MuleSoft - 快速指南
MuleSoft - Mule ESB 简介
ESB 代表企业服务总线,它基本上是一种通过类似总线的基础设施将各种应用程序集成在一起的中间件工具。从根本上讲,它是一种旨在提供在集成应用程序之间移动工作的统一方法的架构。这样,借助 ESB 架构,我们可以通过通信总线连接不同的应用程序,并使它们能够相互通信而不相互依赖。
实施 ESB
ESB 架构的主要重点是将系统彼此分离,并允许它们以稳定且可控的方式进行通信。 ESB 的实现可以借助"总线"和"适配器"以以下方式完成 −
"总线"的概念是通过 JMS 或 AMQP 等消息服务器实现的,用于将不同的应用程序彼此分离。
"适配器"的概念用于应用程序和总线之间,负责与后端应用程序通信并将数据从应用程序格式转换为总线格式。
通过总线从一个应用程序传递到另一个应用程序的数据或消息采用规范格式,这意味着将有一种一致的消息格式。
适配器还可以执行其他活动,如安全、监控、错误处理和消息路由管理。
ESB 的指导原则
我们可以将这些原则称为核心集成原则。它们如下 −
编排 − 集成两个或多个服务以实现数据和流程之间的同步。
转换 − 将数据从规范格式转换为特定于应用程序的格式。
传输 − 处理 FTP、HTTP、JMS 等格式之间的协议协商。
中介 − 提供多个接口以支持服务的多个版本。
非功能一致性 − 还提供管理事务和安全的机制。
需要 ESB
ESB 架构使我们能够集成不同的应用程序,每个应用程序都可以通过它进行通信。以下是有关何时使用 ESB 的一些指导原则 −
集成两个或多个应用程序 − 当需要集成两个或多个服务或应用程序时,使用 ESB 架构是有益的。
未来集成更多应用程序 − 假设我们想在未来添加更多服务或应用程序,那么可以借助 ESB 架构轻松完成。
使用多种协议 − 如果我们需要使用多种协议,如 HTTP、FTP、JMS 等,ESB 是正确的选择。
消息路由 − 如果我们需要基于消息内容和其他类似参数进行消息路由,我们可以使用 ESB。
组合和使用 −如果我们需要发布服务以供组合和使用,则可以使用 ESB。
P2P 集成与 ESB 集成
随着应用程序数量的增加,开发人员面临的一个大问题是如何连接不同的应用程序?这种情况是通过手动编码各种应用程序之间的连接来处理的。这称为点对点集成。
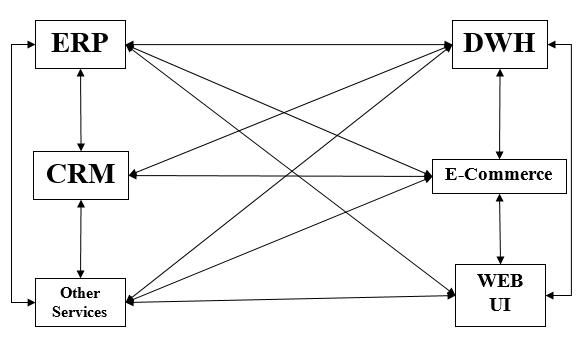
刚性是点对点集成最明显的缺点。随着连接和接口数量的增加,复杂性也会增加。P-2-P 集成的缺点使我们想到了 ESB 集成。
ESB 是一种更灵活的应用程序集成方法。它将每个应用程序功能封装并公开为一组离散的可重用功能。没有应用程序直接与其他应用程序集成,而是通过 ESB 进行集成,如下所示 −
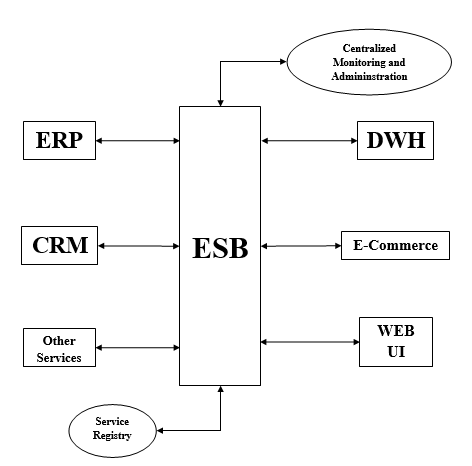
为了管理集成,ESB 具有以下两个组件 −
服务注册表 − Mule ESB 具有服务注册表/存储库,所有暴露到 ESB 中的服务都在此发布和注册。它充当发现点,人们可以从这里使用其他应用程序的服务和功能。
集中管理 − 顾名思义,它提供了 ESB 内部交互的事务流程视图。
ESB 功能 − VETRO 缩写通常用于总结 ESB 的功能。它如下 −
V(验证) − 顾名思义,它验证模式验证。它需要验证解析器和最新的模式。一个例子是符合最新架构的 XML 文档。
E(丰富) − 它向消息添加额外数据。目的是使消息对目标服务更有意义和更有用。
T(转换) − 它将数据结构转换为规范格式或从规范格式转换。例如日期/时间、货币等的转换。
R(路由) − 它将路由消息并充当服务端点的守门人。
O(操作) − 此功能的主要工作是调用目标服务或与目标应用程序交互。它们在后端运行。
VETRO 模式为集成提供了整体灵活性,并确保只有一致且经过验证的数据才会在整个 ESB 中路由。
什么是 Mule ESB?
Mule ESB 是 MuleSoft 提供的轻量级且高度可扩展的基于 Java 的企业服务总线 (ESB) 和集成平台。Mule ESB 允许开发人员轻松快速地连接应用程序。无论应用程序使用何种技术,Mule ESB 都可以轻松集成应用程序,使它们能够交换数据。Mule ESB 有以下两个版本 −
- 社区版
- 企业版
Mule ESB 的一个优点是我们可以轻松地从 Mule ESB 社区版升级到 Mule ESB 企业版,因为这两个版本都是基于通用代码库构建的。
功能和Mule ESB 的功能
Mule ESB 具有以下功能 −
- 它具有简单的拖放式图形设计。
- Mule ESB 能够进行可视化数据映射和转换。
- 用户可以使用数百个预构建的认证连接器。
- 集中监控和管理。
- 它提供强大的企业安全实施功能。
- 它提供 API 管理功能。
- 有用于云/本地连接的安全数据网关。
- 它提供服务注册表,所有暴露到 ESB 中的服务都会在此发布和注册。
- 用户可以通过基于 Web 的管理控制台进行控制。
- 可以使用服务流分析器进行快速调试。
MuleSoft - Mule 项目
Mule 项目背后的动机是 −
让程序员的工作更简单,
需要轻量级和模块化的解决方案,可以从应用程序级消息传递框架扩展到企业范围内高度可分布的框架。
Mule ESB 被设计为事件驱动和编程框架。它之所以是事件驱动的,是因为它结合了消息的统一表示,并且可以通过可插入模块进行扩展。它是可编程的,因为程序员可以轻松植入一些额外的行为,例如特定的消息处理或自定义数据转换。
历史
Mule 项目的历史视角如下 −
SourceForge 项目
Mule 项目于 2003 年 4 月作为 SourceForge 项目启动,两年后其第一个版本发布并移至 CodeHaus。通用消息对象 (UMO) API 是其架构的核心。UMO API 背后的想法是统一逻辑,同时使它们与底层传输隔离。
版本 1.0
它于 2005 年 4 月发布,包含多种传输。随后的许多其他版本的主要重点是调试和添加新功能。
版本 2.0(采用 Spring 2)
Mule 2 采用了 Spring 2 作为配置和布线框架,但由于所需 XML 配置缺乏表现力,因此被证明是一次重大改革。当在 Spring 2 中引入基于 XML Schema 的配置时,此问题得到了解决。
使用 Maven 构建
在开发和部署时简化 Mule 使用的最大改进是使用 Maven。从版本 1.3 开始,它开始使用 Maven 构建。
MuleSource
2006 年,MuleSource 成立,"以帮助支持和推动在关键任务企业应用程序中使用 Mule 的快速增长社区"。事实证明,这是 Mule 项目的关键里程碑。
Mule ESB 的竞争对手
以下是 Mule ESB 的一些主要竞争对手 −
- WSO2 ESB
- Oracle Service Bus
- WebSphere Message Broker
- Aurea CX Platform
- Fiorano ESB
- WebSphere DataPower Gateway
- Workday Business Process Framework
- Talend Enterprise Service Bus
- JBoss Enterprise Service Bus
- iWay Service Manager
Mule 的核心概念
如上所述,Mule ESB 是一个轻量级且高度可扩展的基于 Java 的企业服务总线 (ESB) 和集成平台。无论应用程序使用何种技术,Mule ESB 都可以轻松集成应用程序,使它们能够交换数据。在本节中,我们将讨论 Mule 的核心概念如何发挥作用,以实现这种集成。
为此,我们需要了解其架构以及构建块。
架构
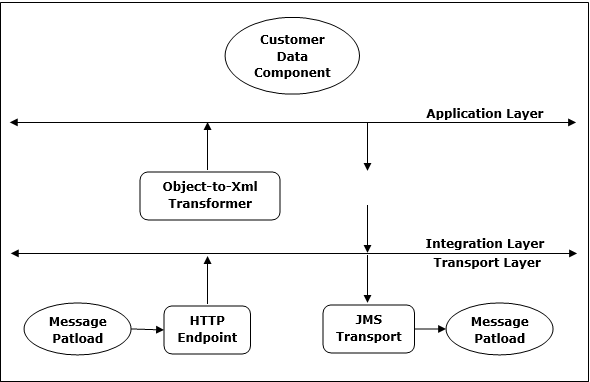
Mule ESB 的架构分为三层,即传输层、集成层和应用层,如下图所示 −
通常,可以执行以下三种类型的任务来配置和自定义 Mule 部署 −
服务组件开发
此任务涉及开发或重新使用现有的 POJO 或 Spring Bean。POJO 是一个具有属性的类,可生成 get 和 set 方法、云连接器。另一方面,Spring Bean 包含丰富消息的业务逻辑。
服务编排
此任务基本上提供服务中介,涉及配置消息处理器、路由器、转换器和过滤器。
集成
Mule ESB 最重要的任务是集成各种应用程序,无论它们使用何种协议。为此,Mule 提供了传输方法,允许在各种协议连接器上接收和分派消息。 Mule 支持许多现有的传输方法,或者我们也可以使用自定义传输方法。
构建块
Mule 配置具有以下构建块 −
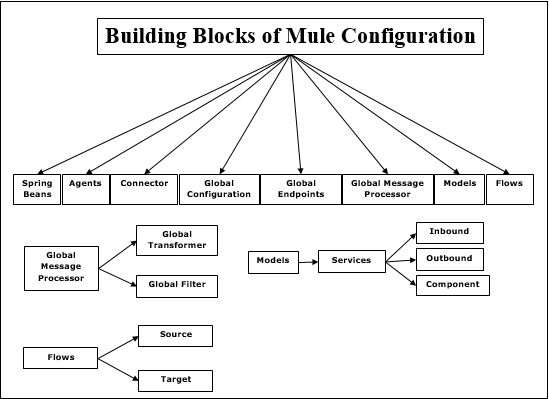
Spring beans
Spring beans 的主要用途是构建服务组件。构建 spring 服务组件后,我们可以通过配置文件定义它,或者如果您没有配置文件,也可以手动定义它。
代理
它基本上是在 Mule Studio 之前在 Anypoint Studio 中创建的服务。启动服务器后会创建代理,停止服务器后代理将被销毁。
连接器
它是一个配置了特定于协议的参数的软件组件。它主要用于控制协议的使用。例如,JMS 连接器配置了一个 Connection,并且该连接器将在负责实际通信的各个实体之间共享。
全局配置
顾名思义,此构建块用于设置全局属性和设置。
全局端点
它可以在"全局元素"选项卡中使用,该选项卡可以在流中使用多次 −
全局消息处理器
顾名思义,它观察或修改消息或消息流。转换器和过滤器是全局消息处理器的示例。
转换器 − 转换器的主要工作是将数据从一种格式转换为另一种格式。它可以全局定义,并可用于多个流。
过滤器 − 过滤器将决定应该处理哪条 Mule 消息。过滤器基本上指定了处理消息并将其路由到服务所必须满足的条件。
模型
与代理不同,它是在工作室中创建的服务的逻辑分组。我们可以自由地启动和停止特定模型内的所有服务。
服务 − 服务是包装我们的业务逻辑或组件的服务。它还专门为该服务配置路由器、端点、转换器和过滤器。
端点 − 它可以定义为服务将在其上传入(接收)和传出(发送)消息的对象。服务通过端点连接。
流
消息处理器使用流来定义源和目标之间的消息流。
Mule 消息结构
Mule 消息完全包装在 Mule 消息对象下,是通过 Mule 流通过应用程序的数据。Mule 消息的结构如下图所示 −
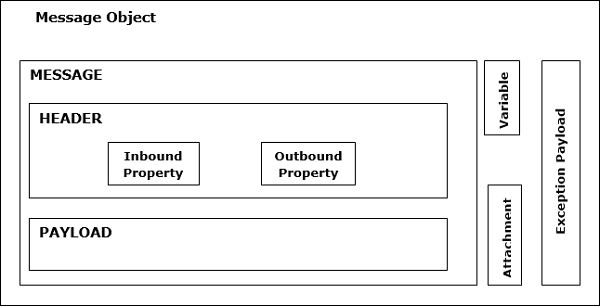
如上图所示,Mule 消息由两个主要部分组成 −
Header
它只是消息的元数据,进一步由以下两个属性表示 −
入站属性 − 这些是由消息源自动设置的属性。它们不能由用户操纵或设置。本质上,入站属性是不可变的。
