C - 快速指南
C 是一种通用的高级语言,最初由 Dennis M. Ritchie 为贝尔实验室的 UNIX 操作系统开发而开发。 C 语言最初于 1972 年在 DEC PDP-11 计算机上首次实现。
1978 年,Brian Kernighan 和 Dennis Ritchie 编写了第一份公开的 C 语言描述,现在称为 K&R 标准。
UNIX 操作系统、C 编译器以及几乎所有 UNIX 应用程序都是用 C 语言编写的。由于各种原因,C 语言现在已成为一种广泛使用的专业语言 -
- 易于学习
- 结构化语言
- 它能生成高效的程序
- 它可以处理低级活动
- 它可以在各种计算机平台上编译
关于 C 语言的事实
C 语言的发明是为了编写一个名为 UNIX 的操作系统。
C 语言是B 语言诞生于 20 世纪 70 年代初。
该语言于 1988 年由美国国家标准协会 (ANSI) 正式确定。
UNIX 操作系统完全用 C 语言编写。
如今,C 语言是最广泛使用和最流行的系统编程语言。
大多数最先进的软件都是用 C 语言实现的。
当今最流行的 Linux 操作系统和关系数据库管理系统 MySQL 都是用 C 语言编写的。
为什么使用 C 语言?
C 语言最初用于系统开发工作,尤其是组成操作系统的程序。之所以采用 C 语言作为系统开发语言,是因为它生成的代码运行速度几乎与用汇编语言编写的代码一样快。 C 语言的一些使用示例如下:-
- 操作系统
- 语言编译器
- 汇编器
- 文本编辑器
- 打印后台处理程序
- 网络驱动程序
- 现代程序
- 数据库
- 语言解释器
- 实用程序
C 程序
C 程序的长度可以从 3 行到数百万行不等,应将其写入一个或多个扩展名为 ".c"的文本文件中;例如,hello.c。您可以使用"vi"、"vim"或任何其他文本编辑器将 C 程序写入文件。
本教程假设您知道如何编辑文本文件以及如何在程序文件中编写源代码。
C - 环境设置
本地环境设置
如果您想设置 C 编程语言环境,您的计算机上需要以下两个软件工具:(a) 文本编辑器和 (b) C 编译器。
文本编辑器
这将用于编写程序。一些编辑器的示例包括 Windows 记事本、OS Edit 命令、Brief、Epsilon、EMACS 以及 vim 或 vi。
文本编辑器的名称和版本在不同的操作系统上可能有所不同。例如,Windows 系统使用记事本,而 vim 或 vi 则可用于 Windows 以及 Linux 或 UNIX 系统。
您使用编辑器创建的文件称为源文件,它们包含程序源代码。 C 程序的源文件通常以".c"为扩展名。
开始编程之前,请确保您已安装好文本编辑器,并且具备编写计算机程序、将其保存为文件、进行编译并最终执行的经验。
C 编译器
源文件中编写的源代码是程序的可读源代码。它需要被"编译"成机器语言,以便 CPU 能够按照指令实际执行程序。
编译器将源代码编译成最终的可执行程序。最常用且免费的编译器是 GNU C/C++ 编译器,或者您也可以使用 HP 或 Solaris 的编译器(如果您有相应的操作系统)。
以下部分介绍如何在各种操作系统上安装 GNU C/C++ 编译器。我们一直将 C/C++ 放在一起提及,是因为 GNU gcc 编译器适用于 C 和 C++ 编程语言。
在 UNIX/Linux 上安装
如果您使用的是 Linux 或 UNIX,请在命令行中输入以下命令,检查您的系统上是否安装了 GCC -
$ gcc -v
如果您的计算机上安装了 GNU 编译器,则它会打印如下消息 -
Using built-in specs. Target: i386-redhat-linux Configured with: ../configure --prefix=/usr ....... Thread model: posix gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
如果未安装 GCC,则需要按照 https://gcc.gnu.org/install/
上的详细说明自行安装。本教程基于 Linux 编写,所有示例均在 Cent OS Linux 系统上编译。
在 Mac OS 上安装
如果您使用的是 Mac OS X,获取 GCC 最简单的方法是从 Apple 网站下载 Xcode 开发环境,然后按照简单的安装说明进行操作。设置好 Xcode 后,您就可以使用 GNU 编译器来编译 C/C++ 了。
Xcode 目前可在 developer.apple.com/technologies/tools/ 获取。
Windows 系统安装
要在 Windows 系统上安装 GCC,您需要安装 MinGW。要安装 MinGW,请访问 MinGW 主页 www.mingw.org,然后点击链接进入 MinGW 下载页面。下载最新版本的 MinGW 安装程序,其名称应为 MinGW-<version>.exe。
安装 MinGW 时,至少必须安装 gcc-core、gcc-g++、binutils 和 MinGW 运行时,但您可能希望安装更多程序。
将 MinGW 安装目录下的 bin 子目录添加到 PATH 环境变量中,以便您可以在命令行中通过这些工具的简单名称来指定它们。
安装完成后,您将能够从 Windows 命令行运行 gcc、g++、ar、ranlib、dlltool 和其他几个 GNU 工具。
C - 程序结构
在学习 C 编程语言的基本构造块之前,让我们先看一个最基本的 C 程序结构,以便在接下来的章节中作为参考。
Hello World 示例
一个 C 程序基本上由以下部分组成 -
- 预处理器命令
- 函数
- 变量
- 语句和表达式
- 注释
让我们看一段打印"Hello World"的简单代码 -
#include <stdio.h>
int main() {
/* 我的第一个 C 语言程序 */
printf("Hello, World!
");
return 0;
}
让我们看一下上述程序的各个部分 -
程序的第一行 #include <stdio.h> 是一个预处理命令,它告诉 C 编译器在实际编译之前包含 stdio.h 文件。
下一行 int main() 是程序开始执行的主函数。
下一行 /*...*/ 将被编译器忽略,它被添加到程序中以添加额外的注释。因此,这些行在程序中被称为注释。
下一行 printf(...) 是 C 语言中的另一个函数,它会返回消息"Hello, World!"。显示在屏幕上。
下一行 return 0; 终止 main() 函数并返回值 0。
编译并执行 C 程序
让我们看看如何将源代码保存到文件中,以及如何编译和运行它。以下是简单的步骤 -
打开文本编辑器并添加上述代码。
将文件另存为 hello.c
打开命令提示符并转到保存文件的目录。
输入 gcc hello.c 并按 Enter 键编译代码。
如果代码中没有错误,命令提示符将带您到下一行并生成 a.out 可执行文件。
现在,输入 a.out 来执行您的程序。
您将看到屏幕上显示 "Hello World" 的输出。
$ gcc hello.c $ ./a.out Hello, World!
确保 gcc 编译器位于你的路径中,并且你在包含源文件 hello.c 的目录中运行它。
C - 基本语法
您已经了解了 C 程序的基本结构,因此理解 C 编程语言的其他基本构建块将非常容易。
C 中的标记
C 程序由各种标记组成,标记可以是关键字、标识符、常量、字符串文字或符号。例如,以下 C 语句由五个标记组成 -
printf("Hello, World!
");
各个标记如下 -
printf ( "Hello, World! " ) ;
分号
在 C 程序中,分号是语句终止符。也就是说,每个单独的语句都必须以分号结尾。它表示一个逻辑实体的结束。
下面给出了两个不同的语句 -
printf("Hello, World!
");
return 0;
注释
注释就像 C 程序中的帮助文本,会被编译器忽略。它们以 /* 开头,以字符 */ 结尾,如下所示 -
/* 我的第一个 C 语言程序 */
注释中不能包含注释,注释也不能出现在字符串或字符字面量中。
标识符
C 语言标识符是用于标识变量、函数或任何其他用户定义项的名称。标识符以字母 A 到 Z、a 到 z 或下划线"_"开头,后跟零个或多个字母、下划线和数字(0 到 9)。
C 语言不允许在标识符中使用标点符号,例如 @、$ 和 %。C 语言是一种区分大小写的编程语言。因此,Manpower 和 manpower 在 C 语言中是两个不同的标识符。以下是一些可接受标识符的示例 -
mohd zara abc move_name a_123 myname50 _temp j a23b9 retVal
关键字
以下列表列出了 C 语言中的保留字。这些保留字不能用作常量、变量或任何其他标识符名称。
| auto | else | long | switch |
| break | enum | register | typedef |
| case | extern | return | union |
| char | float | short | unsigned |
| const | for | signed | void |
| continue | goto | sizeof | volatile |
| default | if | static | while |
| do | int | struct | _Packed |
| double |
C 语言中的空格
仅包含空格(可能带有注释)的行称为空行,C 编译器会完全忽略它。
空格是 C 语言中用来描述空格、制表符、换行符和注释的术语。空格将语句的各个部分分隔开,并使编译器能够识别语句中一个元素(例如 int)的结束位置和下一个元素的开始位置。因此,在以下语句中 -
int age;
int 和 age 之间必须至少有一个空格字符(通常为空格),编译器才能区分它们。另一方面,在以下语句中 -
fruit = apples + oranges; // 获取水果总数
fruit 和 = 之间,以及 = 和 apples 之间不需要空格,但如果您希望提高可读性,可以随意添加一些空格。
C - 数据类型
C 语言中的数据类型是指用于声明不同类型的变量或函数的一套广泛的系统。变量的类型决定了它在存储空间中的占用空间以及如何解释存储的位模式。在本章中,我们将学习C 语言中的数据类型。一个相关的概念是"变量",它指的是处理器内存中的可寻址位置。通过不同输入设备获取的数据存储在计算机内存中。可以为存储位置分配一个符号名称,称为变量名。
C 是一种静态类型语言。在实际使用变量之前,必须明确声明变量的名称及其要存储的数据类型。
C 语言也是一种强类型语言,这意味着不允许自动或隐式地将一种数据类型转换为另一种数据类型。
C 语言中的类型可以分为以下几类:
| 序号 | 类型 &说明 |
|---|---|
| 1 | 基本类型 它们是算术类型,进一步分为:(a) 整数类型和 (b) 浮点类型。 |
| 2 | 枚举类型 它们同样是算术类型,用于定义在整个程序中只能赋值特定离散整数值的变量。 |
| 3 | void 类型 类型说明符 void 表示没有值可用。 |
| 4 | 派生类型 包括 (a) 指针类型,(b) 数组类型,(c) 结构体类型,(d) 联合类型和 (e) 函数类型。 |
数组类型和结构体类型统称为聚合类型。函数的类型指定了函数返回值的类型。我们将在下一节中介绍基本类型,其他类型将在接下来的章节中介绍。
C 语言中的整数数据类型
下表列出了标准整数类型及其存储大小和取值范围的详细信息 -
| 类型 | 存储大小 | 取值范围 |
|---|---|---|
| 字符型 | 1 字节 | -128 至 127 或 0 至 255 |
| 无符号字符型 | 1 字节 | 0 至 255 |
| 有符号字符型 | 1 字节 | -128 至 127 |
| 整数 | 2 或 4 个字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| 无符号整数 | 2 或 4 个字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| 短整型 | 2 个字节 | -32,768 到 32,767 |
| 无符号短整型 | 2字节 | 0 到 65,535 |
| 长整型 | 8 字节 | -9223372036854775808 到 9223372036854775807 |
| 无符号长整型 | 8 字节 | 0 到 18446744073709551615 |
要获取特定平台上类型或变量的确切大小,可以使用 sizeof 运算符。表达式 sizeof(type) 可得出对象或类型的存储大小(以字节为单位)。
整数数据类型示例
下面给出了一个示例,使用 limits.h 头文件中定义的不同常量来获取不同机器上各种类型的大小 -
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <float.h>
int main(int argc, char** argv) {
printf("CHAR_BIT : %d
", CHAR_BIT);
printf("CHAR_MAX : %d
", CHAR_MAX);
printf("CHAR_MIN : %d
", CHAR_MIN);
printf("INT_MAX : %d
", INT_MAX);
printf("INT_MIN : %d
", INT_MIN);
printf("LONG_MAX : %ld
", (long) LONG_MAX);
printf("LONG_MIN : %ld
", (long) LONG_MIN);
printf("SCHAR_MAX : %d
", SCHAR_MAX);
printf("SCHAR_MIN : %d
", SCHAR_MIN);
printf("SHRT_MAX : %d
", SHRT_MAX);
printf("SHRT_MIN : %d
", SHRT_MIN);
printf("UCHAR_MAX : %d
", UCHAR_MAX);
printf("UINT_MAX : %u
", (unsigned int) UINT_MAX);
printf("ULONG_MAX : %lu
", (unsigned long) ULONG_MAX);
printf("USHRT_MAX : %d
", (unsigned short) USHRT_MAX);
return 0;
}
输出
当你编译并执行上述程序时,它会在 Linux 上产生以下结果 -
CHAR_BIT : 8 CHAR_MAX : 127 CHAR_MIN : -128 INT_MAX : 2147483647 INT_MIN : -2147483648 LONG_MAX : 9223372036854775807 LONG_MIN : -9223372036854775808 SCHAR_MAX : 127 SCHAR_MIN : -128 SHRT_MAX : 32767 SHRT_MIN : -32768 UCHAR_MAX : 255 UINT_MAX : 4294967295 ULONG_MAX : 18446744073709551615 USHRT_MAX : 65535
C 语言中的浮点数据类型
下表提供了标准浮点类型的详细信息,包括存储大小、值范围及其精度 -
| 类型 | 存储大小 | 取值范围 | 精度 |
|---|---|---|---|
| 浮点型 | 4 字节 | 1.2E-38 到 3.4E+38 | 6 位小数 |
| 双精度型 | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位小数 |
| 长整型双精度型 | 10 字节 | 3.4E-4932 到 1.1E+4932 | 19 位小数 |
头文件"float.h"定义了一些宏,允许您在程序中使用这些值以及有关实数二进制表示的其他详细信息。
浮点数据类型示例
以下示例打印浮点类型占用的存储空间及其范围值 -
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <float.h>
int main(int argc, char** argv) {
printf("Storage size for float : %zu
", sizeof(float));
printf("FLT_MAX : %g
", (float) FLT_MAX);
printf("FLT_MIN : %g
", (float) FLT_MIN);
printf("-FLT_MAX : %g
", (float) -FLT_MAX);
printf("-FLT_MIN : %g
", (float) -FLT_MIN);
printf("DBL_MAX : %g
", (double) DBL_MAX);
printf("DBL_MIN : %g
", (double) DBL_MIN);
printf("-DBL_MAX : %g
", (double) -DBL_MAX);
printf("Precision value: %d
", FLT_DIG );
return 0;
}
输出
当你编译并执行上述程序时,它会在 Linux 上产生以下结果 -
Storage size for float : 4 FLT_MAX : 3.40282e+38 FLT_MIN : 1.17549e-38 -FLT_MAX : -3.40282e+38 -FLT_MIN : -1.17549e-38 DBL_MAX : 1.79769e+308 DBL_MIN : 2.22507e-308 -DBL_MAX : -1.79769e+308 Precision value: 6
注意:"sizeof"返回"size_t"。"size_t"的无符号整数类型可能因平台而异。并且,它可能并非在所有情况下都是长整型无符号整数。在这种情况下,我们使用"%zu"作为格式字符串,而不是"%d"。
早期版本的 C 语言没有布尔数据类型。 ANSI C 的 C99 标准化引入了 _bool 类型,该类型将零值视为假,将非零值视为真。
C 语言中的用户定义数据类型
有两种用户定义数据类型:struct 和 union,用户可以结合其他基本数据类型来定义它们。
结构体数据类型
C 语言独有的特性之一就是将不同类型的值存储在一个变量中。关键字 struct 和 union 用于派生用户定义数据类型。例如,
struct student {
char name[20];
int marks, age;
};
联合数据类型
联合是结构体的一种特殊情况,联合变量的大小不像结构体那样是各个元素大小的总和,而是对应于各个元素中最大的一个。因此,一次只能使用一个元素。请看以下示例:
union ab {
int a;
float b;
};
我们将在后面的章节中了解更多关于结构体和联合类型的知识。
C 语言中的 void 数据类型
void 类型指定没有可用的值。它在三种情况下使用 -
| Sr.No | 类型 &说明 |
|---|---|
| 1 |
函数返回 void C 语言中有很多函数不返回任何值,或者说它们返回 void。没有返回值的函数的返回类型为 void。例如,void exit (int status); |
| 2 |
函数参数为 void C 语言中有很多函数不接受任何参数。没有参数的函数可以接受 void。例如,int rand(void); |
| 3 |
指向 void 的指针 void * 类型的指针表示对象的地址,但不表示其类型。例如,内存分配函数 void *malloc( size_t size ); 返回一个指向 void 的指针,该指针可以转换为任何数据类型。 |
C - 变量
变量只不过是程序可以操作的存储区域的名称。C 语言中的每个变量都有特定的类型,这决定了变量内存的大小和布局;内存中可以存储的值的范围;以及可以对变量执行的操作集。
为什么在 C 语言中使用变量?
