Python 数据访问 - 快速指南
Python MySQL - 简介
Python 数据库接口的标准是 Python DB-API。大多数 Python 数据库接口都遵循此标准。
您可以为您的应用程序选择合适的数据库。Python 数据库 API 支持各种数据库服务器,例如 −
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
以下是可用的 Python 数据库接口列表:Python 数据库接口和 API。您必须为需要访问的每个数据库下载单独的 DB API 模块。例如,如果您需要访问 Oracle 数据库和 MySQL 数据库,则必须同时下载 Oracle 和 MySQL 数据库模块。
什么是 mysql-connector-python?
MySQL Python/Connector 是一个用于从 Python 连接到 MySQL 数据库服务器的接口。它实现了 Python 数据库 API,并建立在 MySQL 之上。
如何安装 mysql-connector-python?
首先,您需要确保您已经在机器上安装了 python。为此,打开命令提示符并在其中输入 python,然后按 Enter。如果你的系统中已经安装了 python,此命令将显示其版本,如下所示 −
C:\Users\Tutorialspoint>python Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
现在按 ctrl+z,然后按 Enter 退出 Python shell,并创建一个名为 Python_MySQL 的文件夹(您打算在其中安装 Python-MySQL 连接器),如下所示: −
>>> ^Z C:\Users\Tutorialspoint>d: D:\>mkdir Python_MySQL
验证 PIP
PIP 是 Python 中的一个包管理器,您可以使用它在 Python 中安装各种模块/包。因此,要安装 Mysql-python mysql-connector-python,您需要确保您的计算机中安装了 PIP,并将其位置添加到路径中。
您可以通过执行 pip 命令来执行此操作。如果您的系统中没有 PIP,或者如果您没有在 Path 环境变量中添加其位置,您将收到一条错误消息,提示为 −
D:\Python_MySQL>pip 'pip' is not recognized as an internal or external command, operable program or batch file.
要安装 PIP,请将 get-pip.py 下载到上面创建的文件夹中,然后从命令中导航并安装 pip,如下所示 −
D:\>cd Python_MySQL D:\Python_MySQL>python get-pip.py Collecting pip Downloading https://files.pythonhosted.org/packages/8d/07/f7d7ced2f97ca3098c16565efbe6b15fafcba53e8d9bdb431e09140514b0/pip-19.2.2-py2.py3-none-any.whl (1.4MB) |████████████████████████████████| 1.4MB 1.3MB/s Collecting wheel Downloading https://files.pythonhosted.org/packages/00/83/b4a77d044e78ad1a45610eb88f745be2fd2c6d658f9798a15e384b7d57c9/wheel-0.33.6-py2.py3-none-any.whl Installing collected packages: pip, wheel Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed pip-19.2.2 wheel-0.33.6
安装 mysql-connector-python
安装 Python 和 PIP 后,打开命令提示符并升级 pip(可选),如下所示 −
C:\Users\Tutorialspoint>python -m pip install --upgrade pip Collecting pip Using cached https://files.pythonhosted.org/packages/8d/07/f7d7ced2f97ca3098c16565efbe6b15fafcba53e8d9bdb431e09140514b0/pip-19.2.2-py2.py3-none-any.whl Python Data Access 4 Installing collected packages: pip Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Successfully installed pip-19.2.2
然后以管理员模式打开命令提示符并安装 python MySQL 连接为 −
C:\WINDOWS\system32>pip install mysql-connector-python Collecting mysql-connector-python Using cached https://files.pythonhosted.org/packages/99/74/f41182e6b7aadc62b038b6939dce784b7f9ec4f89e2ae14f9ba8190dc9ab/mysql_connector_python-8.0.17-py2.py3-none-any.whl Collecting protobuf>=3.0.0 (from mysql-connector-python) Using cached https://files.pythonhosted.org/packages/09/0e/614766ea191e649216b87d331a4179338c623e08c0cca291bcf8638730ce/protobuf-3.9.1-cp37-cp37m-win32.whl Collecting six>=1.9 (from protobuf>=3.0.0->mysql-connector-python) Using cached https://files.pythonhosted.org/packages/73/fb/00a976f728d0d1fecfe898238ce23f502a721c0ac0ecfedb80e0d88c64e9/six-1.12.0-py2.py3-none-any.whl Requirement already satisfied: setuptools in c:\program files (x86)\python37-32\lib\site-packages (from protobuf>=3.0.0->mysql-connector-python) (40.8.0) Installing collected packages: six, protobuf, mysql-connector-python Successfully installed mysql-connector-python-8.0.17 protobuf-3.9.1 six-1.12.0
验证
要验证安装,请创建一个示例 Python 脚本,其中包含以下行。
import mysql.connector
如果安装成功,则执行时不应出现任何错误 −
D:\Python_MySQL>python test.py D:\Python_MySQL>
从头开始安装 Python
简单来说,如果您需要从头开始安装 Python。访问 Python 主页。
单击下载按钮,您将被重定向到下载页面,该页面提供适用于各种平台的最新版本 Python 的链接,请选择一个并下载。
例如,我们下载了 python-3.7.4.exe(适用于 Windows)。双击下载的 .exe 文件开始安装过程。
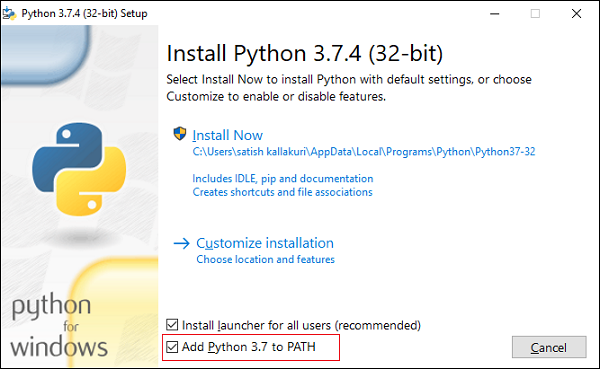
选中"将 Python 3.7 添加到路径"选项并继续安装。完成此过程后,python 将安装在您的系统中。
Python MySQL - 数据库连接
要连接 MySQL,(一种方法是)在系统中打开 MySQL 命令提示符,如下所示 −
这里要求输入密码;您需要输入安装时为默认用户(root)设置的密码。
然后建立与 MySQL 的连接,并显示以下消息−
Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.7.12-log MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
您可以随时在 mysql> 提示符下使用 exit 命令断开与 MySQL 数据库的连接。
mysql> exit Bye
使用 python 与 MySQL 建立连接
在使用 python 与 MySQL 数据库建立连接之前,假设 −
我们已经创建了一个名为 mydb 的数据库。
我们已经创建了一个表 EMPLOYEE,其中包含列 FIRST_NAME、LAST_NAME、AGE、SEX 和 INCOME。
我们用于连接 MySQL 的凭据是用户名:root,密码:password。
您可以使用 connect() 构造函数建立连接。它接受用户名、密码、主机和需要连接的数据库的名称(可选),并返回 MySQLConnection 类的对象。
示例
以下是连接 MySQL 数据库"mydb"的示例。
import mysql.connector
#建立连接
conn = mysql.connector.connect(user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#使用 execute() 方法执行 MYSQL 函数
cursor.execute("SELECT DATABASE()")
# 使用 fetchone() 方法获取单行。
data = cursor.fetchone()
print("Connection established to: ",data)
#关闭连接
conn.close()
输出
执行时,此脚本产生以下输出 −
D:\Python_MySQL>python EstablishCon.py
Connection established to: ('mydb',)
您还可以通过将凭据(用户名、密码、主机名和数据库名称)传递给 connection.MySQLConnection() 来建立与 MySQL 的连接,如下所示−
from mysql.connector import (connection) #建立连接 conn = connection.MySQLConnection(user='root', password='password', host='127.0.0.1', database='mydb') #关闭连接 conn.close()
Python MySQL - 创建数据库
您可以使用 CREATE DATABASE 查询在 MYSQL 中创建数据库。
语法
以下是 CREATE DATABASE 查询的语法 −
CREATE DATABASE name_of_the_database
示例
以下语句在 MySQL 中创建名为 mydb 的数据库 −
mysql> CREATE DATABASE mydb; Query OK, 1 row affected (0.04 sec)
如果您使用 SHOW DATABASES 语句观察数据库列表,则可以在其中观察到新创建的数据库,如下所示 −
mysql> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | logging | | mydatabase | | mydb | | performance_schema | | students | | sys | +--------------------+ 26 rows in set (0.15 sec)
使用 python 在 MySQL 中创建数据库
与 MySQL 建立连接后,要操作其中的数据,您需要连接到数据库。您可以连接到现有数据库,也可以创建自己的数据库。
您需要特殊权限才能创建或删除 MySQL 数据库。因此,如果您有权访问 root 用户,则可以创建任何数据库。
示例
以下示例与 MYSQL 建立连接并在其中创建数据库。
import mysql.connector
#建立连接
conn = mysql.connector.connect(user='root', password='password', host='127.0.0.1')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果数据库 MYDATABASE 已经存在,则将其删除。
cursor.execute("DROP database IF EXISTS MyDatabase")
#准备查询以创建数据库
sql = "CREATE database MYDATABASE";
#创建数据库
cursor.execute(sql)
#检索数据库列表
print("List of databases: ")
cursor.execute("SHOW DATABASES")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
List of databases:
[('information_schema',), ('dbbug61332',), ('details',), ('exampledatabase',), ('mydatabase',), ('mydb',), ('mysql',), ('performance_schema',)]
Python MySQL - 创建表
CREATE TABLE 语句用于在 MYSQL 数据库中创建表。在这里,您需要指定表的名称以及每列的定义(名称和数据类型)。
语法
以下是在 MySQL 中创建表的语法 −
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, );
示例
以下查询在 MySQL 中创建一个名为 EMPLOYEE 的表,该表包含五列,即 FIRST_NAME、LAST_NAME、AGE、SEX 和 INCOME。
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.42 sec)
DESC 语句为您提供指定表的描述。使用此语句,您可以验证表是否已创建,如下所示 −
mysql> Desc Employee; +------------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+----------+------+-----+---------+-------+ | FIRST_NAME | char(20) | NO | | NULL | | | LAST_NAME | char(20) | YES | | NULL | | | AGE | int(11) | YES | | NULL | | | SEX | char(1) | YES | | NULL | | | INCOME | float | YES | | NULL | | +------------+----------+------+-----+---------+-------+ 5 rows in set (0.07 sec)
使用 python 在 MySQL 中创建表
名为 execute() 的方法(在游标对象上调用)接受两个变量 −
表示要执行的查询的字符串值。
可选的 args 参数,可以是元组、列表或字典,表示查询的参数(占位符的值)。
它返回一个整数值,表示查询影响的行数。
建立数据库连接后,您可以通过将 CREATE TABLE 查询传递给 execute() 方法来创建表。
简而言之,使用 python 7minus; 创建表
导入mysql.connector 包。
使用 mysql.connector.connect() 方法创建连接对象,将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给该方法。
通过在上面创建的连接对象上调用 cursor() 方法创建游标对象。
然后,通过将 CREATE TABLE 语句作为参数传递给 execute() 方法执行该语句。
示例
以下示例在数据库 mydb 中创建一个名为 Employee 的表。
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb'
)
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已存在,则删除该表。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#根据要求创建表
sql ='''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#关闭连接
conn.close()
Python MySQL - 插入数据
您可以使用 INSERT INTO 语句向现有的 MySQL 表添加新行。在此,您需要指定表的名称、列名和值(与列名的顺序相同)。
语法
以下是 MySQL 的 INSERT INTO 语句的语法。
INSERT INTO TABLE_NAME (column1, column2,column3,...columnN) VALUES (value1, value2, value3,...valueN);
示例
以下查询将记录插入名为 EMPLOYEE 的表中。
INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES ('
Mac', 'Mohan', 20, 'M', 2000
);
您可以使用 SELECT 语句验证插入操作后的表记录,如下所示 −
mysql> select * from Employee; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Mac | Mohan | 20 | M | 2000 | +------------+-----------+------+------+--------+ 1 row in set (0.00 sec)
不必总是指定列的名称,如果您按照与表列相同的顺序传递记录的值,则可以执行不带列名的 SELECT 语句,如下所示 −
INSERT INTO EMPLOYEE VALUES ('Mac', 'Mohan', 20, 'M', 2000);
使用 python 在 MySQL 表中插入数据
execute() 方法(在游标对象上调用)接受查询作为参数并执行给定的查询。要插入数据,您需要将 MySQL INSERT 语句作为参数传递给它。
cursor.execute("""INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)""")
使用 python 将数据插入 MySQL 中的表中 −
导入 mysql.connector 包。
使用 mysql.connector.connect() 方法创建连接对象,将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过在上面创建的连接对象上调用 cursor() 方法创建游标对象
然后,通过将 INSERT 语句作为参数传递给 execute() 方法执行该语句。
示例
以下示例执行 SQL INSERT 语句以将记录插入EMPLOYEE 表 −
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
# 准备 SQL 查询以将记录插入数据库。
sql = """INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)"""
try:
# 执行 SQL 命令
cursor.execute(sql)
# 在数据库中提交你的更改
conn.commit()
except:
# 出现错误时回滚
conn.rollback()
# 关闭连接
conn.close()
动态插入值
您还可以在 MySQL 的 INSERT 查询中使用"%s"代替值,并将值作为列表传递给它们,如下所示 −
cursor.execute("""INSERT INTO EMPLOYEE VALUES ('Mac', 'Mohan', 20, 'M', 2000)""",
('Ramya', 'Ramapriya', 25, 'F', 5000))
示例
以下示例动态地将一条记录插入到 Employee 表中。
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
# 准备 SQL 查询以将记录插入数据库。
insert_stmt = (
"INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)"
"VALUES (%s, %s, %s, %s, %s)"
)
data = ('Ramya', 'Ramapriya', 25, 'F', 5000)
try:
# 执行 SQL 命令
cursor.execute(insert_stmt, data)
# 在数据库中提交你的更改
conn.commit()
except:
# 出现错误时回滚
conn.rollback()
print("Data inserted")
# 关闭连接
conn.close()
输出
Data inserted
Python MySQL - 选择数据
您可以使用 SELECT 查询从 MySQL 中的表中检索/获取数据。此查询/语句以表格形式返回指定表的内容,并称为结果集。
语法
以下是 SELECT 查询的语法 −
SELECT column1, column2, columnN FROM table_name;
示例
假设我们在 MySQL 中创建了一个名为 cricketers_data 的表,如下所示 −
CREATE TABLE cricketers_data( First_Name VARCHAR(255), Last_Name VARCHAR(255), Date_Of_Birth date, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) );
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
insert into cricketers_data values(
'Shikhar', 'Dhawan', DATE('1981-12-05'), 'Delhi', 'India');
insert into cricketers_data values(
'Jonathan', 'Trott', DATE('1981-04-22'), 'CapeTown', 'SouthAfrica');
insert into cricketers_data values(
'Kumara', 'Sangakkara', DATE('1977-10-27'), 'Matale', 'Srilanka');
insert into cricketers_data values(
'Virat', 'Kohli', DATE('1988-11-05'), 'Delhi', 'India');
insert into cricketers_data values(
'Rohit', 'Sharma', DATE('1987-04-30'), 'Nagpur', 'India');
以下查询从表中检索 FIRST_NAME 和 Country 值。
mysql> select FIRST_NAME, Country from cricketers_data; +------------+-------------+ | FIRST_NAME | Country | +------------+-------------+ | Shikhar | India | | Jonathan | SouthAfrica | | Kumara | Srilanka | | Virat | India | | Rohit | India | +------------+-------------+ 5 rows in set (0.00 sec)
您还可以使用 * 代替列名称来检索每条记录的所有值,如下所示 −
mysql> SELECT * from cricketers_data; +------------+------------+---------------+----------------+-------------+ | First_Name | Last_Name | Date_Of_Birth | Place_Of_Birth | Country | +------------+------------+---------------+----------------+-------------+ | Shikhar | Dhawan | 1981-12-05 | Delhi | India | | Jonathan | Trott | 1981-04-22 | CapeTown | SouthAfrica | | Kumara | Sangakkara | 1977-10-27 | Matale | Srilanka | | Virat | Kohli | 1988-11-05 | Delhi | India | | Rohit | Sharma | 1987-04-30 | Nagpur | India | +------------+------------+---------------+----------------+-------------+ 5 rows in set (0.00 sec)
使用 Python 从 MYSQL 表读取数据
对任何数据库执行 READ 操作意味着从数据库获取一些有用的信息。您可以使用 mysql-connector-python 提供的 fetch() 方法从 MYSQL 获取数据。
cursor.MySQLCursor 类提供三种方法,即 fetchall()、fetchmany() 和 fetchone(),其中
fetchall() 方法检索查询结果集中的所有行并将它们作为元组列表返回。 (如果我们在检索几行后执行此操作,它将返回剩余的行)。
fetchone() 方法获取查询结果中的下一行并将其作为元组返回。
fetchmany() 方法类似于 fetchone(),但它检索查询结果集中的下一组行,而不是单个行。
注意 − 结果集是使用游标对象查询表时返回的对象。
rowcount −这是一个只读属性,返回受 execute() 方法影响的行数。
示例
以下示例使用 SELECT 查询获取 EMPLOYEE 表的所有行,并从最初获得的结果集中,我们使用 fetchone() 方法检索第一行,然后使用 fetchall() 方法获取其余行。
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb') #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE''' #执行查询 cursor.execute(sql) #从表中获取第一行 result = cursor.fetchone(); print(result) #Fetching 1st row from the table result = cursor.fetchall(); print(result) #关闭连接 conn.close()
输出
('Krishna', 'Sharma', 19, 'M', 2000.0)
[('Raj', 'Kandukuri', 20, 'M', 7000.0), ('Ramya', 'Ramapriya', 25, 'M', 5000.0)]
Following example retrieves first two rows of the EMPLOYEE table using the fetchmany() method.
