BigQuery - 数据仓库
对于许多组织来说,BigQuery 是数据仓库的自然候选者。数据仓库是一个业务系统和中央存储库,用于存储数据以供分析,然后进行下游报告。
注意通常,存储在数据仓库中的数据是结构化或半结构化的,而数据湖则存储非结构化数据。
BigQuery 能够连接到Looker或Tableau等可视化平台,这使其成为支持企业仪表板和临时报告的理想引擎。应用分区和集群等存储优化的能力意味着数据团队可以自信而高效地存储数据数年或数十年,而不必担心性能受损。能够与 Python 和 JavaScript 等脚本语言集成,使软件工程师、数据架构师和数据工程师等专业人士能够创建自动化、重复的加载作业。
将 BigQuery 与 Google Sheets 等其他应用程序集成,可让非技术利益相关者(他们可能更喜欢或只使用电子表格)更清楚地看到和访问存储在 BigQuery 中的数据。
利用 BigQuery API,开发人员可以将 BigQuery SQL 与编程逻辑相结合,以生成自定义见解。
使用 BI Engine 等工具按需添加插槽(Slot)、升级存储和加速查询的能力对于最初构建或扩展数据基础架构的组织来说是一个很有吸引力的选择。
这些功能的缺点是成本。但是,无论是固定定价模式还是按使用量定价模式,业务用户和决策者都可能会发现使用面向 BigQuery 的数据仓库具有成本效益。
下图由 Google Cloud 提供,说明了如何构建和实施面向数据仓库的基本解决方案。
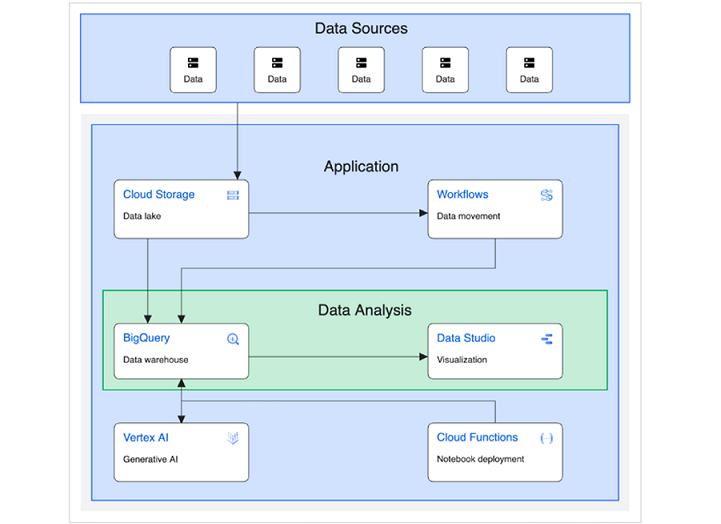
(来源:https://cloud.google.com/architecture/big-data-analytics/data-warehouse)
除了数据源、应用程序和数据分析之外,此图还可以细分为更具体的类别并解释为 −
- 上游源(第三方 API 或外部数据源)。
- 中间/暂存存储(云存储存储桶)。
- 永久/长期存储(BigQuery)。
- ML/AI 应用程序(Vertex AI、Cloud Functions 和 Compute Engine 虚拟机)。
- 下游用户:通过 Looker 等可视化平台访问模型和查询输出的业务用户。
无论从哪种解释来看,BigQuery 都是包含数据的中央存储库或"数据仓库",然后才能为下游用户创造业务价值。