C 语言中的变量是用户为计算机内存中某个位置指定的名称,而内存是大量可随机访问的位置的集合,可以容纳单个位。内存中的每个位置都由一个唯一的地址标识,该地址以二进制(或为方便起见,以十六进制)格式表示。
由于通过二进制形式引用内存中数据的位置来存储和处理数据非常繁琐,因此像 C 语言这样的高级语言允许使用用户定义的名称或变量来标识这些位置。
您无需查找空闲的内存位置并为其赋值,而是可以找到合适的助记符标识符并为其赋值。C 编译器将选择合适的位置并将其绑定到您指定的标识符。
C 变量的命名约定
变量名称必须以字母(大写或小写)或下划线 (_) 开头。它可以由字母(大写或小写)、数字和下划线字符组成。C 语言中,变量名称不能包含其他字符。
C 语言中的变量名称区分大小写。例如,"age"与"AGE"不同。
ANSI 标准识别的变量名长度为 31 个字符。虽然您可以选择包含更多字符的名称,但只有前 31 个字符会被识别。使用描述性名称来描述变量,并反映其预期存储的值被认为是一种良好做法。避免使用可能造成混淆的过短变量名。
C 语言是静态类型语言。因此,变量的数据类型必须在其名称之前声明。变量可以在函数内部声明(局部变量),也可以在全局声明。一个语句中可以声明多个相同类型的变量。
示例
根据上述规则和约定,以下是一些有效和无效的变量名:
int _num = 5; // 有效的整数变量 float marks = 55.50; // 有效的浮点变量 char choice = '0'; // 有效的字符变量 // 无效的变量名 // 不能使用"-" int sub-1 = 35; // 无效;必须具有数据类型 avg = 50; // 无效;名称只能用于 // 在函数中声明一次 int choice = 0; // 有效的整数名称 int sal_of_employee = 20000; // 有效,因为所有变量都是相同类型 int phy, che, maths; // 错误,因为同一语句中的变量 // 类型不同 int sal, float tax;
在 C 语言中,变量可以存储其可识别的任何类型的数据。因此,变量的类型数量与 C 语言中的数据类型的数量相同。
| 序号 | 类型和描述 |
|---|---|
| 1 | char 通常为一个八位字节(一个字节)。它是整数类型。 |
| 2 | int 机器最自然的整数大小。 |
| 3 | float 单精度浮点值。 |
| 4 | double 双精度浮点值。 |
| 5 | void 表示不存在类型。 |
C 编程语言还允许定义各种其他类型的变量,例如枚举类型、指针类型、数组类型、结构体类型、联合类型等。本章仅学习基本变量类型。
C 语言中的变量定义
变量定义会告诉编译器在何处以及为变量创建多少存储空间。变量定义指定一种数据类型,并包含该类型的一个或多个变量列表,如下所示:-
type 变量列表;
其中,type 必须是有效的 C 数据类型,包括 char、w_char、int、float、double、bool 或任何用户定义的对象;variable_list 可以包含一个或多个以逗号分隔的标识符名称。
此处显示了一些有效的变量声明 -
int i, j, k; char c, ch; float f, salary; double d;
int i, j, k; 行声明并定义了变量 i、j 和 k;这指示编译器创建名为 i、j 和 k 且类型为 int 的变量。
变量可以在声明中初始化(赋予初始值)。初始化函数由一个等号后跟一个常量表达式组成,如下所示:
type Variable_name = Value;
示例:变量定义和初始化
请看以下示例:
// 声明 d 和 f extern int d = 3, f = 5; // 定义并初始化 d 和 f int d = 3, f = 5; // 定义并初始化 z byte z = 22; // 变量 x 的值为 'x' char x = 'x';
对于没有初始化器的定义:具有静态存储期的变量隐式初始化为 NULL(所有字节的值均为 0);所有其他变量的初始值均未定义。
C 语言中的变量声明
根据 ANSI C 标准,所有变量必须在开头声明。不允许在第一个处理语句之后声明变量。虽然 C99 和 C11 标准修订版已取消此规定,但这仍然被认为是一种良好的编程习惯。您可以声明一个变量,并在代码的后续部分赋值,也可以在声明时初始化它。
示例:变量声明
// 带初始化的声明 int x = 10; // 先声明后赋值 int y; y = 20; // 定义并初始化两个变量 int d = 3, f = 5; // 变量 x 的值为 'x' char x = 'x';
一旦声明了特定类型的变量,就不能再赋值给其他类型的变量。在这种情况下,C 编译器 会报告类型不匹配错误。
变量声明可以确保编译器存在具有给定类型和名称的变量,这样编译器就可以继续进行编译,而无需了解变量的完整信息。变量定义仅在编译时才有意义,编译器在链接程序时需要实际的变量定义。
当您使用多个文件,并且在链接程序时可用的其中一个文件中定义变量时,变量声明非常有用。您可以使用关键字"extern"在任何地方声明变量。虽然你可以在 C 程序中多次声明一个变量,但它在一个文件、函数或代码块中只能定义一次。
示例
尝试以下示例,其中变量在顶部声明,但在主函数内部定义和初始化 -
#include <stdio.h>
// 变量声明:
extern int a, b;
extern int c;
extern float f;
int main () {
/* 变量定义: */
int a, b;
int c;
float f;
/* 实际初始化 */
a = 10;
b = 20;
c = a + b;
printf("value of c : %d
", c);
f = 70.0/3.0;
printf("value of f : %f
", f);
return 0;
}
输出
上述代码编译执行后,结果如下:
value of c : 30 value of f : 23.333334
同样的概念也适用于函数声明,即在声明时提供函数名称,而其实际定义可以在其他任何地方给出。例如:-
// 函数声明
int func();
int main() {
// function call
int i = func();
}
// 函数定义
int func() {
return 0;
}
C 语言中的左值和右值
C 语言中有两种表达式:
- 左值表达式
- 右值表达式
C 语言中的左值表达式
引用内存位置的表达式称为"左值"表达式。左值可以出现在赋值语句的左侧或右侧。
C 语言中的变量是左值,因此它们可以出现在赋值语句的左侧。
C 语言中的右值表达式
术语"右值"是指存储在内存中某个地址的数据值。 "右值"是指不能被赋值的表达式,这意味着右值可以出现在赋值语句的右侧,但不能出现在左侧。
数字字面量是右值,因此它们不能被赋值,也不能出现在左侧。
请看以下有效和无效的语句:
// 有效语句 int g = 20; // 无效语句 // 会产生编译时错误 10 = 20;
C - 常量和字面量
常量是指程序在执行过程中无法更改的固定值。这些固定值也称为字面量。
常量可以是任何基本数据类型,例如整型常量、浮点型常量、字符型常量或字符串字面量。此外,还有枚举常量。
常量与常规变量类似,只是它们的值在定义后无法修改。
整型字面量
整型字面量可以是十进制、八进制或十六进制常量。前缀指定基数或基数:十六进制为 0x 或 0X,八进制为 0,十进制为无。
整数字面量还可以带有后缀,后缀由 U 和 L 组成,分别代表无符号和长整型。后缀可以是大写或小写,且顺序不限。
以下是一些整数字面量的示例 -
212 /* 合法 */ 215u /* 合法 */ 0xFeeL /* 合法 */ 078 /* 非法:8 不是八进制数字 */ 032UU /* 非法:后缀不能重复 */
以下是其他各种整数字面量的示例 -
85 /* 十进制 */ 0213 /* 八进制 */ 0x4b /* 十六进制 */ 30 /* 整数 */ 30u /* 无符号整数 */ 30l /* 长整型 */ 30ul /* 无符号长整型*/
浮点字面量
浮点字面量包含整数部分、小数点、小数部分和指数部分。浮点字面量可以用十进制形式或指数形式表示。
表示十进制形式时,必须包含小数点、指数或两者;表示指数形式时,必须包含整数部分、小数部分或两者。带符号的指数由 e 或 E 引入。
以下是一些浮点文字的示例 -
3.14159 /* 合法 */ 314159E-5L /* 合法 */ 510E /* 非法:指数不完整 */ 210f /* 非法:无小数或指数 */ .e55 /* 非法:缺少整数或分数 */
字符常量
字符文字用单引号括起来,例如,"x"可以存储在一个 char 类型的简单变量中。
字符文字可以是普通字符(例如,"x")、转义序列(例如," ")或通用字符(例如," '\u02C0')。
C 语言中,某些字符前面带有反斜杠时具有特殊含义,例如换行符 ( ) 或制表符 ( )。
以下示例展示了一些转义序列字符 -
#include <stdio.h>
int main() {
printf("Hello World
");
return 0;
}
当编译并执行上述代码时,它会产生以下结果 -
Hello World
字符串字面量
字符串字面量或常量用双引号""括起来。字符串包含与字符字面量类似的字符:普通字符、转义序列和通用字符。
您可以使用字符串字面量将长行拆分成多行,并使用空格分隔它们。
以下是一些字符串字面量的示例。这三种形式都是相同的字符串。
"hello, dear" "hello, \ dear" "hello, " "d" "ear"
定义常量
C 语言中定义常量有两种简单方法 -
使用 #define 预处理器。
使用 const 关键字。
#define 预处理器
以下是使用 #define 预处理器定义常量的形式 -
#define 标识符值
以下示例对此进行了详细说明 -
#include <stdio.h>
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '
'
int main() {
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE);
return 0;
}
当编译并执行上述代码时,它会产生以下结果 -
value of area : 50
const 关键字
您可以使用 const 前缀来声明特定类型的常量,如下所示 -
const type Variable = value;
以下示例对此进行了详细说明 -
#include <stdio.h>
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '
';
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE);
return 0;
}
当编译并执行上述代码时,它会产生以下结果 -
value of area : 50
请注意,用大写字母定义常量是一种良好的编程习惯。
C 语言中的存储类
C 语言存储类定义了 C 程序中变量和/或函数的作用域(可见性)和生命周期。它们位于被修饰的类型之前。
C 程序中有四种不同的存储类 -
- auto
- register
- static
- extern
auto 存储类
auto 是所有在函数或块内声明的变量的默认存储类。关键字"auto"是可选的,可用于定义局部变量。
auto 变量的作用域和生命周期位于声明它们的同一块内。
auto 存储类示例
以下代码语句演示了自动 (auto) 变量的声明 -
{
int mount;
auto int month;
}
上面的示例定义了两个属于同一存储类的变量。"auto"只能在函数内部使用,即局部变量。
寄存器存储类
寄存器存储类用于定义应存储在寄存器而非 RAM 中的局部变量。这意味着该变量的最大大小等于寄存器大小(通常为一个字),并且不能对其应用一元"&"运算符(因为它没有实际的内存位置)。
寄存器仅应用于需要快速访问的变量,例如计数器。还应注意,定义"寄存器"并不意味着该变量将存储在寄存器中。这意味着它可能存储在寄存器中,具体取决于硬件和实现限制。
寄存器存储类示例
以下代码语句演示了寄存器变量的声明 -
{
register int miles;
}
静态存储类
静态存储类指示编译器在程序的整个生命周期内保持局部变量的存在,而不是在每次进入和离开作用域时创建和销毁它。因此,将局部变量设为静态变量可以让它们在函数调用之间保持其值不变。
static 修饰符也可以应用于全局变量。这样做会将该变量的作用域限制在其声明的文件中。
在 C 语言编程中,当对全局变量使用 static 时,它会导致该成员只有一个副本被其类的所有对象共享。
静态存储类示例
以下示例演示了如何在 C 程序中使用静态存储类 -
#include <stdio.h>
/* 函数声明 */
void func(void);
static int count = 5; /* 全局变量 */
main(){
while(count--) {
func();
}
return 0;
}
/* 函数定义 */
void func(void) {
static int i = 5; /* 局部静态变量 */
i++;
printf("i is %d and count is %d
", i, count);
}
Output
当编译并执行上述代码时,它会产生以下结果 -
i is 6 and count is 4 i is 7 and count is 3 i is 8 and count is 2 i is 9 and count is 1 i is 10 and count is 0
extern 存储类
extern 存储类用于提供全局变量的引用,该变量对所有程序文件可见。使用"extern"时,变量无法初始化,但它会将变量名指向先前定义的存储位置。
如果您有多个文件,并且定义了一个全局变量或函数,并且该变量或函数也会在其他文件中使用,则将在另一个文件中使用 extern 来提供已定义变量或函数的引用。为了便于理解,extern 用于在另一个文件中声明全局变量或函数。
当两个或多个文件共享相同的全局变量或函数时,最常使用 extern 修饰符,如下所述。
extern 存储类示例
extern 存储类示例可能包含两个或多个文件。下面是一个演示在 C 语言中使用外部存储类的示例 -
第一个文件:main.c
#include <stdio.h>
int count;
extern void write_extern();
main(){
count = 5;
write_extern();
}
第二个文件:support.c
#include <stdio.h>
extern int count;
void write_extern(void) {
printf("Count is %d
", count);
}
此处,extern 在第二个文件中用于声明 count,而它在第一个文件 (main.c) 中有定义。现在,按如下方式编译这两个文件 -
$gcc main.c support.c
它将生成可执行程序 a.out。执行此程序时,将产生以下输出 -
count is 5
存储类的使用
存储类用于定义变量的作用域、可见性、生存期和初始(默认)值。
存储类摘要
下表概述了不同存储类的变量的作用域、默认值和生存期 -
| 存储类 | 名称 | 内存 | 作用域、默认值 | 生存期 |
|---|---|---|---|---|
| auto | Automatic | Internal Memory | 局部作用域,垃圾值 | 在声明它们的同一函数或块内。 |
| register | Register | Register | 局部作用域,0 | 在声明它们的同一函数或块内。 |
| static | Static | Internal Memory | 局部作用域,0 | 在程序内,即程序运行期间。 |
| extern | External | Internal Memory | 全局范围,0 | 在程序内部,即程序运行期间。 |
C - 运算符
运算符是指示编译器执行特定数学或逻辑函数的符号。根据定义,运算符对操作数执行特定的运算。运算符需要一个或多个操作数才能执行该运算。
根据执行运算所需的操作数数量,操作数被称为一元运算符、二元运算符或三元运算符。它们分别需要一个、两个或三个操作数。
一元运算符 − ++(递增)、--(递减)、!(非)、~(补码)、& (地址), * (解引用)
二元运算符 − 除 ! 之外的算术、逻辑和关系运算符
三元运算符 − ? 运算符
C 语言拥有丰富的内置运算符,并提供以下类型的运算符 −
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其他运算符
本章将探讨每个运算符的工作方式。您将在此获得所有章节的概述。此后,我们为每个运算符都提供了独立的章节,其中包含大量示例,以展示这些运算符在 C 编程 中的工作原理。
算术运算符
我们最熟悉的是算术运算符。这些运算符用于对操作数执行算术运算。最常见的算术运算符是加法 (+)、减法 (-)、乘法 (*) 和除法 (/)。
此外,模 (%) 是一个重要的算术运算符,用于计算除法运算的余数。算术运算符用于构成算术表达式。这些运算符本质上是二进制的,因为它们需要两个操作数,并且它们对数字操作数进行操作,这些操作数可以是数字文字、变量或表达式。
例如,看一下这个简单的表达式 −
a + b
这里的"+"是算术运算符。我们将在后续章节中学习更多关于 C 语言中算术运算符的知识。
下表列出了 C 语言支持的所有算术运算符。假设变量 A 为 10,变量 B 为 20,则 −
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 将两个操作数相加。 | A + B = 30 |
| − | 用第一个操作数减去第二个操作数。 | A − B = -10 |
| * | 将两个操作数相乘。 | A * B = 200 |
| / | 用分子除以反分子。 | B / A = 2 |
| % | 模运算符,用于计算整数除法后的余数。 | B % A = 0 |
| ++ | 自增运算符,将整数值加一。 | A++ = 11 |
| -- | 自减运算符,将整数值减一。 | A-- = 9 |
关系运算符
我们在学习中学数学时也熟悉关系运算符。这些运算符用于比较两个操作数并返回布尔值(true 或 false)。它们用于布尔表达式中。
最常见的关系运算符是小于 (<)、大于 (>)、小于等于 (<=)、大于等于 (>=)、等于 (==) 和不等于 (!=)。关系运算符也是二元运算符,需要两个数字操作数。
例如,在布尔表达式中 -
a > b
这里,">"是关系运算符。
我们将在后续章节中学习更多关于关系运算符及其用法的知识。
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等。如果相等,则条件成立。 | (A == B) 不成立。 |
| != | 检查两个操作数的值是否相等。如果不相等,则条件成立。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值。如果是,则条件成立。 | (A > B) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值。如果是,则条件成立。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值。如果是,则条件成立。 | (A >= B) 不为真。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值。如果是,则条件成立。 | (A <= B) 为真。 |
逻辑运算符
这些运算符用于组合两个或多个布尔表达式。我们可以通过将布尔表达式与这些运算符组合来构成复合布尔表达式。逻辑运算符的示例如下:
a >= 50 && b >= 50
最常见的逻辑运算符是与 (&&)、或 (||) 和非 (!)。逻辑运算符也是二元运算符。
| 运算符 | 描述 | 示例 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都不为零,则条件为真。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有一个非零,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。它用于反转其操作数的逻辑状态。如果条件为真,则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
我们将在后续章节中详细讨论 C 语言中的逻辑运算符。
位运算符
位运算符可用于操作存储在计算机内存中的数据。这些运算符用于对操作数执行位级运算。
最常见的位运算符是与 (&)、或 (|)、异或 (^)、非 (~)、左移 (<<) 和右移 (>>)。其中"~"运算符是一元运算符,而其他大多数位运算符本质上是二元运算符。
位运算符作用于位,并执行逐位运算。 &、"|" 和 "^" 的真值表如下 -
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假设二进制格式的 A = 60 和 B = 13,则它们将如下所示 -
A = 0011 1100
B = 0000 1101
------------------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
下表列出了 C 语言支持的位运算符。假设变量"A"为 60,变量"B"为 13,则 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| & | 二进制与运算符如果两个操作数中都存在一位,则将一位复制到结果中。 | (A & B) = 12,即 0000 1100 |
| | | 二进制或运算符复制一个位(如果该位存在于任一操作数中)。 | (A | B) = 61,即 0011 1101 |
| ^ | 二进制异或运算符复制一个位(如果该位在一个操作数中被设置,但不是同时存在于两个操作数中)。 | (A ^ B) = 49,即 0011 0001 |
| ~ | 二进制二进制补码运算符是一元运算符,具有"翻转"位的效果。 | (~A ) = ~(60),即 -0111101 |
| << | 二进制左移运算符。左侧操作数的值按右侧操作数指定的位数向左移动。 | A << 2 = 240,即 1111 0000 |
| >> | 二进制右移运算符。左侧操作数的值按右侧操作数指定的位数向右移动。 | A >> 2 = 15,即 0000 1111 |
赋值运算符
顾名思义,赋值运算符在 C 语言中将值"赋值"或设置为一个命名变量。这些运算符用于为变量赋值。"="符号在 C 语言中被定义为赋值运算符,但不要将其与数学中的用法混淆。
下表列出了 C 语言支持的赋值运算符 -
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 简单赋值运算符。将右侧操作数的值赋给左侧操作数 | C = A + B 将把 A + B 的值赋给 C |
| += | 加法与赋值运算符。它将右侧操作数与左侧操作数相加,并将结果赋给左侧操作数。 | C += A 等同于 C = C + A |
| -= | 减法与赋值运算符。它从左操作数中减去右操作数,并将结果赋值给左操作数。 | C -= A 等同于 C = C - A |
| *= | 乘法与赋值运算符。它将右操作数与左操作数相乘,并将结果赋值给左操作数。 | C *= A 等同于 C = C * A |
| /= | 除法与赋值运算符。它将左操作数除以右操作数,并将结果赋值给左操作数。 | C /= A 等同于 C = C / A |
| %= | 模与赋值运算符。它使用两个操作数取模,并将结果赋值给左操作数。 | C %= A 等同于 C = C % A |
| <<= | 左移与赋值运算符。 | C <<= 2 等同于 C = C << 2 |
| >>= | 右移与赋值运算符。 | C >>= 2 与 C = C >> 2 相同 |
| &= | 按位与赋值运算符。 | C &= 2 与 C = C & 相同2 |
| ^= | 按位异或赋值运算符。 | C ^= 2 与 C = C ^ 2 相同 |
| |= | 按位异或赋值运算符。 | C |= 2 与 C = C | 2 相同 |
因此,表达式"a = 5"将 5 赋值给变量"a",但"5 = a"在 C 语言中是无效表达式。
"="运算符与其他算术运算符、关系运算符和位运算符组合构成增强赋值运算符。例如,+= 运算符用作加法和赋值运算符。最常见的赋值运算符是 =、+=、-=、*=、/=、%=、&=、|= 和 ^=。
其他运算符 ↦ sizeof & 三元运算符
除了上面讨论的运算符之外,还有一些其他重要的运算符,包括 sizeof 和 ? : C 语言支持。
| 运算符 | 描述 | 示例 |
|---|---|---|
| sizeof() | 返回变量的大小。 | sizeof(a),其中 a 为整数,将返回 4。 |
| & | 返回变量的地址变量。 | &a; 返回变量的实际地址。 |
| * | 指向变量的指针。 | *a; |
| ? : | 条件表达式。 | 如果条件为真?则值为 X :否则值为 Y |
C 语言中的运算符优先级
运算符优先级决定了表达式中项的分组,并决定了表达式的求值方式。某些运算符的优先级高于其他运算符;例如,乘法运算符的优先级高于加法运算符。
例如,x = 7 + 3 * 2;这里,x 被赋值为 13,而不是 20,因为运算符 * 的优先级高于 +,所以它先与 3*2 相乘,然后再与 7 相加。
此处,优先级最高的运算符显示在表格顶部,优先级最低的运算符显示在表格底部。在表达式中,优先级较高的运算符将首先被求值。
| 类别 | 运算符 | 结合律 |
|---|---|---|
| 后缀 | () [] -> . ++ - - | 从左到右 |
| 一元运算符 | + - ! ~ ++ - - (type)* & sizeof | 从右到左 |
| 乘法 | * / % | 从左到右 |
| 加法 | + - | 从左到右 |
| 移位 | << >> | 从左到右 |
| 关系 | < <= > >= | 从左到右 |
| 相等 | == != | 从左到右 |
| 按位与 | & | 从左到右 |
| 按位异或 | ^ | 从左到右 |
| 按位或 | | | 从左到右 |
| 逻辑与 | && | 从左到右 |
| 逻辑或 | || | 从左到右 |
| 条件 | ?: | 从右到左 |
| 赋值 | = += -= *= /= %=>>= <<= &= ^= |= | 从右到左 |
| 逗号 | , | 左向右 |
C 语言中的其他运算符
除上述运算符外,C 语言中还有一些其他运算符未归入上述任何类别。例如,自增和自减运算符(++ 和 --)本质上是一元运算符,可以作为操作数的前缀或后缀。
用于处理内存位置地址的运算符,例如寻址运算符 (&) 和解引用运算符 (*)。sizeof 运算符 (sizeof) 看起来像一个关键字,但实际上是一个运算符。
C 语言还具有类型转换运算符 (()),用于强制更改操作数的类型。 C 语言在处理派生数据类型(例如struct和union)时,也使用点 (.) 和箭头 (->) 符号作为运算符。
C 语言的 C99 版本引入了一些附加运算符,例如 auto、decltype。
C 语言中的单个表达式可能包含多个不同类型的运算符。C 编译器会根据运算符的优先级和结合性来计算其值。例如,在以下表达式中 -
a + b * c
乘法操作数优先于加法运算符。
我们将在后续章节中通过示例理解这些属性。
许多其他编程语言,称为 C 系列语言(例如 C++、C#、Java、Perl 和 PHP),其运算符命名法与 C 语言类似。
C - 决策语句
包括 C 语言在内的每种编程语言都包含决策语句来支持条件逻辑。C 语言提供了多种在代码中添加决策的替代方案。
任何进程都是三种逻辑的组合 -
- 顺序逻辑
- 决策或分支
- 重复或迭代
计算机程序本质上是顺序的,默认情况下从上到下运行。C 语言中的决策语句提供了另一种执行方式。您可以要求重复执行一组语句,直到满足某个条件为止。
决策结构根据条件控制程序流程。它们是设计复杂算法的重要工具。
在 C 语言程序的决策语句中,我们使用以下关键字和运算符:if、else、switch、case、default、goto、?: 运算符、break 和 continue 语句。
在编程中,我们会遇到需要做出决策的情况。基于这些决策,我们决定下一步该做什么。在算法中也会出现类似的情况,我们需要做出一些决策,并基于这些决策执行下一个代码块。
下一条指令取决于布尔表达式,无论条件是 True 还是 False。 C 编程语言将任何非零和非空值假定为 True,如果为零或空,则假定为 False。
C 编程语言提供以下类型的决策语句。
| Sr.No. | 声明 &说明 |
|---|---|
| 1 | if 语句 if 语句由一个布尔表达式后跟一个或多个语句组成。 |
| 2 | if...else 语句 if 语句后可以跟一个可选的 else 语句,该语句在布尔表达式为 false 时执行。 |
| 3 | 嵌套 if 语句 您可以在一个 if 或 else-if 语句中嵌套另一个 if 或else-if 语句。 |
| 4 | switch 语句 switch 语句允许测试变量是否与值列表相等。 |
| 5 | 嵌套 switch 语句 您可以在一个 switch 语句中使用另一个 switch 语句。 |
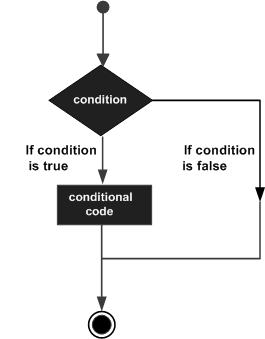
C 语言编程中的 If 语句
if 语句 用于根据结果 True 或 False 在两条路径之间做出判断。它由以下流程图表示 -
语法
if (Boolean expr){
expression;
. . .