Example
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb') #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE''' #执行查询 cursor.execute(sql) #从表中获取第一行 result = cursor.fetchmany(size =2); print(result) #关闭连接 conn.close()
输出
[('Krishna', 'Sharma', 19, 'M', 2000.0), ('Raj', 'Kandukuri', 20, 'M', 7000.0)]
Python MySQL - Where 子句
如果要获取、删除或更新 MySQL 中表的特定行,则需要使用 where 子句指定条件来过滤要执行操作的表行。
例如,如果您有一个带有 where 子句的 SELECT 语句,则只会检索满足指定条件的行。
语法
以下是 WHERE 子句的语法 −
SELECT column1, column2, columnN FROM table_name WHERE [condition]
示例
假设我们在 MySQL 中创建了一个名为 EMPLOYEES 的表,如下所示 −
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.36 sec)
如果我们使用 INSERT 语句向其中插入 4 条记录,如下所示 −
mysql> INSERT INTO EMPLOYEE VALUES
('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000);
以下 MySQL 语句检索收入大于 4000 的员工记录。
mysql> SELECT * FROM EMPLOYEE WHERE INCOME > 4000; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Raj | Kandukuri | 20 | M | 7000 | | Ramya | Ramapriya | 25 | F | 5000 | +------------+-----------+------+------+--------+ 2 rows in set (0.00 sec)
使用 python 的 WHERE 子句
使用 python 程序 − 从表中获取特定记录
导入 mysql.connector 包。
使用 mysql.connector.connect() 方法创建连接对象,将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过在上面创建的连接对象上调用 cursor() 方法创建游标对象。
然后,执行带有 WHERE 子句的 SELECT 语句,将其作为参数传递给 execute()方法。
示例
以下示例创建一个名为 Employee 的表并填充它。然后使用 where 子句检索年龄值小于 23 的记录。
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#填充表格
insert_stmt = "INSERT INTO EMPLOYEE (FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (%s, %s, %s, %s, %s)"
data = [('Krishna', 'Sharma', 19, 'M', 2000), ('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),('Mac', 'Mohan', 26, 'M', 2000)]
cursor.executemany(insert_stmt, data)
conn.commit()
使用 where 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE WHERE AGE <23")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
[('Krishna', 'Sharma', 19, 'M', 2000.0), ('Raj', 'Kandukuri', 20, 'M', 7000.0)]
Python MySQL - Order By 子句
使用 SELECT 查询获取数据时,可以使用 Order By 子句按所需顺序(升序或降序)对结果进行排序。默认情况下,此子句按升序对结果进行排序,如果您需要按降序排列,则需要明确使用"DESC"。
语法
以下是语法 SELECT column-list
FROM table_name [WHERE condition] [ORDER BY column1, column2,.. columnN] [ASC | DESC]; ORDER BY 子句:
示例
假设我们在 MySQL 中创建了一个名为 EMPLOYEES 的表,如下所示 −
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.36 sec)
如果我们使用 INSERT 语句向其中插入 4 条记录,如下所示 −
mysql> INSERT INTO EMPLOYEE VALUES
('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000);
以下语句按年龄升序检索 EMPLOYEE 表的内容。
mysql> SELECT * FROM EMPLOYEE ORDER BY AGE; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Krishna | Sharma | 19 | M | 2000 | | Raj | Kandukuri | 20 | M | 7000 | | Ramya | Ramapriya | 25 | F | 5000 | | Mac | Mohan | 26 | M | 2000 | +------------+-----------+------+------+--------+ 4 rows in set (0.04 sec)
您还可以使用 DESC 以降序检索数据,如下所示 −
mysql> SELECT * FROM EMPLOYEE ORDER BY FIRST_NAME, INCOME DESC; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Krishna | Sharma | 19 | M | 2000 | | Mac | Mohan | 26 | M | 2000 | | Raj | Kandukuri | 20 | M | 7000 | | Ramya | Ramapriya | 25 | F | 5000 | +------------+-----------+------+------+--------+ 4 rows in set (0.00 sec)
使用 Python 的 ORDER BY 子句
要按特定顺序检索表的内容,请在游标对象上调用 execute() 方法,并将 SELECT 语句与 ORDER BY 子句一起作为参数传递给它。
示例
在下面的例子中,我们将创建一个包含姓名和员工的表,填充它,并使用 ORDER BY 子句按年龄(升序)顺序检索其记录。
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#填充表
insert_stmt = "INSERT INTO EMPLOYEE (FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (%s, %s, %s, %s, %s)"
data = [('Krishna', 'Sharma', 26, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 29, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000)]
cursor.executemany(insert_stmt, data)
conn.commit()
#使用 ORDER BY 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE ORDER BY AGE")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
[('Raj', 'Kandukuri', 20, 'M', 7000.0),
('Krishna', 'Sharma', 26, 'M', 2000.0),
('Mac', 'Mohan', 26, 'M', 2000.0),
('Ramya', 'Ramapriya', 29, 'F', 5000.0)
]
同样,您可以使用 ORDER BY 子句按降序从表中检索数据。
示例
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#Retrieving specific records using the ORDERBY clause
cursor.execute("SELECT * from EMPLOYEE ORDER BY INCOME DESC")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
[('Raj', 'Kandukuri', 20, 'M', 7000.0),
('Ramya', 'Ramapriya', 29, 'F', 5000.0),
('Krishna', 'Sharma', 26, 'M', 2000.0),
('Mac', 'Mohan', 26, 'M', 2000.0)
]
Python MySQL - 更新表
对任何数据库执行 UPDATE 操作都会更新数据库中已有的一条或多条记录。您可以使用 UPDATE 语句更新 MySQL 中现有记录的值。要更新特定行,您需要同时使用 WHERE 子句。
语法
以下是 MySQL 中 UPDATE 语句的语法 −
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
您可以使用 AND 或 OR 运算符组合 N 个条件。
示例
假设我们在 MySQL 中创建了一个名为 EMPLOYEES 的表,如下所示−
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.36 sec)
如果我们使用 INSERT 语句向其中插入 4 条记录,如下所示 −
mysql> INSERT INTO EMPLOYEE VALUES
('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000);
以下 MySQL 语句将所有男性员工的年龄增加一岁 −
mysql> UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = 'M'; Query OK, 3 rows affected (0.06 sec) Rows matched: 3 Changed: 3 Warnings: 0
如果您检索表的内容,您可以看到更新的值 −
mysql> select * from EMPLOYEE; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Krishna | Sharma | 20 | M | 2000 | | Raj | Kandukuri | 21 | M | 7000 | | Ramya | Ramapriya | 25 | F | 5000 | | Mac | Mohan | 27 | M | 2000 | +------------+-----------+------+------+--------+ 4 rows in set (0.00 sec)
使用 Python 更新表的内容
使用 python − 更新 MySQL 中表中的记录
导入 mysql.connector 包。
使用 mysql.connector.connect() 方法创建连接对象,将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过在上面创建的连接对象上调用 cursor() 方法创建游标对象。
然后,通过将 UPDATE 语句作为参数传递给 execute() 方法执行该语句。
示例
以下示例增加年龄比所有男性都多一岁。
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb') #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #准备查询以更新记录 sql = '''UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = 'M' ''' try: # 执行 SQL 命令 cursor.execute(sql) # 在数据库中提交你的更改 conn.commit() except: # 如果出现任何错误,请回滚 conn.rollback() #检索数据 sql = '''SELECT * from EMPLOYEE''' #执行查询 cursor.execute(sql) #显示结果 print(cursor.fetchall()) #关闭连接 conn.close()
输出
[('Krishna', 'Sharma', 22, 'M', 2000.0),
('Raj', 'Kandukuri', 23, 'M', 7000.0),
('Ramya', 'Ramapriya', 26, 'F', 5000.0)
]
Python MySQL - 删除数据
要从 MySQL 表中删除记录,您需要使用 DELETE FROM 语句。要删除特定记录,您需要同时使用 WHERE 子句。
语法
以下是 MYSQL 中 DELETE 查询的语法 −
DELETE FROM table_name [WHERE 子句]
示例
假设我们在 MySQL 中创建了一个名为 EMPLOYEES 的表,如下所示 −
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.36 sec)
如果我们使用 INSERT 语句向其中插入 4 条记录,如下所示 −
mysql> INSERT INTO EMPLOYEE VALUES
('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000);
以下 MySQL 语句删除 FIRST_NAME 为"Mac"的员工记录。
mysql> DELETE FROM EMPLOYEE WHERE FIRST_NAME = 'Mac'; Query OK, 1 row affected (0.12 sec)
如果您检索表的内容,您将只能看到 3 条记录,因为我们已删除了一条记录。
mysql> select * from EMPLOYEE; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Krishna | Sharma | 20 | M | 2000 | | Raj | Kandukuri | 21 | M | 7000 | | Ramya | Ramapriya | 25 | F | 5000 | +------------+-----------+------+------+--------+ 3 rows in set (0.00 sec)
如果执行不带 WHERE 子句的 DELETE 语句,则指定表中的所有记录都将被删除。
mysql> DELETE FROM EMPLOYEE; Query OK, 3 rows affected (0.09 sec)
如果你检索表格的内容,你将得到一个空集,如下所示 −
mysql> select * from EMPLOYEE; Empty set (0.00 sec)
使用 python 删除表中的记录
当您想要从数据库中删除一些记录时,需要执行 DELETE 操作。
要删除表中的记录 −
导入 mysql.connector 包。
使用 mysql.connector.connect() 方法创建连接对象,将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过在上面创建的连接对象上调用 cursor() 方法创建游标对象。
然后,通过将 DELETE 语句作为参数传递给 execute() 来执行该语句方法。
示例
以下程序删除 EMPLOYEE 中所有 AGE 大于 20 的记录 −
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索单行
print("Contents of the table: ")
cursor.execute("SELECT * from EMPLOYEE")
print(cursor.fetchall())
#准备删除记录的查询
sql = "DELETE FROM EMPLOYEE WHERE AGE > '%d'" % (25)
try:
# 执行 SQL 命令
cursor.execute(sql)
# 在数据库中提交你的更改
conn.commit()
except:
# 如果出现任何错误,请回滚
conn.rollback()
#Retrieving data
print("Contents of the table after delete operation ")
cursor.execute("SELECT * from EMPLOYEE")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
Contents of the table:
[('Krishna', 'Sharma', 22, 'M', 2000.0),
('Raj', 'Kandukuri', 23, 'M', 7000.0),
('Ramya', 'Ramapriya', 26, 'F', 5000.0),
('Mac', 'Mohan', 20, 'M', 2000.0),
('Ramya', 'Rama priya', 27, 'F', 9000.0)]
Contents of the table after delete operation:
[('Krishna', 'Sharma', 22, 'M', 2000.0),
('Raj', 'Kandukuri', 23, 'M', 7000.0),
('Mac', 'Mohan', 20, 'M', 2000.0)]
Python MySQL - 删除表
您可以使用 DROP TABLE 语句删除整个表。您只需指定需要删除的表的名称即可。
语法
以下是 MySQL 中 DROP TABLE 语句的语法 −
DROP TABLE table_name;
示例
在删除表之前,使用 SHOW TABLES 语句获取表列表,如下所示 −
mysql> SHOW TABLES; +-----------------+ | Tables_in_mydb | +-----------------+ | contact | | cricketers_data | | employee | | sample | | tutorials | +-----------------+ 5 rows in set (0.00 sec)
以下语句将从数据库中完全删除名为 sample 的表 −
mysql> DROP TABLE sample; Query OK, 0 rows affected (0.29 sec)
由于我们已经从 MySQL 中删除了名为 sample 的表,如果您再次获取表列表,您将找不到其中的表名 sample。
mysql> SHOW TABLES; +-----------------+ | Tables_in_mydb | +-----------------+ | contact | | cricketers_data | | employee | | tutorials | +-----------------+ 4 rows in set (0.00 sec)
使用 python 删除表
您可以使用 MYSQL 的 DROP 语句随时删除表,但在删除任何现有表时需要非常小心,因为删除表后丢失的数据将无法恢复。
要使用 python 从 MYSQL 数据库中删除表,请在游标对象上调用 execute() 方法,并将 drop 语句作为参数传递给它。
示例
下表从数据库中删除了一个名为 EMPLOYEE 的表。
import mysql.connector
#建立连接 conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb'
)
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索表格列表打印("List of tables in the database: ")
cursor.execute("SHOW Tables") print(cursor.fetchall())
#如果 EMPLOYEE 表已经存在,则执行 cursor.execute
("DROP TABLE EMPLOYEE") print("Table dropped... ")
#Retrieving the list of tables print(
"List of tables after dropping the EMPLOYEE table: ")
cursor.execute("SHOW Tables") print(cursor.fetchall())
#关闭连接 conn.close()
输出
List of tables in the database:
[('employee',), ('employeedata',), ('sample',), ('tutorials',)]
Table dropped...
List of tables after dropping the EMPLOYEE table:
[('employeedata',), ('sample',), ('tutorials',)]
仅当表存在时才删除
如果您尝试删除数据库中不存在的表,则会发生错误,如下所示−
mysql.connector.errors.ProgrammingError: 1051 (42S02): Unknown table 'mydb.employee'
您可以通过在 DELETE 语句中添加 IF EXISTS 来验证表在删除之前是否存在,从而避免出现此错误。
import mysql.connector
#建立连接
conn = mysql.connector.connect(
user='root', password='password', host='127.0.0.1', database='mydb')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索表列表
print("数据库中的表列表: ")
cursor.execute("SHOW Tables")
print(cursor.fetchall())
#如果 EMPLOYEE 表已存在,则将其删除
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
print("Table dropped... ")
#检索表列表
print("List of tables after dropping the EMPLOYEE table: ")
cursor.execute("SHOW Tables")
print(cursor.fetchall())
#关闭连接
conn.close()
输出
List of tables in the database:
[('employeedata',), ('sample',), ('tutorials',)]
Table dropped...