出站属性 − 这些是包含元数据的属性,如入站属性,可以在流程过程中设置。它们可以由 Mule 自动设置,也可以由用户手动设置。本质上,出站属性是可变的。
当消息通过传输从一个流的出站端点传递到另一个流的入站端点时,出站属性将成为入站属性。
当消息通过 flow-ref 而不是连接器传递到新流时,出站属性仍为出站属性。
有效负载
消息对象携带的实际业务消息称为有效负载。
Variables(变量)
它可以定义为有关消息的用户定义元数据。基本上,变量是处理该消息的应用程序使用的有关该消息的临时信息。它不打算与消息一起传递到其目的地。它们有以下三种类型 −
流变量 − 这些变量仅适用于它们所在的流。
会话变量 −这些变量适用于同一应用程序内的所有流程。
记录变量 − 这些变量仅适用于作为批处理的一部分处理的记录。
附件和额外有效负载
这些是关于消息有效负载的一些额外元数据,不一定每次都出现在消息对象中。
MuleSoft - Mule in Our Machine
在前面的章节中,我们学习了 Mule ESB 的基础知识。在本章中,让我们学习如何安装和配置它。
先决条件
在计算机上安装 Mule 之前,我们需要满足以下先决条件 −
Java 开发工具包 (JDK)
在安装 MULE 之前,请验证您的系统上是否支持 Java 版本。建议使用 JDK 1.8.0 才能在您的系统上成功安装 Mule。
操作系统
Mule 支持以下操作系统 −
- MacOS 10.11.x
- HP-UX 11iV3
- AIX 7.2
- Windows 2016 Server
- Windows 2012 R2 Server
- Windows 10
- Windows 8.1
- Solaris 11.3
- RHEL 7
- Ubuntu Server 18.04
- Linux Kernel 3.13+
数据库
由于 Mule Runtime 作为独立服务器运行,因此不需要应用服务器或数据库。但如果我们需要访问数据存储或想要使用应用服务器,则可以使用以下受支持的应用服务器或数据库 −
- Oracle 11g
- Oracle 12c
- MySQL 5.5+
- IBM DB2 10
- PostgreSQL 9
- Derby 10
- Microsoft SQL Server 2014
系统要求
在您的系统上安装 Mule 之前,它必须满足以下系统要求 −
- 至少 2 GHz CPU 或虚拟化环境中的 1 个虚拟 CPU
- 至少 1 GB RAM
- 至少 4 GB 存储空间
下载 Mule
要下载 Mule 4 二进制文件,请单击链接 https://www.mulesoft.com/lp/dl/mule-esb-enterprise,它将带您进入 MuleSoft 的官方网页,如下所示 −
通过提供必要的详细信息,您可以获取 Zip 格式的 Mule 4 二进制文件。
安装并运行 Mule
现在下载 Mule 4 二进制文件后,解压缩它并为解压文件夹内的 Mule 目录设置一个名为 MULE_HOME 的环境变量。
例如,在 Windows 和 Linux/Unix 环境中,可以在下载目录中为版本 4.1.5 设置环境变量,如下所示 −
Windows 环境
$ env:MULE_HOME=C:\Downloads\mule-enterprise-standalone-4.1.5\
Unix/Linux 环境
$ export MULE_HOME=~/Downloads/mule-enterprise-standalone-4.1.5/
现在,要测试 Mule 是否在您的系统中无错误运行,请使用以下命令 −
Windows 环境
$ $MULE_HOME\bin\mule.bat
Unix/Linux 环境
$ $MULE_HOME/bin/mule
上述命令将在前台模式下运行 Mule。如果 Mule 正在运行,则我们无法在终端上发出任何其他命令。在终端中按 ctrl-c 命令将停止 Mule。
启动 Mule 服务
我们可以将 Mule 作为 Windows 服务启动,也可以将其作为 Linux/Unix 守护进程启动。
将 Mule 作为 Windows 服务
要将 Mule 作为 Windows 服务运行,我们需要遵循以下步骤 −
步骤 1 − 首先,使用以下命令安装它 −
$ $MULE_HOME\bin\mule.bat install
步骤 2 − 安装后,我们可以使用以下命令将 mule 作为 Windows 服务运行:
$ $MULE_HOME\bin\mule.bat start
Mule 作为 Linux/Unix 守护进程
要将 Mule 作为 Linux/Unix 守护进程运行,我们需要遵循以下步骤 −
步骤 1 − 使用以下命令安装它 −
$ $MULE_HOME/bin/mule install
步骤 2 − 安装后,我们可以在以下命令的帮助下将 mule 作为 Windows 服务运行 −
$ $MULE_HOME/bin/mule start
示例
以下示例将 Mule 作为 Unix 守护进程启动 −
$ $MULE_HOME/bin/mule start MULE_HOME is set to ~/Downloads/mule-enterprise-standalone-4.1.5 MULE_BASE is set to ~/Downloads/mule-enterprise-standalone-4.1.5 Starting Mule Enterprise Edition... Waiting for Mule Enterprise Edition................. running: PID:87329
部署 Mule 应用
我们可以按照以下步骤部署 Mule 应用 −
步骤 1 − 首先,启动 Mule。
步骤 2 − 一旦 Mule 启动,我们就可以通过移动 JAR 包文件到 $MULE_HOME 中的 apps 目录来部署 Mule 应用。
停止 Mule 服务
我们可以使用 stop 命令来停止 Mule。例如,以下示例将 Mule 作为 Unix 守护进程启动 −
$ $MULE_HOME/bin/mule stop MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5 MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5 Stopping Mule Enterprise Edition... Stopped Mule Enterprise Edition.
我们还可以使用 remove 命令从系统中删除 Mule 服务或守护进程。以下示例将 Mule 作为 Unix 守护进程删除 −
$ $MULE_HOME/bin/mule remove MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5 MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5 Detected Mac OSX: Mule Enterprise Edition is not running. Removing Mule Enterprise Edition daemon...
MuleSoft - Anypoint Studio
MuleSoft 的 Anypoint Studio 是一个用户友好的 IDE(集成开发环境),用于设计和测试 Mule 应用程序。它是一个基于 Eclipse 的 IDE。我们可以轻松地从 Mule Palette 中拖动连接器。换句话说,Anypoint Studio 是一个基于 Eclipse 的 IDE,用于开发流程等。
先决条件
在所有操作系统(即 Windows、Mac 和 Linux/Unix)上安装 Mule 之前,我们需要满足以下先决条件。
Java 开发工具包 (JDK) − 在安装 Mule 之前,请验证您的系统上是否支持 Java 版本。建议使用 JDK 1.8.0 才能在您的系统上成功安装 Anypoint。
下载和安装 Anypoint Studio
在不同操作系统上下载和安装 Anypoint Studio 的过程可能有所不同。接下来,在各种操作系统上下载和安装 Anypoint Studio 需要遵循以下步骤 −
在 Windows 上
要在 Windows 上下载和安装 Anypoint Studio,我们需要遵循以下步骤 −
步骤 1 −首先,单击链接 https://www.mulesoft.com/lp/dl/studio 并从上到下的列表中选择 Windows 操作系统以下载工作室。
步骤 2 − 现在,将其解压到 'C:\' 根文件夹中。
步骤 3 − 打开解压的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击确定。首次加载时,您将收到一条欢迎消息。
步骤 5 −现在,单击"开始"按钮以使用 Anypoint Studio。
在 OS X 上
要在 OS X 上下载并安装 Anypoint Studio,我们需要按照以下步骤操作 −
步骤 1 − 首先,单击链接 https://www.mulesoft.com/lp/dl/studio 并下载工作室。
步骤 2 − 现在,提取它。如果您使用的是 OS 版本 Sierra,请确保在启动之前将解压的应用程序移动到 /Applications 文件夹。
步骤 3 − 打开解压的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击"确定"。首次加载时,您将收到一条欢迎消息。
步骤 5 − 现在,单击开始按钮以使用 Anypoint Studio。
如果您要使用自定义路径到您的工作区,请注意 Anypoint Studio 不会展开 Linux/Unix 系统中使用的 ~ 波浪符号。因此,建议在定义工作区时使用绝对路径。
在 Linux 上
要在 Linux 上下载并安装 Anypoint Studio,我们需要按照以下步骤操作 −
步骤 1 − 首先,单击链接 https://www.mulesoft.com/lp/dl/studio 并从上到下的列表中选择 Linux 操作系统以下载工作室。
步骤 2 − 现在,提取它。
步骤 3 −接下来,打开解压的 Anypoint Studio。
步骤 4 − 要接受默认工作区,请单击"确定"。首次加载时,您将收到一条欢迎消息。
步骤 5 − 现在,单击"开始"按钮以使用 Anypoint Studio。
如果您要使用自定义路径到您的工作区,请注意,Anypoint Studio 不会展开 Linux/Unix 系统中使用的 ~ 波浪符号。因此,建议在定义工作区时使用绝对路径。