}
if 语句由一个布尔表达式后跟一个或多个语句组成。
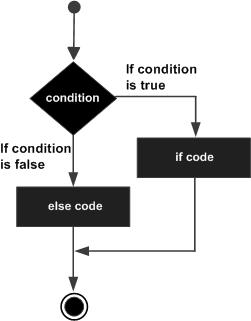
C 语言编程中的 If...else 语句
ifelse 语句 在条件不满足时提供替代路径。
语法
if (Boolean expr){
expression;
. . .
}
else{
expression;
. . .
}
if 语句后可以跟可选的 else 语句,当布尔表达式为 false 时执行该语句。
C 语言编程中的嵌套 If 语句
嵌套 if 语句 用于构建复杂的决策树,通过评估多个嵌套条件来实现细致的程序流程。
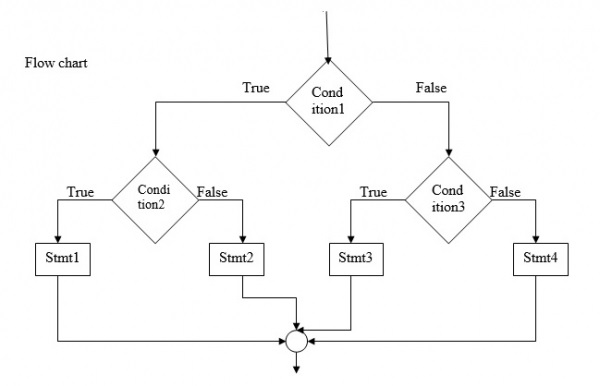
您可以将一个 if 或 else-if 语句嵌套在另一个 if 或 else-if 语句中。
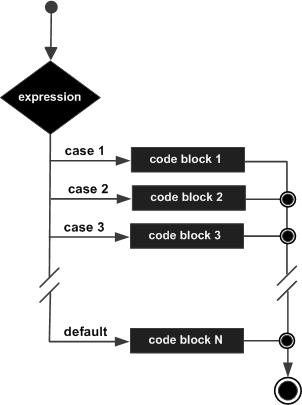
C 语言编程中的 Switch 语句
A switch 语句通过对单个变量进行多个值匹配,并根据匹配结果执行特定代码,从而简化了多路选择。它允许测试变量与一系列值是否相等。
语法
switch(expression) {
case constant-expression :
statement(s);
break; /* optional */
case constant-expression :
statement(s);
break; /* optional */
/* 你可以有任意数量的 case 语句 */
default : /* Optional */
statement(s);
}
与 if 语句一样,您可以在一个 switch 语句中使用另一个 switch 语句。
C 语言编程中的 ?: 运算符
我们在上一章中介绍了 条件运算符 (?:),它可用于替换 if-else 语句。它将 if-else 语句压缩为单个表达式,从而提供紧凑且可读的代码。
它的一般形式如下:
Exp1 ? Exp2 : Exp3;
其中 Exp1、Exp2 和 Exp3 是表达式。注意冒号 (:) 的使用和位置。"?"表达式的值确定如下 -
Exp1 会被求值。如果它为真,则 Exp2 会被求值,并成为整个 ? 表达式 的值。
如果 Exp1 为假,则 Exp3 会被求值,其值将成为 : 表达式 的值。
您可以使用 ? 运算符模拟嵌套的 if 语句。您可以在现有 ? 运算符的 true 和/或 false 操作数中使用其他三元运算符。
算法也可以包含迭代逻辑。在 C 语言中,while、dowhile 和 for 语句用于形成循环。
while 和 dowhile 形成的循环是条件循环,而 for 语句 形成的循环是计数循环。
循环也由布尔表达式控制。 C 编译器会根据条件决定是否重复执行循环块。
循环中的程序流程也由不同的跳转语句控制。break 和 continue 关键字可终止循环或执行下一次迭代。
C 语言编程中的 Break 语句
在 C 语言中,break 语句 不仅用于循环,也用于 switchcase 语句中。在循环中使用时,它会放弃重复操作。
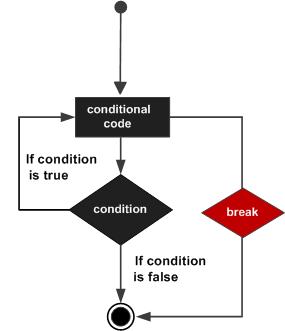
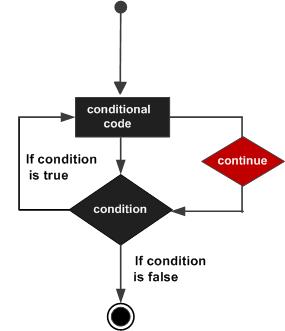
C 语言编程中的 Continue 语句
在 C 语言中,continue 语句 会执行循环的条件测试和递增部分。
C 语言编程中的 goto 语句
C 语言中也有一个 goto 关键字。您可以将程序流重定向到程序中任何带标签的指令。
以下是 C 语言中 goto 语句的语法 -
goto label; .. . label: statement;
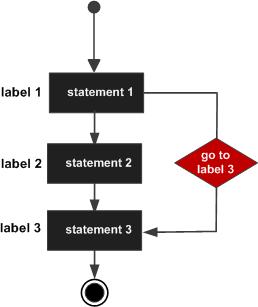
使用 goto 语句,可以将流程定向到任意上一步或后续步骤。
C - 循环
循环是一种编程结构,表示由一个或多个语句组成的程序块,这些语句会重复执行指定的次数,或直到达到某个条件为止。
重复性任务在编程中很常见,而循环对于节省时间和减少错误至关重要。在C 语言编程中,提供了关键字 while、dowhile 和 for 来实现循环。
循环结构是任何处理逻辑的重要组成部分,因为它们有助于反复执行相同的过程。C 语言程序员应该熟悉循环结构的实现和控制。
编程语言提供了各种控制结构,允许更复杂的执行路径。循环语句允许我们多次执行一个或一组语句。
C 循环语句流程图
下面给出了适用于任何编程语言的循环语句的通用流程图 -
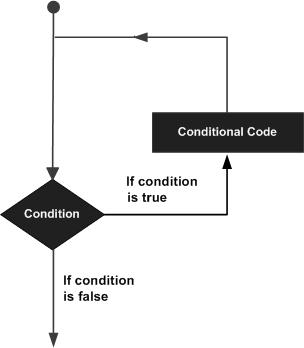
C 程序中的语句始终以自上而下的方式执行。如果我们要求编译器返回到之前的任何步骤,则构成一个循环。
示例:C 中的循环
为了理解程序中循环的必要性,请考虑以下代码片段 -
#include <stdio.h>
int main (){
// 局部变量定义
int a = 1;
printf("a: %d
", a);
a++;
printf("a: %d
", a);
a++;
printf("a: %d
", a);
a++;
printf("a: %d
", a);
a++;
printf("a: %d
", a);
return 0;
}
输出
运行此代码后,您将获得以下输出 -
a: 1 a: 2 a: 3 a: 4 a: 5
该程序打印"a"的值,并将其值递增。这两个步骤重复多次。如果您需要将"a"的值从 1 打印到 100,则无需在代码中手动重复这些步骤。我们可以让编译器重复执行打印和递增这两个步骤,直到达到 100。
示例:在 C 语言中使用 While 循环
您可以使用 for、while 或 do-while 结构来重复循环。以下程序展示了如何使用 C 语言中的"while"循环打印 100 个"a"的值 -
#include <stdio.h>
int main () {
// 局部变量定义
int a = 1;
while (a <= 100){
printf("a: %d
", a);
a++;
}
return 0;
}
输出
运行此代码并检查输出 -
a: 1 a: 2 a: 3 a: 4 ..... ..... a: 98 a: 99 a: 100
如果某个步骤基于任何条件将程序流重定向到任何先前的步骤,则该循环为条件循环。一旦控制条件变为假,重复将立即停止。如果重定向没有任何条件,则为无限循环,因为代码块会永远重复执行。
C 循环的组成部分
要构成循环,以下元素是必需的 -
- 循环语句(while、dowhile 或 for)
- 循环块
- 循环条件
循环通常有两种类型 -
C 语言中的计数循环
如果循环被设计为重复一定次数,则它为计数循环。在 C 语言中,for 循环就是计数循环的一个例子。
C 语言中的条件循环
如果循环被设计为重复执行直到条件成立,则它就是条件循环。while 和 dowhile 结构可帮助您构建条件循环。
C 语言中的循环语句
C 语言编程提供了以下类型的循环来处理循环需求 -
| 序号 | 循环类型和说明 |
|---|---|
| 1 |
当给定条件为真时,重复执行一个语句或一组语句。它在执行循环体之前测试条件。 |
| 2 |
多次执行一系列语句,并简化管理循环变量的代码。 |
| 3 |
它更像是一个 while 语句,只不过它在循环体的末尾测试条件。 |
| 4 |
您可以在任何其他 while、for 或 do-while 循环中使用一个或多个循环。 |
上述每种循环类型都必须根据具体情况选择合适的循环。我们将在后续章节中详细学习这些循环类型。
C 语言中的循环控制语句
循环控制语句会改变程序的正常执行顺序。当执行离开某个作用域时,所有在该作用域内创建的自动对象都将被销毁。
C 支持以下控制语句 −
| Sr.No. | 控制语句 &说明 |
|---|---|
| 1 |
终止 循环 或 switch 语句,并将执行转移到紧接着循环或 switch 语句的语句。 |
| 2 |
使循环跳过其主体的剩余部分,并在重新迭代之前立即重新测试其条件。 |
| 3 |
将控制权转移到带标签的语句。 |
break 和 continue 语句的作用截然不同。如果 goto 语句使程序跳转到后面的语句,则它充当跳转语句。如果 goto 语句将程序重定向到前面的语句,则它形成一个循环。
C 语言中的无限循环
如果条件永不为假,则循环变为无限循环。无限循环是指由于没有终止条件、终止条件永远不满足或循环被指示从头开始而无限重复的循环。
虽然程序员有可能故意使用无限循环,但这通常是新手程序员常犯的错误。
示例:C 语言中的无限循环
for 循环传统上用于创建无限循环。由于构成"for"循环的三个表达式都不是必需的,因此可以通过将条件表达式留空来创建无限循环。
#include <stdio.h>
int main (){
for( ; ; ){
printf("This loop will run forever.
");
}
return 0;
}
输出
通过运行此代码,您将获得一个无限循环,该循环将永远打印同一行。
This loop will run forever. This loop will run forever. ........ ........ This loop will run forever.
当条件表达式不存在时,假定其为真。您可能有一个初始化和增量表达式,但 C 程序员更常用 for(;;) 结构来表示无限循环。
注意 − 您可以通过按"Ctrl + C"键来终止无限循环。
C 语言中的函数
C 语言中的函数是一段可复用的代码块,用于执行单一相关的操作。每个 C 语言程序至少包含一个函数,即 main(),所有最简单的程序都可以定义其他函数。
当某个问题的算法涉及冗长复杂的逻辑时,它会被分解成更小、独立且可复用的代码块。这些小代码块在不同的编程语言中有不同的名称,例如 模块、子例程、函数 或 方法。
您可以将代码拆分成多个独立的函数。如何在不同的函数之间划分代码由您决定,但从逻辑上讲,这种划分应该确保每个函数执行特定的任务。
函数声明会告知编译器函数的名称、返回类型和参数。函数定义提供了函数的实际主体。
C 标准库提供了许多可供程序调用的内置函数。例如,strcat() 用于连接两个字符串,memcpy() 用于将一个内存位置复制到另一个位置,以及许多其他函数。
C 语言中的模块化编程
函数旨在执行作为整个过程一部分的特定任务。这种软件开发方法称为模块化编程。
模块化编程采用自上而下的软件开发方法。编程解决方案有一个主例程,通过该主例程可以调用较小的独立模块(函数)。
每个函数都是一个独立、完整且可重用的软件组件。函数被调用时,会执行指定的任务,并将控制权返回给调用例程,并可选地返回其处理结果。
这种方法的主要优点是代码易于理解、开发和维护。
C 语言中的库函数
C 语言提供了许多库函数,包含在不同的头文件中。例如,stdio.h 头文件包含 printf() 和 scanf() 函数。同样,math.h 头文件包含许多函数,例如 sin()、pow()、sqrt() 等等。
这些函数执行预定义的任务,可以根据需要在任何程序中调用。但是,如果您找不到合适的库函数来满足您的目的,您可以定义一个。
在 C 语言中定义函数
在 C 语言中,任何函数都需要提供原型的前向声明。库函数的原型位于相应的头文件中。
对于用户定义的函数,其原型位于当前程序中。函数的定义和原型声明应该匹配。
函数中的所有语句执行完成后,程序流程返回到调用环境。函数可能会随流程控制一起返回一些数据。
C 语言中的函数声明
函数声明会告知编译器函数名称以及如何调用该函数。函数的实际主体可以单独定义。
函数声明包含以下部分 -
返回类型 函数名(参数列表);
对于上面定义的函数 max(),函数声明如下 -
int max(int num1, int num2);
函数声明中参数名称并不重要,只需要其类型,因此以下声明也是有效的 -
int max(int, int);
当您在一个源文件中定义一个函数并在另一个文件中调用该函数时,需要进行函数声明。在这种情况下,您应该在调用该函数的文件顶部声明该函数。
C 语言中函数的组成部分
C 编程语言中函数定义的一般形式如下 -
return_type function_name(parameter list){
body of the function
}
C 语言中的函数定义由函数头和函数体组成。以下是函数的所有组成部分 -
- 返回类型 - 函数可以返回一个值。return_type 是函数返回值的数据类型。某些函数执行所需的操作而不返回值。在这种情况下,return_type 是关键字 void。
- 函数名称 - 这是函数的实际名称。函数名称和参数列表共同构成了函数签名。
- 参数列表 - 参数(也称为参数)就像一个占位符。调用函数时,您将一个值作为参数传递。该值称为实际参数或实参。参数列表指的是函数参数的类型、顺序和数量。参数是可选的;也就是说,函数可以不包含任何参数。
- 函数体 − 函数体包含一组定义函数功能的语句。
C 语言中的函数应该具有返回类型。函数返回的变量类型必须是函数的返回类型。在上图中,add() 函数返回 int 类型。
示例:C 语言中的用户定义函数
在此程序中,我们使用了一个名为 max() 的用户定义函数。该函数接受两个参数 num1 和 num2,并返回两者之间的最大值 −
#include <stdio.h>
/* 返回两个数字之间最大值的函数 */
int max(int num1, int num2){
/*局部变量声明*/
int result;
if(num1 > num2)
result = num1;
else
result = num2;
return result;
}
int main(){
printf("Comparing two numbers using max() function:
");
printf("Which of the two, 75 or 57, is greater than the other?