List of tables after dropping the EMPLOYEE table:
[('employeedata',), ('sample',),
('tutorials',)]
Python MySQL - Limit 限制子句
在获取记录时,如果您想用特定数字限制它们,可以使用 MYSQL 的 LIMIT 子句来实现。
示例
假设我们在 MySQL 中创建了一个名为 EMPLOYEES 的表,如下所示 −
mysql> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); Query OK, 0 rows affected (0.36 sec)
如果我们使用 INSERT 语句向其中插入 4 条记录,如下所示 −
mysql> INSERT INTO EMPLOYEE VALUES
('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'F', 5000),
('Mac', 'Mohan', 26, 'M', 2000);
以下 SQL 语句使用 LIMIT 子句检索 Employee 表的前两条记录。
SELECT * FROM EMPLOYEE LIMIT 2; +------------+-----------+------+------+--------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | +------------+-----------+------+------+--------+ | Krishna | Sharma | 19 | M | 2000 | | Raj | Kandukuri | 20 | M | 7000 | +------------+-----------+------+------+--------+ 2 rows in set (0.00 sec)
使用 Python 的 Limit 子句
如果通过将 SELECT 查询与 LIMIT 子句一起传递,在游标对象上调用 execute() 方法,则可以检索所需数量的记录。
要使用 Python 从 MYSQL 数据库中删除表,请在游标对象上调用 execute() 方法,并将 drop 语句作为参数传递给它。
示例
以下 Python 示例创建并填充名为 EMPLOYEE 的表,并使用 LIMIT 子句获取该表的前两个记录。
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb') #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE LIMIT 2''' #执行查询 cursor.execute(sql) #获取数据 result = cursor.fetchall(); print(result) #关闭连接 conn.close()
输出
[('Krishna', 'Sharma', 26, 'M', 2000.0), ('Raj', 'Kandukuri', 20, 'M', 7000.0)]
LIMIT 与 OFFSET
如果您需要限制从第 n 条记录(而不是第 1 条记录)开始的记录,则可以将 OFFSET 与 LIMIT 结合使用。
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb') #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE LIMIT 2 OFFSET 2''' #执行查询 cursor.execute(sql) #获取数据 result = cursor.fetchall(); print(result) #关闭连接 conn.close()
输出
[('Ramya', 'Ramapriya', 29, 'F', 5000.0), ('Mac', 'Mohan', 26, 'M', 2000.0)]
Python MySQL - 连接
将数据分成两个表后,可以使用连接从这两个表中获取组合记录。
示例
假设我们创建了一个名为 EMPLOYEE 的表,并在其中填充了数据,如下所示 −
mysql> CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT,
CONTACT INT
);
Query OK, 0 rows affected (0.36 sec)
INSERT INTO Employee VALUES ('Ramya', 'Rama Priya', 27, 'F', 9000, 101),
('Vinay', 'Bhattacharya', 20, 'M', 6000, 102),
('Sharukh', 'Sheik', 25, 'M', 8300, 103),
('Sarmista', 'Sharma', 26, 'F', 10000, 104),
('Trupthi', 'Mishra', 24, 'F', 6000, 105);
Query OK, 5 rows affected (0.08 sec)
Records: 5 Duplicates: 0 Warnings: 0
然后,如果我们创建了另一个表并将其填充为 −
CREATE TABLE CONTACT( ID INT NOT NULL, EMAIL CHAR(20) NOT NULL, PHONE LONG, CITY CHAR(20) ); Query OK, 0 rows affected (0.49 sec)
INSERT INTO CONTACT (ID, EMAIL, CITY) VALUES (101, 'Krishna@mymail.com', 'Hyderabad'), (102, 'Raja@mymail.com', 'Vishakhapatnam'), (103, 'Krishna@mymail.com', 'Pune'), (104, 'Raja@mymail.com', 'Mumbai'); Query OK, 4 rows affected (0.10 sec) Records: 4 Duplicates: 0 Warnings: 0
以下语句检索结合这两个表中的值的数据 −
mysql> SELECT * from EMPLOYEE INNER JOIN CONTACT ON EMPLOYEE.CONTACT = CONTACT.ID; +------------+--------------+------+------+--------+---------+-----+--------------------+-------+----------------+ | FIRST_NAME | LAST_NAME | AGE | SEX | INCOME | CONTACT | ID | EMAIL | PHONE | CITY | +------------+--------------+------+------+--------+---------+-----+--------------------+-------+----------------+ | Ramya | Rama Priya | 27 | F | 9000 | 101 | 101 | Krishna@mymail.com | NULL | Hyderabad | | Vinay | Bhattacharya | 20 | M | 6000 | 102 | 102 | Raja@mymail.com | NULL | Vishakhapatnam | | Sharukh | Sheik | 25 | M | 8300 | 103 | 103 | Krishna@mymail.com | NULL | Pune | | Sarmista | Sharma | 26 | F | 10000 | 104 | 104 | Raja@mymail.com | NULL | Mumbai | +------------+--------------+------+------+--------+---------+-----+--------------------+-------+----------------+ 4 rows in set (0.00 sec)
使用 python 的 MYSQL JOIN
以下示例从上述两个表中检索数据,这些数据由 EMPLOYEE 表的 contact 列和 CONTACT 表的 ID 列组合而成。
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb' ) #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE INNER JOIN CONTACT ON EMPLOYEE.CONTACT = CONTACT.ID''' #执行查询 cursor.execute(sql) #从表中获取第一行 result = cursor.fetchall(); print(result) #关闭连接 conn.close()
输出
[('Krishna', 'Sharma', 26, 'M', 2000, 101, 101, 'Krishna@mymail.com', 9848022338, 'Hyderabad'),
('Raj', 'Kandukuri', 20, 'M', 7000, 102, 102, 'Raja@mymail.com', 9848022339, 'Vishakhapatnam'),
('Ramya', 'Ramapriya', 29, 'F', 5000, 103, 103, 'Krishna@mymail.com', 9848022337, 'Pune'),
('Mac', 'Mohan', 26, 'M', 2000, 104, 104, 'Raja@mymail.com', 9848022330, 'Mumbai')]
Python MySQL - Cursor 对象
mysql-connector-python(和类似库)的 MySQLCursor 用于执行语句以与 MySQL 数据库进行通信。
使用它的方法,您可以执行 SQL 语句、从结果集中获取数据、调用过程。
您可以使用 Connection 对象/类的 cursor() 方法创建 Cursor 对象。
示例
import mysql.connector #建立连接 conn = mysql.connector.connect( user='root', password='password', host='127.0.0.1', database='mydb' ) #使用 cursor() 方法创建游标对象 cursor = conn.cursor()
方法
以下是 Cursor 类/对象提供的各种方法。
| Sr.No | 方法 &描述 |
|---|---|
| 1 | callproc() 此方法用于调用 MySQL 数据库中的现有过程。 |
| 2 | close() 此方法用于关闭当前游标对象。 |
| 3 | Info() 此方法提供有关最后一个查询的信息。 |
| 4 | executemany() 此方法接受一系列参数列表。准备一个 MySQL 查询并使用所有参数执行它。 |
| 5 | execute() 此方法接受 MySQL 查询作为参数并执行给定的查询。 |
| 6 | fetchall() 此方法检索查询结果集中的所有行并将它们作为元组列表返回。 (如果我们在检索几行后执行此操作,它将返回剩余的行) |
| 7 | fetchone() 此方法获取查询结果中的下一行并将其作为元组返回。 |
| 8 | fetchmany() 此方法类似于 fetchone(),但它检索查询结果集中的下一组行,而不是单个行。 |
| 9 | etchwarnings() 此方法返回上次执行的查询。 |
属性
以下是 Cursor 类的属性 −
| Sr.No | 属性 &描述 |
|---|---|
| 1 | column_names 这是一个只读属性,它返回包含结果集列名的列表。 |
| 2 | description 这是一个只读属性,它返回包含结果集中列描述的列表。 |
| 3 | lastrowid 这是一个只读属性,如果表中有任何自动递增的列,它将返回上次 INSERT 或 UPDATE 中为该列生成的值操作。 |
| 4 | rowcount 这将返回 SELECT 和 UPDATE 操作中返回/更新的行数。 |
| 5 | statement 此属性返回最后执行的语句。 |
Python PostgreSQL - 简介
安装
PostgreSQL 是一个功能强大的开源对象关系数据库系统。它拥有超过 15 年的活跃开发阶段和经过验证的架构,在可靠性、数据完整性和正确性方面赢得了良好的声誉。
要使用 Python 与 PostgreSQL 通信,您需要安装 psycopg,这是为 Python 编程提供的适配器,其当前版本为 psycog2。
psycopg2 的编写目标是非常小巧、快速且稳定如磐石。它可以在 PIP(python 的包管理器)下使用
使用 PIP 安装 Psycog2
首先,确保 python 和 PIP 已正确安装在您的系统中,并且 PIP 是最新的。
要升级 PIP,请打开命令提示符并执行以下命令 −
C:\Users\Tutorialspoint>python -m pip install --upgrade pip Collecting pip Using cached https://files.pythonhosted.org/packages/8d/07/f7d7ced2f97ca3098c16565efbe6b15fafcba53e8d9bdb431e09140514b0/pip-19.2.2-py2.py3-none-any.whl Installing collected packages: pip Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Successfully installed pip-19.2.2
然后,以管理员模式打开命令提示符并执行pip install psycopg2-binary命令,如下所示 −
C:\WINDOWS\system32>pip install psycopg2-binary Collecting psycopg2-binary Using cached https://files.pythonhosted.org/packages/80/79/d0d13ce4c2f1addf4786f4a2ded802c2df66ddf3c1b1a982ed8d4cb9fc6d/psycopg2_binary-2.8.3-cp37-cp37m-win32.whl Installing collected packages: psycopg2-binary Successfully installed psycopg2-binary-2.8.3
验证
要验证安装,请创建一个包含以下行的示例 Python 脚本。
import mysql.connector
如果安装成功,则执行时不会出现任何错误 −
D:\Python_PostgreSQL>import psycopg2 D:\Python_PostgreSQL>
Python PostgreSQL - 数据库连接
PostgreSQL 提供自己的 shell 来执行查询。要与 PostgreSQL 数据库建立连接,请确保您已在系统中正确安装它。打开 PostgreSQL shell 提示符并传递服务器、数据库、用户名和密码等详细信息。如果您提供的所有详细信息均合适,则会与 PostgreSQL 数据库建立连接。
传递详细信息时,您可以使用 shell 建议的默认服务器、数据库、端口和用户名。
使用 python 建立连接
psycopg2 的连接类表示/处理连接实例。您可以使用 connect() 函数创建新连接。它接受基本连接参数,例如 dbname、user、password、host、port,并返回一个连接对象。使用此函数,您可以与 PostgreSQL 建立连接。
示例
以下 Python 代码显示如何连接到现有数据库。如果数据库不存在,则将创建该数据库,最后返回一个数据库对象。PostgreSQL 的默认数据库名称为 postrgre。因此,我们将其作为数据库名称提供。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="postgres", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#使用execute()方法执行MYSQL函数
cursor.execute("select version()")
# 使用 fetchone() 方法获取单行。
data = cursor.fetchone()
print("Connection established to: ",data)
#关闭连接
conn.close()
Connection established to: (
'PostgreSQL 11.5, compiled by Visual C++ build 1914, 64-bit',
)
输出
Connection established to: ( 'PostgreSQL 11.5, compiled by Visual C++ build 1914, 64-bit', )
Python PostgreSQL - 创建数据库
您可以使用 CREATE DATABASE 语句在 PostgreSQL 中创建数据库。您可以在 PostgreSQL shell 提示符中执行此语句,方法是在命令后指定要创建的数据库的名称。
语法
以下是 CREATE DATABASE 语句的语法。
CREATE DATABASE dbname;
示例
以下语句在 PostgreSQL 中创建一个名为 testdb 的数据库。
postgres=# CREATE DATABASE testdb; CREATE DATABASE
您可以使用 \l 命令列出 PostgreSQL 中的数据库。如果您验证数据库列表,则可以找到新创建的数据库,如下所示 −
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype |
-----------+----------+----------+----------------------------+-------------+
mydb | postgres | UTF8 | English_United States.1252 | ........... |
postgres | postgres | UTF8 | English_United States.1252 | ........... |
template0 | postgres | UTF8 | English_United States.1252 | ........... |
template1 | postgres | UTF8 | English_United States.1252 | ........... |
testdb | postgres | UTF8 | English_United States.1252 | ........... |
(5 rows)
您还可以使用命令 createdb(SQL 语句 CREATE DATABASE 的包装器)从命令提示符在 PostgreSQL 中创建数据库。
C:\Program Files\PostgreSQL\11\bin> createdb -h localhost -p 5432 -U postgres sampledb Password:
使用 python 创建数据库
psycopg2 的游标类提供了各种方法来执行各种 PostgreSQL 命令、获取记录和复制数据。您可以使用 Connection 类的 cursor() 方法创建游标对象。
此类的 execute() 方法接受 PostgreSQL 查询作为参数并执行它。
因此,要在 PostgreSQL 中创建数据库,请使用此方法执行 CREATE DATABASE 查询。
示例
以下 Python 示例在 PostgreSQL 数据库中创建一个名为 mydb 的数据库。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="postgres", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#准备查询以创建数据库
sql = '''CREATE database mydb''';
#创建数据库
cursor.execute(sql)
print("Database created successfully........")
#关闭连接
conn.close()
输出
Database created successfully........
Python PostgreSQL - 创建表
您可以使用 CREATE TABLE 语句在 PostgreSQL 数据库中创建新表。执行此操作时,您需要指定表的名称、列名及其数据类型。
语法
以下是 PostgreSQL 中 CREATE TABLE 语句的语法。
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, );
示例
以下示例在 PostgreSQL 中创建一个名为 CRICKETERS 的表。
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age INT, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
您可以使用 \dt 命令获取 PostgreSQL 数据库中的表列表。创建表后,如果您可以验证表列表,则可以在其中观察到新创建的表,如下所示 −
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------+-------+----------
public | cricketers | table | postgres
(1 row)
postgres=#
同样,您可以使用 \d 获取已创建表的描述,如下所示 −
postgres=# \d cricketers
Table "public.cricketers"
Column | Type | Collation | Nullable | Default
----------------+------------------------+-----------+----------+---------
first_name | character varying(255) | | |
last_name | character varying(255) | | |
age | integer | | |
place_of_birth | character varying(255) | | |
country | character varying(255) | | |
postgres=#
使用 python 创建表
要使用 python 创建表,您需要使用 pyscopg2 的 Cursor 的 execute() 方法执行 CREATE TABLE 语句。
示例
以下 Python 示例创建一个名为 employee 的表。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#根据要求创建表
sql ='''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
print("Table created successfully........")
conn.commit()
#关闭连接
conn.close()
输出
Table created successfully........