还建议安装 GTK 版本 2 以在 Linux 中使用完整的 Studio 主题。
Anypoint Studio 的功能
以下是 Anypoint Studio 的一些功能,可在构建 Mule 应用程序时提高工作效率 −
它可在本地运行时内即时运行 Mule 应用程序。
Anypoint Studio 为我们提供了用于配置 API 定义文件和 Mule 域的可视化编辑器。
它具有嵌入式单元测试框架,可提高工作效率。
Anypoint Studio 为我们提供了部署到 CloudHub 的内置支持。
它具有与 Exchange 集成的功能,可从其他 Anypoint Platform 组织导入模板、示例、定义和其他资源。
MuleSoft - Discovering Anypoint Studio
Anypoint Studio 编辑器可帮助我们设计应用程序、API、属性和配置文件。除了设计之外,它还帮助我们编辑它们。为此,我们有 Mule 配置文件编辑器。要打开此编辑器,请双击 /src/main/mule 中的应用程序 XML 文件。
要使用我们的应用程序,我们在 Mule 配置文件编辑器下有以下三个选项卡。
"消息流"选项卡
此选项卡以直观的方式表示工作流程。它基本上包含一个画布,可帮助我们直观地检查流程。如果您想将事件处理器从 Mule 面板添加到画布中,只需拖放即可反映在画布中。
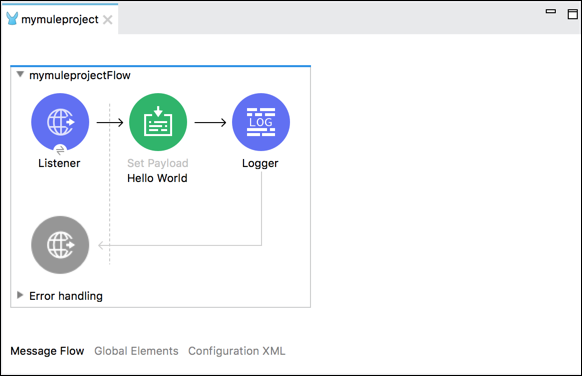
通过单击事件处理器,您可以获得 Mule 属性视图,其中包含所选处理器的属性。我们也可以编辑它们。
全局元素选项卡
此选项卡包含模块的全局 Mule 配置元素。在此选项卡下,我们可以创建、编辑或删除配置文件。
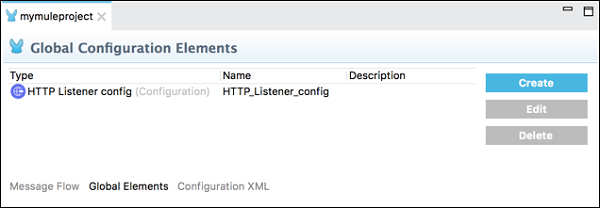
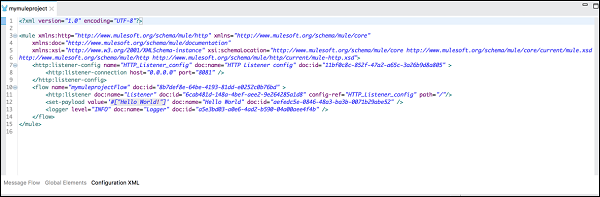
配置 XML 选项卡
顾名思义,它包含定义 Mule 应用程序的 XML。您在此处所做的所有更改都将反映在画布以及"消息流"选项卡下的事件处理器的属性视图中。
视图
对于活动编辑器,Anypoint Studio 借助视图为我们提供项目元数据和属性的图形表示。用户可以在 Mule 项目中移动、关闭和添加视图。以下是 Anypoint Studio 中的一些默认视图 −
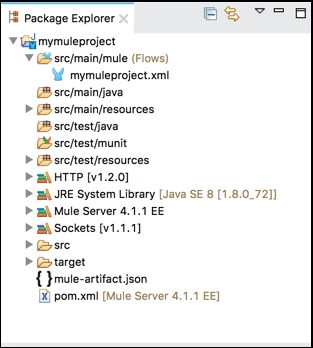
包资源管理器
包资源管理器视图的主要任务是显示 Mule 项目中包含的项目文件夹和文件。我们可以通过单击旁边的箭头来展开或收缩 Mule 项目文件夹。双击即可打开文件夹或文件。看看它的屏幕截图 −
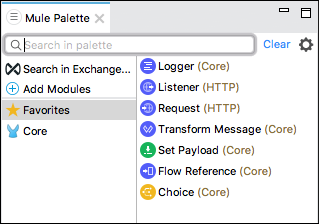
Mule Palette
Mule Palette 视图显示事件处理器(如范围、过滤器和流控制路由器)以及模块及其相关操作。Mule Palette 视图的主要任务如下 −
- 此视图可帮助我们管理项目中的模块和连接器。
- 我们还可以从 Exchange 添加新元素。
看看它的屏幕截图 −
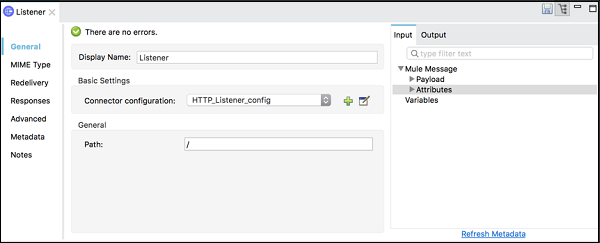
Mule 属性
顾名思义,它允许我们编辑画布中当前选定模块的属性。 Mule 属性视图包括以下内容 −
DataSense Explorer 提供有关我们有效负载数据结构的实时信息。
入站和出站属性(如果可用)或变量。
以下是屏幕截图 −
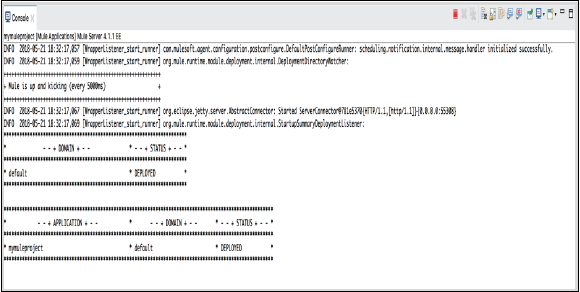
控制台
每当我们创建或运行 Mule 应用程序时,嵌入式 Mule 服务器都会显示 Studio 报告的事件和问题(如果有)列表。控制台视图包含该嵌入式 Mule 服务器的控制台。看一下它的屏幕截图 −
问题视图
在处理 Mule 项目时,我们可能会遇到许多问题。所有这些问题都显示在"问题"视图中。以下是屏幕截图

视角
在 Anypoint Studio 中,它是按指定排列的视图和编辑器的集合。Anypoint Studio 中有两种视角 −
Mule 设计视角 − 这是我们在 Studio 中获得的默认视角。
Mule 调试视角 − Anypoint Studio 提供的另一个视角是 Mule Debug Perspective。
另一方面,我们也可以创建自己的视角,并可以添加或删除任何默认视图。
MuleSoft - 创建第一个 Mule 应用程序
在本章中,我们将在 MuleSoft 的 Anypoint Studio 中创建我们的第一个 Mule 应用程序。要创建它,首先我们需要启动 Anypoint Studio。
启动 Anypoint Studio
单击 Anypoint Studio 以启动它。如果您是第一次启动它,那么您将看到以下窗口 −
Anypoint Studio 的用户界面
单击"转到工作区"按钮后,它将引导您进入 Anypoint Studio 的用户界面,如下所示 −
创建 Mule 应用程序的步骤
要创建您的 Mule 应用程序,请按照以下步骤 −
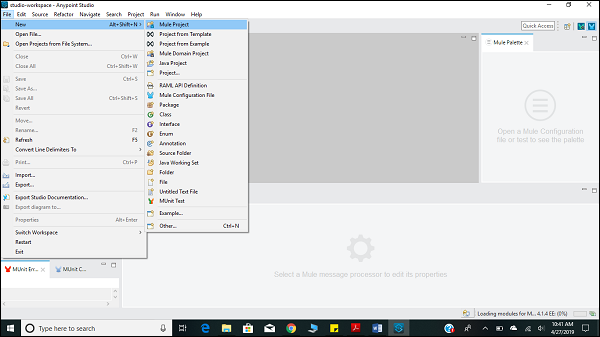
创建新项目
创建 Mule 应用程序的第一步是创建一个新项目。可以通过以下路径 FILE → NEW → Mule Project 完成此操作,如下所示 −
命名项目
单击新的 Mule 项目后,如上所述,它将打开一个新窗口,要求输入项目名称和其他规范。将项目命名为"TestAPP1",然后单击完成按钮。
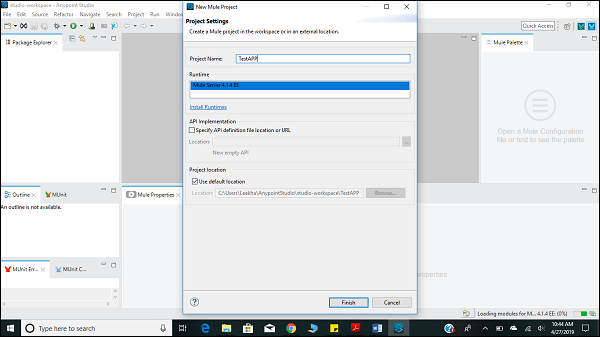
单击完成按钮后,它将打开为您的 MuleProject 构建的工作区,即"TestAPP1"。您可以看到上一章中描述的所有 编辑器 和 视图。
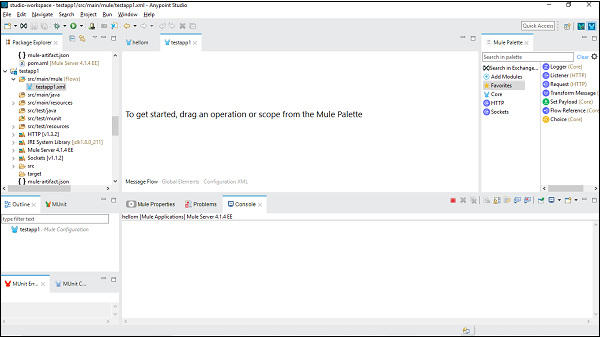
配置连接器
在这里,我们将为 HTTP 侦听器构建一个简单的 Mule 应用程序。为此,我们需要将 HTTP 侦听器连接器从 Mule Palette 拖放到工作区,如下所示 −
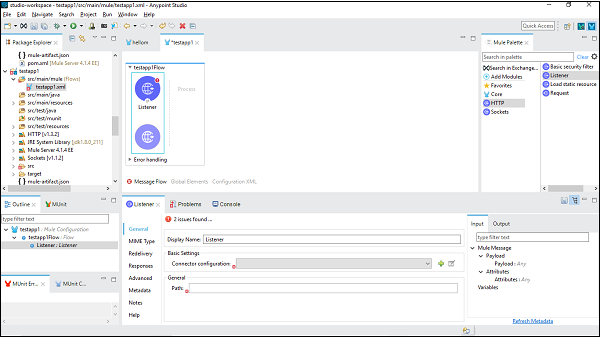
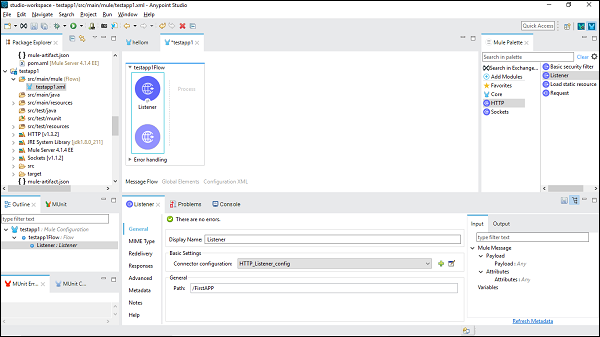
现在,我们需要对其进行配置。如上所示,在"基本设置"下的"连接器配置"后单击绿色 + 号。
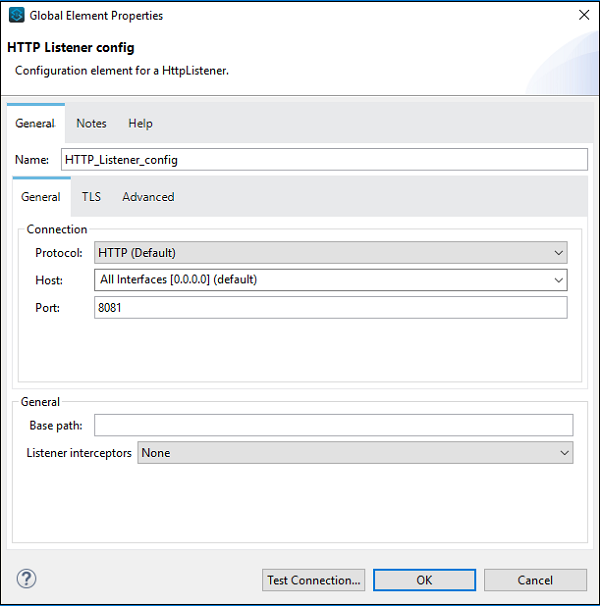
单击"确定"后,将返回 HTTP 侦听器属性页。现在我们需要在"常规"选项卡下提供路径。在此特定示例中,我们提供了 /FirstAPP 作为路径名。
配置 Set Payload 连接器
现在,我们需要使用 Set Payload 连接器。我们还需要在"设置"选项卡下为其赋值,如下所示 −
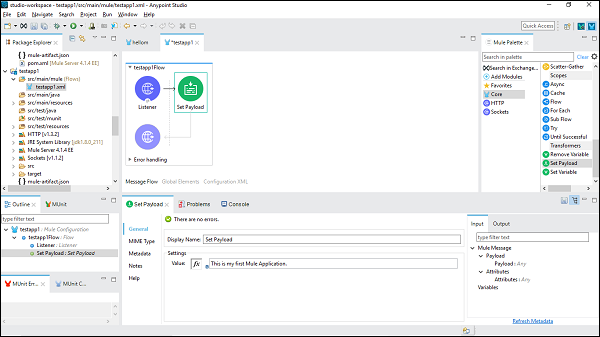
这是我的第一个 Mule 应用程序,是本示例中提供的名称。
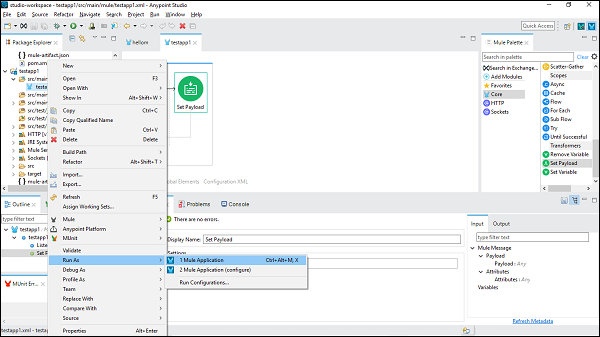
运行 Mule 应用程序
现在,保存它并单击作为 Mule 应用程序运行,如下所示 −
我们可以在部署应用程序的控制台下检查它,如下所示 −
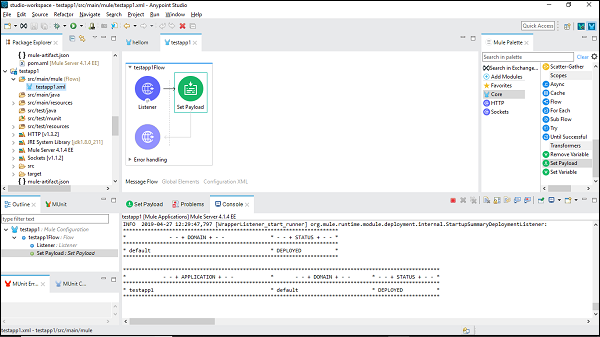
它表明您已成功构建了您的第一个 Mule 应用程序。
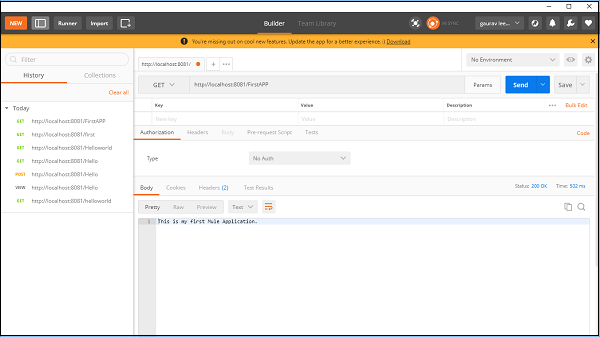
验证 Mule 应用程序
现在,我们需要测试我们的应用程序是否正在运行。转到 POSTMAN(Chrome 应用程序)并输入网址:http:/localhost:8081。它显示了我们在构建 Mule 应用程序时提供的消息,如下所示 −
MuleSoft - DataWeave 语言
DataWeave 基本上是一种 MuleSoft 表达式语言。它主要用于访问和转换通过 Mule 应用程序接收的数据。Mule 运行时负责运行 Mule 应用程序中的脚本和表达式,DataWeave 与 Mule 运行时紧密集成。
DataWeave 语言的功能
以下是 DataWeave 语言的一些重要功能 −
数据可以非常轻松地从一种格式转换为另一种格式。例如,我们可以将 application/json 转换为 application/xml。输入有效负载如下−
{
"title": "MuleSoft",
"author": " tutorialspoint.com ",
"year": 2019
}
以下是 DataWeave 中用于转换的代码 −
%dw 2.0
output application/xml
---
{
order: {
'type': 'Tutorial',
'title': payload.title,
'author': upper(payload.author),
'year': payload.year
}
}
接下来,输出有效负载如下 −
<?xml version = '1.0' encoding = 'UTF-8'?> <order> <type>Tutorial</type> <title>MuleSoft</title> <author>tutorialspoint.com</author> <year>2019</year> </order>
转换组件可用于创建执行简单和复杂数据转换的脚本。
我们可以访问和使用 Mule 事件部分的核心 DataWeave 函数,因为大多数 Mule 消息处理器都支持 DataWeave 表达式。
先决条件
在我们的计算机上使用 DataWeave 脚本之前,我们需要满足以下先决条件 −
使用 Dataweave 脚本需要 Anypoint Studio 7。
安装 Anypoint Studio 后,我们需要设置一个带有转换消息组件的项目才能使用 DataWeave 脚本。
使用 DataWeave 脚本的步骤(带示例)
为了使用 DataWeave 脚本,我们需要遵循以下步骤−
步骤 1
首先,我们需要像上一章一样,通过使用 File →New →Mule Project 来设置一个新项目。
步骤 2
接下来,我们需要提供项目的名称。在本例中,我们将其命名为 Mule_test_script。
步骤 3
现在,我们需要将 Transform Message 组件 从 Mule Palette 选项卡 拖到 canvas 中。如下所示 −
步骤 4
接下来,在 Transform Message 组件 选项卡中,单击 Preview 以打开 Preview 窗格。我们可以通过单击"预览"旁边的空矩形来展开源代码区域。
