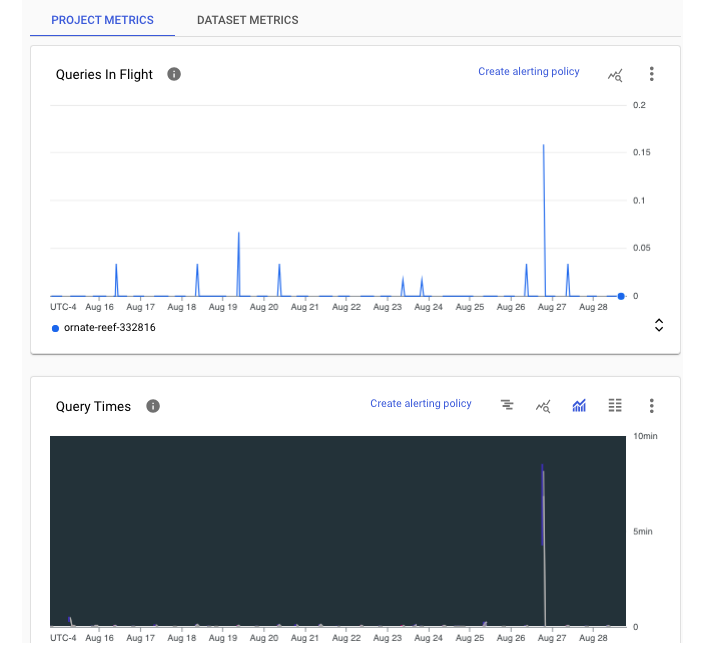
在项目级别,管理员可以在"监控"仪表板中查看 BigQuery 数据。监控可在项目级别和数据集级别进行。
项目级别监控
项目级别显示当前正在运行或"正在进行"的查询数。
数据集级别监控
在数据集级别,我们可以看到每个表存储的字节数。
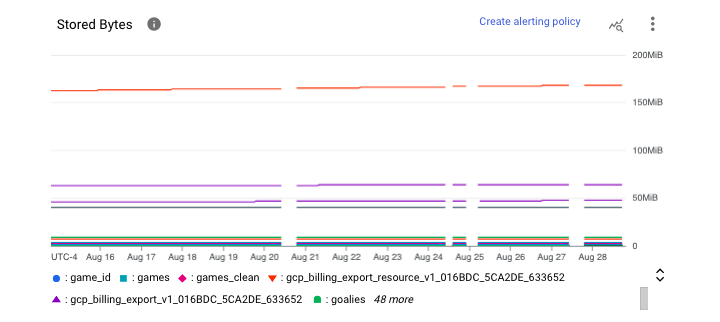
要访问和操作这些图表,请按照以下步骤操作 −
- 导航到 BigQuery
- 选择管理
- 单击监控
- 如果需要:切换实时数据
在此 UI 中,用户还可以访问操作运行状况,它以两种不同视图的形式提供信息:摘要视图和更详细视图。
操作运行状况摘要表中的一些顶级指标对管理员和用户都很有用,包括 −
- 插槽(Slot)使用情况
- 随机播放(预留重新分配)使用情况
- 并发性(同时执行的作业)
- 处理的字节数
- 作业持续时间
- 总存储量
注意 − 使用单位是字节(如有必要,可以转换为千兆字节或太字节)。
如需更详细的视图,用户可以使用本教程前面介绍的元数据查询技术查询 INFORMATION_SCHEMA 视图。
BigQuery 的常见错误
尽管掌握了有关 BigQuery 功能的教育和信息,但与任何开发过程一样,错误是可能的,事实上,错误是不可避免的。由于新用户对平台不熟悉,他们特别容易受到 BigQuery 错误的影响。
BigQuery 错误类型
BigQuery 错误分为两类 −
- 基于代码的错误
- 基于平台的错误
尽管 BigQuery 的 SQL 方言 (Google SQL) 旨在被普遍理解并让人联想到其他 SQL 方言,但可能会发生语法错误,坦率地说,这可能会让人非常沮丧。
BigQuery 语法错误
以下是 BigQuery 语法错误的非详尽列表 −
- 使用撇号代替反引号。
- 在 FROM 子句中省略数据集或表。
- 错误地使用 UNNEST()(在 STRUCT 而不是 ARRAY 上)。
- 在使用 AVG() 等聚合函数时忘记 GROUP BY 子句。
- 忘记列名之间的逗号。
基于平台的错误
基于平台的错误源于误解 BigQuery 的执行约束,可能包括 −
- 运行超过 20 个并发查询。
- 未将大型查询的结果写入表,导致"结果太大"错误。
- 未将大型查询作为批处理作业运行。
- 覆盖或截断表而不是附加结果。
不幸的是,不可能标记新的 BigQuery SQL 开发人员遇到的几乎所有错误。但是,以上代表了您可能遇到的各种问题。
BigQuery - 数据仓库
对于许多组织来说,BigQuery 是数据仓库的自然候选者。数据仓库是一个业务系统和中央存储库,用于存储数据以供分析,然后进行下游报告。
注意通常,存储在数据仓库中的数据是结构化或半结构化的,而数据湖则存储非结构化数据。
BigQuery 能够连接到Looker或Tableau等可视化平台,这使其成为支持企业仪表板和临时报告的理想引擎。应用分区和集群等存储优化的能力意味着数据团队可以自信而高效地存储数据数年或数十年,而不必担心性能受损。能够与 Python 和 JavaScript 等脚本语言集成,使软件工程师、数据架构师和数据工程师等专业人士能够创建自动化、重复的加载作业。
将 BigQuery 与 Google Sheets 等其他应用程序集成,可让非技术利益相关者(他们可能更喜欢或只使用电子表格)更清楚地看到和访问存储在 BigQuery 中的数据。
利用 BigQuery API,开发人员可以将 BigQuery SQL 与编程逻辑相结合,以生成自定义见解。
使用 BI Engine 等工具按需添加插槽(Slot)、升级存储和加速查询的能力对于最初构建或扩展数据基础架构的组织来说是一个很有吸引力的选择。