Python PostgreSQL - 插入数据
您可以使用 INSERT INTO 语句将记录插入到 PostgreSQL 中的现有表中。执行此操作时,您需要指定表的名称以及其中列的值。
语法
以下是 INSERT 语句的推荐语法 −
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
其中,column1、column2、column3、.. 是表的列名称,value1、value2、value3、... 是需要插入到表中的值。
示例
假设我们使用 CREATE TABLE 语句创建了一个名为 CRICKETERS 的表,如下所示 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age INT, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
以下 PostgreSQL 语句在上面创建的表中插入一行 −
postgres=# insert into CRICKETERS (
First_Name, Last_Name, Age, Place_Of_Birth, Country)
values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=#
使用 INSERT INTO 语句插入记录时,如果跳过任何列名,则将插入记录并在跳过的列处留下空格。
postgres=# insert into CRICKETERS (First_Name, Last_Name, Country)
values('Jonathan', 'Trott', 'SouthAfrica');
INSERT 0 1
如果传递的值的顺序与表中相应的列名相同,您也可以在不指定列名的情况下将记录插入表中。
postgres=# insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
postgres=#
将记录插入表后,您可以使用 SELECT 语句验证其内容,如下所示 −
postgres=# SELECT * from CRICKETERS; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | | | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India (5 rows)
使用 python 插入数据
psycopg2 的游标类提供了一个名为 execute() 方法的方法。此方法接受查询作为参数并执行它。
因此,要使用 python − 将数据插入 PostgreSQL 中的表中
导入 psycopg2 包。
使用 connect() 方法创建连接对象,通过将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过将属性 autocommit 的值设置为 false 来关闭自动提交模式。
psycopg2 库的 Connection 类的 cursor() 方法返回一个游标对象。使用此方法创建一个游标对象。
然后,通过将 INSERT 语句作为参数传递给 execute() 方法执行该语句。
示例
以下 Python 程序在 PostgreSQL 数据库中创建一个名为 EMPLOYEE 的表,并使用 execute() 方法将记录插入其中 −
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
# 准备 SQL 查询以将记录插入数据库。
cursor.execute('''INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX,
INCOME) VALUES ('Ramya', 'Rama priya', 27, 'F', 9000)''')
cursor.execute('''INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX,
INCOME) VALUES ('Vinay', 'Battacharya', 20, 'M', 6000)''')
cursor.execute('''INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX,
INCOME) VALUES ('Sharukh', 'Sheik', 25, 'M', 8300)''')
cursor.execute('''INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX,
INCOME) VALUES ('Sarmista', 'Sharma', 26, 'F', 10000)''')
cursor.execute('''INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX,
INCOME) VALUES ('Tripthi', 'Mishra', 24, 'F', 6000)''')
# 在数据库中提交你的更改
conn.commit()
print("Records inserted........")
# 关闭连接
conn.close()
输出
Records inserted........
Python PostgreSQL - Select 选择数据
您可以使用 SELECT 语句检索 PostgreSQL 中现有表的内容。在此语句中,您需要指定表的名称,它会以表格格式返回其内容,这被称为结果集。
语法
以下是 PostgreSQL 中 SELECT 语句的语法 −
SELECT column1, column2, columnN FROM table_name;
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下 SELECT 查询从 CRICKETERS 表中检索 FIRST_NAME、LAST_NAME 和 COUNTRY 列的值。
postgres=# SELECT FIRST_NAME, LAST_NAME, COUNTRY FROM CRICKETERS; first_name | last_name | country ------------+------------+------------- Shikhar | Dhawan | India Jonathan | Trott | SouthAfrica Kumara | Sangakkara | Srilanka Virat | Kohli | India Rohit | Sharma | India (5 rows)
如果要检索每条记录的所有列,则需要用"*"替换列名称,如下所示 −
postgres=# SELECT * FROM CRICKETERS; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | 38 | CapeTown | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India (5 rows) postgres=#
使用 python 检索数据
对任何数据库执行 READ 操作意味着从数据库获取一些有用的信息。您可以使用 psycopg2 提供的 fetch() 方法从 PostgreSQL 获取数据。
Cursor 类提供了三种方法,即 fetchall()、fetchmany() 和 fetchone(),
fetchall() 方法检索查询结果集中的所有行并将它们作为元组列表返回。 (如果我们在检索几行后执行此操作,它将返回剩余的行)。
fetchone() 方法获取查询结果中的下一行并将其作为元组返回。
fetchmany() 方法类似于 fetchone(),但它检索查询结果集中的下一组行,而不是单个行。
注意 − 结果集是使用游标对象查询表时返回的对象。
示例
以下 Python 程序连接到 PostgreSQL 的名为 mydb 的数据库并从名为 EMPLOYEE 的表中检索所有记录。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索数据
cursor.execute('''SELECT * from EMPLOYEE''')
#从表中获取第一行
result = cursor.fetchone();
print(result)
#从表中获取第一行
result = cursor.fetchall();
print(result)
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
('Ramya', 'Rama priya', 27, 'F', 9000.0)
[('Vinay', 'Battacharya', 20, 'M', 6000.0),
('Sharukh', 'Sheik', 25, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Python PostgreSQL - Where 子句
在执行 SELECT、UPDATE 或 DELETE 操作时,您可以使用 WHERE 子句指定条件来过滤记录。操作将对满足给定条件的记录执行。
语法
以下是 PostgreSQL 中 WHERE 子句的语法 −
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
您可以使用比较或逻辑运算符指定 search_condition。如 >、<、=、LIKE、NOT 等。以下示例将使这个概念更加清晰。
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下 SELECT 语句检索年龄大于 35 的记录 −
postgres=# SELECT * FROM CRICKETERS WHERE AGE > 35; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Jonathan | Trott | 38 | CapeTown | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka (2 rows) postgres=#
使用 Python 的 Where 子句
要使用 Python 程序从表中获取特定记录,请执行带有 WHERE 子句的 SELECT 语句,并将其作为参数传递给 execute() 方法。
示例
以下 Python 示例演示了如何使用 Python 来使用 WHERE 命令。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#填充表
insert_stmt = "INSERT INTO EMPLOYEE (FIRST_NAME, LAST_NAME, AGE, SEX, INCOME)
VALUES (%s, %s, %s, %s, %s)"
data = [('Krishna', 'Sharma', 19, 'M', 2000),
('Raj', 'Kandukuri', 20, 'M', 7000),
('Ramya', 'Ramapriya', 25, 'M', 5000),
('Mac', 'Mohan', 26, 'M', 2000)]
cursor.executemany(insert_stmt, data)
#使用 where 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE WHERE AGE <23")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Krishna', 'Sharma', 19, 'M', 2000.0), ('Raj', 'Kandukuri', 20, 'M', 7000.0)]
Python PostgreSQL - Order By 子句
通常,如果您尝试从表中检索数据,您将按照插入记录的顺序获取记录。
使用 ORDER BY 子句,在检索表的记录时,您可以根据所需的列按升序或降序对结果记录进行排序。
语法
以下是 PostgreSQL 中 ORDER BY 子句的语法。
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下 SELECT 语句按年龄升序检索 CRICKETERS 表中的行 −
postgres=# SELECT * FROM CRICKETERS ORDER BY AGE; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | 38 | CapeTown | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka (5 rows)es:
您可以使用多个列对表的记录进行排序。以下 SELECT 语句根据 age 和 FIRST_NAME 列对 CRICKETERS 表的记录进行排序。
postgres=# SELECT * FROM CRICKETERS ORDER BY AGE, FIRST_NAME; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | 38 | CapeTown | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka (5 rows)
默认情况下,ORDER BY子句按升序对表的记录进行排序。您可以使用 DESC 按降序排列结果,如下所示 −
postgres=# SELECT * FROM CRICKETERS ORDER BY AGE DESC; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Kumara | Sangakkara | 41 | Matale | Srilanka Jonathan | Trott | 38 | CapeTown | SouthAfrica Shikhar | Dhawan | 33 | Delhi | India Rohit | Sharma | 32 | Nagpur | India Virat | Kohli | 30 | Delhi | India (5 rows)
使用 Python 的 ORDER BY 子句
要按特定顺序检索表的内容,请在游标对象上调用 execute() 方法,并将 SELECT 语句与 ORDER BY 子句一起作为参数传递给它。
示例
在下面的示例中,我们将创建一个包含姓名和员工的表,填充它,并使用 ORDER BY 子句按年龄的(升序)顺序检索其记录。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#创建一个表
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT, SEX CHAR(1),
INCOME INT,
CONTACT INT
)'''
cursor.execute(sql)
#填充表
insert_stmt = "INSERT INTO EMPLOYEE (
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME, CONTACT) VALUES
(%s, %s, %s, %s, %s, %s)"
data = [('Krishna', 'Sharma', 26, 'M', 2000, 101),
('Raj', 'Kandukuri', 20, 'M', 7000, 102),
('Ramya', 'Ramapriya', 29, 'F', 5000, 103),
('Mac', 'Mohan', 26, 'M', 2000, 104)]
cursor.executemany(insert_stmt, data)
conn.commit()
#使用 ORDER BY 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE ORDER BY AGE")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Sharukh', 'Sheik', 25, 'M', 8300.0), ('Sarmista', 'Sharma', 26, 'F', 10000.0)]
Python PostgreSQL - 更新表
您可以使用 UPDATE 语句修改 PostgreSQL 中表的现有记录的内容。要更新特定行,您需要与其一起使用 WHERE 子句。
语法
以下是 PostgreSQL 中 UPDATE 语句的语法 −
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下语句修改了运动员的年龄,其名字是Shikhar −
postgres=# UPDATE CRICKETERS SET AGE = 45 WHERE FIRST_NAME = 'Shikhar' ; UPDATE 1 postgres=#
如果您检索 FIRST_NAME 为 Shikhar 的记录,您会发现年龄值已更改为 45 −
postgres=# SELECT * FROM CRICKETERS WHERE FIRST_NAME = 'Shikhar'; first_name | last_name | age | place_of_birth | country ------------+-----------+-----+----------------+--------- Shikhar | Dhawan | 45 | Delhi | India (1 row) postgres=#
如果您没有使用 WHERE 子句,所有记录的值都将被更新。以下 UPDATE 语句将 CRICKETERS 表中所有记录的年龄增加 1 −
postgres=# UPDATE CRICKETERS SET AGE = AGE+1; UPDATE 5
如果您使用 SELECT 命令检索表的内容,您可以看到更新的值如下 −
postgres=# SELECT * FROM CRICKETERS; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Jonathan | Trott | 39 | CapeTown | SouthAfrica Kumara | Sangakkara | 42 | Matale | Srilanka Virat | Kohli | 31 | Delhi | India Rohit | Sharma | 33 | Nagpur | India Shikhar | Dhawan | 46 | Delhi | India (5 rows)
使用 python 更新记录
psycopg2 的游标类提供了一个名为 execute() 方法的方法。此方法接受查询作为参数并执行它。
因此,要使用 python − 将数据插入 PostgreSQL 中的表中
导入 psycopg2 包。
使用 connect() 方法创建连接对象,通过将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过将属性 autocommit 的值设置为 false 来关闭自动提交模式。
psycopg2 库的 Connection 类的 cursor() 方法返回一个游标对象。使用此方法创建一个游标对象。
然后,通过将 UPDATE 语句作为参数传递给 execute() 方法执行该语句。
示例
以下 Python 代码更新 Employee 表的内容并检索结果 −
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#获取更新前的所有行
print("Contents of the Employee table: ")
sql = '''SELECT * from EMPLOYEE'''
cursor.execute(sql)
print(cursor.fetchall())
#更新记录
sql = "UPDATE EMPLOYEE SET AGE = AGE + 1 WHERE SEX = 'M'"
cursor.execute(sql)
print("Table updated...... ")
#获取更新后的所有行
print("Contents of the Employee table after the update operation: ")
sql = '''SELECT * from EMPLOYEE'''
cursor.execute(sql)
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Contents of the Employee table:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Vinay', 'Battacharya', 20, 'M', 6000.0),
('Sharukh', 'Sheik', 25, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Table updated......
Contents of the Employee table after the update operation:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0),
('Vinay', 'Battacharya', 21, 'M', 6000.0),
('Sharukh', 'Sheik', 26, 'M', 8300.0)]
Python PostgreSQL - Delete 删除数据
您可以使用 PostgreSQL 数据库的 DELETE FROM 语句删除现有表中的记录。要删除特定记录,您需要与其一起使用 WHERE 子句。
语法
以下是 PostgreSQL 中 DELETE 查询的语法 −
DELETE FROM table_name [WHERE 子句]
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values ('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下语句删除 LAST_NAME 为"Sangakkara"的运动员的记录。 −
postgres=# DELETE FROM CRICKETERS WHERE LAST_NAME = 'Sangakkara'; DELETE 1
如果使用 SELECT 语句检索表的内容,则只能看到 4 条记录,因为我们已删除了一条。
postgres=# SELECT * FROM CRICKETERS; first_name | last_name | age | place_of_birth | country ------------+-----------+-----+----------------+------------- Jonathan | Trott | 39 | CapeTown | SouthAfrica Virat | Kohli | 31 | Delhi | India Rohit | Sharma | 33 | Nagpur | India Shikhar | Dhawan | 46 | Delhi | India (4 rows)
如果执行不带 WHERE 子句的 DELETE FROM 语句,则指定表中的所有记录都将被删除。
postgres=# DELETE FROM CRICKETERS; DELETE 4
由于您已删除所有记录,如果您尝试使用 SELECT 语句检索 CRICKETERS 表的内容,您将获得一个空结果集,如下所示 −
postgres=# SELECT * FROM CRICKETERS; first_name | last_name | age | place_of_birth | country ------------+-----------+-----+----------------+--------- (0 rows)
使用 python 删除数据
psycopg2 的 cursor 类提供了一个名为 execute() 方法的方法。此方法接受查询作为参数并执行它。
因此,要使用 python − 将数据插入 PostgreSQL 中的表中
导入 psycopg2 包。
使用 connect() 方法创建连接对象,通过将用户名、密码、主机(可选默认值:localhost)和数据库(可选)作为参数传递给它。
通过将属性 autocommit 的值设置为 false 来关闭自动提交模式。
psycopg2 库的 Connection 类的 cursor() 方法返回一个游标对象。使用此方法创建一个游标对象。
然后,通过将 UPDATE 语句作为参数传递给 execute() 方法执行该语句。
示例
以下 Python 代码删除 EMPLOYEE 表中年龄值大于 25 的记录 −
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索表的内容
print("Contents of the table: ")
cursor.execute('''SELECT * from EMPLOYEE''')
print(cursor.fetchall())
#删除记录
cursor.execute('''DELETE FROM EMPLOYEE WHERE AGE > 25''')
#删除后检索数据
print("Contents of the table after delete operation ")
cursor.execute("SELECT * from EMPLOYEE")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Contents of the table:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0),
('Vinay', 'Battacharya', 21, 'M', 6000.0),
('Sharukh', 'Sheik', 26, 'M', 8300.0)]
Contents of the table after delete operation:
[('Tripthi', 'Mishra', 24, 'F', 6000.0),
('Vinay', 'Battacharya', 21, 'M', 6000.0)]
Python PostgreSQL - Drop Table 删除表
您可以使用 DROP TABLE 语句从 PostgreSQL 数据库中删除表。
语法
以下是 PostgreSQL 中 DROP TABLE 语句的语法 −
DROP TABLE table_name;
示例
假设我们使用以下查询创建了两个名为 CRICKETERS 和 EMPLOYEES 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=# postgres=# CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); CREATE TABLE postgres=#
现在,如果您使用"\dt"命令验证表列表,您可以看到上面创建的表 −
postgres=# \dt; List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | cricketers | table | postgres public | employee | table | postgres (2 rows) postgres=#
以下语句从数据库中删除名为 Employee 的表 −
postgres=# DROP table employee; DROP TABLE
由于您已删除 Employee 表,因此如果您再次检索表列表,则只能看到其中的一个表。
postgres=# \dt; List of relations Schema | Name | Type | Owner --------+------------+-------+---------- public | cricketers | table | postgres (1 row) postgres=#
如果您再次尝试删除 Employee 表,由于您已经删除了它,您将收到一条错误消息,提示"table does not exist",如下所示−
postgres=# DROP table employee; ERROR: table "employee" does not exist postgres=#
要解决此问题,您可以将 IF EXISTS 子句与 DELETE 语句一起使用。如果表存在,则删除该表,否则跳过 DELETE 操作。
postgres=# DROP table IF EXISTS employee; NOTICE: table "employee" does not exist, skipping DROP TABLE postgres=#
使用 Python 删除整个表
您可以使用 DROP 语句随时删除表。但是删除任何现有表时需要非常小心,因为删除表后丢失的数据将无法恢复。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加
cursor.execute("DROP TABLE emp")
print("Table dropped... ")
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
#Table dropped...