步骤 5
现在,我们可以开始使用 DataWeave 语言编写脚本。
示例
以下是将两个字符串连接成一个字符串的简单示例 −
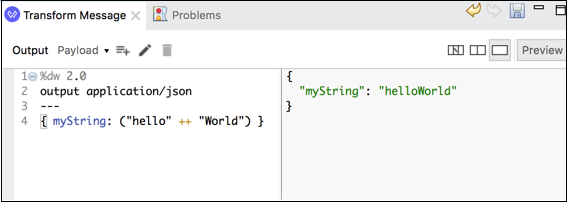
上述 DataWeave 脚本有一个键值对 ({ myString: ("hello" ++ "World") }),它将两个字符串连接成一个。
MuleSoft - 核心组件和配置
Mule 最重要的功能之一是它可以对组件进行路由、转换和处理,因此,结合各种元素的 Mule 应用程序的配置文件非常大。
以下是 Mule 提供的配置模式类型 −
- 简单服务模式
- 桥接
- 验证器
- HTTP 代理
- WS 代理
配置组件
在 Anypoint Studio 中,我们可以按照以下步骤配置组件 −
步骤 1
我们需要将想要使用的组件拖放到我们的 Mule 应用程序中。例如,这里我们使用 HTTP 侦听器组件,如下所示 −
步骤 2
接下来,双击组件以获取配置窗口。对于 HTTP 侦听器,它显示如下 −
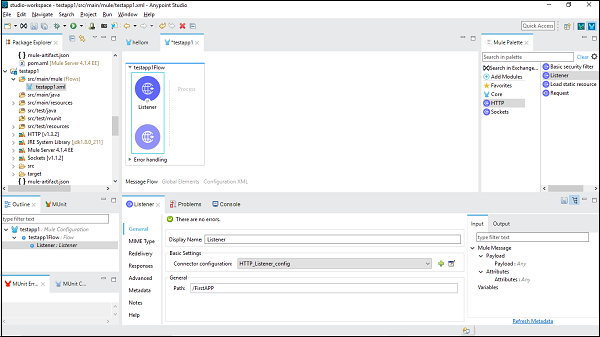
步骤 3
我们可以根据项目要求配置组件。举例来说,我们为 HTTP 侦听器组件做了 −
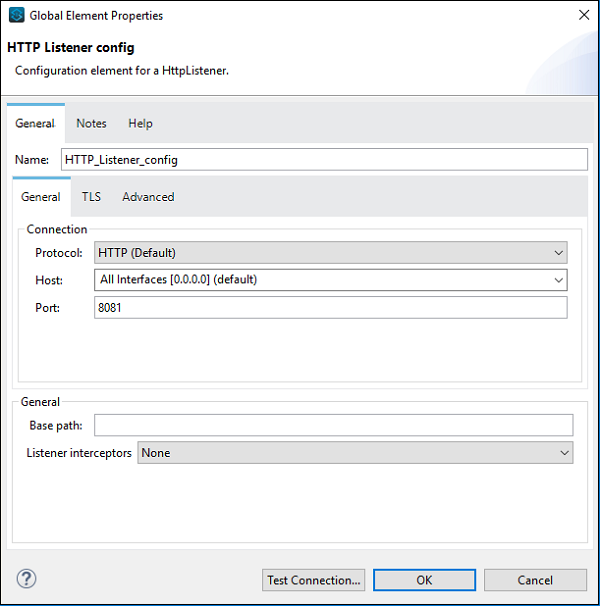
核心组件是 Mule 应用程序中工作流程的重要组成部分之一。处理 Mule 事件的逻辑由这些核心组件提供。在 Anypoint Studio 中,要访问这些核心组件,您可以单击 Mule Palette 中的 Core,如下所示 −
以下是各种核心组件及其在 Mule 4中的工作 −
自定义业务事件
此核心组件用于收集有关流程的信息以及处理 Mule 应用程序中的业务交易的消息处理器。换句话说,我们可以使用自定义业务事件组件在我们的工作流程中添加以下内容 −
- 元数据
- 关键绩效指标 (KPI)
如何添加 KPI?
以下是在 Mule 应用程序的流程中添加 KPI 的步骤 −
步骤 1 − 按照 Mule 调色板 → 核心 → 组件 → 自定义业务事件,将自定义业务事件组件添加到 Mule 应用程序的工作流程中。
步骤 2 − 单击组件将其打开。
步骤 3 −现在,我们需要为显示名称和事件名称提供值。
步骤 4 − 要从消息负载中捕获信息,请按如下方式添加 KPI −
为 KPI(tracking: meta-data 元素)提供一个名称(键)和一个值。该名称将在运行时管理器的搜索界面中使用。
提供一个可以是任何 Mule 表达式的值。
示例
下表包含带有名称和值的 KPI 列表 −
| 名称 | 表达式/值 |
|---|---|
| Student RollNo | #[payload['RollNo']] |
| Student Name | #[payload['Name']] |
动态评估
此核心组件用于在 Mule 应用程序中动态选择脚本。我们也可以通过 Transform Message 组件使用硬核脚本,但使用动态评估组件是更好的方法。此核心组件的工作原理如下 −
- 首先,它评估应产生另一个脚本的表达式。
- 然后它评估该脚本以获得最终结果。
通过这种方式,它允许我们动态选择脚本而不是对其进行硬编码。
示例
以下是通过 Id 查询参数从数据库中选择脚本并将该脚本存储在名为 MyScript 的变量中的示例。现在,动态评估组件将访问变量来调用脚本,以便它可以从 UName 查询参数中添加名称变量。
流程的 XML 配置如下所示 −
<flow name = "DynamicE-example-flow">
<http:listener config-ref = "HTTP_Listener_Configuration" path = "/"/>
<db:select config-ref = "dbConfig" target = "myScript">
<db:sql>#["SELECT script FROM SCRIPTS WHERE ID =
$(attributes.queryParams.Id)"]
</db:sql>
</db:select>
<ee:dynamic-evaluate expression = "#[vars.myScript]">
<ee:parameters>#[{name: attributes.queryParams.UName}]</ee:parameters>
</ee:dynamic-evaluate>
</flow>
脚本可以使用上下文变量,如消息、有效负载、变量或属性。但是,如果您想添加自定义上下文变量,则需要提供一组键值对。
配置动态评估
下表提供了一种配置动态评估组件的方法 −
| 字段 | 值 | 描述 | 示例 |
|---|---|---|---|
| Expression | DataWeave expression | It specifies the expression to be evaluated into the final script. | expression="#[vars.generateOrderScript]" |
| Parameters | DataWeave expression | It specifies key-value pairs. | #[{joiner: ' and ', id: payload.user.id}] |
流程引用组件
如果您想将 Mule 事件路由到另一个流程或子流程,并在同一个 Mule 应用程序中返回,那么流程引用组件是正确的选择。
特点
以下是此核心组件的特点 −
此核心组件允许我们将整个引用流程视为当前流程中的单个组件。
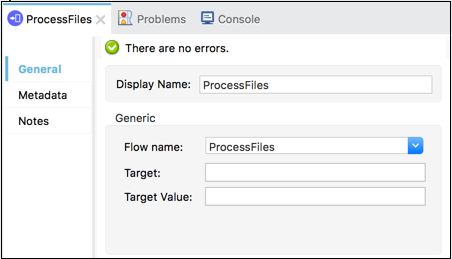
它将 Mule 应用程序分解为离散且可重复使用的单元。例如,流程定期列出文件。它可能会引用处理列表操作输出的另一个流程。
这样,我们可以附加指向处理流程的流程引用,而不是附加整个处理步骤。下面的屏幕截图显示,Flow Reference Core Component 指向名为 ProcessFiles 的子流。
工作原理
可以借助下图了解 Flow Ref 组件的工作原理 −
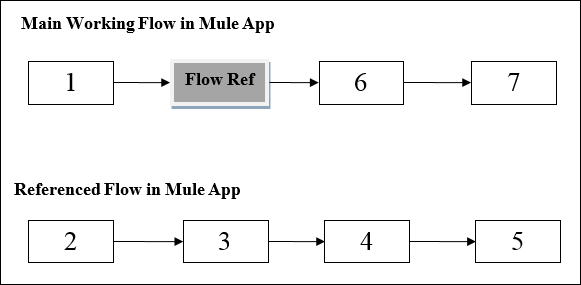
该图显示了当一个流引用同一应用程序中的另一个流时,Mule 应用程序中的处理顺序。当 Mule 应用程序中的主要工作流触发时,Mule 事件将贯穿始终并执行该流,直到 Mule 事件到达 Flow Reference。
到达 Flow Reference 后,Mule 事件将从头到尾执行引用的流。一旦 Mule 事件完成执行 Ref Flow,它就会返回到主流程。
示例
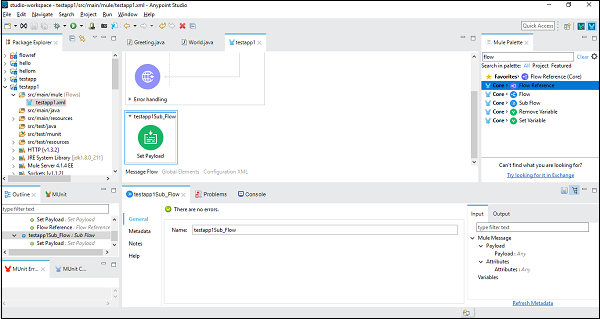
为了更好地理解,让我们在 Anypoint Studio 中使用此组件。在此示例中,我们将使用 HTTP 侦听器来获取消息,就像我们在上一章中所做的那样。因此,我们可以拖放组件并进行配置。但对于此示例,我们需要添加一个子流组件并在其下设置 Payload 组件,如下所示 −
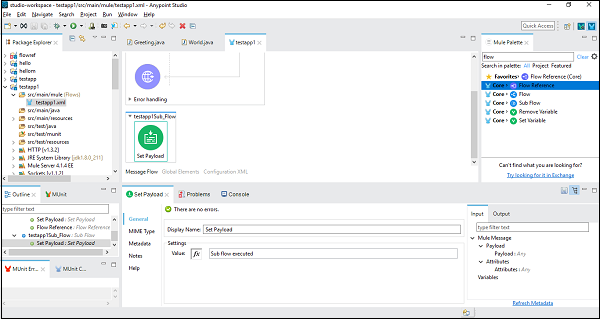
接下来,我们需要通过双击来配置Set Payload。这里我们给出值"子流执行",如下所示 −
成功配置子流组件后,我们需要在设置主流的有效负载后设置流参考组件,我们可以从 Mule Palette 中拖放它,如下所示 −
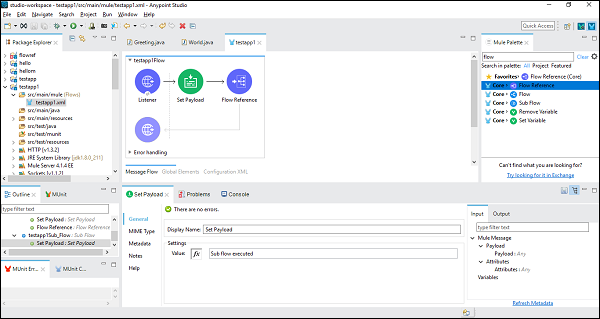
接下来,在配置流参考组件时,我们需要在通用选项卡下选择流名称,如下所示 −
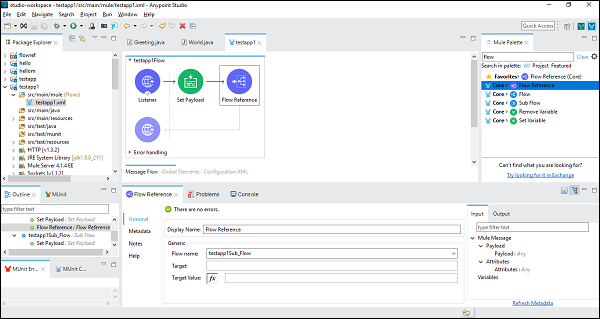
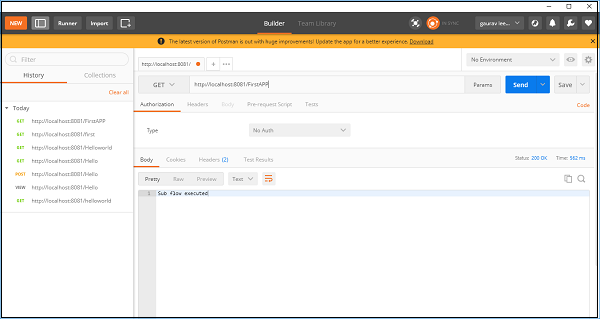
现在,保存并运行此应用程序。要测试这一点,请转到 POSTMAN 并在 URL 栏中输入 http:/localhost:8181/FirstAPP,您将收到消息"子流程已执行"。
记录器组件
名为 logger 的核心组件通过记录重要信息(如错误消息、状态通知、有效负载等)帮助我们监控和调试 Mule 应用程序。在 AnyPoint 工作室中,它们出现在控制台中。
优点
以下是记录器组件的一些优点 −
- 我们可以在工作流程的任何地方添加这个核心组件。
- 我们可以将其配置为记录我们指定的字符串。
- 我们可以将其配置为我们编写的 DataWeave 表达式的输出。
- 我们还可以将其配置为字符串和表达式的任意组合。
示例
下面的示例在浏览器中的 Set Payload 中显示消息"Hello World",并记录该消息。
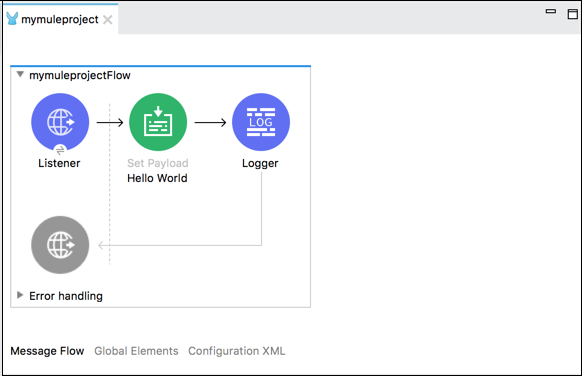
以下是上述示例中流程的 XML 配置 −
<http:listener-config name = "HTTP_Listener_Configuration" host = "localhost" port = "8081"/> <flow name = "mymuleprojectFlow"> <http:listener config-ref="HTTP_Listener_Configuration" path="/"/> <set-payload value="Hello World"/> <logger message = "#[payload]" level = "INFO"/> </flow>
传输消息组件
转换消息组件,也称为传输组件,允许我们将输入数据转换为新的输出格式。
构建转换的方法
我们可以借助以下两种方法构建转换 −
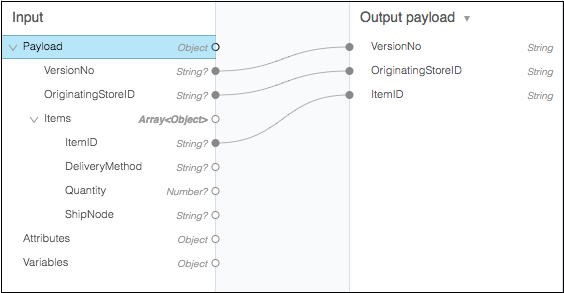
拖放编辑器(图形视图) − 这是构建转换的第一个也是最常用的方法。在此方法中,我们可以使用此组件的可视化映射器拖放传入数据结构的元素。例如,在下图中,两个树形视图显示了输入和输出的预期元数据结构。连接输入和输出字段的线表示两个树视图之间的映射。
脚本视图 − 转换的可视化映射也可以借助 DataWeave(一种用于 Mule 代码的语言)来表示。我们可以对一些高级转换进行编码,如聚合、规范化、分组、连接、分区、透视和过滤。示例如下 −
这个核心组件基本上接受变量、属性或消息有效负载的输入和输出元数据。我们可以提供以下格式特定的资源 −
- CSV
- Schema
- 平面文件 Schema
- JSON
- 对象类
- 简单类型
- XML Schema
- Excel 列名称和类型
- 固定宽度列名称和类型
MuleSoft - 端点