");
printf("The answer is: %d", max(75, 57));
return 0;
}
输出
运行此代码时,它将产生以下输出 -
Comparing two numbers using max() function: Which of the two, 75 or 57, is greater than the other? The answer is: 75
在 C 语言中调用函数
创建 C 函数时,需要定义该函数的功能。要使用函数,必须调用该函数来执行定义的任务。
要正确调用函数,需要遵循函数原型的声明。如果函数定义为接收一组参数,则必须传递相同数量和类型的参数。
当函数定义时带有参数,函数名称前面的参数称为形式参数。当函数被调用时,传递给它的参数称为实际参数。
当程序调用函数时,程序控制权将转移到被调用函数。被调用函数执行定义的任务,当执行其 return 语句或到达函数结束括号时,程序控制权将返回给主程序。
示例:调用函数
要调用函数,您只需传递所需的参数以及函数名称。如果函数返回值,则可以存储返回值。请看以下示例 -
#include <stdio.h>
/* 函数声明 */
int max(int num1, int num2);
int main (){
/* 局部变量定义 */
int a = 100;
int b = 200;
int ret;
/* 调用函数获取最大值 */
ret = max(a, b);
printf( "Max value is : %d
", ret );
return 0;
}
/* 函数返回两个数字之间的最大值 */
int max(int num1, int num2){
/*局部变量声明*/
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
输出
我们将 max() 与 main() 函数一起保留,并编译了源代码。运行最终的可执行文件时,将产生以下结果 -
Max value is :200
C 语言中的 main() 函数
C 程序是一个或多个函数的集合,但其中一个函数必须命名为 main(),它是程序执行的入口点。
在 main() 函数内部,调用其他函数。main() 函数可以调用库函数,例如 printf(),其原型从头文件 (stdio.h) 中获取,也可以调用代码中存在的任何其他用户定义函数。
在 C 语言中,程序的定义顺序并不重要。在程序中,无论 main() 函数是否是第一个函数,它都是程序的入口点。
注意:在 C 语言中,任何函数都可以调用其他函数,调用次数不限。函数也可以调用自身。这种自调用函数称为递归函数。
函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量被称为函数的形式参数。
形式参数的行为类似于函数内的其他局部变量,在函数进入时创建,在函数退出时销毁。
调用函数时,有两种方式将参数传递给函数 -
| 序号 | 调用类型和说明 |
|---|---|
| 1 | 按值调用
此方法将参数的实际值复制到函数的形式参数中。在这种情况下,对函数内部形参的更改不会影响实际参数。 |
| 2 | 通过引用调用
此方法将实参的地址复制到形式参数中。在函数内部,该地址用于访问调用中使用的实际实参。这意味着对形参的更改会影响实际参数。 |
默认情况下,C 使用通过值调用来传递实参。通常,这意味着函数内的代码无法更改用于调用函数的实参。
C - 作用域规则
任何编程中的作用域都是程序中的一个区域,定义的变量可以存在于该区域内,并且超出该区域的范围则无法访问该变量。在 C 编程语言中,变量可以在三个地方声明 -
函数或代码块内部声明的变量称为局部变量。
所有函数外部声明的变量称为全局变量。
在函数参数的定义中声明的变量称为形式参数。
让我们了解一下什么是局部变量、全局变量,以及形式参数。
局部变量
在函数或代码块内部声明的变量称为局部变量。它们只能在该函数或代码块内的语句中使用。局部变量不为自身函数以外的函数所知。
示例
以下示例展示了如何使用局部变量。这里,所有变量 a、b 和 c 都是 main() 函数 的局部变量。
#include <stdio.h>
int main () {
/*局部变量声明*/
int a, b;
int c;
/* 实际初始化 */
a = 10;
b = 20;
c = a + b;
printf ("value of a = %d, b = %d and c = %d
", a, b, c);
return 0;
}
全局变量
全局变量在函数外部定义,通常位于程序顶部。全局变量的值在程序的整个生命周期内保持不变,并且可以在程序定义的任何函数内部访问它们。
全局变量可以被任何函数访问。也就是说,全局变量在声明后,可在整个程序中使用。
示例
以下程序展示了如何在程序中使用全局变量。
#include <stdio.h>
/* 全局变量声明 */
int g;
int main () {
/*局部变量声明*/
int a, b;
/* 实际初始化 */
a = 10;
b = 20;
g = a + b;
printf ("value of a = %d, b = %d and g = %d
", a, b, g);
return 0;
}
程序中的局部变量和全局变量可以同名,但函数内部局部变量的值优先。以下是示例 -
示例
#include <stdio.h>
/* 全局变量声明 */
int g = 20;
int main () {
/*局部变量声明*/
int g = 10;
printf ("value of g = %d
", g);
return 0;
}
当编译并执行上述代码时,它会产生以下结果 -
value of g = 10
形式参数
形式参数在函数内被视为局部变量,其优先级高于全局变量。以下是示例:
示例
#include <stdio.h>
/* 全局变量声明 */
int a = 20;
int main () {
/* 主函数中的局部变量声明 */
int a = 10;
int b = 20;
int c = 0;
printf ("value of a in main() = %d
", a);
c = sum( a, b);
printf ("value of c in main() = %d
", c);
return 0;
}
/* 函数将两个整数相加 */
int sum(int a, int b) {
printf ("value of a in sum() = %d
", a);
printf ("value of b in sum() = %d
", b);
return a + b;
}
当编译并执行上述代码时,它会产生以下结果 -
value of a in main() = 10 value of a in sum() = 10 value of b in sum() = 20 value of c in main() = 30
初始化局部变量和全局变量
定义局部变量时,系统不会初始化它,您必须自行初始化。全局变量在您定义时会由系统自动初始化,如下所示:
| 数据类型 | 初始默认值 |
|---|---|
| int | 0 |
| char | '\0' |
| float | 0 |
| double | 0 |
| pointer | NULL |
正确初始化变量是一种很好的编程习惯,否则您的程序可能会产生意外的结果,因为未初始化的变量将占用其内存位置上已经存在的一些垃圾值。
C 语言中的数组
C 语言中的数组是一种数据结构,可以存储相同数据类型元素的固定大小顺序集合。数组用于存储数据集合,但通常将数组视为相同类型变量的集合更为实用。
什么是 C 语言中的数组?
C 语言中的数组是数据类型相似的数据项的集合。数组中可以存储一个或多个相同数据类型的值,这些值可以是基本数据类型(int、float、char),也可以是用户定义的类型,例如结构体或指针。在 C 语言中,数组中元素的类型应与数组本身的数据类型匹配。
数组的大小(也称为数组长度)必须在声明时指定。 C 数组一旦声明,其大小就无法更改。声明数组时,编译器会分配一段连续的内存块,用于存储声明数量的元素。
为什么在 C 语言中使用数组?
数组用于存储和操作相似类型的数据。
假设我们要存储 10 个学生的成绩并计算平均分。我们声明 10 个不同的变量来存储 10 个不同的值,如下所示:
int a = 50, b = 55, c = 67, ...; float avg = (float)(a + b + c + ... ) / 10;
这些变量将分散在内存中,彼此之间没有任何关联。重要的是,如果我们想扩展计算 100 名(或更多)学生平均分的问题,那么声明如此多的独立变量就变得不切实际了。
数组提供了一种紧凑且节省内存的解决方案。由于数组中的元素存储在相邻的位置,我们可以轻松访问与当前元素相关的任何元素。由于每个元素都有索引,因此可以直接操作。
示例:在 C 语言中使用数组
回到存储 10 名学生成绩并计算平均分的问题,使用数组的解决方案如下:-
#include <stdio.h>
int main(){
int marks[10] = {50, 55, 67, 73, 45, 21, 39, 70, 49, 51};
int i, sum = 0;
float avg;
for (i = 0; i <= 9; i++){
sum += marks[i];
}
avg = (float)sum / 10;
printf("Average: %f", avg);
return 0;
}
Output
运行代码并检查其输出 −
Average: 52.000000
数组元素存储在连续的内存位置。每个元素都由一个从"0"开始的索引标识。最低地址对应第一个元素,最高地址对应最后一个元素。

C 语言数组声明
要在 C 语言中声明数组,需要指定元素的类型以及要存储的元素数量。
声明数组的语法
type arrayName[size];
"size"必须是大于零的整型常量,其"type"可以是任何有效的 C 数据类型。在 C 语言中,声明数组有多种方式。
示例:在 C 语言中声明数组
在以下示例中,我们声明一个包含 5 个整数的数组,并打印所有数组元素的索引和值 -
#include <stdio.h>
int main(){
int arr[5];
int i;
for (i = 0; i <= 4; i++){
printf("a[%d]: %d
", i, arr[i]);
}
return 0;
}
输出
运行代码并检查其输出 −
a[0]: -133071639 a[1]: 32767 a[2]: 100 a[3]: 0 a[4]: 4096
C 语言中数组的初始化
声明数组时,可以通过提供用大括号 {} 括起来的一组逗号分隔的值来初始化数组。
初始化数组的语法
data_type array_name [size] = {value1, value2, value3, ...};
初始化数组示例
以下示例演示了整数数组的初始化:
// 整数数组的初始化
#include <stdio.h>
int main()
{
int numbers[5] = {10, 20, 30, 40, 50};
int i; // 循环计数器
// 打印数组元素
printf("数组元素为 : ");
for (i = 0; i
输出
数组元素为:10 20 30 40 50
将所有数组元素初始化为 0 的示例
要将所有元素初始化为 0,请将其放在花括号内
#include <stdio.h>
int main(){
int arr[5] = {0};
int i;
for(i = 0; i <= 4; i++){
printf("a[%d]: %d
", i, arr[i]);
}
return 0;
}
输出
运行此代码时,将产生以下输出 -
a[0]: 0
a[1]: 0
a[2]: 0
a[3]: 0
a[4]: 0
数组部分初始化示例
如果值列表小于数组的大小,则其余元素将初始化为"0"。
#include <stdio.h>
int main(){
int arr[5] = {1,2};
int i;
for(i = 0; i <= 4; i++){
printf("a[%d]: %d
", i, arr[i]);
}
return 0;
}
输出
运行此代码,将产生以下输出 -
a[0]: 1
a[1]: 2
a[2]: 0
a[3]: 0
a[4]: 0
部分和特定元素初始化示例
如果数组是部分初始化的,则可以在方括号中指定元素。
#include <stdio.h>
int main(){
int a[5] = {1,2, [4] = 4};
int i;
for(i = 0; i <= 4; i++){
printf("a[%d]: %d
", i, a[i]);
}
return 0;
}
输出
执行后,将产生以下输出 -
a[0]: 1
a[1]: 2
a[2]: 0
a[3]: 0
a[4]: 4
C 语言中获取数组大小
编译器会分配一块连续的内存。分配的内存大小取决于数组的数据类型。
示例 1:整数数组的大小
如果声明了一个包含 5 个元素的整数数组,则该数组的字节数大小为"sizeof(int) x 5"
#include <stdio.h>
int main(){
int arr[5] = {1, 2, 3, 4, 5};
printf("Size of array: %ld", sizeof(arr));
return 0;
}
输出
执行后,您将获得以下输出 -
Size of array: 20
sizeof 运算符返回变量占用的字节数。
示例 2:数组元素的相邻地址
每个 int 的大小为 4 个字节。编译器会为每个元素分配相邻的位置。
#include <stdio.h>
int main(){
int a[] = {1, 2, 3, 4, 5};
int i;
for(i = 0; i < 4; i++){
printf("a[%d]: %d Address: %d
", i, a[i], &a[i]);
}
return 0;
}
Output
运行代码并检查其输出 −
a[0]: 1 Address: 2102703872
a[1]: 2 Address: 2102703876
a[2]: 3 Address: 2102703880
a[3]: 4 Address: 2102703884
此数组中的每个元素均为 int 类型。因此,第 0 个元素占用前 4 个字节(642016 至 19)。下一个下标处的元素占用接下来的 4 个字节,依此类推。
示例 3:双精度型数组
如果数组类型为 double 类型,则每个下标处的元素占用 8 个字节。
#include <stdio.h>
int main(){
double a[] = {1.1, 2.2, 3.3, 4.4, 5.5};
int i;
for(i = 0; i < 4; i++){
printf("a[%d]: %f Address: %ld
", i, a[i], &a[i]);
}
return 0;
}
Output
运行代码并检查其输出 −
a[0]: 1.100000 Address: 140720746288624
a[1]: 2.200000 Address: 140720746288632
a[2]: 3.300000 Address: 140720746288640
a[3]: 4.400000 Address: 140720746288648
示例 4:字符数组的大小
"char"变量的长度为 1 个字节。因此,char 数组的长度等于该数组的大小。
#include <stdio.h>
int main(){
char a[] = "Hello";
int i;
for (i=0; i<5; i++){
printf("a[%d]: %c address: %ld
", i, a[i], &a[i]);
}
return 0;
}
Output
运行代码并检查其输出 −
a[0]: H address: 6422038
a[1]: e address: 6422039
a[2]: l address: 6422040
a[3]: l address: 6422041
a[4]: o address: 6422042
在 C 语言中访问数组元素
数组中的每个元素都由一个唯一的递增索引标识,以"0"开头。要通过索引访问元素,只需将元素的索引放在数组名称后的方括号中即可。
访问数组元素的方法是,在数组名称后的方括号中指定所需元素的索引(偏移量)。例如:-
double salary = balance[9];
上述语句将从数组中取出第 10 个元素,并将其值赋给"salary"。
在 C 语言中访问数组元素的示例
以下示例展示了如何使用上述三个概念:声明、赋值和访问数组。
#include <stdio.h>
int main(){
int n[5]; /* n 是一个由 5 个整数组成的数组 */
int i, j;
/* 将数组 n 的元素初始化为 0 */
for(i = 0; i < 5; i++){
n[i] = i + 100;
}
/* 输出每个数组元素的值 */
for(j = 0; j < 5; j++){
printf("n[%d] = %d
", j, n[j]);
}
return 0;
}
输出
运行此代码后,您将获得以下输出 -
n[0] = 100
n[1] = 101
n[2] = 102
n[3] = 103
n[4] = 104
索引允许随机访问数组元素。数组可以由结构体变量、指针甚至其他数组作为其元素组成。
更多关于 C 数组
数组是 C 语言中的一个重要概念,需要更多关注。以下与数组相关的重要概念对于 C 程序员来说应该清晰易懂:
C 语言中的指针
C 语言中的指针是什么?
C 语言指针是一种派生数据类型,用于存储另一个变量的地址,也可用于访问和操作存储在该位置的变量数据。指针被视为派生数据类型。
使用指针,您可以访问和修改内存中的数据,在函数之间高效地传递数据,以及创建动态数据结构,例如链表、树和图。
指针声明
要声明指针,请使用解引用运算符 (*),后跟数据类型。
语法
指针变量声明的一般形式为:-
type *var-name;
此处,type 是指针的基类型;它必须是有效的 C 数据类型,var-name 是指针变量的名称。用于声明指针的星号 * 与用于乘法的星号相同。然而,在此语句中,星号被用来将变量指定为指针。
有效指针变量声明示例
查看一些有效的指针声明 −
int *ip; /* 指向整数的指针 */ double *dp; /* 指向双精度数的指针 */ float *fp; /* 指向浮点数的指针 */ char *ch /* 指向字符的指针 */
所有指针(无论是整数、浮点数、字符型还是其他类型)的实际数据类型都是相同的,即一个表示内存地址的长十六进制数。不同数据类型的指针之间的唯一区别在于指针指向的变量或常量的数据类型。
指针初始化
声明指针变量后,需要使用取地址 (&) 运算符,用另一个变量的地址初始化该指针变量。此过程称为引用指针。
语法
以下是初始化指针变量的语法
pointer_variable = &variable;
示例
以下是指针初始化的示例
int x = 10; int *ptr = &x;
这里,x 是一个整型变量,ptr 是一个整型指针。指针 ptr 正在使用 x 初始化。
引用和解除引用指针
指针引用内存中的某个位置。获取存储在该位置的值称为解除引用指针。
在 C 语言中,理解指针机制中以下两个运算符的用途非常重要 -
- & 运算符 - 也称为"取地址运算符"。它用于引用,即获取现有变量的地址(使用 &)来设置指针变量。
- * 运算符 − 也称为"取消引用运算符"。取消引用 指针是使用 * 运算符 从指针指向的内存地址获取值来实现的。
指针用于通过引用传递参数。如果程序员希望函数对参数的修改对函数调用者可见,则这非常有用。这对于从函数返回多个值也很有用。
使用指针访问和操作值
可以使用指针变量访问和操作指针指向的变量的值。您需要使用星号 (*) 和指针变量来访问和操作变量的值。
示例
在下面的示例中,我们将一个整数变量及其初始值更改为新值。
#include <stdio.h>
int main() {
int x = 10;
// 指针声明和初始化
int * ptr = & x;
// 打印当前值
printf("Value of x = %d
", * ptr);
// 更改值
* ptr = 20;
// 打印更新后的值
printf("Value of x = %d
", * ptr);
return 0;
}
输出
Value of x = 10 Value of x = 20
如何使用指针?