Python PostgreSQL - Limit 限制子句
执行 PostgreSQL SELECT 语句时,可以使用 LIMIT 子句限制其结果中的记录数。
语法
以下是 PostgreSQL 中 LMIT 子句的语法 −
SELECT column1, column2, columnN FROM table_name LIMIT [行数]
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); CREATE TABLE postgres=#
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
postgres=# insert into CRICKETERS values ('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Virat', 'Kohli', 30, 'Delhi', 'India');
INSERT 0 1
postgres=# insert into CRICKETERS values ('Rohit', 'Sharma', 32, 'Nagpur', 'India');
INSERT 0 1
以下语句使用 LIMIT 子句检索 Cricketers 表的前 3 条记录 −
postgres=# SELECT * FROM CRICKETERS LIMIT 3; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+------------- Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | 38 | CapeTown | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka (3 rows)
如果您想要获取从特定记录(偏移量)开始的记录,可以使用 OFFSET 子句和 LIMIT 来实现。
postgres=# SELECT * FROM CRICKETERS LIMIT 3 OFFSET 2; first_name | last_name | age | place_of_birth | country ------------+------------+-----+----------------+---------- Kumara | Sangakkara | 41 | Matale | Srilanka Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India (3 rows) postgres=#
使用 Python 的限制子句
以下 Python 示例检索名为 EMPLOYEE 的表的内容,将结果中的记录数限制为 2 −
示例
import psycopg2 #建立连接 conn = psycopg2.connect( database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432' ) #设置自动提交为 false conn.autocommit = True #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMPLOYEE LIMIT 2 OFFSET 2''' #执行查询 cursor.execute(sql) #获取数据 result = cursor.fetchall(); print(result) #在数据库中提交你的更改 conn.commit() #关闭连接 conn.close()
输出
[('Sharukh', 'Sheik', 25, 'M', 8300.0), ('Sarmista', 'Sharma', 26, 'F', 10000.0)]
Python PostgreSQL - 连接
将数据分成两个表后,可以使用连接从这两个表中获取组合记录。
示例
假设我们创建了一个名为 CRICKETERS 的表,并在其中插入了 5 条记录,如下所示 −
postgres=# CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); postgres=# insert into CRICKETERS values ( 'Shikhar', 'Dhawan', 33, 'Delhi', 'India' ); postgres=# insert into CRICKETERS values ( 'Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica' ); postgres=# insert into CRICKETERS values ( 'Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka' ); postgres=# insert into CRICKETERS values ( 'Virat', 'Kohli', 30, 'Delhi', 'India' ); postgres=# insert into CRICKETERS values ( 'Rohit', 'Sharma', 32, 'Nagpur', 'India' );
并且,如果我们创建了另一个名为 OdiStats 的表,并在其中插入 5 条记录,如下所示 −
postgres=# CREATE TABLE ODIStats (
First_Name VARCHAR(255), Matches INT, Runs INT, AVG FLOAT,
Centuries INT, HalfCenturies INT
);
postgres=# insert into OdiStats values ('Shikhar', 133, 5518, 44.5, 17, 27);
postgres=# insert into OdiStats values ('Jonathan', 68, 2819, 51.25, 4, 22);
postgres=# insert into OdiStats values ('Kumara', 404, 14234, 41.99, 25, 93);
postgres=# insert into OdiStats values ('Virat', 239, 11520, 60.31, 43, 54);
postgres=# insert into OdiStats values ('Rohit', 218, 8686, 48.53, 24, 42);
以下语句检索结合这两个表中的值的数据 −
postgres=# SELECT Cricketers.First_Name, Cricketers.Last_Name, Cricketers.Country, OdiStats.matches, OdiStats.runs, OdiStats.centuries, OdiStats.halfcenturies from Cricketers INNER JOIN OdiStats ON Cricketers.First_Name = OdiStats.First_Name; first_name | last_name | country | matches | runs | centuries | halfcenturies ------------+------------+-------------+---------+-------+-----------+--------------- Shikhar | Dhawan | India | 133 | 5518 | 17 | 27 Jonathan | Trott | SouthAfrica | 68 | 2819 | 4 | 22 Kumara | Sangakkara | Srilanka | 404 | 14234 | 25 | 93 Virat | Kohli | India | 239 | 11520 | 43 | 54 Rohit | Sharma | India | 218 | 8686 | 24 | 42 (5 rows) postgres=#
使用 Python 进行连接
将数据分成两个表后,可以使用连接从这两个表中获取组合记录。
示例
以下 Python 程序演示了 JOIN 子句的用法−
import psycopg2 #建立连接 conn = psycopg2.connect( database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432' ) #设置自动提交为 false conn.autocommit = True #使用 cursor() 方法创建游标对象 cursor = conn.cursor() #检索单行 sql = '''SELECT * from EMP INNER JOIN CONTACT ON EMP.CONTACT = CONTACT.ID''' #执行查询 cursor.execute(sql) #从表中获取第一行 result = cursor.fetchall(); print(result) #在数据库中提交你的更改 conn.commit() #关闭连接 conn.close()
输出
[('Ramya', 'Rama priya', 27, 'F', 9000.0, 101, 101, 'Krishna@mymail.com', 'Hyderabad'),
('Vinay', 'Battacharya', 20, 'M', 6000.0, 102, 102, 'Raja@mymail.com', 'Vishakhapatnam'),
('Sharukh', 'Sheik', 25, 'M', 8300.0, 103, 103, 'Krishna@mymail.com ', 'Pune'),
('Sarmista', 'Sharma', 26, 'F', 10000.0, 104, 104, 'Raja@mymail.com', 'Mumbai')]
Python PostgreSQL - Cursor 对象
psycopg 库的 Cursor 类提供使用 Python 代码在数据库中执行 PostgreSQL 命令的方法。
使用它的方法,您可以执行 SQL 语句、从结果集中获取数据、调用过程。
您可以使用 Connection 对象/类的 cursor() 方法创建 Cursor 对象。
示例
import psycopg2 #建立连接 conn = psycopg2.connect( database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432' ) #设置自动提交为 false conn.autocommit = True #使用 cursor() 方法创建游标对象 cursor = conn.cursor()
方法
以下是 Cursor 类/对象提供的各种方法。
| Sr.No | 方法 &描述 |
|---|---|
| 1 | callproc() 该方法用于调用PostgreSQL数据库中现有的过程。 |
| 2 | close() 该方法用于关闭当前游标对象。 |
| 3 | executemany() 该方法接受一个list系列的参数列表。准备一个 MySQL 查询并使用所有参数执行它。 |
| 4 | execute() 此方法接受 MySQL 查询作为参数并执行给定的查询。 |
| 5 | fetchall() 此方法检索查询结果集中的所有行并将它们作为元组列表返回。 (如果我们在检索几行后执行此操作,它将返回剩余的行) |
| 6 | fetchone() 此方法获取查询结果中的下一行并将其作为元组返回。 |
| 7 | fetchmany() 此方法类似于 fetchone(),但它检索查询结果集中的下一组行,而不是单个行。 |
属性
以下是 Cursor 类的属性 −
| Sr.No | 属性 &描述 |
|---|---|
| 1 | description 这是一个只读属性,它返回包含结果集中列描述的列表。 |
| 2 | astrowid 这是一个只读属性,如果表中有任何自动增加的列,它将返回上次 INSERT 或 UPDATE 操作中为该列生成的值。 |
| 3 | rowcount 这将返回 SELECT 和 UPDATE 操作中返回/更新的行数。 |
| 4 | closed 此属性指定游标是否已关闭,如果已关闭则返回 true,否则返回 false。 |
| 5 | connection 这将返回对创建此游标所用的连接对象的引用。 |
| 6 | name 此属性返回游标的名称。 |
| 7 | scrollable 此属性指定特定游标是否可滚动。 |
Python SQLite - 简介
安装
SQLite3 可以使用由 Gerhard Haring 编写的 sqlite3 模块与 Python 集成。它提供了符合 PEP 249 描述的 DB-API 2.0 规范的 SQL 接口。您无需单独安装此模块,因为它默认随 Python 2.5.x 版及更高版本一起提供。
要使用 sqlite3 模块,您必须首先创建一个代表数据库的连接对象,然后可以选择创建一个游标对象,这将帮助您执行所有 SQL 语句。
Python sqlite3 模块 API
以下是重要的 sqlite3 模块例程,它们可以满足您在 Python 程序中使用 SQLite 数据库的要求。如果您正在寻找更复杂的应用程序,那么您可以查看 Python sqlite3 模块的官方文档。
| Sr.No. | API 和说明 |
|---|---|
| 1 | sqlite3.connect(database [,timeout ,other optional arguments]) 此 API 打开与 SQLite 数据库文件的连接。您可以使用":memory:"打开与驻留在 RAM 中而不是磁盘上的数据库的数据库连接。如果数据库成功打开,它将返回一个连接对象。 |
| 2 | connection.cursor([cursorClass]) 此例程创建一个游标,它将在使用 Python 进行数据库编程的整个过程中使用。此方法接受单个可选参数 cursorClass。如果提供,这必须是扩展 sqlite3.Cursor 的自定义游标类。 |
| 3 | cursor.execute(sql [, 可选参数]) 此例程执行 SQL 语句。 SQL 语句可以参数化(即占位符而不是 SQL 文字)。sqlite3 模块支持两种占位符:问号和命名占位符(命名样式)。 例如 − cursor.execute("insert into people values (?, ?)", (who, age)) |
| 4 | connection.execute(sql [, 可选参数]) 此例程是游标对象提供的上述执行方法的快捷方式,它通过调用游标方法创建一个中间游标对象,然后使用给定的参数调用游标的执行方法。 |
| 5 | cursor.executemany(sql, seq_of_parameters) 此例程针对序列 sql 中找到的所有参数序列或映射执行 SQL 命令。 |
| 6 | connection.executemany(sql[, parameters]) 此例程是一种快捷方式,它通过调用 cursor 方法创建一个中间游标对象,然后使用给定的参数调用 cursor.s executemany 方法。 |
| 7 | cursor.executescript(sql_script) 此例程一次执行以脚本形式提供的多个 SQL 语句。它首先发出 COMMIT 语句,然后执行作为参数获取的 SQL 脚本。所有 SQL 语句都应以分号 (;) 分隔。 |
| 8 | connection.executescript(sql_script) 此例程是一种快捷方式,它通过调用 cursor 方法创建中间游标对象,然后使用给定的参数调用游标的 executescript 方法。 |
| 9 | connection.total_changes() 此例程返回自打开数据库连接以来已修改、插入或删除的数据库行总数。 |
| 10 | connection.commit() 此方法提交当前事务。如果不调用此方法,自上次调用 commit() 以来所做的任何操作都不会在其他数据库连接中可见。 |
| 11 | connection.rollback() 此方法可回滚自上次调用 commit() 以来对数据库所做的任何更改。 |
| 12 | connection.close() 此方法可关闭数据库连接。请注意,这并不会自动调用 commit()。如果您没有先调用 commit() 就直接关闭数据库连接,您的更改将会丢失! |
| 13 | cursor.fetchone() 此方法获取查询结果集的下一行,返回单个序列,或者在没有更多数据可用时返回 None。 |
| 14 | cursor.fetchmany([size = cursor.arraysize]) 此例程获取查询结果的下一组行,返回一个列表。当没有更多行可用时,将返回一个空列表。该方法尝试获取 size 参数所指示的尽可能多的行。 |
| 15 | cursor.fetchall() 此例程获取查询结果的所有(剩余)行,并返回一个列表。当没有可用行时,将返回一个空列表。 |
Python SQLite - 建立连接
要与 SQLite 建立连接,请打开命令提示符,浏览您安装 SQLite 的位置,然后执行命令 sqlite3,如下所示 −
使用 python 建立连接
您可以使用 SQLite3 python 模块与 SQLite2 数据库进行通信。为此,首先您需要建立连接(创建连接对象)。
要使用 python 与 SQLite3 数据库建立连接,您需要 −
使用 import 语句导入 sqlite3 模块。
connect() 方法接受您需要连接的数据库的名称作为参数,并返回一个 Connection 对象。
示例
import sqlite3
conn = sqlite3.connect('example.db')
输出
print("Connection established ..........")
Python SQLite - 创建表
使用 SQLite CREATE TABLE 语句,您可以在数据库中创建表。
语法
以下是在 SQLite 数据库中创建表的语法 −
CREATE TABLE database_name.table_name( column1 datatype PRIMARY KEY(one or more columns), column2 datatype, column3 datatype, ..... columnN datatype );
示例
以下 SQLite 查询/语句在 SQLite 数据库中创建一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
让我们再创建一个表 OdiStats,描述 CRICKETERS 表中每个球员的单日统计数据。
sqlite> CREATE TABLE ODIStats ( First_Name VARCHAR(255), Matches INT, Runs INT, AVG FLOAT, Centuries INT, HalfCenturies INT ); sqlite
您可以使用 .tables 命令获取 SQLite 数据库中的表列表。创建表后,如果您可以验证表列表,则可以在其中观察到新创建的表为 −
sqlite> . tables CRICKETERS ODIStats sqlite>
使用 python 创建表
Cursor 对象包含执行查询和获取数据等的所有方法。连接类的 cursor 方法返回一个 cursor 对象。
因此,要使用 python 在 SQLite 数据库中创建表 −
使用 connect() 方法与数据库建立连接。
通过调用上面创建的连接对象上的 cursor() 方法创建 cursor 对象。
现在使用 Cursor 类的 execute() 方法执行 CREATE TABLE 语句。
示例
以下 Python 程序在 SQLite3 中创建一个名为 Employee 的表 −
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#根据要求创建表
sql ='''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
print("Table created successfully........")
# 在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Table created successfully........
Python SQLite - 插入数据
您可以使用 INSERT INTO 语句向 SQLite 的现有表中添加新行。在此,您需要指定表的名称、列名和值(与列名的顺序相同)。
语法
以下是 INSERT 语句的推荐语法 −
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
其中,column1、column2、column3、.. 是表的列名称,value1、value2、value3、... 是您需要插入到表中的值。
示例
假设我们使用 CREATE TABLE 语句创建了一个名为 CRICKETERS 的表,如下所示 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
以下 PostgreSQL 语句在上面创建的表中插入一行。
sqlite> insert into CRICKETERS
(First_Name, Last_Name, Age, Place_Of_Birth, Country) values
('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite>
使用 INSERT INTO 语句插入记录时,如果跳过任何列名,则插入该记录时会在跳过的列处留下空格。
sqlite> insert into CRICKETERS
(First_Name, Last_Name, Country) values
('Jonathan', 'Trott', 'SouthAfrica');
sqlite>
如果传递的值的顺序与表中相应的列名相同,您也可以在不指定列名的情况下将记录插入表中。
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
将记录插入表后,您可以使用 SELECT 语句验证其内容,如下所示 −
sqlite> select * from cricketers; Shikhar | Dhawan | 33 | Delhi | India Jonathan | Trott | | | SouthAfrica Kumara | Sangakkara | 41 | Matale | Srilanka Virat | Kohli | 30 | Delhi | India Rohit | Sharma | 32 | Nagpur | India sqlite>
使用 python 插入数据
向 SQLite 数据库中的现有表添加记录 −
导入 sqlite3 包。
使用 connect() 方法通过将数据库名称作为参数传递给它来创建连接对象。
cursor() 方法返回一个游标对象,您可以使用该对象与 SQLite3 进行通信。通过在(上面创建的)Connection 对象上调用 cursor() 对象来创建游标对象。
然后,通过将 INSERT 语句作为参数传递给游标对象,调用游标对象上的 execute() 方法。
示例
以下 python 示例将记录插入到名为 EMPLOYEE 的表中 −
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
# 准备 SQL 查询以将记录插入数据库。
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Ramya', 'Rama Priya', 27, 'F', 9000)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Vinay', 'Battacharya', 20, 'M', 6000)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Sharukh', 'Sheik', 25, 'M', 8300)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Sarmista', 'Sharma', 26, 'F', 10000)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Tripthi', 'Mishra', 24, 'F', 6000)''')
# 在数据库中提交你的更改
conn.commit()
print("Records inserted........")
