BigQuery - 数据集
BigQuery 中的数据集是什么?
数据集是存在于项目中的实体。数据集充当 BigQuery 表以及视图、例程和机器学习模型的容器。
表不能独立于数据集,因此在 BigQuery Studio 中创建新数据源时,必须创建数据集。
除了人类可读的名称等属性外,开发人员还需要在授权创建数据集时指定位置。这些位置与 Google 数据中心在世界各地的物理位置相对应。
指定位置时,您需要指定单个区域或多个区域。例如,您不会选择位于芝加哥的数据中心,而是指定"us-central-1"。
将数据集建立为多区域实体,为 BigQuery 提供了额外的优势,即当特定区域没有足够的资源来满足当前需求时,BigQuery 会转移位置。当前的多区域位于美洲(美国)或欧盟(欧洲)。
在 BigQuery 中创建数据集的步骤
要创建数据集,请按照以下步骤操作。首先,导航到您的项目名称并点击三个点,这将触发一个带有"创建数据集" −
的弹出窗口
单击"创建数据集"后,系统将提示您输入 −
- dataset_id
- 位置类型(区域与多区域)。
- 默认表到期时间(表到期前多少天)。
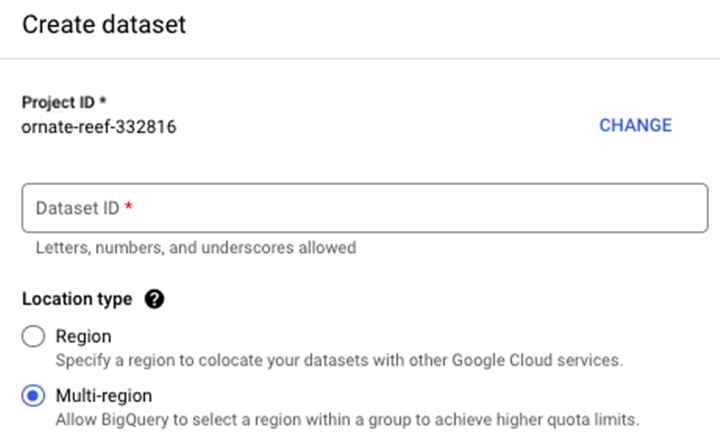
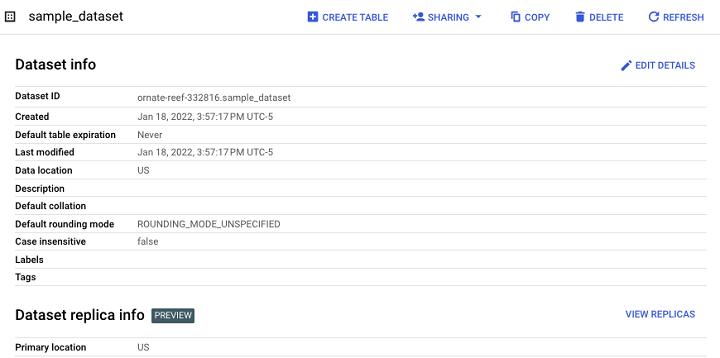
最终结果是一个数据集,它可作为未来表、视图和物化视图的容器。
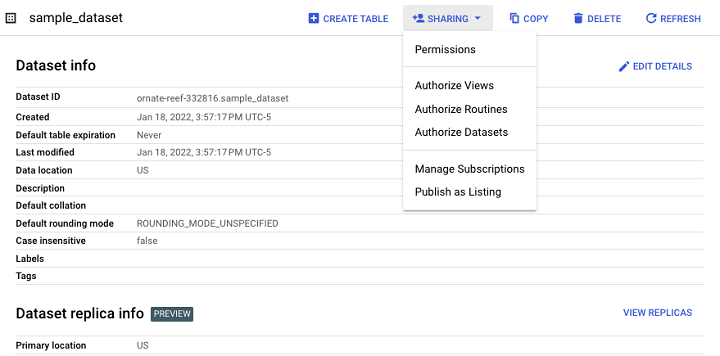
"共享"选项允许开发人员管理对数据集的访问控制,以限制未经授权的用户。
BigQuery:公共数据集
如果您是 BigQuery 新手,并且可能不熟悉 SQL,则可能没有生成要存储和操作的数据。这是使用 BigQuery Studio 作为 SQL 沙盒的优势之一。除了无服务器基础架构外,BigQuery 还提供了数 TB 的示例数据,学生和专业人士可以使用这些数据来学习和完善他们的 SQL 技能。
- 通过 Google Cloud 公共数据集计划发布的 BigQuery 公共数据集存储在其自己的通用可访问项目中:bigquery-public-data。
- 根据按 TB 付费的定价模型,开发人员每月最多可以免费查询 1 TB 的数据。
- 与许多库存数据集不同,表中包含的数据是真实的,也就是"混乱的",有时需要进行重大转换才能产生可操作的见解。
BigQuery 还提供了几个独立于其 BigQuery 公共数据集的示例表,可以在 bigquery-public-data:samples 表数据集中找到 −
- gsod
- github_nested
- github_timeline
- natality
- shakespeare
- trigrams
- wikipedia
访问 BigQuery 公共数据集的最显著优势或许在于,数据是从 BBC、Hacker News 和约翰霍普金斯大学等真实数据源中提取的。