要在 C 语言中使用指针,您需要声明一个指针变量,然后用另一个变量的地址对其进行初始化,然后可以通过解引用来获取和更改指针指向的变量的值。
您可以将指针用于任何类型的变量,例如整数、浮点数、字符串等。您还可以将指针用于派生数据类型,例如数组、结构、联合等。
示例
在下面的示例中,我们使用指针获取不同类型变量的值。
#include <stdio.h>
int main() {
int x = 10;
float y = 1.3f;
char z = 'p';
// 指针声明和初始化
int * ptr_x = & x;
float * ptr_y = & y;
char * ptr_z = & z;
// 打印值
printf("Value of x = %d
", * ptr_x);
printf("Value of y = %f
", * ptr_y);
printf("Value of z = %c
", * ptr_z);
return 0;
}
输出
Value of x = 10 Value of y = 1.300000 Value of z = p
指针变量的大小
指针变量占用的内存(或大小)与其指向的变量类型无关。指针的大小取决于系统架构。
示例
在下面的示例中,我们将打印不同类型指针的大小:
#include <stdio.h>
int main() {
int x = 10;
float y = 1.3f;
char z = 'p';
// 指针声明和初始化
int * ptr_x = & x;
float * ptr_y = & y;
char * ptr_z = & z;
// 打印指针变量的大小
printf("Size of integer pointer : %lu
", sizeof(ptr_x));
printf("Size of float pointer : %lu
", sizeof(ptr_y));
printf("Size of char pointer : %lu
", sizeof(ptr_z));
return 0;
}
输出
Size of integer pointer : 8 Size of float pointer : 8 Size of char pointer : 8
C 语言指针示例
练习以下示例以学习指针的概念
示例 1:在 C 语言中使用指针
以下示例展示了如何在 C 语言中使用 & 和 * 运算符执行与指针相关的操作 -
#include <stdio.h>
int main(){
int var = 20; /* 实际变量声明 */
int *ip; /* 指针变量声明 */
ip = &var; /* 将 var 的地址存储在指针变量中*/
printf("Address of var variable: %p
", &var);
/* 指针变量中存储的地址 */
printf("Address stored in ip variable: %p
", ip);
/* 使用指针访问值 */
printf("Value of *ip variable: %d
", *ip );
return 0;
}
输出
执行代码并检查其输出 −
Address of var variable: 0x7ffea76fc63c Address stored in ip variable: 0x7ffea76fc63c Value of *ip variable: 20
示例:打印整数的值和地址
我们将声明一个 int 变量并显示其值和地址 -
#include <stdio.h>
int main(){
int var = 100;
printf("Variable: %d Address: %p", var, &var);
return 0;
}
输出
运行代码并检查其输出 −
Variable: 100 Address: 0x7ffc62a7b844
示例:整数指针
在本例中,var 的地址通过 & 运算符存储在 intptr 变量中
#include <stdio.h>
int main(){
int var = 100;
int *intptr = &var;
printf("Variable: %d
Address of Variable: %p
", var, &var);
printf("intptr: %p
Address of intptr: %p
", intptr, &intptr);
return 0;
}
输出
运行代码并检查其输出 −
Variable: 100 Address of Variable: 0x7ffdcc25860c intptr: 0x7ffdcc25860c Address of intptr: 0x7ffdcc258610
示例 5
现在我们以浮点变量为例,查找其地址 -
#include <stdio.h>
int main(){
float var1 = 10.55;
printf("var1: %f
", var1);
printf("Address of var1: %d", &var1);
}
输出
运行代码并检查其输出 −
var1: 10.550000 Address of var1: 1512452612
我们可以看到,这个变量(任何类型的变量)的地址都是整数。因此,如果我们尝试将其存储在"浮点"类型的指针变量中,看看会发生什么 -
float var1 = 10.55; int *intptr = &var1;
编译器不接受这种情况,并报告以下错误 -
从不兼容的指针类型"float *"初始化"int *" [-Wincompatible-pointer-types]
注意:变量的类型和其指针的类型必须相同。
在 C 语言中,变量具有特定的数据类型,用于定义其大小以及存储值的方式。使用匹配类型(例如 float *)声明指针会强制指针与其指向的数据之间保持"类型兼容性"。
在 C 语言中,不同的数据类型占用不同的内存空间。例如,"int"通常占用 4 个字节,而"float"则可能占用 4 个或 8 个字节,具体取决于系统。对指针进行整数加减操作会根据其指向的数据的大小在内存中移动指针。
示例:浮点指针
在此示例中,我们声明一个"float *"类型的变量"floatptr"。
#include <stdio.h>
int main(){
float var1 = 10.55;
float *floatptr = &var1;
printf("var1: %f
Address of var1: %p
",var1, &var1);
printf("floatptr: %p
Address of floatptr: %p
", floatptr, &floatptr);
printf("var1: %f
Value at floatptr: %f", var1, *floatptr);
return 0;
}
输出
var1: 10.550000 Address of var1: 0x7ffc6daeb46c floatptr: 0x7ffc6daeb46c Address of floatptr: 0x7ffc6daeb470
指向指针的指针
我们可能有一个指针变量,它存储另一个指针本身的地址。
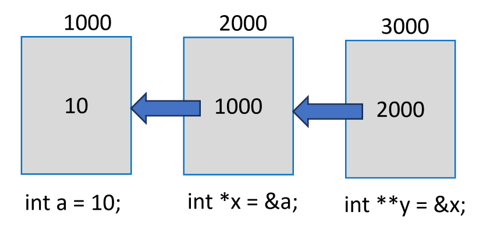
在上图中,"a"是一个普通的"int"变量,其指针指向"x"。反过来,该变量存储"x"的地址。
请注意,"y"被声明为"int **",以指示它是指向另一个指针变量的指针。显然,"y"将返回"x"的地址,"*y"是"x"中的值(即"a"的地址)。
要从"y"获取"a"的值,我们需要使用表达式"**y"。通常,"y"将被称为指向指针的指针。
示例
请看以下示例 -
#include <stdio.h>
int main(){
int var = 10;
int *intptr = &var;
int **ptrptr = &intptr;
printf("var: %d
Address of var: %d
",var, &var);
printf("inttptr: %d
Address of inttptr: %d
", intptr, &intptr);
printf("var: %d
Value at intptr: %d
", var, *intptr);
printf("ptrptr: %d
Address of ptrtptr: %d
", ptrptr, &ptrptr);
printf("intptr: %d
Value at ptrptr: %d
", intptr, *ptrptr);
printf("var: %d
*intptr: %d
**ptrptr: %d", var, *intptr, **ptrptr);
return 0;
}
输出
运行代码并检查其输出 −
var: 10 Address of var: 951734452 inttptr: 951734452 Address of inttptr: 951734456 var: 10 Value at intptr: 10 ptrptr: 951734456 Address of ptrtptr: 951734464 intptr: 951734452 Value at ptrptr: 951734452 var: 10 *intptr: 10 **ptrptr: 10
您可以使用指向数组的指针,也可以使用struct定义的派生类型。指针具有重要的应用。它们在通过传递引用来调用函数时使用。指针还有助于克服函数只能返回单个值的限制。使用指针,您可以实现返回多个值或数组的效果。
NULL 指针
如果没有要分配的确切地址,最好将 NULL 值赋给指针变量。这在变量声明时完成。被赋值为 NULL 的指针称为空指针。
NULL 指针是一个常量,其值为"0",在多个标准库中都有定义。
示例
考虑以下程序 -
#include <stdio.h>
int main(){
int *ptr = NULL;
printf("The value of ptr is : %x
", ptr);
return 0;
}
输出
当编译并执行上述代码时,它会产生以下结果 -
The value of ptr is 0
在大多数操作系统中,程序不允许访问地址"0"处的内存,因为该内存由操作系统保留。
内存地址"0"具有特殊含义;它表示指针不打算指向可访问的内存位置。但按照惯例,如果指针包含空值(零),则假定它指向空。
要检查是否为空指针,可以使用 if 语句,如下所示 -
if(ptr) /* 如果 p 不为空,则执行成功 */ if(!ptr) /* 如果 p 为空,则执行成功 */
变量的地址
众所周知,每个变量都是一个内存位置,每个内存位置都有其定义的地址,可以使用 & 运算符访问,该运算符表示内存中的地址。
示例
考虑以下示例,该示例打印已定义变量的地址 -
#include <stdio.h>
int main(){
int var1;
char var2[10];
printf("Address of var1 variable: %x
", &var1);
printf("Address of var2 variable: %x
", &var2);
return 0;
}
输出
当上述代码被编译并执行时,它将打印变量的地址 -
Address of var1 variable: 61e11508 Address of var2 variable: 61e1150e
指针详解
指针的概念很多,但都很简单,它们对 C 语言编程至关重要。以下重要的指针概念对于任何 C 程序员来说都应该清楚 -
| 序号 | 概念 &说明 |
|---|---|
| 1 | 指针运算
指针可以使用四种运算运算符:++、--、+、- |
| 2 | 指针数组
您可以定义数组来保存多个指针。 |
| 3 | 指向指针的指针
C 语言允许将指针指向指针,因此开启。 |
| 4 | 在 C 语言中向函数传递指针
通过引用或地址传递参数,被调用函数可以在调用函数中更改传递的参数。 |
| 5 | 在 C 语言中从函数返回指针
C 语言允许函数返回指向局部变量、静态变量以及动态分配内存的指针。 |
C 语言中的字符串
C 语言中的字符串是一个 char 类型的一维数组,数组中的最后一个字符是一个"空字符",用 '\0' 表示。因此,C 语言中的字符串可以定义为以空字符结尾的 char 类型值序列。
在 C 语言中创建字符串
我们创建一个字符串"Hello"。它包含五个 char 值。在 C 语言中,char 类型的字面量表示使用单引号符号,例如 'H'。将这五个字母放在单引号中,后跟一个用 '\0' 表示的空字符,赋值给一个 char 类型数组。数组的大小为 5 个字符加上 6 个空字符。
示例
char greet[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
初始化字符串而不指定大小
C 语言允许初始化数组而不声明大小,在这种情况下,编译器会自动确定数组大小。
示例
char greet[] = {'H', 'e', 'l', 'l', 'o', '\0'};
在内存中创建的数组可以示意性地显示如下:
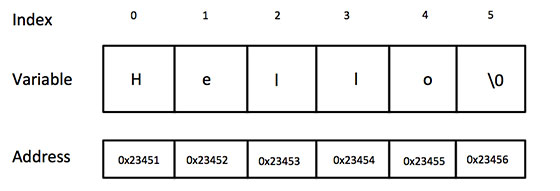
如果字符串不以"\0"结尾,则会导致不可预测的行为。
注意:字符串的长度不包括空字符。库函数 strlen() 返回此字符串的长度为 5。
循环遍历字符串
您可以使用 for 循环 或任何其他 循环语句 循环遍历字符串(字符数组),以访问和操作字符串中的每个字符。
示例
在下面的示例中,我们将打印字符串的字符。
#include <stdio.h>
#include <string.h>
int main (){
char greeting[] = {'H', 'e', 'l', 'l', 'o', '\0'};
for (int i = 0; i < 5; i++) {
printf("%c", greeting[i]);
}
return 0;
}
输出
它将产生以下输出 -
Hello
打印字符串(使用 %s 格式说明符)
C 语言提供了一个格式说明符"%s",用于在使用 printf() 或 fprintf() 等函数时打印字符串。
示例
"%s"说明符指示函数遍历数组,直到遇到空终止符 (\0) 并打印每个字符。这有效地打印了字符数组所表示的整个字符串,而无需使用循环。
#include <stdio.h>
int main (){
char greeting[] = {'H', 'e', 'l', 'l', 'o', '\0'};
printf("Greeting message: %s
", greeting );
return 0;
}
输出
它将产生以下输出 -
Greeting message: Hello
您可以声明一个超大数组并分配较少的字符数,C 编译器 对此不会产生任何问题。但是,如果数组大小小于初始化时指定的字符数,则输出中可能会出现垃圾值。
char Greeting[3] = {'H', 'e', 'l', 'l', 'o', '\0'};
printf("%s", Greeting);
使用双引号构造字符串
C 语言允许您通过将字符括在双引号中来构造字符串,而不是像以前那样用单引号将单个 char 值组成一个 char 数组,并使用 "\0" 作为最后一个元素。这种初始化字符串的方法更方便,因为编译器会自动添加"\0"作为最后一个字符。
Example
#include <stdio.h>
int main() {
// 创建字符串
char Greeting[] = "Hello World";
// 打印字符串
printf("%s
", greeting);
return 0;
}
输出
它将产生以下输出 -
Hello World
使用 scanf() 输入字符串
如果要让用户输入字符串,声明一个以空字符结尾的字符串会比较困难。您可以借助 for 循环,一次接受一个字符并将其存储在数组的每个下标中 -
语法
for(i = 0; i < 6; i++){
scanf("%c", &greeting[i]);
}
greeting[i] = '\0';
示例
在以下示例中,您可以使用 scanf() 函数 输入一个字符串。输入特定字符(以下示例中为 5 个)后,我们将赋值 null ('\0') 来终止该字符串。
printf("Starting Typing... ");
for (i = 0; i < 5; i++) {
scanf("%c", &greeting[i]);
}
// 手动赋值 NULL
greeting[i] = '\0';
// 打印字符串
printf("Value of greeting: %s
", greeting);
输出
运行代码并检查其输出 −
Starting typing... Hello Value of greeting: Hello
示例
无法输入"\0"(空字符串),因为它是不可打印的字符。为了解决这个问题,在 scanf() 语句中使用了"%s"格式说明符 -
#include <stdio.h>
#include <string.h>
int main (){
char greeting[10];
printf("Enter a string:
");
scanf("%s", greeting);
printf("You entered:
");
printf("%s", greeting);
return 0;
}
输出
运行代码并检查其输出 −
Enter a string: Hello You entered: Hello
注意:如果数组的大小小于输入字符串的长度,则可能会导致垃圾数据、数据损坏等情况。
包含空格的字符串输入
scanf("%s") 会读取字符,直到遇到空格(空格、制表符、换行符等)或 EOF。因此,如果您尝试输入一个包含多个单词(以空格分隔)的字符串,C 程序会接受第一个空格之前的字符作为字符串的输入。
示例
请看以下示例 -
#include <stdio.h>
#include <string.h>
int main (){
char greeting[20];
printf("Enter a string:
");
scanf("%s", greeting);
printf("You entered:
");
printf("%s", greeting);
return 0;
}
输出
运行代码并检查其输出 −
Enter a string: Hello World! You entered: Hello
使用 gets() 和 fgets() 函数进行字符串输入
要接受中间带有空格的字符串输入,我们应该使用 gets() 函数。它被称为非格式化控制台输入函数,定义在 stdio.h" 头文件 中。
示例:使用 gets() 函数进行字符串输入
请看以下示例 -
#include <stdio.h>
#include <string.h>
int main(){
char name[20];
printf("Enter a name:
");
gets(name);
printf("You entered:
");
printf("%s", name);
return 0;
}
输出
运行代码并检查其输出 −
Enter a name: Sachin Tendulkar You entered: Sachin Tendulkar
在较新版本的 C 语言中,gets() 已被弃用。它是一个潜在的危险函数,因为它不执行边界检查,并且可能导致缓冲区溢出。
建议使用 fgets() 函数。
fgets(char arr[], size, stream);
fgets() 函数 可用于接受来自任何输入流的输入,例如 stdin(键盘)或 FILE(文件流)。
示例:使用 fgets() 函数进行字符串输入
以下程序使用 fgets() 并接受来自用户的多字输入。
#include <stdio.h>
#include <string.h>
int main(){
char name[20];
printf("Enter a name:
");
fgets(name, sizeof(name), stdin);
printf("You entered:
");
printf("%s", name);
return 0;
}
输出
运行代码并检查其输出 −
Enter a name: Virat Kohli You entered: Virat Kohli
示例:使用 scanf("%[^ ]s") 输入字符串
您也可以使用 scanf("%[^ ]s") 作为替代方案。它会读取字符,直到遇到换行符 (" ")。
#include <stdio.h>
#include <string.h>
int main (){
char name[20];
printf("Enter a name:
");
scanf("%[^
]s", name);
printf("You entered
");
printf("%s", name);
return 0;
}
输出
运行代码并检查其输出 −
Enter a name: Zaheer Khan You entered Zaheer Khan
使用 puts() 和 fputs() 函数打印字符串
我们一直在使用带有 %s 说明符的 printf() 函数 来打印字符串。我们也可以使用 puts() 函数(在 C11 和 C17 版本中已弃用)或 fputs() 函数 作为替代方案。
示例
请看以下示例 -
#include <stdio.h>
#include <string.h>
int main (){
char name[20] = "Rakesh Sharma";
printf("With puts():
");
puts(name);
printf("With fputs():
");
fputs(name, stdout);
return 0;
}
输出
运行代码并检查其输出 −
With puts(): Harbhajan Singh With fputs(): Harbhajan Singh
C 语言中的结构体
C 语言中的结构体
C 语言中的结构体是一种派生数据类型或用户自定义数据类型。我们使用关键字 struct 来定义一种自定义数据类型,将不同类型的元素组合在一起。数组和结构体的区别在于,数组是相似类型的同质集合,而结构体可以相邻存储不同类型的元素,并通过名称进行标识。
我们经常需要处理不同数据类型的值,这些值之间存在一定的关系。例如,一本 book 由其 title(字符串)、author(字符串)、price(双精度型)、number of pages(整数型)等描述。这些值可以存储在一个 struct 变量中,而无需使用四个不同的变量。
声明(创建)结构体
您可以使用 "struct" 关键字加上structure_tag(结构体名称)来创建(声明)结构体,并在花括号内声明结构体的所有成员及其数据类型。
要定义结构体,必须使用 struct 语句。 struct 语句定义了一个新的数据类型,该类型包含多个成员。
结构体声明的语法
声明结构的格式(语法)如下:-
struct [structure tag]{
member definition;
member definition;
...
member definition;
} [one or more structure variables];
结构体标签是可选的,每个成员定义都是一个普通的变量定义,例如"int i;"或"float f;"。或任何其他有效的变量定义。
在结构体定义的末尾,在最后一个分号之前,您可以指定一个或多个结构体变量,但这是可选的。
示例
在下面的示例中,我们为 Book 声明了一个结构体来存储书籍的详细信息 -
struct book{
char title[50];
char author[50];
double price;
int pages;
} book1;
此处,我们在结构体定义的末尾声明了结构体变量 book1。不过,您也可以在不同的语句中单独声明。
结构体变量声明
要访问和操作结构体成员,需要先声明其变量。声明结构体变量时,请将结构体名称与 "struct" 关键字一起写入,后跟结构体变量的名称。此结构体变量将用于访问和操作结构体成员。
示例
以下语句演示了如何声明(创建)结构体变量
struct book book1;
通常,结构体在程序中定义第一个函数之前声明,位于 include 语句之后。这样,派生类型便可用于在任何函数内声明其变量。
结构体初始化
结构体变量的初始化是通过将每个元素的值放在大括号内来完成的。
示例
以下语句演示了结构体的初始化
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325};
访问结构体成员
要访问结构体成员,首先需要声明一个结构体变量,然后使用点 (.) 运算符以及该结构体变量。
示例 1
使用点 (.) 运算符访问结构体变量 book1 的四个元素。因此,"book1.title"指的是书名元素,"book1.author"是作者姓名,"book1.price"是价格,"book1.pages"是第四个元素(页数)。
请看以下示例 -
#include <stdio.h>
struct book{
char title[10];
char author[20];
double price;
int pages;
};
int main(){
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325};
printf("Title: %s
", book1.title);
printf("Author: %s
", book1.author);
printf("Price: %lf
", book1.price);
printf("Pages: %d
", book1.pages);
printf("Size of book struct: %d", sizeof(struct book));
return 0;
}
输出
运行代码并检查其输出 −
Title: Learn C Author: Dennis Ritchie Price: 675.500000 Pages: 325 Size of book struct: 48
示例 2
对上面的程序进行一些小修改。在这里,我们将类型定义和变量声明放在一起,如下所示 -
struct book{
char title[10];
char author[20];
double price;
int pages;
} book1;
请注意,如果您以这种方式声明结构体变量,则不能使用花括号初始化它。相反,需要对元素单独赋值。
#include <stdio.h>
#include <string.h>
struct book{
char title[10];
char author[20];
double price;
int pages;
} book1;
int main(){
strcpy(book1.title, "Learn C");
strcpy(book1.author, "Dennis Ritchie");
book1.price = 675.50;
book1.pages = 325;
printf("Title: %s
", book1.title);
printf("Author: %s
", book1.author);
printf("Price: %lf
", book1.price);
printf("Pages: %d
", book1.pages);
return 0;
}
输出
当您执行此代码时,它将产生以下输出 -
Title: Learn C Author: Dennis Ritchie Price: 675.500000 Pages: 325
复制结构体
赋值运算符 (=) 可用于直接复制结构体。您也可以使用赋值运算符 (=) 将一个结构体成员的值赋给另一个结构体。
假设有两个结构体 book 变量,book1 和 book2。变量 book1 已通过声明初始化,我们希望将其元素的值赋给 book2。
我们可以按如下方式对各个元素进行赋值 -
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325}, book2;
strcpy(book2.title, book1.title);
strcpy(book2.author, book1.author);
book2.price = book1.price;
book2.pages = book1.pages;
请注意,使用 strcpy() 函数 将值赋给 string 变量,而不是使用"="运算符。
示例
您还可以将 book1 赋值给 book2,这样 book1 的所有元素都会分别赋值给 book2 的元素。请看以下程序代码 -
#include <stdio.h>
#include <string.h>
struct book{
char title[10];
char author[20];
double price;
int pages;
};
int main(){
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325}, book2;
book2 = book1;
printf("Title: %s
", book2.title);
printf("Author: %s
", book2.author);
printf("Price: %lf
", book1.price);
printf("Pages: %d
", book1.pages);
printf("Size of book struct: %d", sizeof(struct book));
return 0;
}
输出
运行代码并检查其输出 −
Title: Learn C Author: Dennis Ritchie Price: 675.500000 Pages: 325 Size of book struct: 48
结构体作为函数参数
您可以像传递其他变量或指针一样,将结构体作为函数参数传递。
示例
查看以下程序代码。它演示了如何将结构体作为函数参数传递 -
#include <stdio.h>
#include <string.h>
struct Books{
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* 函数声明 */
void printBook(struct Books book);
int main(){
struct Books Book1; /* 将 Book1 声明为 Book 类型 */
struct Books Book2; /* 将 Book2 声明为 Book 类型 */
/* 书 1 的说明 */
strcpy(Book1.title, "C Programming");
strcpy(Book1.author, "Nuha Ali");
strcpy(Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* 书 2 的说明 */
strcpy(Book2.title, "Telecom Billing");
strcpy(Book2.author, "Zara Ali");
strcpy(Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 打印 Book1 的信息 */
printBook(Book1);
/* 打印 Book2 的信息 */
printBook(Book2);
return 0;
}
void printBook(struct Books book){
printf("Book title : %s
", book.title);
printf("Book author : %s
", book.author);
printf("Book subject : %s
", book.subject);
printf("Book book_id : %d
", book.book_id);
}
输出
当编译并执行上述代码时,它会产生以下结果 -
Book title : C Programming Book author : Nuha Ali Book subject : C Programming Tutorial Book book_id : 6495407 Book title : Telecom Billing Book author : Zara Ali Book subject : Telecom Billing Tutorial Book book_id : 6495700
指向结构的指针
指向结构的指针的声明
您可以按如下方式声明指向结构的指针(或结构指针):
struct Books *struct_pointer;
指向结构的指针的初始化
您可以将结构变量的地址存储在上述指针变量struct_pointer中。要查找结构变量的地址,请在"&"结构体名称前的运算符如下:-
struct_pointer = & book1;
让我们将结构体变量的地址存储在结构体指针变量中。
struct book{
char title[10];
char author[20];
double price;
int pages;
};
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325},
struct book *strptr;
使用指向结构体的指针访问成员
要使用指向结构体的指针访问结构体的成员,必须使用 运算符,如下所示 -
struct_pointer->title;
C 语言将 符号定义为与结构体指针一起使用的 间接运算符(也称为 结构体解引用运算符)。它有助于访问指针引用的结构体变量的元素。
示例
在此示例中,strptr 是指向 struct book book1 变量的指针。因此,strrptrtitle 返回标题,就像 book1.title 一样。
#include <stdio.h>
#include <string.h>
struct book{
char title[10];
char author[20];
double price;
int pages;
};
int main (){
struct book book1 = {"Learn C", "Dennis Ritchie", 675.50, 325};
struct book *strptr;
strptr = &book1;
printf("Title: %s
", strptr -> title);
printf("Author: %s
", strptr -> author);
printf("Price: %lf
", strptr -> price);
printf("Pages: %d
", strptr -> pages);
return 0;
}
输出
运行此代码时,将产生以下输出 -
Title: Learn C Author: Dennis Ritchie Price: 675.500000 Pages: 325
注意:点运算符 (.) 用于通过 struct 变量访问结构体元素。要通过其指针访问元素,必须使用 间接寻址 (->) 运算符
。结构体变量类似于普通的主类型变量,您可以拥有一个结构体数组,可以将结构体变量传递给函数,也可以从函数返回一个结构体。
您可能已经注意到,在声明变量或指针时,需要在名称前加上"结构体类型"前缀。可以通过使用 typedef 关键字创建简写符号来避免这种情况,我们将在后续章节中对此进行解释。
结构体用于不同的应用程序,例如数据库、文件管理应用程序,以及处理复杂的数据结构,例如树形结构和链表。
位域
位域 允许将数据打包到结构体中。当内存或数据存储紧张时,这尤其有用。典型示例包括:-
- 将多个对象打包成一个机器字,例如,可以压缩 1 位标志。
- 读取外部文件格式 - 可以读取非标准文件格式,例如 9 位整数。
声明
C 语言允许我们在结构体定义中通过在变量后添加 :bit length 来实现此目的。例如:-
struct packed_struct{
unsigned int f1:1;
unsigned int f2:1;
unsigned int f3:1;
unsigned int f4:1;
unsigned int type:4;
unsigned int my_int:9;
} pack;
此处,packed_struct 包含 6 个成员:四个 1 位标志 f1..f3、一个 4 位类型和一个 9 位 my_int。
C 语言会自动尽可能紧凑地打包上述位字段,前提是这些字段的最大长度小于或等于计算机的整数字长。如果不是这种情况,某些编译器可能会允许这些字段的内存重叠,而其他编译器则会将下一个字段存储在下一个字中。
C 语言中的联合
联合是 C 语言中一种特殊的数据类型,允许在同一内存位置存储不同的数据类型。您可以定义一个包含多个成员的联合,但在任何给定时刻只有一个成员可以包含值。联合提供了一种高效的方式,可以将同一内存位置用于多种用途。
联合的所有成员共享同一内存位置。因此,如果需要为两个或多个成员使用同一内存位置,那么联合是最佳的数据类型。最大的联合成员决定了联合的大小。
定义联合
联合变量的创建方式与结构体变量相同。关键字 union 用于在 C 语言中定义联合。
语法
以下是在 C 语言中定义 联合 的语法 -
union [union tag]{
member definition;
member definition;
...