# 关闭连接
conn.close()
输出
Records inserted........
Python SQLite - 选择数据
您可以使用 SELCT 查询从 SQLite 表中检索数据。此查询/语句以表格形式返回指定关系(表)的内容,并称为结果集。
语法
以下是 SQLite 中 SELECT 语句的语法 −
SELECT column1, column2, columnN FROM table_name;
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
以下 SELECT 查询从 CRICKETERS 表中检索 FIRST_NAME、LAST_NAME 和 COUNTRY 列的值。
sqlite> SELECT FIRST_NAME, LAST_NAME, COUNTRY FROM CRICKETERS; Shikhar |Dhawan |India Jonathan |Trott |SouthAfrica Kumara |Sangakkara |Srilanka Virat |Kohli |India Rohit |Sharma |India sqlite>
如您所见,SQLite 数据库的 SELECT 语句仅返回指定表的记录。要获得格式化的输出,您需要在 SELECT 语句之前使用相应的命令设置 header 和 mode,如下所示 −
sqlite> .header on sqlite> .mode column sqlite> SELECT FIRST_NAME, LAST_NAME, COUNTRY FROM CRICKETERS; First_Name Last_Name Country ---------- -------------------- ---------- Shikhar Dhawan India Jonathan Trott SouthAfric Kumara Sangakkara Srilanka Virat Kohli India Rohit Sharma India sqlite>
如果要检索每条记录的所有列,则需要用"*"替换列名称,如下所示 −
sqlite> .header on sqlite> .mode column sqlite> SELECT * FROM CRICKETERS; First_Name Last_Name Age Place_Of_Birth Country ---------- ---------- ---------- -------------- ---------- Shikhar Dhawan 33 Delhi India Jonathan Trott 38 CapeTown SouthAfric Kumara Sangakkara 41 Matale Srilanka Virat Kohli 30 Delhi India Rohit Sharma 32 Nagpur India sqlite>
在 SQLite 中,默认情况下列的宽度为 10,超出此宽度的值将被截断(观察上表中第二行的国家/地区列)。您可以使用 .width 命令将每列的宽度设置为所需值,然后检索表格的内容,如下所示−
sqlite> .width 10, 10, 4, 10, 13 sqlite> SELECT * FROM CRICKETERS; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Shikhar Dhawan 33 Delhi India Jonathan Trott 38 CapeTown SouthAfrica Kumara Sangakkara 41 Matale Srilanka Virat Kohli 30 Delhi India Rohit Sharma 32 Nagpur India sqlite>
使用 python 检索数据
对任何数据库执行 READ 操作都意味着从数据库中提取一些有用的信息。您可以使用 sqlite python 模块提供的 fetch() 方法从 MYSQL 中提取数据。
sqlite3.Cursor 类提供了三种方法,即 fetchall()、fetchmany() 和 fetchone(),
fetchall() 方法检索查询结果集中的所有行并将它们作为元组列表返回。 (如果我们在检索几行之后执行此操作,它将返回剩余的行)。
fetchone() 方法获取查询结果中的下一行并将其作为元组返回。
fetchmany() 方法类似于 fetchone(),但它检索查询结果集中的下一组行,而不是单行。
注意 −结果集是使用游标对象查询表时返回的对象。
示例
以下示例使用 SELECT 查询获取 EMPLOYEE 表的所有行,从最初获得的结果集中,我们使用 fetchone() 方法检索第一行,然后使用 fetchall() 方法获取其余行。
以下 Python 程序显示如何从上述示例中创建的 COMPANY 表中获取和显示记录。
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索数据
cursor.execute('''SELECT * from EMPLOYEE''')
#从表中获取第一行
result = cursor.fetchone();
print(result)
#从表中获取第一行
result = cursor.fetchall();
print(result)
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
('Ramya', 'Rama priya', 27, 'F', 9000.0)
[('Vinay', 'Battacharya', 20, 'M', 6000.0),
('Sharukh', 'Sheik', 25, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)
]
Python SQLite - Where 子句
如果要在 SQLite 中获取、删除或更新表的特定行,则需要使用 where 子句指定条件来过滤要执行操作的表行。
例如,如果您有一个带有 where 子句的 SELECT 语句,则只会检索满足指定条件的行。
语法
以下是 SQLite 中 WHERE 子句的语法 −
SELECT column1, column2, columnN FROM table_name WHERE [search_condition]
您可以使用比较或逻辑运算符指定 search_condition。如 >、<、=、LIKE、NOT 等。以下示例将使这一概念更加清晰。
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
以下 SELECT 语句检索年龄大于 35 的记录 −
sqlite> SELECT * FROM CRICKETERS WHERE AGE > 35; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Jonathan Trott 38 CapeTown SouthAfrica Kumara Sangakkara 41 Matale Srilanka sqlite>
使用 Python 的 Where 子句
Cursor 对象/类包含执行查询和获取数据等的所有方法。连接类的 cursor 方法返回一个 cursor 对象。
因此,要使用 Python 在 SQLite 数据库中创建表 −
使用 connect() 方法与数据库建立连接。
通过调用上面创建的连接对象上的 cursor() 方法创建 cursor 对象。
现在使用 Cursor 类的 execute() 方法执行 CREATE TABLE 语句。
示例
以下示例创建一个名为 Employee 的表并填充它。然后使用 where 子句检索年龄值小于 23 的记录。
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#填充表
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Ramya', 'Rama priya', 27, 'F', 9000)''')
cursor.execute('''INSERT INTO EMPLOYEE
(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Vinay', 'Battacharya', 20, 'M', 6000)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Sharukh', 'Sheik', 25, 'M', 8300)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Sarmista', 'Sharma', 26, 'F', 10000)''')
cursor.execute('''INSERT INTO EMPLOYEE(
FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Tripthi', 'Mishra', 24, 'F', 6000)''')
#使用 where 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE WHERE AGE <23")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Vinay', 'Battacharya', 20, 'M', 6000.0)]
Python SQLite - Order By
使用 SELECT 查询获取数据时,您将按照插入记录的顺序获取记录。
您可以使用 Order By 子句按所需顺序(升序或降序)对结果进行排序。默认情况下,此子句按升序对结果进行排序,如果您需要按降序排列,则需要明确使用"DESC"。
语法
以下是 SQLite 中 ORDER BY 子句的语法。
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
以下 SELECT 语句按年龄升序检索 CRICKETERS 表中的行 −
sqlite> SELECT * FROM CRICKETERS ORDER BY AGE; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Virat Kohli 30 Delhi India Rohit Sharma 32 Nagpur India Shikhar Dhawan 33 Delhi India Jonathan Trott 38 CapeTown SouthAfrica Kumara Sangakkara 41 Matale Srilanka sqlite>
您可以使用多个列对表的记录进行排序。以下 SELECT 语句根据 AGE 和 FIRST_NAME 列对 CRICKETERS 表的记录进行排序。
sqlite> SELECT * FROM CRICKETERS ORDER BY AGE, FIRST_NAME; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Virat Kohli 30 Delhi India Rohit Sharma 32 Nagpur India Shikhar Dhawan 33 Delhi India Jonathan Trott 38 CapeTown SouthAfrica Kumara Sangakkara 41 Matale Srilanka sqlite>
默认情况下,ORDER BY子句按升序对表的记录进行排序,您可以使用 DESC 按降序排列结果 −
sqlite> SELECT * FROM CRICKETERS ORDER BY AGE DESC; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Kumara Sangakkara 41 Matale Srilanka Jonathan Trott 38 CapeTown SouthAfrica Shikhar Dhawan 33 Delhi India Rohit Sharma 32 Nagpur India Virat Kohli 30 Delhi India sqlite>
使用 Python 的 ORDER BY 子句
要按特定顺序检索表的内容,请在游标对象上调用 execute() 方法,并将 SELECT 语句与 ORDER BY 子句一起作为参数传递给它。
示例
在下面的例子中,我们将创建一个包含姓名和员工的表,填充它,并使用 ORDER BY 子句按年龄(升序)顺序检索其记录。
import psycopg2
#建立连接
conn = psycopg2.connect(
database="mydb", user='postgres', password='password', host='127.0.0.1', port= '5432'
)
#设置自动提交为 false
conn.autocommit = True
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#Creating a table
sql = '''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT, SEX CHAR(1),
INCOME INT,
CONTACT INT
)'''
cursor.execute(sql)
#填充表
#填充表
cursor.execute('''INSERT INTO EMPLOYEE
(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Ramya', 'Rama priya', 27, 'F', 9000),
('Vinay', 'Battacharya', 20, 'M', 6000),
('Sharukh', 'Sheik', 25, 'M', 8300),
('Sarmista', 'Sharma', 26, 'F', 10000),
('Tripthi', 'Mishra', 24, 'F', 6000)''')
conn.commit()
#使用 ORDER BY 子句检索特定记录
cursor.execute("SELECT * from EMPLOYEE ORDER BY AGE")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Vinay', 'Battacharya', 20, 'M', 6000, None),
('Tripthi', 'Mishra', 24, 'F', 6000, None),
('Sharukh', 'Sheik', 25, 'M', 8300, None),
('Sarmista', 'Sharma', 26, 'F', 10000, None),
('Ramya', 'Rama priya', 27, 'F', 9000, None)]
Python SQLite - 更新表
对任何数据库执行 UPDATE 操作都意味着修改数据库中已有的表中一个或多个记录的值。您可以使用 UPDATE 语句更新 SQLite 中现有记录的值。
要更新特定行,您需要同时使用 WHERE 子句。
语法
以下是 SQLite 中 UPDATE 语句的语法 −
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
以下语句修改了运动员的年龄,其名字为 Shikhar −
sqlite> UPDATE CRICKETERS SET AGE = 45 WHERE FIRST_NAME = 'Shikhar' ; sqlite>
如果您检索 FIRST_NAME 为 Shikhar 的记录,您会发现年龄值已更改为 45−
sqlite> SELECT * FROM CRICKETERS WHERE FIRST_NAME = 'Shikhar'; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Shikhar Dhawan 45 Delhi India sqlite>
如果您没有使用 WHERE 子句,则所有记录的值都将被更新。以下 UPDATE 语句将 CRICKETERS 表中所有记录的年龄增加 1 −
sqlite> UPDATE CRICKETERS SET AGE = AGE+1; sqlite>
如果您使用 SELECT 命令检索表的内容,则可以看到更新后的值−
sqlite> SELECT * FROM CRICKETERS; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Shikhar Dhawan 46 Delhi India Jonathan Trott 39 CapeTown SouthAfrica Kumara Sangakkara 42 Matale Srilanka Virat Kohli 31 Delhi India Rohit Sharma 33 Nagpur India sqlite>
使用 python 更新现有记录
向 SQLite 数据库中的现有表添加记录 −
导入 sqlite3 包。
使用 connect() 方法创建一个连接对象,并将数据库名称作为参数传递给它。
cursor() 方法返回一个游标对象,您可以使用该对象与 SQLite3 进行通信。通过调用(上面创建的)Connection 对象上的 cursor() 对象来创建游标对象。
然后,通过将 UPDATE 语句作为参数传递给游标对象,调用游标对象上的 execute() 方法。
示例
按照 Python 示例,创建一个名为 EMPLOYEE 的表,向其中插入 5 条记录,并将所有男性员工的年龄增加 1 −
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则添加注释。
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
#根据要求创建表
sql ='''CREATE TABLE EMPLOYEE(
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT
)'''
cursor.execute(sql)
#插入数据
cursor.execute('''INSERT INTO EMPLOYEE
(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES
('Ramya', 'Rama priya', 27, 'F', 9000),
('Vinay', 'Battacharya', 20, 'M', 6000),
('Sharukh', 'Sheik', 25, 'M', 8300),
('Sarmista', 'Sharma', 26, 'F', 10000),
('Tripthi', 'Mishra', 24, 'F', 6000)''')
conn.commit()
#获取更新前的所有行
print("Contents of the Employee table: ")
cursor.execute('''SELECT * from EMPLOYEE''')
print(cursor.fetchall())
#更新记录
sql = '''UPDATE EMPLOYEE SET AGE=AGE+1 WHERE SEX = 'M' '''
cursor.execute(sql)
print("Table updated...... ")
#获取更新后的所有行
print("Contents of the Employee table after the update operation: ")
cursor.execute('''SELECT * from EMPLOYEE''')
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Contents of the Employee table:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Vinay', 'Battacharya', 20, 'M', 6000.0),
('Sharukh', 'Sheik', 25, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Table updated......
Contents of the Employee table after the update operation:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Vinay', 'Battacharya', 21, 'M', 6000.0),
('Sharukh', 'Sheik', 26, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Python SQLite - Delete 删除数据
要从 SQLite 表中删除记录,您需要使用 DELETE FROM 语句。要删除特定记录,您需要与其一起使用 WHERE 子句。
要更新特定行,您需要与其一起使用 WHERE 子句。
语法
以下是 SQLite 中 DELETE 查询的语法 −
DELETE FROM table_name [WHERE 子句]
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
Python SQLite - 删除数据
要从 SQLite 表中删除记录,您需要使用 DELETE FROM 语句。要删除特定记录,您需要与其一起使用 WHERE 子句。
要更新特定行,您需要与其一起使用 WHERE 子句。
语法
以下是 SQLite 中 DELETE 查询的语法 −
DELETE FROM table_name [WHERE 子句]
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表
sqlite> SELECT * FROM CRICKETERS; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Shikhar Dhawan 46 Delhi India Jonathan Trott 39 CapeTown SouthAfrica Virat Kohli 31 Delhi India Rohit Sharma 33 Nagpur India sqlite>
如果执行不带 WHERE 子句的 DELETE FROM 语句,则指定表中的所有记录都将被删除。
sqlite> DELETE FROM CRICKETERS; sqlite>
由于您已删除所有记录,如果您尝试使用 SELECT 语句检索 CRICKETERS 表的内容,您将获得一个空结果集,如下所示 −
sqlite> SELECT * FROM CRICKETERS; sqlite>
使用 python 删除数据
向 SQLite 数据库中的现有表添加记录 −
导入 sqlite3 包。
使用 connect() 方法创建一个连接对象,并将数据库名称作为参数传递给它。
cursor() 方法返回一个游标对象,您可以使用该对象与 SQLite3 进行通信。通过调用(上面创建的)Connection 对象上的 cursor() 对象来创建游标对象。
然后,通过将 DELETE 语句作为参数传递给游标对象,调用游标对象上的 execute() 方法。
示例
以下 Python 示例从 EMPLOYEE 表中删除年龄值大于 25 的记录。
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索表的内容
print("Contents of the table: ")
cursor.execute('''SELECT * from EMPLOYEE''')
print(cursor.fetchall())
#删除记录
cursor.execute('''DELETE FROM EMPLOYEE WHERE AGE > 25''')
#删除后检索数据
print("Contents of the table after delete operation ")
cursor.execute("SELECT * from EMPLOYEE")
print(cursor.fetchall())
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Contents of the table:
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Vinay', 'Battacharya', 21, 'M', 6000.0),
('Sharukh', 'Sheik', 26, 'M', 8300.0),
('Sarmista', 'Sharma', 26, 'F', 10000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Contents of the table after delete operation
[('Vinay', 'Battacharya', 21, 'M', 6000.0),
('Tripthi', 'Mishra', 24, 'F', 6000.0)]
Python SQLite - Drop Table 删除表
您可以使用 DROP TABLE 语句删除整个表。您只需指定需要删除的表的名称即可。
语法
以下是 PostgreSQL 中 DROP TABLE 语句的语法 −
DROP TABLE table_name;
示例
假设我们使用以下查询创建了两个名为 CRICKETERS 和 EMPLOYEES 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite> CREATE TABLE EMPLOYEE( FIRST_NAME CHAR(20) NOT NULL, LAST_NAME CHAR(20), AGE INT, SEX CHAR(1), INCOME FLOAT ); sqlite>
现在,如果您使用 .tables 命令验证表列表,您可以在其中看到上面创建的表(列表)为 −
sqlite> .tables CRICKETERS EMPLOYEE sqlite>
以下语句从数据库中删除名为 Employee 的表 −
sqlite> DROP table employee; sqlite>
由于您已删除 Employee 表,如果您再次检索表列表,则只能在其中观察到一个表。
sqlite> .tables CRICKETERS sqlite>
如果您尝试再次删除 Employee 表,由于您已经删除了它,您将收到一条错误消息,提示"no such table",如下所示 −
sqlite> DROP table employee; Error: no such table: employee sqlite>
要解决此问题,您可以将 IF EXISTS 子句与 DELTE 语句一起使用。如果表存在,则删除该表,否则跳过 DLETE 操作。
sqlite> DROP table IF EXISTS employee; sqlite>
使用 Python 删除表
您可以随时使用 MYSQL 的 DROP 语句删除表,但在删除任何现有表时需要非常小心,因为删除表后丢失的数据将无法恢复。
示例
要使用 python 从 SQLite3 数据库中删除表,请在游标对象上调用 execute() 方法,并将 drop 语句作为参数传递给它。
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#如果 EMPLOYEE 表已经存在则删除
cursor.execute("DROP TABLE emp")
print("Table dropped... ")
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
Table dropped...