端点基本上包括触发或启动 Mule 应用程序工作流程中的处理的组件。它们在 Anypoint Studio 中称为 源,在 Mule 的设计中心中称为 触发器。Mule 4 中的一个重要端点是 调度程序组件。
调度程序端点
此组件在基于时间的条件下工作,这意味着,它使我们能够在满足基于时间的条件时触发流程。例如,调度程序可以每隔 10 秒触发一次事件来启动 Mule 工作流程。我们还可以使用灵活的 Cron 表达式来触发 Scheduler Endpoint。
关于 Scheduler 的要点
使用 Scheduler 事件时,我们需要注意以下几点 −
Scheduler Endpoint 遵循 Mule 运行时所在机器的时区。
假设 Mule 应用程序在 CloudHub 中运行,Scheduler 将遵循 CloudHub 工作器所在区域的时区。
在任何给定时间,只能有一个由 Scheduler Endpoint 触发的流处于活动状态。
在 Mule 运行时集群中,Scheduler Endpoint 仅在主节点上运行或触发。
配置 Scheduler 的方法
如上所述,我们可以配置一个调度程序端点以固定间隔触发,或者我们也可以给出一个 Cron 表达式。
配置调度程序的参数(用于固定间隔)
以下是设置调度程序以定期触发流的参数 −
频率 − 它基本上描述了调度程序端点将以什么频率触发 Mule 流。可以从时间单位字段中选择此时间单位。如果您不为此提供任何值,它将使用默认值 1000。另一方面,如果您提供 0 或负值,那么它也会使用默认值。
启动延迟 − 这是应用程序启动后我们必须等待的时间,然后才能第一次触发 Mule 流。启动延迟的值以与频率相同的时间单位表示。其默认值为 0。
时间单位 − 它描述了频率和启动延迟的时间单位。时间单位的可能值为毫秒、秒、分钟、小时、天。默认值为毫秒。
配置 Scheduler 的参数(用于 Cron 表达式)
实际上,Cron 是用于描述时间和日期信息的标准。如果您使用灵活的 Cron 表达式来触发 Scheduler,Scheduler Endpoint 会跟踪每一秒,并在 Quartz Cron 表达式与时间日期设置匹配时创建 Mule 事件。使用 Cron 表达式,事件可以仅触发一次或定期触发。
下表给出了六个必需设置的日期时间表达式 −
| 属性 | 值 |
|---|---|
| Seconds | 0-59 |
| Minutes | 0-59 |
| Hours | 0-23 |
| Day of month | 1-31 |
| Month | 1-12 or JAN-DEC |
| Day of the week | 1-7 or SUN-SAT |
Scheduler Endpoint 支持的 Quartz Cron 表达式的一些示例如下 −
½ * * * * ? − 表示调度程序每天每 2 秒运行一次。
0 0/5 16 ** ? − 表示调度程序每天从下午 4 点开始到下午 4:55 结束每 5 分钟运行一次。
1 1 1 1, 5 * ? − 表示调度程序每年 1 月 1 日和 4 月 1 日运行。
示例
以下代码每秒记录一次消息"hi"−
<flow name = "cronFlow" doc:id = "ae257a5d-6b4f-4006-80c8-e7c76d2f67a0">
<doc:name = "Scheduler" doc:id = "e7b6scheduler8ccb-c6d8-4567-87af-aa7904a50359">
<scheduling-strategy>
<cron expression = "* * * * * ?" timeZone = "America/Los_Angeles"/>
</scheduling-strategy>
</scheduler>
<logger level = "INFO" doc:name = "Logger"
doc:id = "e2626dbb-54a9-4791-8ffa-b7c9a23e88a1" message = '"hi"'/>
</flow>
MuleSoft - 流控制和转换器
流控制(路由器)
流控制组件的主要任务是接收输入的 Mule 事件并将其路由到一个或多个单独的组件序列。它基本上是将输入的 Mule 事件路由到其他组件序列。因此,它也被称为路由器。选择和分散-聚集路由器是流控制组件下最常用的路由器。
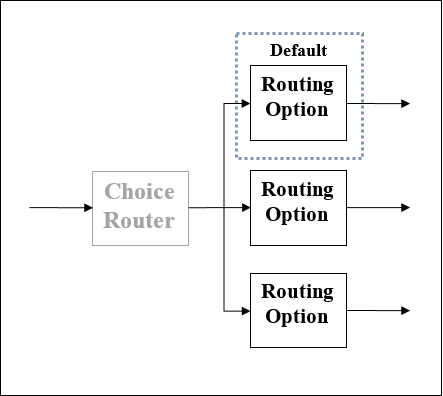
选择路由器
顾名思义,此路由器应用 DataWeave 逻辑来选择两个或多个路由中的一个。如前所述,每个路由都是一个单独的 Mule 事件处理器序列。我们可以将选择路由器定义为根据用于评估消息内容的一组 DataWeave 表达式动态地通过流路由消息的路由器。
选择路由器示意图
使用选择路由器的效果就像在大多数编程语言中向流或 if/then/else 代码块添加条件处理一样。以下是选择路由器的示意图,有三个选项。其中一个是默认路由器。
分散-聚集路由器
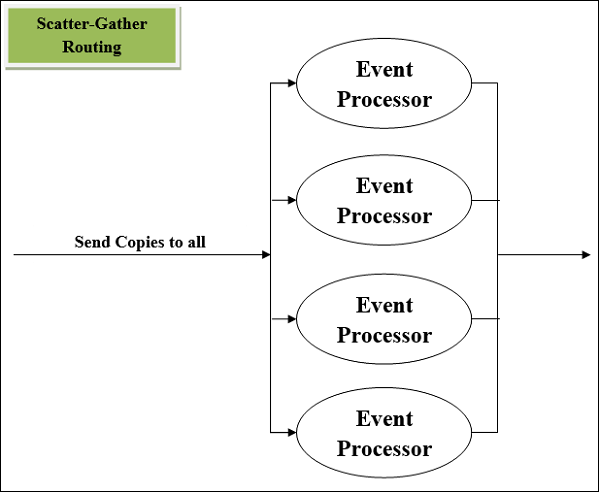
另一个最常用的路由事件处理器是 分散-聚集组件。顾名思义,它基于分散(复制)和聚集(合并)的基本原理工作。我们可以通过以下两点来理解它的工作原理 −
首先,该路由器将 Mule 事件复制(分散)到两个或多个并行路由。条件是每个路由必须是一个或多个事件处理器的序列,就像一个子流。在这种情况下,每个路由将使用单独的线程创建一个 Mule 事件。每个 Mule 事件都有自己的有效负载、属性以及变量。
接下来,该路由器从每个路由收集创建的 Mule 事件,然后将它们合并为一个新的 Mule 事件。此后,它将这个合并的 Mule 事件传递给下一个事件处理器。这里的条件是,只有当每条路由都成功完成时,S-G 路由器才会将合并的 Mule 事件传递给下一个事件处理器。
Scatter-Gather 路由器示意图
以下是具有四个事件处理器的 Scatter-Gather 路由器示意图。它并行执行每个路由,而不是按顺序执行。
Scatter-Gather 路由器的错误处理
首先,我们必须了解 Scatter-Gather 组件中可能生成的错误类型。事件处理器中可能生成任何错误,导致 Scatter-Gather 组件抛出类型为 Mule: COMPOSITE_ERROR 的错误。仅当每个路由失败或完成后,S-G 组件才会抛出此错误。
要处理此错误类型,可以在 Scatter-Gather 组件的每个路由中使用 try scope。如果错误被 try scope 成功处理,那么该路由肯定能够生成 Mule 事件。
Transformers
假设我们想设置或删除任何 Mule 事件的一部分,Transformer 组件是最佳选择。Transformer 组件有以下类型 −
删除变量转换器
顾名思义,此组件采用变量名称并从 Mule 事件中删除该变量。
配置删除变量转换器
下表显示了配置删除变量转换器时要考虑的字段名称及其描述 −
| Sr.No | 字段及说明 |
|---|---|
| 1 |
Display Name (doc:name) 我们可以自定义它以在我们的 Mule 工作流程中显示此组件的唯一名称。 |
| 2 | Name (variableName) 它表示要删除的变量的名称。 |
设置有效载荷转换器
借助set-payload组件,我们可以更新消息的有效载荷,该有效载荷可以是文字字符串或DataWeave表达式。不建议将此组件用于复杂的表达式或转换。它可以用于简单的表达式或转换,例如选择。
下表显示了配置设置有效载荷转换器时要考虑的字段名称及其描述 −
| 字段 | 用法 | 说明 |
|---|---|---|
| Value (value) | Mandatory | 设置有效负载需要值字段。它将接受文字字符串或 DataWeave 表达式来定义如何设置有效负载。示例就像"some string" |
| Mime Type (mimeType) | Optional | 它是可选的,但表示分配给消息有效负载的值的 mime 类型。示例如 text/plain。 |
| Encoding (encoding) | Optional | 它也是可选的,但表示分配给消息有效负载的值的编码。示例如 UTF-8。 |
我们可以通过 XML 配置代码设置有效负载 −
使用静态内容 − 以下 XML 配置代码将使用静态内容设置有效负载 −
<set-payload value = "{ 'name' : 'Gaurav', 'Id' : '2510' }"
mimeType = "application/json" encoding = "UTF-8"/>
使用表达式内容 − 下面的 XML 配置代码将使用表达式内容设置有效负载 −
<set-payload value = "#['Hi' ++ ' Today is ' ++ now()]"/>
上述示例将今天的日期附加到消息有效负载"Hi"。
设置变量转换器
借助设置变量组件,我们可以创建或更新变量来存储值,这些值可以是简单的文字值,如字符串、消息有效负载或属性对象,供 Mule 应用程序流程中使用。不建议将此组件用于复杂的表达式或转换。它可以用于简单的表达式或转换,如选择。
配置设置变量转换器
下表显示了配置设置有效负载转换器时要考虑的字段名称及其描述 −
| 字段 | 用法 | 说明 |
|---|---|---|
| Variable Name (variableName) | Mandatory | 必填字段,表示变量的名称。命名时,请遵循命名约定,例如必须包含数字、字符和下划线。 |
| Value (value) | Mandatory | 设置变量时需要值字段。它将接受文字字符串或 DataWeave 表达式。 |
| Mime Type (mimeType) | Optional | 它是可选的,但表示变量的 mime 类型。示例如 text/plain。 |
| Encoding (encoding) | Optional | 它也是可选的,但表示变量的编码。示例如 ISO 10646/Unicode(UTF-8)。 |
示例
下面的示例将变量设置为消息有效负载 −
Variable Name = msg_var Value = payload in Design center and #[payload] in Anypoint Studio
类似地,下面的示例将变量设置为消息有效负载 −
Variable Name = msg_var Value = attributes in Design center and #[attributes] in Anypoint Studio.