member definition;
} [one or more union variables];
"联合标签"是可选的,每个成员定义都是一个普通的变量定义,例如"int i;"或"float f;"或其他任何有效的变量定义。
在联合定义的末尾,在最后一个分号之前,可以指定一个或多个联合变量。
访问联合成员
要访问联合的任何成员,我们使用成员访问运算符 (.)。成员访问运算符的代码形式为联合变量名和我们要访问的联合成员之间的一个句点。您可以使用关键字 union 来定义联合类型的变量。
语法
以下是使用 C 语言访问联合成员的语法 -
union_name.member_name;
联合成员的初始化
您可以使用赋值运算符 (=) 为联合成员赋值来初始化它们。
语法
以下是初始化联合成员的语法 -
union_variable.member_name = value;
示例
以下代码语句演示了如何初始化联合"data"的成员"i" -
data.i = 10;
联合示例
示例 1
以下示例演示了如何在程序中使用联合 -
#include <stdio.h>
#include <string.h>
union Data{
int i;
float f;
char str[20];
};
int main(){
union Data data;
data.i = 10;
data.f = 220.5;
strcpy(data.str, "C Programming");
printf("data.i: %d
", data.i);
printf("data.f: %f
", data.f);
printf("data.str: %s
", data.str);
return 0;
}
输出
当编译并执行上述代码时,它会产生以下结果 -
data.i: 1917853763 data.f: 4122360580327794860452759994368.000000 data.str: C Programming
这里,我们可以看到 i 和 f(联合体成员)的值显示为垃圾值,因为赋给变量的最终值已经占用了内存位置,这也是 str 成员的值打印效果很好的原因。
示例 2
现在让我们再次看一下同一个例子,我们将一次使用一个变量,这也是使用联合体的主要目的 -
#include <stdio.h>
#include <string.h>
union Data{
int i;
float f;
char str[20];
};
int main(){
union Data data;
data.i = 10;
printf("data.i: %d
", data.i);
data.f = 220.5;
printf("data.f: %f
", data.f);
strcpy(data.str, "C Programming");
printf("data.str: %s
", data.str);
return 0;
}
输出
当编译并执行上述代码时,它会产生以下结果 -
data.i: 10 data.f: 220.500000 data.str: C Programming
这里,所有联合成员的值都打印得很好,因为每次只使用一个成员。
联合的大小
联合的大小是其最大成员的大小。例如,如果一个联合包含两个 char 和 int 类型的成员。在这种情况下,联合的大小将是 int 的大小,因为 int 是最大的成员。
您可以使用 sizeof() 运算符 来获取联合的大小。
示例
在以下示例中,我们将打印联合的大小 -
#include <stdio.h>
// 定义一个联合
union Data {
int a;
float b;
char c[20];
};
int main() {
union Data data;
// 打印联合体每个成员的大小
printf("Size of a: %lu bytes
", sizeof(data.a));
printf("Size of b: %lu bytes
", sizeof(data.b));
printf("Size of c: %lu bytes
", sizeof(data.c));
// 打印联合的大小
printf("Size of union: %lu bytes
", sizeof(data));
return 0;
}
输出
当您编译并执行代码时,它将产生以下输出 -
Size of a: 4 bytes Size of b: 4 bytes Size of c: 20 bytes Size of union: 20 bytes
结构体与联合体的区别
结构体和联合体都是 C 语言编程中的复合数据类型。结构体和联合体之间最显著的区别在于它们存储数据的方式。结构体将每个成员存储在单独的内存位置,而联合体将所有成员存储在相同的内存位置。
以下是名为 myunion 的联合体类型的定义 -
union myunion{
int a;
double b;
char c;
};
联合的定义类似于结构体的定义。具有相同元素的"struct type mystruct"的定义如下所示 -
struct mystruct{
int a;
double b;
char c;
};
结构体和联合体之间的主要区别在于变量的大小。编译器会为结构体变量分配内存,以便存储所有元素的值。mystruct 包含三个元素:int、double 和 char,共占用 13 个字节(4 + 8 + 1)。因此,sizeof(struct mystruct) 返回 13。
另一方面,对于联合类型变量,编译器会分配一块大小足以容纳最大字节大小元素的内存。myunion 类型包含一个 int、一个 double 和一个 char 元素。在这三个元素中,double 变量的大小最大,为 8。因此,sizeof(union myunion) 返回 8。
另外需要考虑的一点是,联合变量只能保存其一个元素的值。当你为一个元素赋值时,其他元素是未定义的。如果你尝试使用其他元素,将会导致一些垃圾。
示例 1:联合占用的内存
在下面的代码中,我们定义了一个名为 Data 的联合类型,它包含三个成员 i、f 和 str。Data 类型的变量可以存储整数、浮点数或字符串。这意味着一个变量(即相同的内存位置)可以用来存储多种类型的数据。你可以根据需要在联合中使用任何内置或用户定义的数据类型。
联合占用的内存足够大,可以容纳联合中最大的成员。例如,在上面的例子中,Data将占用20个字节的内存空间,因为这是字符串可以占用的最大空间。
以下示例显示上述联合体占用的总内存大小 -
#include <stdio.h>
#include <string.h>
union Data{
int i;
float f;
char str[20];
};
int main(){
union Data data;
printf("Memory occupied by Union Data: %d
", sizeof(data));
return 0;
}
输出
当您编译并执行代码时,它将产生以下输出 -
Memory occupied by Union Data: 20
示例 2:结构体占用的内存
现在,让我们创建一个具有相同元素的结构体,并检查它在内存中占用了多少空间。
#include <stdio.h>
#include <string.h>
struct Data{
int i;
float f;
char str[20];
};
int main(){
struct Data data;
printf("Memory occupied by Struct Data: %d
", sizeof(data));
return 0;
}
输出
此结构将占用 28 个字节(4 + 4 + 20)。运行代码并检查其输出 -
Memory occupied by Struct Data: 28
C 语言中的 Bit 位字段
声明结构体或联合类型时,结构体/联合类型变量的大小取决于其各个元素的大小。除了使用默认内存大小外,您还可以设置位的大小来限制大小。指定的大小称为位字段。
以下是声明位字段的语法 -
struct {
data_type elem : width;
};
假设您的 C 程序包含多个 TRUE/FALSE 变量,这些变量分组在一个名为 status 的结构体中,如下所示 -
struct {
unsigned int widthValidated;
unsigned int heightValidated;
} status;
此结构体需要 8 个字节的内存空间,但实际上,我们将在每个变量中存储"0"或"1"。在这种情况下,C 编程语言提供了一种更好的内存空间利用方法。
如果您在结构体中使用此类变量,则可以定义变量的宽度,以告知 C 编译器您将仅使用这几个字节。例如,上述结构体可以重写如下 -
struct {
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status;
上述结构体需要 4 个字节的内存空间来存储 status 变量,但仅使用 2 位来存储其值。
示例
如果您最多使用 32 个变量,每个变量的宽度为 1 位,那么 status 结构体也将使用 4 个字节。但是,一旦变量数量达到 33 个,它就会分配下一个内存槽,并开始使用 8 个字节。
让我们通过以下示例来理解这一概念 -
#include <stdio.h>
/* 定义简单结构体 */
struct {
unsigned int widthValidated;
unsigned int heightValidated;
} status1;
/* 定义一个包含位字段的结构体 */
struct {
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status2;
int main() {
printf("Memory size occupied by status1: %d
", sizeof(status1));
printf("Memory size occupied by status2: %d
", sizeof(status2));
return 0;
}
输出
编译并执行上述代码后,将产生以下输出 -
Memory size occupied by status1: 8 Memory size occupied by status2: 4
位字段声明
位字段在结构体中的声明形式如下:
struct {
type [member_name] : width ;
};
下表描述了位字段的变量元素 -
| 元素 | 描述 |
|---|---|
| 类型 | 整数类型,用于确定如何解释位字段的值。 类型可以是 int、signed int 或 unsigned int。 |
| member_name | 位字段的名称。 |
| 宽度 | 位字段的位数。"宽度"必须小于或等于指定类型的位宽度。 |
具有预定义宽度的变量称为位字段。位字段可以容纳多个位;例如,如果您需要一个变量来存储从 0 到 7 的值,则可以定义一个宽度为 3 位的位字段,如下所示 -
struct {
unsigned int age : 3;
} Age;
上述结构体定义指示 C 编译器,变量"Age"将仅使用 3 位来存储值。如果您尝试使用超过 3 位,则系统将不允许您这样做。
示例
让我们尝试以下示例 -
#include <stdio.h>
struct {
unsigned int age : 3;
} Age;
int main() {
Age.age = 4;
printf("Sizeof(Age): %d
", sizeof(Age));
printf("Age.age: %d
", Age.age);
Age.age = 7;
printf("Age.age : %d
", Age.age);
Age.age = 8;
printf("Age.age : %d
", Age.age);
return 0;
}
输出
编译上述代码时,会显示警告 -
warning: unsigned conversion from 'int' to 'unsigned char:3' changes value from '8' to '0' [-Woverflow]|
执行后,将产生以下输出 -
Sizeof(Age): 4 Age.age: 4 Age.age: 7 Age.age: 0
在可用存储空间有限的情况下,可以使用位字段。当设备传输编码为多个位的状态或信息时,位字段也非常有效。当某些加密程序需要访问字节中的位时,位字段用于定义数据结构。
C 语言中的 Typedef
C 语言的 typedef
C 编程语言提供了一个名为 typedef 的关键字,用于为现有的数据类型设置一个替代名称。C 语言中的 typedef 关键字在为内置数据类型以及任何派生数据类型(例如结构体、联合体或指针)分配一个方便的别名时非常有用。
有时,每次声明变量时都使用名称较长的数据类型(例如"struct structname"或"unsigned int")会显得很笨拙。在这种情况下,我们可以指定一个方便的快捷方式,以提高代码的可读性。
typedef 语法
通常,typedef 关键字的用法如下:
typedef existing_type new_type;
typedef 示例
在本章中,我们将了解 typedef 的一些用例。
示例 1
在 C 语言中,关键字"unsigned"用于声明只能存储非负值的无符号整数变量。
C 语言中还有一个名为"short"的关键字,用于声明占用 2 个字节内存的整数数据类型。如果您想声明一个 short 类型的变量,并且该变量只能为非负值,则可以组合使用以下两个关键字(unsigned 和 short):
short unsigned int x;
如果要声明多个此类型的变量,每次都使用这三个关键字会不太方便。您可以使用 typedef 关键字定义一个 别名 或快捷方式,如下所示 -
typedef short unsigned int USHORT;
这会告诉编译器标识符 USHORT 对应于"short unsigned int"类型。此后,您可以在变量声明语句中使用 USHORT -
USHORT x;
示例 2
C 语言中还有关键字 static,用于指示此类变量仅初始化一次。关键字 "long" 在 64 位系统上分配 8 个字节来存储整数。我们可以如下声明此类型的变量 -
static unsigned long x;
但是,我们不能在"typedef"语句中使用关键字"static",但是我们可以使用typedef为此类声明分配快捷别名 -
typedefsigned long SLONG; static SLONG x;
注意:按照惯例,别名名称以大写表示,只是为了区分内置类型和使用的别名。
示例 3
以下示例演示了如何在 C 程序中使用别名 -
#include <stdio.h>
int main() {
typedef short unsigned int USHORT;
typedef signed long int SLONG;
static SLONG x = 100;
USHORT y = 200;
printf("Size of SLONG: %d
Size of USHORT: %d", sizeof(SLONG), sizeof(USHORT));
return 0;
}
输出
运行此代码时,将产生以下输出 -
Size of SLONG: 8 Size of USHORT: 2
使用 Typedef 定义结构体
通常,我们需要在声明语句中以 struct_type 的名称作为前缀来声明结构体变量,如下所示:-
struct struct_type var;
如果觉得以这种方式编写类型名称很麻烦,可以使用 typedef 来分配别名 -
typedef struct struct_type ALIAS;
示例
在此示例中,我们定义一个结构类型,然后使用typedef关键字为其设置别名 -
#include <stdio.h>
int main() {
typedef unsigned long int ULONG;
typedef short int SHORT;
struct mystruct {
ULONG a;
SHORT b;
};
typedef struct mystruct STR;
STR s1 = {10, 20};
printf("%ld %u", s1.a, s1.b);
return 0;
}
输出
运行代码并检查其输出 −
10 20
还有一种替代方法,即使用typedef关键字。我们可以将其组合到结构体定义中,如下所示 -
typedef struct mystruct {
ULONG a;
SHORT b;
} STR;
STR s1 = {10, 20};
结构体指针的 Typedef
typedef 关键字也可用于为任何指针类型分配新的标识符。通常,我们声明一个指针变量如下:
struct mystruct * x;
我们也可以如下使用 typedef 关键字:
typedef struct mystruct {
ULONG a;
SHORT b;
} STR;
typedef STR * strptr;
它允许您以更简洁的方式声明此类型的指针 -
strptr ptr;
然后,我们可以将相应的struct变量的地址赋值给该指针。
示例
以下示例展示了如何使用typedef创建结构体指针 -
#include <stdio.h>
int main() {
typedef unsigned long int ULONG;
typedef short int SHORT;
typedef struct mystruct {
ULONG a;
SHORT b;
} STR;
STR s1 = {10, 20};
typedef STR * strptr;
strptr ptr = &s1;
printf("%d %d
", s1.a, s1.b);
printf("%d %d", ptr->a, ptr->b);
return 0;
}
输出
运行此代码时,将产生以下输出 -
10 20 10 20
联合的 Typedef
我们可以使用 typedef 关键字为任何 联合 类型分配快捷别名。
示例
以下示例说明如何使用 typedef 创建联合 -
#include <stdio.h>
int main() {
typedef unsigned long int ULONG;
typedef short int SHORT;
typedef union myunion {
char a;
int b;
double c;
} UNTYPE;
UNTYPE u1;
u1.c = 65.50;
typedef UNTYPE * UNPTR;
UNPTR ptr = &u1;
printf("a:%c b: %d c: %lf
", u1.a, u1.b, u1.c);
printf("a:%c b: %d c: %lf
", ptr->a, ptr->b, ptr->c);
return 0;
}
输出
运行代码并检查其输出 −
a: b: 0 c: 65.500000 a: b: 0 c: 65.500000
C 语言中的 typedef 与 #define
typedef 关键字经常与 #define 指令混淆。在 C 语言中,#define 是一个预处理器指令。这是一种定义常量的有效方法。
使用 #define 的语法如下 -
#define name value
例如 -
#define PI 3.14159265359
#define 语句也可用于定义宏 -
#define SQUARE(x) x*x
宏的工作方式类似于函数。但是,调用时会在预处理器级别替换该值。
printf("%d", SQUARE(5));
#define 是一个预处理器指令,而 typedef 会在编译时进行求值。
- typedef 仅限于为类型提供符号名称。#define 也可用于为值定义别名。例如,您可以将"1"定义为"ONE"。
- typedef 的解释由编译器执行,而 #define 语句由预处理器处理。
示例
在下面的代码中,我们同时使用了这两个功能(typedef 和 #define)-
#include <stdio.h>
#define MAX 10
int main() {
typedef unsigned long int ULONG;
typedef short int SHORT;
typedef struct employee {
char name[MAX];
int age;
} EMP;
EMP e1 = {"Krishna", 25};
printf("Name: %s
Age: %d", e1.name, e1.age);
return 0;
}
输出
运行此代码时,将产生以下输出 -
Name: Krishna Age: 25
C 语言中的输入和输出函数
读取用户的输入并将其显示在控制台(输出)上是每个 C 程序都需要的常见任务。C 语言提供了包含各种输入和输出函数的库(头文件)。在本教程中,我们将学习不同类型的格式化和非格式化输入和输出函数。
C 语言中的标准文件
C 语言将所有设备视为文件。因此,诸如"显示器"之类的设备的寻址方式与"文件"相同。
程序执行时会自动打开以下三个文件,以提供对键盘和屏幕的访问。
| 标准文件 | 文件 | 设备 |
|---|---|---|
| 标准输入 | stdin | 键盘 |
| 标准输出 | stdout | 屏幕 |
| 标准错误 | stderr | 您的屏幕 |
为了访问文件,C 使用预定义的 FILE 结构类型来引用文件以进行读写。阅读本章以了解如何从屏幕读取值以及如何在屏幕上打印结果。
输入和输出函数的类型
C 语言中有以下几类 IO 函数 -
- 非格式化字符 IO 函数:getchar() 和 putchar()
- 非格式化字符串 IO 函数:gets() 和 puts()
- 格式化 IO 函数:scanf() 和 printf()
非格式化 I/O 函数以字节流的形式读取和写入数据,没有任何格式;而格式化 I/O 函数则使用预定义的格式(例如"%d"、"%c"或"%s")从流中读取和写入数据。
非格式化字符输入 &输出函数:getchar() 和 putchar()
这两个函数分别从键盘接受单个字符作为输入,并在输出终端上显示单个字符。
getchar() 函数读取单个按键,无需 Enter 键。
int getchar(void)
无需任何参数。该函数返回一个整数,该整数对应于用户输入的字符键的 ASCII 值。
示例 1
以下程序将单个按键读入 char 变量 -
#include <stdio.h>
int main() {
char ch;
printf("Enter a character: ");
ch = getchar();
puts("You entered: ");
putchar(ch);
return 0;
}
输出
运行代码并检查其输出 −
Enter a character: W You entered: W
示例 2
以下程序展示了如何读取一系列字符,直到用户按下 Enter 键 -
#include <stdio.h>
int main() {
char ch;
char word[10];
int i = 0;
printf("Enter characters. End with pressing enter: ");
while(1) {
ch = getchar();
word[i] = ch;
if (ch == '
')
break;
i++;
}
printf("
You entered the word: %s", word);
return 0;
}
输出
运行代码并检查其输出 −
Enter characters. End with pressing enter: Hello You entered the word: Hello
您还可以使用未格式化的putchar() 函数来打印单个字符。C 库函数"int putchar(int char)"将参数 char 指定的字符(无符号char)写入stdout。
int putchar(int c)
此函数的单个参数是要写入的字符。您也可以传递其 ASCII 等效整数。此函数返回写入的字符,该字符以无符号 char 形式转换为int,如果出错则返回 EOF。
示例 3
以下示例展示了如何使用 putchar() 函数 -
#include <stdio.h>
int main() {
char ch;
for(ch = 'A' ; ch <= 'Z' ; ch++) {
putchar(ch);
}
return(0);
}
输出
运行此代码时,将产生以下输出 -
ABCDEFGHIJKLMNOPQRSTUVWXYZ
格式化字符串输入和输出函数:gets()、fgets()、puts() 和 fputs()
char *gets(char *str) 函数从 stdin 读取一行数据到 str 指向的缓冲区,直到遇到终止换行符或 EOF(文件结束符)。
char *gets (char *str)
此函数只有一个参数。它是一个指向字符数组的指针,用于存储 C 字符串。函数成功时返回"str",出错时或发生 EOF 且未读取任何字符时返回 NULL。
示例
请看以下示例 -
#include <stdio.h>
int main() {
char name[20];
printf("Enter your name: ");
gets(name);
printf("You entered the name: %s", name);
return 0;
}
输出
Enter your name: Ravikant Soni You entered the name: Ravikant Soni
scanf("%s") 读取字符,直到遇到空格(空格、制表符、换行符等)或 EOF。因此,如果您尝试输入包含多个单词(以空格分隔)的字符串,它会将第一个空格之前的字符作为字符串的输入。
fgets() 函数
在较新版本的 C 语言中,gets() 已被弃用,因为它是一个潜在的危险函数,因为它不执行边界检查,可能会导致缓冲区溢出。
建议使用 fgets() 函数 −
fgets(char arr[], size, stream);
fgets() 可用于接受来自任何输入流的输入,例如 stdin(键盘)或 FILE(文件流)。
示例 1
以下程序展示了如何使用 fgets() 接受来自用户的多字输入 -
#include <stdio.h>
int main () {
char name[20];
printf("Enter a name:
");
fgets(name, sizeof(name), stdin);
printf("You entered:
");
printf("%s", name);
return 0;
}
输出
运行代码并检查其输出 −
Enter a name: Rakesh Sharma You entered: Rakesh Sharma
函数"int puts (const char *str)"将字符串"s"及其结尾的换行符写入stdout。
int puts(const char *str)
参数str是要写入的 C 字符串。如果成功,则返回非负值。如果出错,则返回 EOF。
我们可以使用带有 %s 说明符的 printf() 函数来打印字符串。我们也可以使用 puts() 函数(在 C11 和 C17 版本中已弃用)或 fputs() 函数 作为替代方案。
示例 2
以下示例展示了 puts() 和 fputs() 之间的区别 -
#include <stdio.h>
int main () {
char name[20] = "Rakesh Sharma";
printf("With puts():
");
puts(name);
printf("
With fputs():
");
fputs(name, stdout);
return 0;
}
输出
运行代码并检查其输出 −
With puts(): Rakesh Sharma With fputs(): Rakesh Sharma
格式化输入 &输出函数:scanf() 和 printf()
scanf() 函数从标准输入流 stdin 读取输入,并根据提供的格式扫描该输入 -
int scanf(const char *format, ...)