Python SQLite - Limit 限制子句
在获取记录时,如果您想用特定数字限制它们,可以使用 SQLite 的 LIMIT 子句来实现。
语法
以下是 SQLite 中 LIMIT 子句的语法 −
SELECT column1, column2, columnN FROM table_name LIMIT [行数]
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
如果我们使用 INSERT 语句向其中插入 5 条记录,如下所示 −
sqlite> insert into CRICKETERS values('Shikhar', 'Dhawan', 33, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Jonathan', 'Trott', 38, 'CapeTown', 'SouthAfrica');
sqlite> insert into CRICKETERS values('Kumara', 'Sangakkara', 41, 'Matale', 'Srilanka');
sqlite> insert into CRICKETERS values('Virat', 'Kohli', 30, 'Delhi', 'India');
sqlite> insert into CRICKETERS values('Rohit', 'Sharma', 32, 'Nagpur', 'India');
sqlite>
以下语句使用 LIMIT 子句检索 Cricketers 表的前 3 条记录 −
sqlite> SELECT * FROM CRICKETERS LIMIT 3; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Shikhar Dhawan 33 Delhi India Jonathan Trott 38 CapeTown SouthAfrica Kumara Sangakkara 41 Matale Srilanka sqlite>
如果您需要限制从第 n 条记录(而不是第 1 条)开始的记录,则可以结合使用 OFFSET 和 LIMIT。
sqlite> SELECT * FROM CRICKETERS LIMIT 3 OFFSET 2; First_Name Last_Name Age Place_Of_B Country ---------- ---------- ---- ---------- ------------- Kumara Sangakkara 41 Matale Srilanka Virat Kohli 30 Delhi India Rohit Sharma 32 Nagpur India sqlite>
使用 Python 的 LIMIT 子句
如果通过将 SELECT 查询与 LIMIT 子句一起传递来调用游标对象上的 execute() 方法,则可以检索所需数量的记录。
示例
以下 Python 示例使用 LIMIT 子句检索 EMPLOYEE 表的前两个记录。
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索单行
sql = '''SELECT * from EMPLOYEE LIMIT 3'''
#执行查询
cursor.execute(sql)
#获取数据
result = cursor.fetchall();
print(result)
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Ramya', 'Rama priya', 27, 'F', 9000.0),
('Vinay', 'Battacharya', 20, 'M', 6000.0),
('Sharukh', 'Sheik', 25, 'M', 8300.0)]
Python SQLite - Join 连接
将数据分成两个表后,可以使用连接从这两个表中获取组合记录。
示例
假设我们使用以下查询创建了一个名为 CRICKETERS 的表 −
sqlite> CREATE TABLE CRICKETERS ( First_Name VARCHAR(255), Last_Name VARCHAR(255), Age int, Place_Of_Birth VARCHAR(255), Country VARCHAR(255) ); sqlite>
让我们再创建一个表 OdiStats,描述 CRICKETERS 表中每个球员的单日统计数据。
sqlite> CREATE TABLE ODIStats ( First_Name VARCHAR(255), Matches INT, Runs INT, AVG FLOAT, Centuries INT, HalfCenturies INT ); sqlite>
以下语句检索结合这两个表中的值的数据 −
sqlite> SELECT Cricketers.First_Name, Cricketers.Last_Name, Cricketers.Country, OdiStats.matches, OdiStats.runs, OdiStats.centuries, OdiStats.halfcenturies from Cricketers INNER JOIN OdiStats ON Cricketers.First_Name = OdiStats.First_Name; First_Name Last_Name Country Matches Runs Centuries HalfCenturies ---------- ---------- ------- ---------- ------------- ---------- ---------- Shikhar Dhawan Indi 133 5518 17 27 Jonathan Trott Sout 68 2819 4 22 Kumara Sangakkara Sril 404 14234 25 93 Virat Kohli Indi 239 11520 43 54 Rohit Sharma Indi 218 8686 24 42 sqlite>
使用 python 的 Join 子句
以下 SQLite 示例演示了使用 python 的 JOIN 子句 −
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
#检索数据
sql = '''SELECT * from EMP INNER JOIN CONTACT ON EMP.CONTACT = CONTACT.ID'''
#执行查询
cursor.execute(sql)
#从表中获取第一行
result = cursor.fetchall();
print(result)
#在数据库中提交你的更改
conn.commit()
#关闭连接
conn.close()
输出
[('Ramya', 'Rama priya', 27, 'F', 9000.0, 101, 101, 'Krishna@mymail.com', 'Hyderabad'),
('Vinay', 'Battacharya', 20, 'M', 6000.0, 102, 102,'Raja@mymail.com', 'Vishakhapatnam'),
('Sharukh', 'Sheik', 25, 'M', 8300.0, 103, 103, 'Krishna@mymail.com', 'Pune'),
('Sarmista', 'Sharma', 26, 'F', 10000.0, 104, 104, 'Raja@mymail.com', 'Mumbai')]
Python SQLite - Cursor 对象
sqlite3.Cursor 类是一个实例,您可以使用它来调用执行 SQLite 语句的方法,从查询的结果集中获取数据。您可以使用 Connection 对象/类的 cursor() 方法创建 Cursor 对象。
示例
import sqlite3
#连接到 sqlite
conn = sqlite3.connect('example.db')
#使用 cursor() 方法创建游标对象
cursor = conn.cursor()
方法
以下是 Cursor 类/对象提供的各种方法。
| Sr.No | 方法和说明 |
|---|---|
| 1 | execute() 此例程执行 SQL 语句。SQL 语句可能被参数化(即占位符而不是 SQL 文字)。 psycopg2 模块支持使用 %s 符号的占位符 例如:cursor.execute("insert into people values (%s, %s)", (who, age)) |
| 2 | executemany() 此例程针对序列 sql 中找到的所有参数序列或映射执行 SQL 命令。 |
| 3 | fetchone() 此方法获取查询结果集的下一行,返回单个序列,如果没有更多可用数据则返回 None。 |
| 4 | fetchmany() 此例程获取查询结果的下一组行,并返回一个列表。当没有更多行可用时,将返回一个空列表。该方法尝试获取 size 参数指示的尽可能多的行。 |
| 5 | fetchall() 此例程获取查询结果的所有(剩余)行,并返回一个列表。当没有行可用时,将返回一个空列表。 |
属性
以下是 Cursor 类的属性 −
| Sr.No | 方法 &描述 |
|---|---|
| 1 | arraySize 这是一个读/写属性,您可以设置 fetchmany() 方法返回的行数。 |
| 2 | description 这是一个只读属性,它返回包含结果集中列描述的列表。 |
| 3 | lastrowid 这是一个只读属性,如果表中有任何自动递增的列,它将返回上次 INSERT 或 UPDATE 中为该列生成的值操作。 |
| 4 | rowcount 这将返回 SELECT 和 UPDATE 操作中返回/更新的行数。 |
| 5 | connection 此只读属性提供 Cursor 对象使用的 SQLite 数据库连接。 |
Python MongoDB - 简介
Pymongo 是一个 Python 发行版,它提供了使用 MongoDB 的工具,它是通过 Python 与 MongoDB 数据库通信的首选方式。
安装
要安装 pymongo,首先请确保您已正确安装了 python3(以及 PIP)和 MongoDB。然后执行以下命令。
C:\WINDOWS\system32>pip install pymongo Collecting pymongo Using cached https://files.pythonhosted.org/packages/cb/a6/b0ae3781b0ad75825e00e29dc5489b53512625e02328d73556e1ecdf12f8/pymongo-3.9.0-cp37-cp37m-win32.whl Installing collected packages: pymongo Successfully installed pymongo-3.9.0
验证
安装 pymongo 后,打开一个新文本文档,在其中粘贴以下行并将其保存为 test.py。
import pymongo
如果您已正确安装 pymongo,则按照如下所示执行 test.py,不会出现任何问题。
D:\Python_MongoDB>test.py D:\Python_MongoDB>
Python MongoDB - 创建数据库
与其他数据库不同,MongoDB 不提供单独的命令来创建数据库。
一般来说,use 命令用于选择/切换到特定的数据库。此命令首先验证我们指定的数据库是否存在,如果存在,则连接到该数据库。如果我们使用 use 命令指定的数据库不存在,则会创建一个新数据库。
因此,您可以使用 Use 命令在 MongoDB 中创建数据库。
语法
use DATABASE 语句的基本语法如下 −
use DATABASE_NAME
示例
以下命令在 mydb 中创建一个名为的数据库。
>use mydb switched to db mydb
您可以使用 db 命令验证您的创建,这将显示当前数据库。
>db mydb
使用创建数据库python
要使用 pymongo 连接 MongoDB,您需要导入并创建一个 MongoClient,然后您可以在属性 passion 中直接访问您需要创建的数据库。
示例
以下示例在 MangoDB 中创建一个数据库。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydb']
print("Database created........")
#确认
print("List of databases after creating new one")
print(client.list_database_names())
输出
Database created........ List of databases after creating new one: ['admin', 'config', 'local', 'mydb']
您还可以在创建 MongoClient 时指定端口和主机名,并以字典形式访问数据库。
示例
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydb']
print("Database created........")
输出
Database created........
Python MongoDB - 创建集合
MongoDB 中的集合包含一组文档,它类似于关系数据库中的表。
您可以使用 createCollection() 方法创建集合。此方法接受一个字符串值,表示要创建的集合的名称和一个选项(可选)参数。
使用此方法,您可以指定以下 −
- 集合的大小。
- 上限集合中允许的最大文档数。
- 我们创建的集合是否应为上限集合(固定大小集合)。
- 我们创建的集合是否应自动索引。
语法
以下是在 MongoDB 中创建集合的语法。
db.createCollection("CollectionName")
示例
以下方法创建一个名为 ExampleCollection 的集合。
> use mydb
switched to db mydb
> db.createCollection("ExampleCollection")
{ "ok" : 1 }
>
类似地,下面是使用 createCollection() 方法的选项创建集合的查询。
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>
使用 python 创建集合
以下 python 示例连接到 MongoDB (mydb) 中的数据库并在其中创建集合。
示例
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydb']
#创建集合
collection = db['example']
print("Collection created........")
输出
Collection created........
Python MongoDB - 插入文档
您可以使用 insert() 方法将文档存储到 MongoDB 中。此方法接受 JSON 文档作为参数。
语法
以下是 insert 方法的语法。
>db.COLLECTION_NAME.insert(DOCUMENT_NAME)
示例
> use mydb
switched to db mydb
> db.createCollection("sample")
{ "ok" : 1 }
> doc1 = {"name": "Ram", "age": "26", "city": "Hyderabad"}
{ "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
> db.sample.insert(doc1)
WriteResult({ "nInserted" : 1 })
>
类似地,您也可以使用 insert() 方法插入多个文档。
> use testDB
switched to db testDB
> db.createCollection("sample")
{ "ok" : 1 }
> data =
[
{
"_id": "1001",
"name": "Ram",
"age": "26",
"city": "Hyderabad"
},
{
"_id": "1002",
"name" : "Rahim",
"age" : 27,
"city" : "Bangalore"
},
{
"_id": "1003",
"name" : "Robert",
"age" : 28,
"city" : "Mumbai"
}
]
[
{
"_id" : "1001",
"name" : "Ram",
"age" : "26",
"city" : "Hyderabad"
},
{
"_id" : "1002",
"name" : "Rahim",
"age" : 27,
"city" : "Bangalore"
},
{
"_id" : "1003",
"name" : "Robert",
"age" : 28,
"city" : "Mumbai"
}
]
> db.sample.insert(data)
BulkWriteResult
({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 3,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
>
使用 python 创建集合
Pymongo 提供了一个名为 insert_one() 的方法来在 MangoDB 中插入文档。对于此方法,我们需要以字典格式传递文档。
示例
以下示例在名为 example 的集合中插入一个文档。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydb']
#创建集合
coll = db['example']
#将文档插入集合
doc1 = {"name": "Ram", "age": "26", "city": "Hyderabad"}
coll.insert_one(doc1)
print(coll.find_one())
输出
{
'_id': ObjectId('5d63ad6ce043e2a93885858b'),
'name': 'Ram',
'age': '26',
'city': 'Hyderabad'
}
要使用 pymongo 将多个文档插入 MongoDB,您需要调用 insert_many() 方法。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydb']
#创建集合
coll = db['example']
#将文档插入集合
data =
[
{
"_id": "101",
"name": "Ram",
"age": "26",
"city": "Hyderabad"
},
{
"_id": "102",
"name": "Rahim",
"age": "27",
"city": "Bangalore"
},
{
"_id": "103",
"name": "Robert",
"age": "28",
"city": "Mumbai"
}
]
res = coll.insert_many(data)
print("Data inserted ......")
print(res.inserted_ids)
输出
Data inserted ...... ['101', '102', '103']
Python MongoDB - find 方法
您可以使用 find() 方法从 MongoDB 读取/检索存储的文档。此方法以非结构化方式检索并显示 MongoDB 中的所有文档。
语法
以下是 find() 方法的语法。
>db.CollectionName.find()
示例
假设我们使用以下查询将 3 个文档插入到名为 testDB 的集合中的名为 sample 的数据库中 −
> use testDB
> db.createCollection("sample")
> data = [
{"_id": "1001", "name" : "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" },
{"_id": "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
]
> db.sample.insert(data)
您可以使用 find() 方法检索插入的文档,如下所示 −
> use testDB
switched to db testDB
> db.sample.find()
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
>
您还可以使用 findOne() 方法作为 − 检索集合中的第一个文档
> db.sample.findOne()
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
使用 python 检索数据 (find)
pymongo 的 find_One() 方法用于根据您的查询检索单个文档,如果没有匹配项,此方法将不返回任何内容,如果您不使用任何查询,它将返回集合中的第一个文档。
当您只需要检索结果中的一个文档时,或者如果您确定查询只返回一个文档时,此方法就很方便。
示例
以下 python 示例检索集合中的第一个文档 −
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['mydatabase']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "101", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "102", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "103", "name": "Robert", "age": "28", "city": "Mumbai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
print(res.inserted_ids)
#使用 find_one() 方法检索第一条记录
print("First record of the collection: ")
print(coll.find_one())
#使用 find_one() 方法检索值为 103 的记录
print("Record whose id is 103: ")
print(coll.find_one({"_id": "103"}))
输出
Data inserted ......