MuleSoft - 使用 Anypoint Studio 的 Web 服务
REST Web 服务
REST 的全称是 Representational State Transfer,它与 HTTP 绑定。因此,如果您想设计一个专门用于 Web 的应用程序,REST 是最佳选择。
使用 RESTful Web 服务
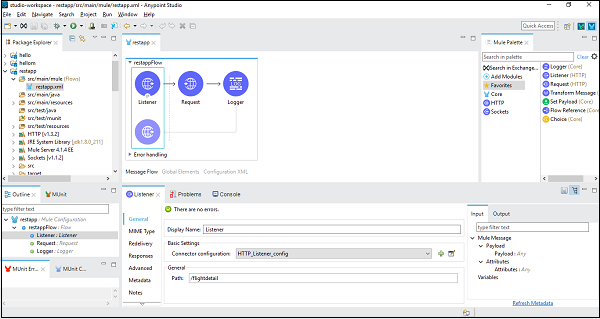
在下面的示例中,我们将使用 REST 组件和 Mule Soft 提供的一项名为 American Flights details 的公共 RESTful 服务。它有各种详细信息,但我们将使用 GET:http://training-american-ws.cloudhub.io/api/flights ,它将返回所有航班详细信息。如前所述,REST 与 HTTP 绑定,因此对于此应用程序,我们需要两个 HTTP 组件 —— 一个是 Listener,另一个是 Request。下面的屏幕截图显示了 HTTP 侦听器的配置 −
配置和传递参数
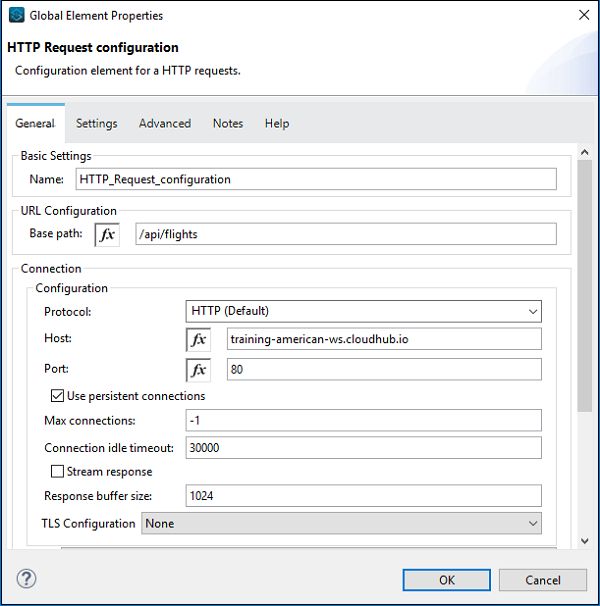
HTTP 请求的配置如下所示 −
现在,根据我们的工作区流程,我们已经采用了记录器,因此可以按如下方式配置它 −
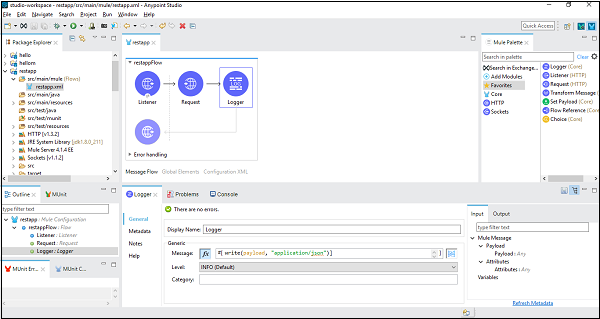
在消息选项卡中,我们编写代码将有效负载转换为字符串。
测试应用程序
现在,保存并运行应用程序并转到 POSTMAN检查最终输出,如下所示 −
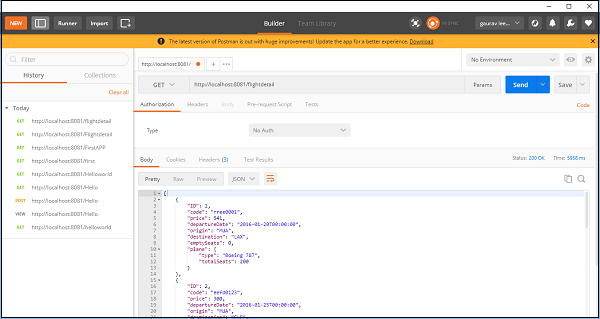
您可以看到它使用 REST 组件提供航班详细信息。
SOAP 组件
SOAP 的全称是 简单对象访问协议。它基本上是一种在 Web 服务实现中交换信息的消息传递协议规范。接下来,我们将在 Anypoint Studio 中使用 SOAP API 通过 Web 服务访问信息。
使用基于 SOAP 的 Web 服务
对于此示例,我们将使用公共 SOAP 服务,其名称为 Country Info Service,它保留与国家信息相关的服务。其 WSDL 地址为:http://www.oorsprong.org/websamples.countryinfo/countryinfoservice.wso?WSDL
首先,我们需要将 SOAP 消费从 Mule Palette 拖到我们的画布中,如下所示 −

配置和传递参数
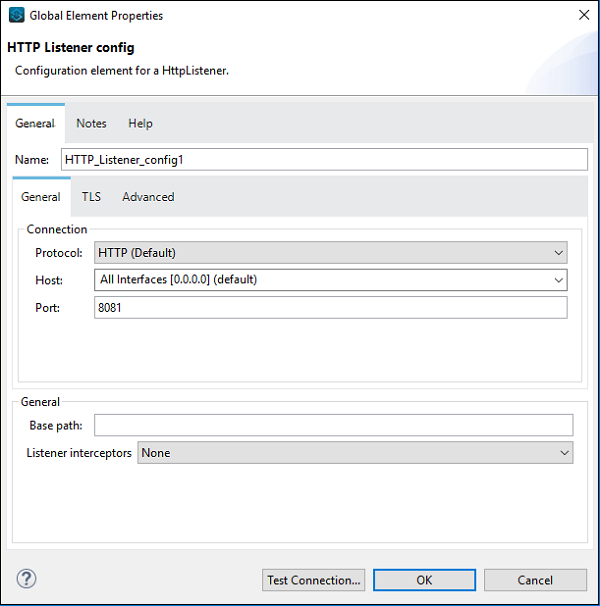
接下来,我们需要按照上述示例配置 HTTP 请求,如下所示 −
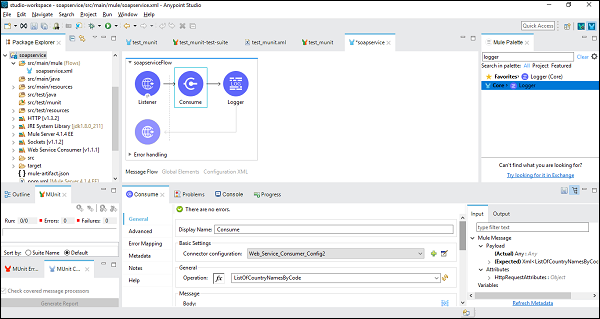
现在,我们还需要配置 Web 服务消费者,如下所示 −
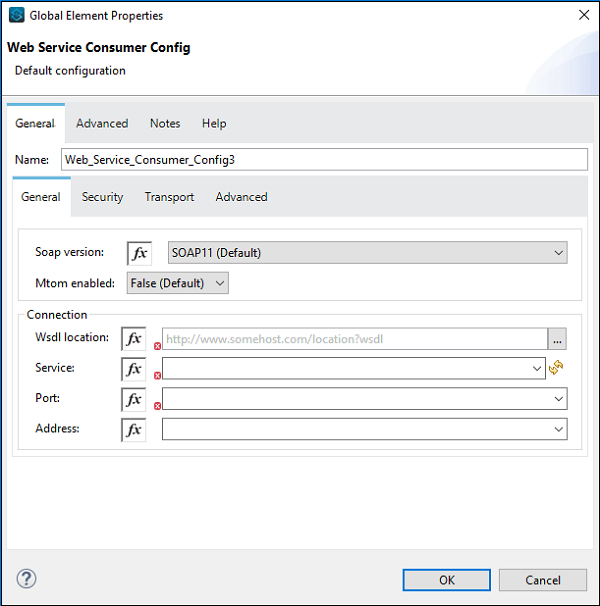
在 WSDL Location 处,我们需要提供 WSDL 的网址,该网址已在上面提供(针对此示例)。提供网址后,Studio 将自行搜索服务、端口和地址。您无需手动提供它。
从 Web 服务传输响应
为此,我们需要在 Mule 流中添加一个记录器,并将其配置为提供有效负载,如下所示 −
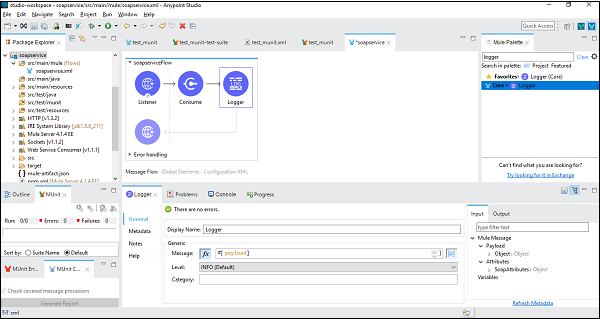
测试应用程序
保存并运行应用程序,然后转到 Google Chrome 检查最终输出。输入 http://localhist:8081/helloSOAP(本例中),它将通过代码显示国家名称,如下面的屏幕截图所示 −

MuleSoft - Mule 错误处理
新的 Mule 错误处理是 Mule 4 中最大的变化之一。新的错误处理可能看起来很复杂,但它更好、更高效。在本章中,我们将讨论 Mule 错误的组成部分、错误类型、Mule 错误的类别以及处理 Mule 错误的组件。
Mule 错误的组成部分
Mule 错误是 Mule 异常失败的结果,具有以下组成部分 −
描述
它是 Mule 错误的重要组成部分,它将提供有关问题的描述。其表达式如下 −
#[error.description]
类型
Mule 错误的类型组件用于描述问题。它还允许在错误处理程序中进行路由。其表达式如下 −
#[error.errorType]
Cause
Mule error 的 Cause 组件给出了导致失败的底层 java throwable。其表达式如下 −
#[error.cause]
Message
Mule error 的 Message 组件显示有关错误的可选消息。其表达式如下 −
#[error.errorMessage]
Child Errors
Mule error 的 Child Errors 组件提供了一个可选的内部错误集合。这些内部错误主要由 Scatter-Gather 等元素使用,以提供聚合路由错误。其表达式如下 −
#[error.childErrors]
示例
如果 HTTP 请求失败,状态代码为 401,则 Mule 错误如下 −
Description: HTTP GET on resource 'http://localhost:8181/TestApp'
failed: unauthorized (401)
Type: HTTP:UNAUTHORIZED
Cause: a ResponseValidatorTypedException instance
Error Message: { "message" : "Could not authorize the user." }
| Sr.NO | 错误类型和说明 |
|---|---|
| 1 | TRANSFORMATION 此错误类型表示转换值时发生错误。该转换是 Mule Runtime 内部转换,而不是 DataWeave 转换。 |
| 2 | EXPRESSION 这种错误类型表示在评估表达式时发生错误。 |
| 3 | VALIDATION 这种错误类型表示发生了验证错误。 |
| 4 | DUPLICATE_MESSAGE 当消息被处理两次时发生的一种验证错误。 |
| 5 | REDELIVERY_EXHAUSTED 当用尽了重新处理来自源的消息的最大尝试次数时,会发生这种错误类型。 |
| 6 | CONNECTIVITY 此错误类型表示建立连接时出现问题。 |
| 7 | ROUTING 此错误类型表示路由消息时发生错误。 |
| 8 | SECURITY 此错误类型表示发生了安全错误。例如,收到无效凭据。 |
| 9 | STREAM_MAXIMUM_SIZE_EXCEEDED 当流允许的最大大小用尽时,会发生此错误类型。 |
| 10 | TIMEOUT 表示处理消息时超时。 |
| 11 | UNKNOWN 此错误类型表示发生了意外错误。 |
| 12 | SOURCE 表示流程源中发生错误。 |