printf() 函数将输出写入标准输出流 stdout,并根据提供的格式生成输出。
int printf(const char *format, ...)
格式可以可以是一个简单的常量字符串,但您可以指定 %s、%d、%c、%f 等,分别用于打印或读取字符串、整数、字符或浮点数。还有许多其他可用的格式化选项,可根据具体需求使用。
C 语言中的格式说明符
CPU 以流式方式对输入和输出设备执行 IO 操作。通过标准输入流从标准输入设备(键盘)读取的数据称为 stdin。同样,通过标准输出设备发送到标准输出(计算机显示屏)的数据称为 stdout。
计算机以文本形式从流中接收数据,但您可能希望将其解析为不同类型的变量,例如 int、float 或字符串。同样,存储在 int、float 或 char 变量中的数据必须以文本格式发送到输出流。格式说明符正是用于此目的。
ANSI C 定义了许多格式说明符。下表列出了不同的说明符及其用途。
| 格式说明符 | 类型 |
|---|---|
| %c | 字符 |
| %d | 有符号整数 |
| %e 或 %E | 浮点数的科学计数法 |
| %f | 浮点值 |
| %g 或 %G | 类似于 %e 或 %E |
| %hi | 有符号整数(短整型) |
| %hu | 无符号整数(短整型) |
| %i | 无符号整数 |
| %l 或 %ld 或 %li | 长整型 |
| %lf | 双精度型 |
| %Lf | 长双精度型 |
| %lu | 无符号整数或无符号长整型 |
| %lli 或%lld | 长整型 |
| %llu | 无符号长整型 |
| %o | 八进制表示 |
| %p | 指针 |
| %s | 字符串 |
| %u | 无符号整型 |
| %x 或 %X | 十六进制表示 |
减号 () 表示左对齐。"%"后面的数字指定最小字段宽度。如果字符串小于该宽度,则会用空格填充。句点 (.) 用于分隔字段宽度和精度。
示例
以下示例演示了格式说明符的重要性 -
#include <stdio.h>
int main(){
char str[100];
printf("Enter a value: ");
gets(str);
printf("
You entered: ");
puts(str);
return 0;
}
输出
当上述代码编译并执行时,它会等待您输入一些文本。当您输入文本并按下 Enter 键时,程序将继续读取输入并显示如下内容 -
Enter a value: seven 7 You entered: seven 7
这里需要注意的是,scanf() 函数要求输入的格式与您提供的"%s"和"%d"相同,这意味着您必须提供有效的输入,例如"一个字符串后跟一个整数"。如果您提供两个连续的字符串"string string"或两个连续的整数"integer integer",则会被视为一组错误的输入。
其次,在读取字符串时,scanf() 函数一旦遇到"空格"就会停止读取,因此对于 scanf() 函数来说,字符串"This is Test"实际上是三个字符串的组合。
C 语言文件处理
C 语言文件处理
C 语言文件处理是指使用 C 语言函数执行文件操作(例如创建、打开、写入数据、读取数据、重命名和删除)的过程。借助这些函数,我们可以在程序中执行文件操作,在文件中存储和检索数据。
C 语言文件处理的必要性
如果我们使用 C 语言程序执行输入和输出操作,则只要程序运行,数据就会存在;程序终止后,我们就无法再次使用该数据。文件处理用于处理存储在外部存储器中的文件,即在计算机的外部存储器中存储和访问信息。您可以使用文件处理永久保存数据。
文件类型
文件表示一个字节序列。文件有两种类型:文本文件和二进制文件 -
- 文本文件 - 文本文件以 ASCII 字符的形式包含数据,通常用于存储字符流。文本文件中的每一行都以换行符(" ")结尾,并且通常以".txt"为扩展名。
- 二进制文件 - 二进制文件以原始位(0 和 1)的形式包含数据。不同的应用程序对位和字节的表示方式不同,并使用不同的文件格式。图像文件(.png、.jpg)、可执行文件(.exe、.com)等都是二进制文件的示例。
FILE 指针 (File*)
使用文件处理时,需要一个文件指针来存储 fopen() 函数返回的 FILE 结构的引用。所有文件处理操作都需要该文件指针。
fopen() 函数返回一个 FILE 类型的指针。 FILE 是 stdio.h 中预定义的结构体类型,包含文件描述符、大小、位置等属性。
typedef struct {
int fd; /* 文件描述符 */
unsigned char *buf; /* 缓冲区 */
size_t size; /* 文件大小 */
size_t pos; /* 文件中的当前位置 */
} FILE;
声明文件指针 (FILE*)
以下是声明文件指针的语法 -
FILE* file_pointer;
打开(创建)文件
任何操作都必须打开文件。fopen() 函数用于创建新文件或打开现有文件。您需要指定要打开的模式。下文介绍了各种文件打开模式,创建/打开文件时可以使用其中任何一种。
fopen() 函数返回一个 FILE 指针,该指针可用于其他操作,例如读取、写入和关闭文件。
语法
以下是打开文件的语法 -
FILE *fopen(const char *filename, const char *mode);
其中,filename 是要打开的文件的名称,mode 定义文件的打开模式。
文件打开模式
默认情况下,文件访问模式以文本或 ASCII 模式打开文件。如果您要处理二进制文件,则应使用以下访问模式,而不是上述模式:
"rb", "wb", "ab", "rb+", "r+b", "wb+", "w+b", "ab+", "a+b"
文件可以使用多种模式打开。以下是不同的文件打开模式 -
| 模式 | 描述 |
|---|---|
| r | 打开现有文本文件进行读取。 |
| w | 打开文本文件进行写入。如果文件不存在,则创建一个新文件。此处,程序将从文件开头开始写入内容。 |
| a | 以追加模式打开一个文本文件进行写入。如果文件不存在,则创建一个新文件。此处,程序将开始在现有文件内容中追加内容。 |
| r+ | 打开一个文本文件进行读写操作。 |
| 打开一个文本文件进行读写操作。如果文件存在,则首先将其长度截断为零;如果文件不存在,则创建一个文件。 | |
| a+ | 打开一个文本文件进行读写操作。如果文件不存在,则创建该文件。读取操作将从头开始,但写入操作只能追加。 |
创建文件示例
在下面的示例中,我们将创建一个新文件。创建新文件的文件模式为"w"(写入模式)。
#include <stdio.h>
int main() {
FILE * file;
// 创建文件
file = fopen("file1.txt", "w");
// 检查文件是否已创建
if (file == NULL) {
printf("Error in creating file");
return 1;
}
printf("File created.");
return 0;
}
输出
File created.
打开文件示例
以下示例中,我们将打开一个现有文件。打开现有文件的文件模式为"r"(只读)。您也可以使用上面介绍的其他文件打开模式选项。
注意:必须有一个要打开的文件。
#include <stdio.h>
int main() {
FILE * file;
// 打开文件
file = fopen("file1.txt", "r");
// 检查文件是否已打开
if (file == NULL) {
printf("Error in opening file");
return 1;
}
printf("File opened.");
return 0;
}
输出
File opened.
关闭文件
每个文件在执行操作后都必须关闭。fclose() 函数 用于关闭已打开的文件。
语法
以下是 fclose() 函数的语法 -
int fclose(FILE *fp);
fclose() 函数在成功时返回零,如果关闭文件时出错,则返回 EOF。
fclose() 函数实际上会将缓冲区中所有待处理的数据刷新到文件中,关闭文件并释放文件占用的内存。 EOF 是头文件 stdio.h 中定义的常量。
关闭文件示例
在以下示例中,我们将关闭一个打开的文件 -
#include <stdio.h>
int main() {
FILE * file;
// 打开文件
file = fopen("file1.txt", "w");
// 检查文件是否已打开
// 是否已打开
if (file == NULL) {
printf("Error in opening file");
return 1;
}
printf("File opened.");
// 关闭文件
fclose(file);
printf("
File closed.");
return 0;
}
输出
File opened. File closed.
写入文本文件
以下库函数用于将数据写入以可写模式打开的文件中 -
- fputc():将单个字符写入文件。
- fputs():将字符串写入文件。
- fprintf():将格式化的字符串(数据)写入文件。
将单个字符写入文件
fputc() 函数是一个非格式化函数,它将参数"c"的单个字符值写入"fp"引用的输出流。
int fputc(int c, FILE *fp);
示例
以下代码将给定字符数组中的一个字符写入以"w"模式打开的文件中:
#include <stdio.h>
int main() {
FILE *fp;
char * string = "C Programming tutorial from TutorialsPoint";
int i;
char ch;
fp = fopen("file1.txt", "w");
for (i = 0; i < strlen(string); i++) {
ch = string[i];
if (ch == EOF)
break;
fputc(ch, fp);
}
printf ("
");
fclose(fp);
return 0;
}
输出
After executing the program, "file1.txt" will be created in the current folder and the string is written to it.
将字符串写入文件
fputs() 函数将字符串"s"写入"fp"引用的输出流。成功时返回非负值,否则返回 EOF(文件尾)。
int fputs(const char *s, FILE *fp);
示例
以下程序将给定二维 char 数组中的字符串写入文件 -
#include <stdio.h>
int main() {
FILE *fp;
char *sub[] = {"C Programming Tutorial
", "C++ Tutorial
", "Python Tutorial
", "Java Tutorial
"};
fp = fopen("file2.txt", "w");
for (int i = 0; i < 4; i++) {
fputs(sub[i], fp);
}
fclose(fp);
return 0;
}
输出
程序运行时,在当前文件夹中创建一个名为"file2.txt"的文件并保存以下行 -
C Programming Tutorial C++ Tutorial Python Tutorial Java Tutorial
将格式化字符串写入文件
fprintf() 函数将格式化的数据流发送到 FILE 指针所指向的磁盘文件。
int fprintf(FILE *stream, const char *format [, argument, ...])
示例
在下面的程序中,我们有一个名为"employee"的结构体类型数组。该结构体包含一个字符串、一个整数和一个浮点数元素。使用 fprintf() 函数将数据写入文件。
#include <stdio.h>
struct employee {
int age;
float percent;
char *name;
};
int main() {
FILE *fp;
struct employee emp[] = {
{25, 65.5, "Ravi"},
{21, 75.5, "Roshan"},
{24, 60.5, "Reena"}
};
char *string;
fp = fopen("file3.txt", "w");
for (int i = 0; i < 3; i++) {
fprintf(fp, "%d %f %s
", emp[i].age, emp[i].percent, emp[i].name);
}
fclose(fp);
return 0;
}
输出
When the above program is executed, a text file is created with the name "file3.txt" that stores the employee data from the struct array.
从文本文件读取
以下库函数可用于从以读取模式打开的文件中读取数据 -
- fgetc():从文件中读取单个字符。
- fgets():从文件中读取字符串。
- fscanf():从文件中读取格式化字符串。
从文件中读取单个字符
fgetc() 函数从"fp"引用的输入文件中读取一个字符。返回值是读取到的字符,如果发生任何错误,则返回 EOF。
int fgetc(FILE * fp);
示例
以下示例逐个字符地读取给定文件,直至到达文件末尾。
#include <stdio.h>
int main(){
FILE *fp ;
char ch ;
fp = fopen ("file1.txt", "r");
while(1) {
ch = fgetc (fp);
if (ch == EOF)
break;
printf ("%c", ch);
}
printf ("
");
fclose (fp);
}
输出
运行代码并检查其输出 −
C Programming tutorial from TutorialsPoint
从文件读取字符串
fgets() 函数从"fp"引用的输入流中读取最多"n 1"个字符。它将读取的字符串复制到缓冲区"buf"中,并在其后附加一个空字符以终止字符串。
示例
以下程序读取给定文件中的每一行,直到检测到文件末尾为止 -
# include <stdio.h>
int main() {
FILE *fp;
char *string;
fp = fopen ("file2.txt", "r");
while (!feof(fp)) {
fgets(string, 256, fp);
printf ("%s", string) ;
}
fclose (fp);
}
输出
运行代码并检查其输出 −
C Programming Tutorial C++ Tutorial Python Tutorial Java Tutorial
从文件读取格式化字符串
C 语言中的 fscanf() 函数 用于从文件读取格式化输入。
int fscanf(FILE *stream, const char *format, ...)
示例
在下面的程序中,我们使用 fscanf() 函数读取不同类型变量中的格式化数据。常用的格式说明符用于指示字段类型(%d、%f、%s 等)。
#include <stdio.h>
int main() {
FILE *fp;
char *s;
int i, a;
float p;
fp = fopen ("file3.txt", "r");
if (fp == NULL) {
puts ("Cannot open file"); return 0;
}
while (fscanf(fp, "%d %f %s", &a, &p, s) != EOF)
printf ("Name: %s Age: %d Percent: %f
", s, a, p);
fclose(fp);
return 0;
}
输出
上述程序执行后,会打开文本文件"file3.txt",并将其内容打印在屏幕上。运行代码后,您将获得如下输出:
Name: Ravi Age: 25 Percent: 65.500000 Name: Roshan Age: 21 Percent: 75.500000 Name: Reena Age: 24 Percent: 60.500000
文件处理二进制读写函数
对于二进制文件,读写操作以二进制形式进行。您需要在访问模式中包含字符"b"(写入二进制文件时使用"wb",读取二进制文件时使用"rb")。
有两个函数可用于二进制输入和输出:fread() 函数和 fwrite() 函数。这两个函数都可用于读写内存块,通常是数组或结构体。
写入二进制文件
fwrite() 函数将指定的字节块从缓冲区写入以二进制写入模式打开的文件。以下是该函数的原型:
fwrite(*buffer, size, no, FILE);
示例
在下面的程序中,声明了一个名为"employee"的结构体类型数组。我们使用 fwrite() 函数将一个字节块(大小相当于一个 employee 数据)写入以"wb"模式打开的文件中。
#include <stdio.h>
struct employee {
int age;
float percent;
char name[10];
};
int main() {
FILE *fp;
struct employee e[] = {
{25, 65.5, "Ravi"},
{21, 75.5, "Roshan"},
{24, 60.5, "Reena"}
};
char *string;
fp = fopen("file4.dat", "wb");
for (int i = 0; i < 3; i++) {
fwrite(&e[i], sizeof (struct employee), 1, fp);
}
fclose(fp);
return 0;
}
输出
When the above program is run, the given file will be created in the current folder. It will not show the actual data, because the file is in binary mode.