['101', '102', '103']
First record of the collection:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
Record whose id is 103:
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
要通过单个查询(一次调用 find 方法)获取多个文档,可以使用 pymongo 的 find() 方法。如果未传递任何查询,则该方法将返回集合中的所有文档;如果已将查询传递给此方法,则该方法将返回所有匹配的文档。
示例
#获取数据库实例
db = client['myDB']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "101", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "102", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "103", "name": "Robert", "age": "28", "city": "Mumbai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#使用 find() 方法检索所有记录
print("Records of the collection: ")
for doc1 in coll.find():
print(doc1)
#使用 find() 方法检索年龄大于 26 的记录
print("Record whose age is more than 26: ")
for doc2 in coll.find({"age":{"$gt":"26"}}):
print(doc2)
输出
Data inserted ......
Records of the collection:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Record whose age is more than 26:
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Python MongoDB - 查询
使用 find() 方法检索时,您可以使用查询对象过滤文档。您可以将指定所需文档条件的查询作为参数传递给此方法。
运算符
以下是 MongoDB 中查询中使用的运算符列表。
| 操作 | 语法 | 示例 |
|---|---|---|
| 等于 | {"key" : "value"} | db.mycol.find({"by":"tutorials point"}) |
| 小于 | {"key" :{$lt:"value"}} | db.mycol.find({"likes":{$lt:50}}) |
| 小于等于 | {"key" :{$lte:"value"}} | db.mycol.find({"likes":{$lte:50}}) |
| 大于 | {"key" :{$gt:"value"}> | db.mycol.find({"likes":{$gt:50}}) |
| 大于等于 | {"key" {$gte:"value"}> | db.mycol.find({"likes":{$gte:50}}) |
| 不等于 | {"key":{$ne: "value"}> | db.mycol.find({"likes":{$ne:50}}) |
示例 1
以下示例检索集合中名为 sarmista 的文档。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['sdsegf']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": "25", "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": "23", "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": "26", "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#检索数据
print("Documents in the collection: ")
for doc1 in coll.find({"name":"Sarmista"}):
print(doc1)
输出
Data inserted ......
Documents in the collection:
{'_id': '1005', 'name': 'Sarmista', 'age': '23', 'city': 'Delhi'}
示例 2
以下示例检索集合中 age 值大于 26 的文档。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['ghhj']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": "25", "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": "23", "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": "26", "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#检索数据
print("Documents in the collection: ")
for doc in coll.find({"age":{"$gt":"26"}}):
print(doc)
输出
Data inserted ......
Documents in the collection:
{'_id': '1002', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '1003', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Python MongoDB - 排序
检索集合的内容时,可以使用 sort() 方法按升序或降序对其进行排序和排列。
对于此方法,您可以传递字段和排序顺序,即 1 或 -1。其中,1 表示升序,-1 表示降序。
语法
以下是 sort() 方法的语法。
>db.COLLECTION_NAME.find().sort({KEY:1})
示例
假设我们创建了一个集合并向其中插入了 5 个文档,如下所示 −
> use testDB
switched to db testDB
> db.createCollection("myColl")
{ "ok" : 1 }
> data = [
... {"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
... {"_id": "1002", "name": "Rahim", "age": 27, "city": "Bangalore"},
... {"_id": "1003", "name": "Robert", "age": 28, "city": "Mumbai"},
... {"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
... {"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
... {"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
> db.sample.insert(data)
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 6,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
下一行检索集合中的所有文档,这些文档按年龄升序排列。
> db.sample.find().sort({age:1})
{ "_id" : "1005", "name" : "Sarmista", "age" : 23, "city" : "Delhi" }
{ "_id" : "1004", "name" : "Romeo", "age" : 25, "city" : "Pune" }
{ "_id" : "1006", "name" : "Rasajna", "age" : 26, "city" : "Chennai" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
使用 python 对文档进行排序
为了按升序或降序对查询结果进行排序,pymongo 提供了 sort() 方法。向此方法传递一个数值,表示结果中需要的文档数量。
默认情况下,此方法根据指定字段按升序对文档进行排序。如果需要按降序排序,请将 -1 与字段名称一起传递 −
coll.find().sort("age",-1)
示例
以下示例检索集合中的所有文档,这些文档按年龄值升序排列 −
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['b_mydb']
#创建集合
coll = db['myColl']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#使用 find() 和 limit() 方法检索前 3 个文档
print("List of documents (sorted in ascending order based on age): ")
for doc1 in coll.find().sort("age"):
print(doc1)
输出
Data inserted ......
List of documents (sorted in ascending order based on age):
{'_id': '1005', 'name': 'Sarmista', 'age': 23, 'city': 'Delhi'}
{'_id': '1004', 'name': 'Romeo', 'age': 25, 'city': 'Pune'}
{'_id': '1006', 'name': 'Rasajna', 'age': 26, 'city': 'Chennai'}
{'_id': '1001', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '1002', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '1003', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Python MongoDB - 删除文档
您可以使用 MongoDB 的 remove() 方法删除集合中的文档。此方法接受两个可选参数 −
删除条件,指定删除文档的条件。
只有一个,如果您传递 true 或 1 作为第二个参数,则只会删除一个文档。
语法
以下是 remove() 方法的语法 −
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)
示例
假设我们创建了一个集合并向其中插入了 5 个文档,如下所示 −
> use testDB
switched to db testDB
> db.createCollection("myColl")
{ "ok" : 1 }
> data = [
... {"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
... {"_id": "1002", "name": "Rahim", "age": 27, "city": "Bangalore"},
... {"_id": "1003", "name": "Robert", "age": 28, "city": "Mumbai"},
... {"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
... {"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
... {"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
> db.sample.insert(data)
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 6,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
以下查询删除集合中名称值为 Sarmista 的文档。
> db.sample.remove({"name": "Sarmista"})
WriteResult({ "nRemoved" : 1 })
> db.sample.find()
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
{ "_id" : "1004", "name" : "Romeo", "age" : 25, "city" : "Pune" }
{ "_id" : "1006", "name" : "Rasajna", "age" : 26, "city" : "Chennai" }
如果调用 remove() 方法时未传递删除条件,则集合中的所有文档都将被删除。
> db.sample.remove({})
WriteResult({ "nRemoved" : 5 })
> db.sample.find()
使用 python 删除文档
要从 MangoDB 集合中删除文档,可以使用方法 delete_one() 和 delete_many() 从集合中删除文档。
这些方法接受指定删除文档条件的查询对象。
如果匹配,detele_one() 方法将删除单个文档。如果未指定查询,则此方法将删除集合中的第一个文档。
示例
以下 Python 示例将删除集合中 ID 值为 1006 的文档。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['lpaksgf']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#删除一个文档
coll.delete_one({"_id" : "1006"})
#使用 find() 方法检索所有记录
print("Documents in the collection after update operation: ")
for doc2 in coll.find():
print(doc2)
输出
Data inserted ......
Documents in the collection after update operation:
{'_id': '1001', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '1002', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '1003', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
{'_id': '1004', 'name': 'Romeo', 'age': 25, 'city': 'Pune'}
{'_id': '1005', 'name': 'Sarmista', 'age': 23, 'city': 'Delhi'}
类似地,pymongo 的 delete_many() 方法删除所有满足指定条件的文档。
示例
以下示例删除集合中 age 值大于 26 的所有文档 −
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['sampleDB']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": "25", "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": "23", "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": "26", "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#删除多个文档
coll.delete_many({"age":{"$gt":"26"}})
#使用 find() 方法检索所有记录
print("Documents in the collection after update operation: ")
for doc2 in coll.find():
print(doc2)
输出
Data inserted ......
Documents in the collection after update operation:
{'_id': '1001', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '1004', 'name': 'Romeo', 'age': '25', 'city': 'Pune'}
{'_id': '1005', 'name': 'Sarmista', 'age': '23', 'city': 'Delhi'}
{'_id': '1006', 'name': 'Rasajna', 'age': '26', 'city': 'Chennai'}
如果调用 delete_many() 方法而不传递任何查询,则此方法将删除集合中的所有文档。
coll.delete_many({})
Python MongoDB - 删除集合
您可以使用 MongoDB 的 drop() 方法删除集合。
语法
以下是 drop() 方法的语法 −
db.COLLECTION_NAME.drop()
示例
以下示例删除名为 sample 的集合 −
> show collections myColl sample > db.sample.drop() true > show collections myColl
使用 python 删除集合
您可以通过调用 drop() 方法从当前数据库中删除集合。
示例
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['example2']
#创建集合
col1 = db['collection']
col1.insert_one({"name": "Ram", "age": "26", "city": "Hyderabad"})
col2 = db['coll']
col2.insert_one({"name": "Rahim", "age": "27", "city": "Bangalore"})
col3 = db['myColl']
col3.insert_one({"name": "Robert", "age": "28", "city": "Mumbai"})
col4 = db['data']
col4.insert_one({"name": "Romeo", "age": "25", "city": "Pune"})
#集合列表
print("集合列表:")
collections = db.list_collection_names()
for coll in collections:
print(coll)
#删除一个集合
col1.drop()
col4.drop()
print("List of collections after dropping two of them: ")
#集合列表
collections = db.list_collection_names()
for coll in collections:
print(coll)
输出
List of collections: coll data collection myColl List of collections after dropping two of them: coll myColl
Python MongoDB - 更新
您可以使用 update() 方法或 save() 方法更新现有文档的内容。
update 方法会修改现有文档,而 save 方法会用新文档替换现有文档。
语法
以下是 MangoDB 的 update() 和 save() 方法的语法 −
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)
或者,
db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
示例
假设我们在数据库中创建了一个集合并在其中插入了 3 条记录,如下所示 −
> use testdatabase
switched to db testdatabase
> data = [
... {"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
... {"_id": "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" },
... {"_id": "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
]
[
{
"_id" : "1001",
"name" : "Ram",
"age" : "26",
"city" : "Hyderabad"
},
{
"_id" : "1002",
"name" : "Rahim",
"age" : 27,
"city" : "Bangalore"
},
{
"_id" : "1003",
"name" : "Robert",
"age" : 28,
"city" : "Mumbai"
}
]
> db.createCollection("sample")
{ "ok" : 1 }
> db.sample.insert(data)
以下方法更新 ID 为 1002 的文档的城市值。
> db.sample.update({"_id":"1002"},{"$set":{"city":"Visakhapatnam"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.sample.find()
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Visakhapatnam" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
同样,您可以使用 save() 方法用相同的 id 保存文档,并用新数据替换文档。
> db.sample.save(
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Vijayawada" }
)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.sample.find()
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Vijayawada" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Visakhapatnam" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
使用 python 更新文档
与检索单个文档的 find_one() 方法类似,pymongo 的 update_one() 方法更新单个文档。
此方法接受指定要更新哪个文档和更新操作的查询。
示例
以下 python 示例更新集合中文档的位置值。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['myDB']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "101", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "102", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "103", "name": "Robert", "age": "28", "city": "Mumbai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#使用 find() 方法检索所有记录
print("Documents in the collection: ")
for doc1 in coll.find():
print(doc1)
coll.update_one({"_id":"102"},{"$set":{"city":"Visakhapatnam"}})
#使用 find() 方法检索所有记录
print("Documents in the collection after update operation: ")
for doc2 in coll.find():
print(doc2)
输出
Data inserted ......
Documents in the collection:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Documents in the collection after update operation:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Visakhapatnam'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
类似地,pymongo 的 update_many() 方法更新所有满足指定条件的文档。
示例
以下示例更新集合中所有文档的位置值(空条件)−
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['myDB']
#创建集合
coll = db['example']
#将文档插入集合
data = [
{"_id": "101", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "102", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "103", "name": "Robert", "age": "28", "city": "Mumbai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#使用 find() 方法检索所有记录
print("Documents in the collection: ")
for doc1 in coll.find():
print(doc1)
coll.update_many({},{"$set":{"city":"Visakhapatnam"}})
#使用 find() 方法检索所有记录
print("Documents in the collection after update operation: ")
for doc2 in coll.find():
print(doc2)
输出
Data inserted ......
Documents in the collection:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}
Documents in the collection after update operation:
{'_id': '101', 'name': 'Ram', 'age': '26', 'city': 'Visakhapatnam'}
{'_id': '102', 'name': 'Rahim', 'age': '27', 'city': 'Visakhapatnam'}
{'_id': '103', 'name': 'Robert', 'age': '28', 'city': 'Visakhapatnam'}
Python MongoDB - Limit 限制
检索集合的内容时,您可以使用 limit() 方法限制结果中的文档数量。此方法接受一个数字值,表示结果中所需的文档数量。
语法
以下是 limit() 方法的语法 −
>db.COLLECTION_NAME.find().limit(NUMBER)
示例
假设我们创建了一个集合并向其中插入了 5 个文档,如下所示 −
> use testDB
switched to db testDB
> db.createCollection("sample")
{ "ok" : 1 }
> data = [
... {"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
... {"_id": "1002", "name": "Rahim", "age": 27, "city": "Bangalore"},
... {"_id": "1003", "name": "Robert", "age": 28, "city": "Mumbai"},
... {"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
... {"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
... {"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
> db.sample.insert(data)
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 6,
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
})
下行检索集合的前 3 个文档。
> db.sample.find().limit(3)
{ "_id" : "1001", "name" : "Ram", "age" : "26", "city" : "Hyderabad" }
{ "_id" : "1002", "name" : "Rahim", "age" : 27, "city" : "Bangalore" }
{ "_id" : "1003", "name" : "Robert", "age" : 28, "city" : "Mumbai" }
使用 python 限制文档
为了将查询结果限制为特定数量的文档,pymongo 提供了 limit() 方法。向此方法传递一个数值,表示结果中需要的文档数量。
示例
以下示例检索集合中的前三个文档。
from pymongo import MongoClient
#创建 pymongo 客户端
client = MongoClient('localhost', 27017)
#获取数据库实例
db = client['l']
#创建集合
coll = db['myColl']
#将文档插入集合
data = [
{"_id": "1001", "name": "Ram", "age": "26", "city": "Hyderabad"},
{"_id": "1002", "name": "Rahim", "age": "27", "city": "Bangalore"},
{"_id": "1003", "name": "Robert", "age": "28", "city": "Mumbai"},
{"_id": "1004", "name": "Romeo", "age": 25, "city": "Pune"},
{"_id": "1005", "name": "Sarmista", "age": 23, "city": "Delhi"},
{"_id": "1006", "name": "Rasajna", "age": 26, "city": "Chennai"}
]
res = coll.insert_many(data)
print("Data inserted ......")
#使用 find() 和 limit() 方法检索前 3 个文档
print("First 3 documents in the collection: ")
for doc1 in coll.find().limit(3):
print(doc1)
输出
Data inserted ......
First 3 documents in the collection:
{'_id': '1001', 'name': 'Ram', 'age': '26', 'city': 'Hyderabad'}
{'_id': '1002', 'name': 'Rahim', 'age': '27', 'city': 'Bangalore'}
{'_id': '1003', 'name': 'Robert', 'age': '28', 'city': 'Mumbai'}