| 13 | SOURCE_RESPONSE 表示在处理成功响应时流程源中发生错误。 |
在上面的例子中,你可以看到 mule 错误的 message 组件。
错误类型
让我们借助错误类型的特点 − 来理解它
Mule 错误类型的第一个特点是它由 命名空间和标识符 组成。这使我们能够根据其领域区分类型。在上面的例子中,错误类型是 HTTP: UNAUTHORIZED。
第二个重要的特点是错误类型可能有一个父类型。例如,错误类型 HTTP: UNAUTHORIZED 的父类型是 MULE:CLIENT_SECURITY,而后者又有一个名为 MULE:SECURITY 的父类型。此特性将错误类型确立为更全局项的规范。
错误类型的种类
以下是所有错误都属于的类别 −
ANY
此类别下的错误是流程中可能发生的错误。它们不太严重,可以轻松处理。
CRITICAL
此类别下的错误是无法处理的严重错误。以下是此类别下的错误类型列表 −
| Sr.NO | 错误类型和描述 |
|---|---|
| 1 | OVERLOAD 此错误类型表示由于过载问题而发生错误。在这种情况下,执行将被拒绝。 |
| 2 | FATAL_JVM_ERROR 此类错误类型表示发生致命错误。例如,stack overflow。 |
自定义错误类型
自定义错误类型是我们定义的错误。它们可以在映射或引发错误时定义。我们必须为这些错误类型提供一个特定的自定义命名空间,以将它们与 Mule 应用程序中其他现有的错误类型区分开来。例如,在使用 HTTP 的 Mule 应用程序中,我们不能使用 HTTP 作为自定义错误类型。
Mule 错误的类别
从广义上讲,Mule 中的错误可以分为两类,即消息错误和系统错误。
消息错误
此类别的 Mule 错误与 Mule 流程有关。每当 Mule 流程中出现问题时,Mule 都会抛出消息错误。我们可以在错误处理程序组件中设置 On Error 组件来处理这些 Mule 错误。
系统错误
系统错误表示在系统级别发生的异常。如果没有 Mule 事件,则系统错误由系统错误处理程序处理。以下类型的异常由系统错误处理程序处理 −
- 应用程序启动期间发生的异常。
- 与外部系统的连接失败时发生的异常。
如果发生系统错误,Mule 会向已注册的侦听器发送错误通知。它还会记录错误。另一方面,如果错误是由连接失败引起的,Mule 会执行重新连接策略。
处理 Mule 错误
Mule 有以下两个错误处理程序来处理错误 −
On-Error 错误处理程序
第一个 Mule 错误处理程序是 On-Error 组件,它定义了它们可以处理的错误类型。如前所述,我们可以在类似作用域的错误处理程序组件内配置 On-Error 组件。每个 Mule 流仅包含一个错误处理程序,但此错误处理程序可以根据需要包含任意数量的 On-Error 作用域。借助 On-Error 组件,在流程内部处理 Mule 错误的步骤如下 −
首先,每当 Mule 流程引发错误时,正常流程执行就会停止。
接下来,流程将转移到已经具有 On Error 组件 的 Error Handler 组件,以匹配错误类型和表达式。
最后,Error Handler 组件将错误路由到与错误匹配的第一个 On Error 作用域。
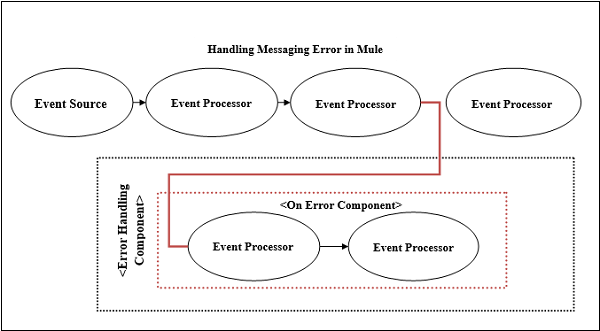
以下是 Mule 支持的两种类型的 On-Error 组件 −
On-Error传播
On-Error Propagate 组件执行,但会将错误传播到下一级别并中断所有者的执行。如果事务由 On Error Propagate 组件处理,则将回滚事务。
On-Error Continue
与 On-Error Propagate 组件一样,On-Error Continue 组件也会执行事务。唯一的条件是,如果所有者已成功完成执行,则此组件将使用执行结果作为其所有者的结果。如果事务由 On-Error Continue 组件处理,则将提交事务。
Try Scope 组件
Try Scope 是 Mule 4 中提供的众多新功能之一。它的工作原理类似于 JAVA 的 try 块,我们过去常常将可能出现异常的代码封装在其中,这样就可以在不破坏整个代码的情况下进行处理。
我们可以在 Try Scope 中包装一个或多个 Mule 事件处理器,然后,try scope 将捕获并处理这些事件处理器抛出的任何异常。try scope 的主要工作围绕其自身的错误处理策略,该策略支持其内部组件而不是整个流程的错误处理。这就是为什么我们不需要将流程提取到单独的流程中。
示例
以下是使用 try 范围的示例 −

配置 try 范围以处理事务
众所周知,事务是一系列永远不应部分执行的操作。事务范围内的所有操作都在同一线程中执行,如果发生错误,则应导致回滚或提交。我们可以按照以下方式配置 try 范围,以便它将子操作视为事务。
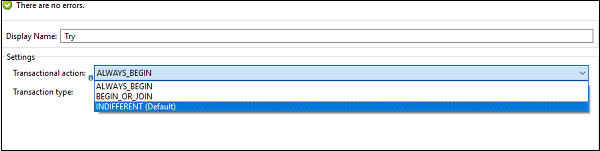
INDIFFERENT [Default] − 如果我们在 try 块上选择此配置,则子操作将不会被视为事务。 在这种情况下,错误既不会导致回滚也不会导致提交。
ALWAYS_BEGIN − 它表示每次执行范围时都会启动一个新事务。
BEGIN_OR_JOIN − 它表示如果流的当前处理已经开始了一个事务,则加入它。 否则,开始一个新的。
MuleSoft - Mule 异常处理
对于每个项目来说,异常都是必然会发生的。这就是为什么捕获、分类和处理异常很重要,这样系统/应用程序就不会处于不一致的状态。有一个默认的异常策略隐式应用于所有 Mule 应用程序。自动回滚任何待处理事务是默认的异常策略。
Mule 中的异常
在深入研究异常处理之前,我们应该了解可能发生哪种异常,以及开发人员在设计异常处理程序时必须考虑的三个基本问题。
哪种传输很重要?
在设计异常处理程序之前,这个问题具有足够的相关性,因为并非所有传输都支持跨国性。
文件或HTTP不支持事务。这就是为什么,如果在这些情况下发生异常,我们必须手动管理它。
数据库支持事务。在这种情况下设计异常处理程序时,我们必须记住数据库事务可以自动回滚(如果需要)。
对于REST API,我们应该记住它们应该返回正确的HTTP状态代码。例如,未找到资源时返回404。
使用哪种消息交换模式?
在设计异常处理程序时,我们必须注意消息交换模式。可以有同步(请求-回复)或异步(即发即弃)消息模式。
同步消息模式基于请求-回复格式,这意味着该模式将等待响应并将被阻止,直到返回响应或发生超时。
异步消息模式基于即发即弃格式,这意味着该模式假定请求最终将被处理。
这是哪种类型的异常?
非常简单的规则是,您将根据异常类型处理异常。知道异常是由系统/技术问题还是业务问题引起的非常重要。
由系统/技术问题(例如网络中断)引起的异常应通过重试机制自动处理。
另一方面,由业务问题(例如无效数据)引起的异常不应通过应用重试机制来解决,因为如果不解决根本原因,重试是没有用的。
为什么要对异常进行分类?
