BigQuery - 分区和聚类
由于本教程中已经使用了"分区"和"聚类",因此提供更多背景信息会很有帮助。
什么是分区和聚类?
这两个术语用于描述优化数据存储和处理的两种方法。
分区是开发人员对数据进行分段的方式,通常(但并非总是)按年、月或日等日期元素进行分段。聚类描述了数据在指定分区内的排序方式。
要使用任一存储方法,您必须定义所需的字段。只有一个字段可用于分区,但多个字段可用于聚类。
需要注意的是,要应用分区或聚类,您必须在构建的"创建表"阶段执行此操作。否则,您将需要删除/重新创建具有更新的分区/聚类规范的表。
如何将分区或聚类应用于表
要在创建时将分区和/或聚类应用于表,请运行以下命令 −
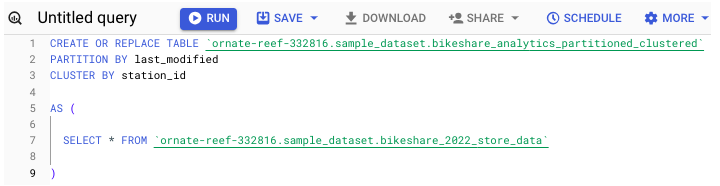
您还可以在 UI 中指定这些说明。在点击"创建表"之前,请花点时间填写架构创建框正下方的字段。
如果正确应用分区/聚类,它可以显著减少长期存储成本和处理时间,尤其是在查询大型表时。