这些功能的缺点是成本。但是,无论是固定定价模式还是按使用量定价模式,业务用户和决策者都可能会发现使用面向 BigQuery 的数据仓库具有成本效益。
下图由 Google Cloud 提供,说明了如何构建和实施面向数据仓库的基本解决方案。
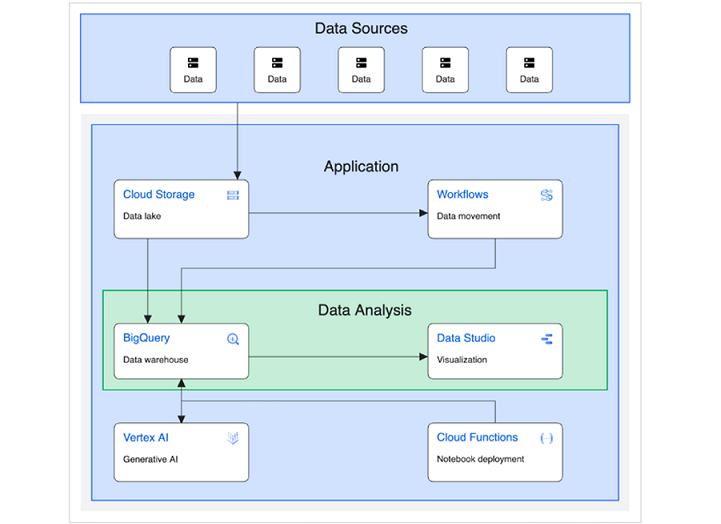
(来源:https://cloud.google.com/architecture/big-data-analytics/data-warehouse)
除了数据源、应用程序和数据分析之外,此图还可以细分为更具体的类别并解释为 −
- 上游源(第三方 API 或外部数据源)。
- 中间/暂存存储(云存储存储桶)。
- 永久/长期存储(BigQuery)。
- ML/AI 应用程序(Vertex AI、Cloud Functions 和 Compute Engine 虚拟机)。
- 下游用户:通过 Looker 等可视化平台访问模型和查询输出的业务用户。
无论从哪种解释来看,BigQuery 都是包含数据的中央存储库或"数据仓库",然后才能为下游用户创造业务价值。
BigQuery - 挑战与最佳实践
作为云计算工具,BigQuery 并非没有挑战。在这一简短的章节中,我们试图强调 BigQuery 面临的一些明显挑战。
从业务角度看 BigQuery
从业务角度看,BigQuery 面临的最大障碍之一是确保领导层支持测试、调整或扩展平台以满足特定组织的需求。
- 许多企业满足于依赖本地数据存储,而不考虑云存储选项。
- 或者更糟糕的是,企业甚至可能不认为任何形式的数据仓库是其大数据存储的可行解决方案。
- 企业领导者可能会将 BigQuery 的可变成本视为潜在的资源消耗,尤其是如果他们的组织有许多开发人员、工程师、架构师和最终用户依赖从 BigQuery 存储和查询的数据。
从用户角度看 BigQuery观点
从用户的角度来看,BigQuery 有一点学习曲线。
- 可用的 SQL 的双重版本,标准 SQL 和 旧版 SQL,意味着那些使用过其他 SQL 方言的人可能会对需要启用哪种模式来运行给定查询或使用特定功能感到困惑。
- 当尝试将基于 BigQuery 的数据仓库与外部连接(如 Google Sheet 或 BigQuery API)集成时,使用 BigQuery 进行开发可能具有挑战性。
- 尽管提供了对执行时和执行后消耗的资源和其他性能指标的可见性,但 BigQuery 的错误日志可能不明确,导致故障排除时感到沮丧 - 尤其是对于新开发人员而言。
BigQuery 最佳实践
为了避免或克服这些挑战,有必要了解和实施 BigQuery 最佳实践。要充分利用 BigQuery,需要具备 Google Cloud Platform、云计算和 SQL 方面的知识。
为了减少收到意外的昂贵月度账单的可能性,请启用监控并经常查看在 BigQuery 上过滤的账单和使用情况仪表板。
不要不断地临时增加插槽(Slot),而要迫使开发人员在代码级别思考和实施最佳实践。这可能包括 −
- 通过避免使用"SELECT *"之类的宽泛查询来减少处理的数据范围
- 选择高效的 SQL 查询设计模式来优化查询操作
- 避免计算密集型查询,例如使用通配符引用和过多元数据读取的查询
- 使用可用的工具(如 BigQuery 的 BI Engine)来识别有问题的操作,并在必要时提高性能
- 通过仅允许用户使用 WHERE 子句进行查询来指定大型表的查询限制
同时具备平台和 SQL 知识的用户将成为构建、扩展和宣传平台的人,将 BigQuery 的强大功能添加到他们的个人技能和组织技术堆栈中。