众所周知,所有异常都不一样,因此对异常进行分类非常重要。从高层次上讲,异常可以分为以下两种类型 −
业务异常
发生业务异常的主要原因是数据不正确或流程不正确。这类异常通常本质上是不可重试的,因此配置回滚并不好。即使应用重试机制也没有任何意义,因为如果不解决根本原因,重试是没有用的。为了处理此类异常,处理应立即停止,并将异常作为对死信队列的响应发送回。还应向操作发送通知。
非业务异常
发生非业务异常的主要原因是系统问题或技术问题。这类异常本质上是可重试的,因此配置重试机制以解决这些异常是很好的。
异常处理策略
Mule 有以下五种异常处理策略 −
默认异常策略
Mule 隐式地将此策略应用于 Mule 流程。它可以处理我们流程中的所有异常,但也可以通过添加 catch、Choice 或 Rollback 异常策略来覆盖它。此异常策略将回滚任何待处理事务并记录异常。此异常策略的一个重要特征是,如果没有事务,它也会记录异常。
作为默认策略,Mule 在流程中发生任何错误时都会实施此策略。我们无法在 AnyPoint 工作室中进行配置。
回滚异常策略
假设没有可能的解决方案来纠正错误,那么该怎么办?一种解决方案是使用回滚异常策略,它将回滚事务,同时向父流的入站连接器发送消息以重新处理该消息。当我们想要重新处理消息时,此策略也非常有用。
示例
此策略可应用于银行交易,其中资金存入支票/储蓄账户。我们可以在这里配置回滚异常策略,因为如果在交易期间发生错误,此策略会将消息回滚到流的开头以重新尝试处理。
捕获异常策略
此策略捕获其父流中抛出的所有异常。它通过处理父流抛出的所有异常来覆盖 Mule 的默认异常策略。我们可以使用捕获异常策略来避免将异常传播到入站连接器和父流。
此策略还可确保在发生异常时不会回滚由流处理的事务。
示例
此策略可应用于航班预订系统,其中我们有一个用于处理来自队列的消息的流程。消息丰富器在消息上添加一个属性以分配座位,然后将消息发送到另一个队列。
现在,如果此流程中发生任何错误,则消息将引发异常。在这里,我们的捕获异常策略可以添加带有适当消息的标头,并将该消息从流中推送到下一个队列。
选择异常策略
如果您想根据消息内容处理异常,那么选择异常策略将是最佳选择。此异常策略的工作方式如下 −
- 首先,它捕获父流中抛出的所有异常。
- 接下来,它检查消息内容和异常类型。
- 最后,它将消息路由到适当的异常策略。
在选择异常策略中会定义多个异常策略,如 Catch 或 Rollback。如果此异常策略下没有定义策略,则它将消息路由到默认异常策略。它从不执行任何提交、回滚或消费活动。
引用异常策略
这指的是在单独的配置文件中定义的常见异常策略。如果消息抛出异常,此异常策略将引用全局捕获、回滚或选择异常策略中定义的错误处理参数。与选择异常策略一样,它也从不执行任何提交、回滚或消费活动。
MuleSoft - 使用 MUnit 进行测试
我们理解单元测试是一种可以测试单个源代码单元以确定它们是否适合使用的方法。Java 程序员可以使用 Junit 框架编写测试用例。同样,MuleSoft 也有一个名为 MUnit 的框架,允许我们为我们的 API 和集成编写自动化测试用例。它非常适合持续集成/部署环境。 MUnit 框架的最大优势之一是我们可以将其与 Maven 和 Surefire 集成。
MUnit 的功能
以下是 Mule MUnit 测试框架的一些非常有用的功能 −
在 MUnit 框架中,我们可以使用 Mule 代码和 Java 代码创建我们的 Mule 测试。
我们可以在 Anypoint Studio 中以图形方式或 XML 形式设计和测试我们的 Mule 应用程序和 API。
MUnit 允许我们轻松地将测试集成到现有的 CI/CD 流程中。
它提供自动生成的测试和覆盖率报告;因此手动工作很少。
我们还可以使用本地 DB/FTP/邮件服务器,使测试在 CI 过程中更具可移植性。
它允许我们启用或禁用测试。
我们还可以使用插件扩展 MUnit 框架。
它允许我们验证消息处理器调用。
借助 MUnit 测试框架,我们可以禁用端点连接器以及流入站端点。
我们可以使用 Mule 堆栈跟踪检查错误报告。
Mule MUnit 测试框架的最新版本
MUnit 2.1.4 是 Mule MUnit 测试框架的最新版本。它需要以下硬件和软件要求 −
- MS Windows 8+
- Apple Mac OS X 10.10+
- Linux
- Java 8
- Maven 3.3.3、3.3.9、3.5.4、3.6.0
它与 Mule 4.1.4 和 Anypoint Studio 7.3.0 兼容。
MUnit 和 Anypoint Studio
如上所述,MUnit 完全集成在 Anypoint Studio 中,我们可以在 Anypoint Studio 中以图形方式或 XML 形式设计和测试我们的 Mule 应用程序和 API。换句话说,我们可以使用 Anypoint Studio 的图形界面执行以下操作 −
- 用于创建和设计 MUnit 测试
- 用于运行我们的测试
- 用于查看测试结果以及覆盖率报告
- 用于调试测试
那么,让我们开始逐一讨论每个任务。
创建和设计 MUnit 测试
一旦启动新项目,它将自动向我们的项目添加一个名为 src/test/munit 的新文件夹。例如,我们启动了一个新的 Mule 项目,即 test_munit,您可以在下图中看到,它在我们的项目下添加了上述文件夹。
现在,一旦您启动了新项目,就有两种基本方法可以在 Anypoint Studio 中创建新的 MUnit 测试 −
通过右键单击流程 − 在此方法中,我们需要右键单击特定流程并从下拉菜单中选择 MUnit。
通过使用向导 − 在此方法中,我们需要使用向导来创建测试。它允许我们为工作区中的任何流程创建测试。
我们将使用"右键单击流程"的方式为特定流程创建测试。
首先,我们需要在工作区中创建一个流程,如下所示 −
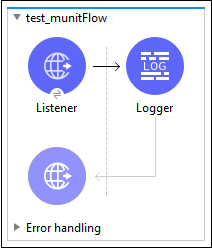
现在,右键单击此流程并选择 MUnit 为该流程创建测试,如下所示 −
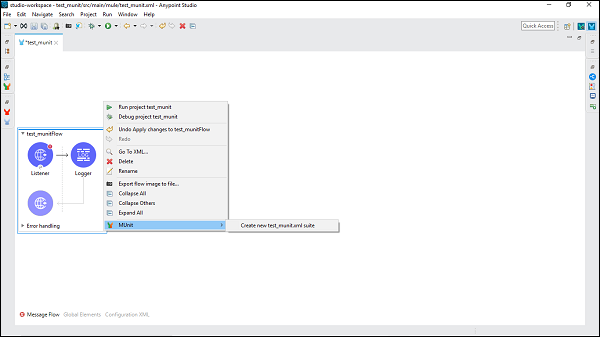
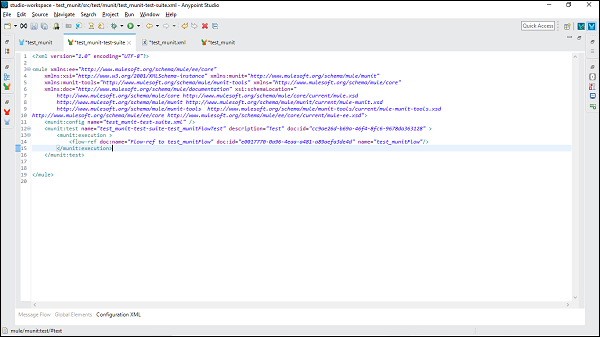
它将创建一个以流程所在的 XML 文件命名的新测试套件。在这种情况下,test_munit-test-suite 是新测试套件的名称,如下所示 −
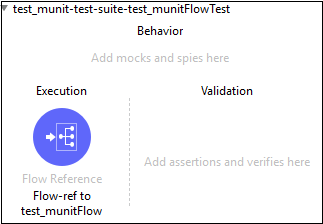
以下是上述消息流的 XML 编辑器 −
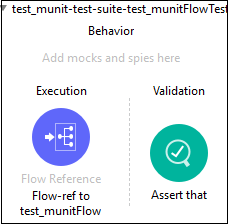
现在,我们可以将 MUnit 消息处理器从 Mule Palette 拖拽到测试套件中。
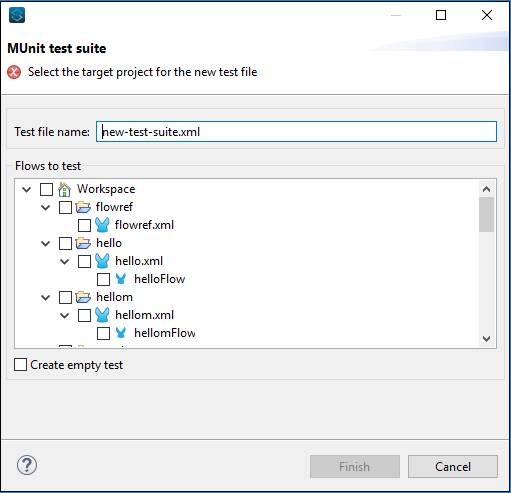
如果您想通过向导创建测试,请按照 File → New → MUnit,它将引导您进入以下 MUnit 测试套件 −
配置测试
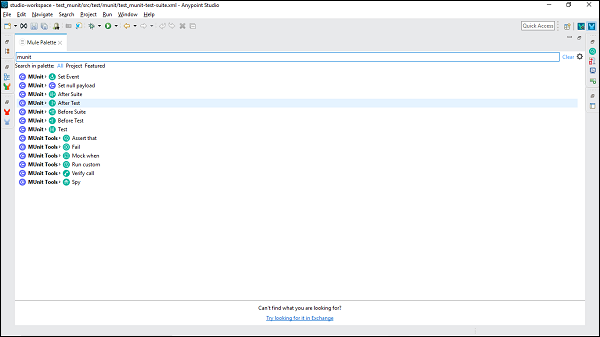
在 Mule 4 中,我们有两个新部分,即 MUnit 和 MUnit Tools,它们共同包含所有 MUnit 消息处理器。您可以将任何消息处理器拖放到 MUnit 测试区域中。它显示在下面的屏幕截图中 −
现在,如果您想在 Anypoint Studio 中编辑您的套件或测试的配置,则需要按照以下步骤 −
步骤 1
转到 Package Explorer 并右键单击您的套件或测试的 .xml 文件。然后,选择 属性。
步骤 2
现在,在属性窗口中,我们需要单击 运行/调试设置。之后单击新建。
步骤 3
最后一步,单击选择配置类型窗口下的MUnit,然后单击确定。
运行测试
我们可以运行测试套件以及测试。首先,我们将了解如何运行测试套件。
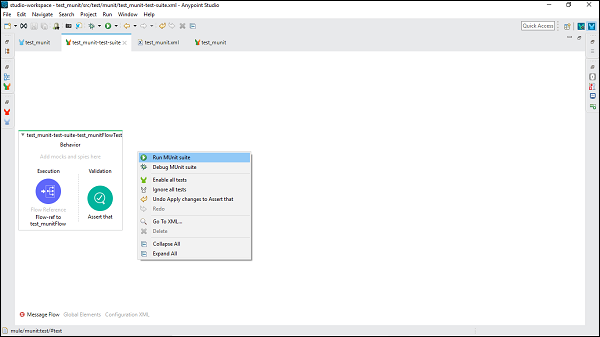
运行测试套件
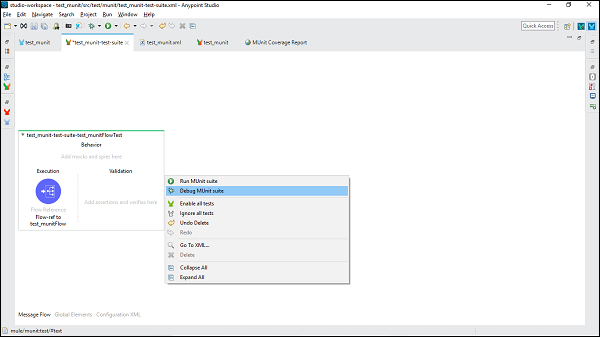
要运行测试套件,请右键单击测试套件所在的 Mule Canvas 的空白部分。它将打开一个下拉菜单。现在,单击 运行 MUnit 套件,如下所示 −
稍后,我们可以在控制台中看到输出。
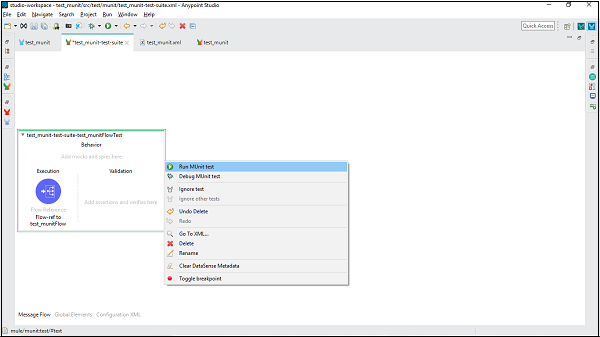
运行测试
要运行特定测试,我们需要选择特定测试并右键单击它。我们将获得与运行测试套件时相同的下拉菜单。现在,单击 Run MUnit Test 选项,如下所示 −
之后,可以在控制台中看到输出。
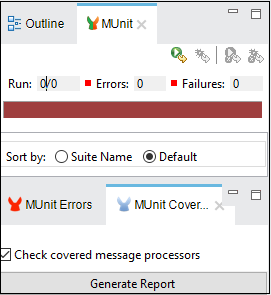
查看和分析测试结果
Anypoint Studio 在左侧资源管理器窗格的 MUnit 选项卡 中显示 MUnit 测试结果。您可以用绿色找到成功的测试,用红色找到失败的测试,如下所示 −
我们可以通过查看覆盖率报告来分析我们的测试结果。覆盖率报告的主要功能是提供一个指标,表明一组 MUnit 测试已成功执行了多少 Mule 应用程序。 MUnit 覆盖率基本上基于执行的 MUnit 消息处理器的数量。MUnit 覆盖率报告提供了以下指标 −
- 应用程序整体覆盖率
- 资源覆盖率
- 流程覆盖率
要获取覆盖率报告,我们需要单击 MUnit 选项卡下的"生成报告",如下所示 −
调试测试
我们可以调试测试套件以及测试。首先,我们将了解如何调试测试套件。
调试测试套件
要调试测试套件,请右键单击测试套件所在的 Mule Canvas 的空白部分。它将打开一个下拉菜单。现在,单击 Debug MUnit Suite,如下图所示 −
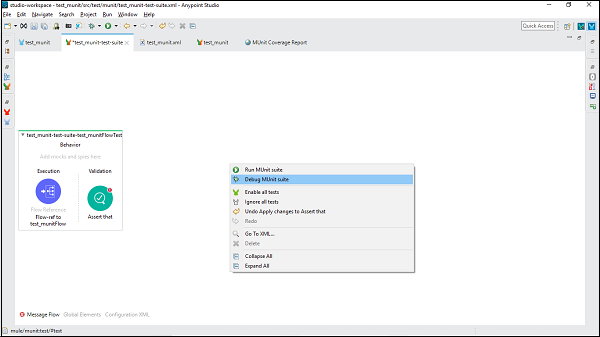
然后,我们可以在控制台中看到输出。
调试测试
要调试特定测试,我们需要选择特定测试并右键单击该测试。我们将获得与调试测试套件时相同的下拉菜单。现在,单击 Debug MUnit Test 选项。它显示在下面的屏幕截图中。