读取二进制文件
fread() 函数 从以二进制读取模式打开的文件中读取指定大小的字节块,并将其保存到指定大小的缓冲区中。以下是该函数的原型:
fread(*buffer, size, no, FILE);
示例
在下面的程序中,声明了一个名为"employee"的结构体类型数组。我们使用 fread() 函数从以"rb"模式打开的文件中读取一个字节块,该字节块的大小相当于一个 employee 数据的大小。
#include <stdio.h>
struct employee {
int age;
float percent;
char name[10];
};
int main() {
FILE *fp;
struct employee e;
fp = fopen ("file4.dat", "rb");
if (fp == NULL) {
puts ("Cannot open file");
return 0;
}
while (fread (&e, sizeof (struct employee), 1, fp) == 1)
printf ("Name: %s Age: %d Percent: %f
", e.name, e.age, e.percent);
fclose(fp);
return 0;
}
输出
上述程序执行后,会打开文件"file4.dat",并将其内容打印在屏幕上。运行代码后,您将获得如下输出:
Name: Ravi Age: 25 Percent: 65.500000 Name: Roshan Age: 21 Percent: 75.500000 Name: Reena Age: 24 Percent: 60.500000
重命名文件
rename() 函数用于将现有文件从旧文件名重命名为新文件名。
语法
以下是重命名文件的语法 -
int rename(const char *old_filename, const char *new_filename)
示例
#include <stdio.h>
int main() {
// 旧文件名和新文件名
char * file_name1 = "file1.txt";
char * file_name2 = "file2.txt";
// 将旧文件名重命名为新文件名
if (rename(file_name1, file_name2) == 0) {
printf("File renamed successfully.
");
} else {
perror("There is an error.");
}
return 0;
}
输出
如果有可用的文件(file1.txt),则输出如下 -
Name: Ravi Age: 25 Percent: 65.500000 Name: Roshan Age: 21 Percent: 75.500000 Name: Reena Age: 24 Percent: 60.500000
C 语言中的预处理器
C 预处理器不是编译器的一部分,而是编译过程中的一个独立步骤。简单来说,C 预处理器只是一个文本替换工具,它指示编译器在实际编译之前进行必要的预处理。我们将 C 预处理器称为 CPP。
在 C 语言编程中,预处理是 C 代码编译的第一步。它发生在标记化步骤之前。预处理器的一个重要功能是包含包含程序中使用的库函数的头文件。C 语言中的预处理器还定义常量并扩展宏。
C 语言中的预处理器语句称为指令。程序的预处理器部分始终位于 C 代码的顶部。每个预处理器语句都以井号 (#) 开头。
C 语言中的预处理器指令
下表列出了所有重要的预处理器指令 -
| 指令 | 描述 |
|---|---|
| # Define | 替换预处理器宏。 |
| # Include | 插入来自另一个文件的特定头文件。 |
| # Undef | 取消定义预处理器宏。 |
| #ifdef | 如果此宏已定义,则返回 true。 |
| #ifndef | 如果此宏未定义,则返回 true。 |
| #if | 测试编译时条件是否为真。 |
| #else | #if 的替代方案。 |
| #elif | #else 和 #if 合二为一语句。 |
| #endif | 结束预处理器条件。 |
| #error | 在 stderr 上打印错误消息。 |
| #pragma | 使用标准化方法向编译器发出特殊命令。 |
预处理器示例
分析以下示例以理解各种指令。
此 #define 指令指示 CPP 将 MAX_ARRAY_LENGTH 的实例替换为 20。使用 #define 常量可提高可读性。
#define MAX_ARRAY_LENGTH 20
以下指令指示 CPP 从系统库中获取"stdio.h"并将文本添加到当前源文件中。下一行指示 CPP 从本地目录中获取"myheader.h"并将内容添加到当前源文件中。
#include <stdio.h> #include "myheader.h"
现在,请看一下以下 #define 和 #undef 指令。它们指示 CPP 取消定义现有的 FILE_SIZE,并将其定义为 42。
#undef FILE_SIZE #define FILE_SIZE 42
以下指令指示 CPP 仅在 MESSAGE 尚未定义时定义 MESSAGE。
#ifndef MESSAGE #define MESSAGE "You wish!" #endif
如果定义了 DEBUG,则以下指令告诉 CPP 处理所附的语句。
#ifdef DEBUG /* Your debugging statements here */ #endif
如果您在编译时将 -DDEBUG 标志传递给 gcc 编译器,这将非常有用。这将定义 DEBUG,以便您可以在编译过程中动态地打开或关闭调试功能。
C 语言中的预定义宏
ANSI C 定义了许多宏。虽然每个宏都可以在编程中使用,但不应直接修改预定义的宏。
| 宏 | 描述 |
|---|---|
| __DATE__ | 以字符形式表示的当前日期,格式为"MMM DD YYYY"。 |
| __TIME__ | 以字符形式表示的当前时间,格式为"HH:MM:SS"。 |
| __FILE__ | 包含当前文件名的字符串字面量。 |
| __LINE__ | 包含当前行号的十进制常量。 |
| __STDC__ | 当编译器符合 ANSI 标准时,定义为 1。 |
示例
让我们尝试以下示例 -
#include <stdio.h>
int main(){
printf("File: %s
", __FILE__ );
printf("Date: %s
", __DATE__ );
printf("Time: %s
", __TIME__ );
printf("Line: %d
", __LINE__ );
printf("ANSI: %d
", __STDC__ );
}
输出
运行此代码时,将产生以下输出 -
File: main.c Date: Mar 6 2024 Time: 13:32:30 Line: 8 ANSI: 1
预处理器运算符
C 预处理器提供以下运算符来帮助创建宏 -
示例:C 中的宏延续运算符 (\)
宏通常限制在一行中。宏延续运算符 (\) 用于延续过长而无法在一行中显示的宏。请看以下示例 -
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!
")
int main() {
message_for(Ram, Raju);
}
输出
运行此代码时,将产生以下输出 -
Ram and Raju: We love you!
示例:C 语言中的字符串化运算符 (#)
字符串化运算符 (#),也称为数字符号运算符,在宏定义中使用时,可将宏参数转换为字符串常量。
字符串化运算符只能在具有指定参数或参数列表的宏中使用。例如 -
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!
")
int main() {
message_for(Carole, Debra);
return 0;
}
输出
运行代码并检查其输出 −
Carole and Debra: We love you!
示例:C 语言中的标记粘贴运算符 (##)
宏定义中的标记粘贴运算符 (##) 可合并两个参数。它允许将宏定义中的两个独立标记合并为一个标记。例如 -
#include <stdio.h>
#define tokenpaster(n) printf ("token" #n " = %d", token##n)
int main() {
int token34 = 40;
tokenpaster(34);
return 0;
}
输出
运行此代码时,将产生以下输出 -
token34 = 40
示例:C 语言中的 Defined() 运算符
预处理器 Defined 运算符用于常量表达式中,用于判断标识符是否已使用 #define 定义。如果指定的标识符已定义,则值为 True(非零)。如果符号未定义,则值为 false(零)。
以下示例展示了如何在 C 程序中使用 defined 运算符 -
#include <stdio.h>
#if !defined (MESSAGE)
#define MESSAGE "You wish!"
#endif
int main() {
printf("Here is the message: %s
", MESSAGE);
return 0;
}
输出
运行代码并检查其输出 −
Here is the message: You wish!
C 语言中的参数化宏
CPP 的强大功能之一是能够使用参数化宏模拟函数。例如,我们可能有一些代码用于计算数字的平方,如下所示 -
int square(int x) {
return x * x;
}
我们可以使用宏重写上述代码,如下所示 -
#define square(x) ((x) * (x))
带有参数的宏必须先使用 #define 指令定义,然后才能使用。参数列表括在括号中,并且必须紧跟在宏名称之后。宏名和左括号之间不允许有空格。
示例
以下示例演示了如何在 C 中使用参数化宏 -
#include <stdio.h>
#define MAX(x,y) ((x) > (y) ? (x) : (y))
int main() {
printf("Max between 20 and 10 is %d
", MAX(10, 20));
return 0;
}
输出
运行此代码时,将产生以下输出 -
Max between 20 and 10 is 20
C 语言中的头文件
#include 预处理器指令用于将一个文件(通常称为头文件)中函数、常量和宏等的定义引入另一个 C 代码中。头文件的扩展名为".h",您可以从中引入一个或多个预定义函数、常量、宏等的前向声明。C 语言提供头文件有助于程序的模块化设计。
系统头文件
C 编译器软件捆绑了许多预编译的头文件。这些文件称为系统头文件。一个著名的例子是"stdio.h",几乎每个 C 程序都包含这个头文件。
每个系统头文件都包含许多实用函数。这些函数通常被称为库函数。例如,执行 IO 操作所需的 printf() 和 scanf() 函数就是"stdio.h"头文件中提供的库函数。
加载一个或多个头文件的预处理语句始终位于 C 代码的开头。我们从一个基本的"Hello World"程序开始学习 C 语言编程,首先要包含"stdio.h"文件。-
#include <stdio.h>
int main() {
/* 我的第一个 C 语言程序 */
printf("Hello, World!
");
return 0;
}
C 预处理指令 #include 本质上是请求编译器加载特定头文件的内容,以便程序可以使用它们。
C 或 C++ 程序中的常见做法是将所有常量、宏、系统全局变量和函数原型保存在头文件中,并在需要时包含该头文件。
C 语言中包含头文件的语法
使用 #include 指令 加载头文件。其使用方法如下:
#include <filename.h>
如果头文件位于 system/default 目录中,则将其名称放在尖括号内。
#include "filename.h"
如果头文件位于与源文件相同的目录中,则将用户定义或非标准头文件的名称放在双引号内。
#include 指令的工作原理是指示 C 预处理器 在继续处理当前源文件的其余部分之前,先扫描指定的文件作为输入。预处理器的输出包含已生成的输出、包含文件的输出以及 #include 指令后文本的输出。
C 语言中的标准头文件
典型的 C 编译器捆绑了许多预编译的头文件。每个头文件都包含一组预定义的标准库函数。"#include"预处理指令用于在程序中包含扩展名为".h"的头文件。
下表列出了 C 语言中的一些头文件 -
| 头文件 | 描述 | 函数/宏/变量 |
|---|---|---|
| stdio.h | 输入/输出函数 | scanf()、printf()、fopen()、FILE |
| stdlib.h | 通用函数 | atoi()、atof()、malloc() |
| math.h | 数学函数 | sin()、cos()、pow()、sqrt() |
| string.h | 字符串函数 | strcpy()、strlen()、strcat() |
| ctype.h | 字符处理函数 | isalpha()、isupper()、 ispunct() |
| time.h | 日期和时间函数 | asctime()、gmtime()、mktime() |
| float.h | 浮点类型的限制 | FLT_ROUNDS、FLT_RADIX |
| limits.h | 基本类型的大小 | CHAR_BIT、CHAR_MIN、CHAR_MAX |
| wctype.h | 用于确定宽字符数据中包含的类型的函数。 | iswalpha()、iswctype()、iswupper() |
示例
以下代码使用了一些头文件中的库函数 -
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
int main() {
char s1[20] = "53875";
char s2[10] = "Hello";
char s3[10] = "World";
int res;
res = pow(8, 4);
printf("Using math.h, The value is : %d
", res);
long int a = atol(s1);
printf("Using stdlib.h, the string to long int: %d
", a);
strcpy(s2, s3);
printf("Using string.h, the strings s2 and s3: %s %s
", s2, s3);
return 0;
}
输出
运行此代码时,将产生以下输出 -
Using math.h, The value is: 4096 Using stdlib.h, the string to long int: 53875 Using string.h, the strings s2 and s3: World World
用户定义的头文件
我们可以在 C 程序中添加一个或多个用户定义的函数(除了 main() 函数)。但是,如果代码包含大量函数定义,将它们放在一个以".c"为扩展名的源代码文件中会变得难以处理和维护。因此,类似性质的函数/宏/变量会被集中到头文件中,像包含标准头文件一样包含它们,并调用其中定义的函数。
用户定义的头文件通常与 C 源代码位于同一目录中。
使用 CodeBlocks IDE 创建和使用头文件的步骤如下所述。启动 CodeBlocks IDE 并创建一个新的控制台应用程序 -
为项目选择一个合适的名称。在文件夹中添加一个新的空文件,并将以下代码保存为 "myheader.h" -
#ifndef MYHEADER_H #define MYHEADER_H void sayHello(); int add(int a, int b); double area(double radius); int length(char *x); #endif
如果一个头文件被包含两次,编译器将对其内容进行两次处理,从而导致错误。防止这种情况的标准方法是将文件的全部实际内容用 #ifndef 指令 的条件定义括起来,这被称为 头文件保护。
头文件保护会检查头文件是否已定义。如果未定义,则表示该文件是首次被包含,并且会执行保护内的代码。
头文件包含要包含的函数的前向声明或原型。这些函数的实际定义位于与头文件同名的".c"文件中。
创建头文件
将以下代码保存在"myheader.c"文件中 -
#include <stdio.h>
#include <string.h>
#include <math.h>
#define PI 3.142
void sayHello(){
printf("Hello World
");
}
int add(int a, int b){
int result;
result = a+b;
return result;
}
double area(double radius){
double areaofcircle = PI*pow(radius, 2);
return areaofcircle;
}
int length(char *x){
return strlen(x);
}
使用头文件
现在我们可以在程序中包含"myheader.h"文件并调用上述任何函数。将以下代码保存为项目文件夹中的"main.c"。
#include <stdio.h>
#include "myheader.h"
int main() {
int p = 10, q = 20;
double x = 5.25;
sayHello();
printf("sum of %d and %d is %d
", p, q, add(p,q));
printf("Radius: %lf Area: %lf", x, area(x));
return 0;
}
构建项目并运行"main.c",可以从 CodeBlocks IDE 的运行菜单或命令行运行,以获得以下结果 -
Hello World sum of 10 and 20 is 30 Radius: 5.250000 Area: 86.601375
计算包含
有时需要从多个不同的头文件中选择一个包含到程序中。例如,它们可能指定在不同类型的操作系统上使用的配置参数。您可以使用一系列条件语句来实现这一点,如下所示 -
#if SYSTEM_1 # include "system_1.h" #elif SYSTEM_2 # include "system_2.h" #elif SYSTEM_3 ... #endif
但随着文件规模的扩大,它变得繁琐乏味。为此,预处理器提供了使用宏来指定头文件名称的功能。这被称为计算包含。您无需将头文件名称作为 #include 的直接参数,只需在其中输入一个宏名称即可。-
#define SYSTEM_H "system_1.h" ... #include SYSTEM_H
SYSTEM_H 将被扩展,预处理器将查找 system_1.h,就像 #include 最初就是这样编写的一样。SYSTEM_H 可以在 Makefile 中使用 -D 选项来定义。
C 语言中的类型转换
"类型转换"是指将一种数据类型转换为另一种数据类型。它也称为"类型转换"。有时,编译器会自行执行转换(隐式类型转换),以使数据类型相互兼容。
在其他情况下,C 编译器会强制执行类型转换(显式类型转换),这是由类型转换运算符引起的。例如,如果您想将"long"值存储为一个简单的整数,则可以将"long"类型转换为"int"。
您可以使用类型转换运算符将值从一种类型显式转换为另一种类型 -
(type_name) expression
示例 1
请考虑以下示例 -
#include <stdio.h>
int main() {
int sum = 17, count = 5;
double mean;
mean = sum / count;
printf("Value of mean: %f
", mean);
}
输出
运行代码并检查其输出 −
Value of mean: 3.000000
我们预期结果为 17/5,即 3.4,但结果却显示为 3.000000,因为除法表达式中的两个操作数均为 int 类型。
示例 2
在 C 语言中,除法运算的结果始终采用字节长度较大的数据类型。因此,我们必须将其中一个整数操作数强制转换为 float 类型。
强制类型转换运算符使一个整数变量除以另一个整数变量的操作执行浮点运算 -
#include <stdio.h>
int main() {
int sum = 17, count = 5;
double mean;
mean = (double) sum / count;
printf("Value of mean: %f
", mean);
}
Output
当编译并执行上述代码时,它会产生以下结果 -
Value of mean: 3.400000
需要注意的是,强制类型转换运算符的优先级高于除法,因此 sum 的值首先被转换为 double 类型,最后除以 count 得到一个 double 值。
类型转换可以是隐式的,由编译器自动执行,也可以通过使用强制类型转换运算符显式指定。在需要进行类型转换时,使用强制类型转换运算符被认为是良好的编程习惯。
类型提升规则
在执行隐式或自动类型转换时,C 编译器遵循类型提升规则。通常,遵循的原则如下:
- 字节型和短整型值 - 它们会被提升为 int 型。
- 如果一个操作数是 long - 整个表达式会被提升为 long 型。
- 如果一个操作数是 float - 整个表达式会被提升为 float 型。
- 如果任何一个操作数是 double - 结果会被提升为 double 型。
C 语言中的整数提升
整数提升是将小于 int 或 unsigned int 的整数类型值转换为 int 或 unsigned int 的过程。
示例
考虑一个将字符与整数相加的示例:-
#include <stdio.h>
int main() {
int i = 17;
char c = 'c'; /* ASCII 值为 99 */
int sum;
sum = i + c;
printf("Value of sum : %d
", sum);
}
输出
当编译并执行上述代码时,它会产生以下结果 -
Value of sum: 116
此处,sum 的值为 116,因为编译器在执行实际加法运算之前进行了整数提升,并将 'c' 的值转换为 ASCII 码。
常规算术转换
赋值运算符、逻辑运算符 && 和 || 不会执行常规算术转换。
示例
让我们通过以下示例来理解这个概念 -
#include <stdio.h>
int main() {
int i = 17;
char c = 'c'; /* ASCII 值为 99 */
float sum;
sum = i + c;
printf("Value of sum : %f
", sum);
}
输出
当编译并执行上述代码时,它会产生以下结果 -
Value of sum: 116.000000
这里很容易理解,首先 c 被转换为整数,但由于最终值是双精度数,因此应用通常的算术转换,编译器将 i 和 c 转换为"浮点数"并将它们相加,得到"浮点数"结果。
C 语言中的错误处理
因此,C 语言编程不提供对错误处理的直接支持,因为 C 语言中没有关键字可以阻止错误或异常突然终止程序。但是,程序员可以使用其他函数进行错误处理。
您可以使用 errno 在 C 语言中高效地处理错误。此外,其他可用于错误处理的函数包括 perror、strerror、ferror 和 clearererr。
errno 变量
C 是一种系统编程语言。它以返回值的形式提供较低级别的访问。大多数 C 语言甚至 Unix 函数调用在发生任何错误时都会返回 -1 或 NULL,并设置错误代码 errno。它被设置为全局变量,用于指示在任何函数调用期间发生的错误。您可以在
因此,C 程序员可以检查返回值,并根据返回值采取适当的操作。在初始化程序时将 errno 设置为 0 是一个好习惯。值为 0 表示程序中没有错误。
下表列出了 errno 值及其对应的错误消息 -
| errno 值 | 错误 |
|---|---|
| 1 | 操作不允许 |
| 2 | 没有此文件或目录 |
| 3 | 没有此进程 |
| 4 | 系统调用中断 |
| 5 | I/O 错误 |
| 6 | 没有此设备或地址 |
| 7 | 参数列表太长 |
| 8 | 执行格式错误 |
| 9 | 文件编号错误 |
| 10 | 无子进程 |
| 11 | 重试 |
| 12 | 内存不足 |
| 13 | 权限被拒绝 |
示例
请看以下示例 -
#include <stdio.h>
#include <errno.h>
int main() {
FILE* fp;
// 打开不存在的文件
fp = fopen("nosuchfile.txt", "r");
printf("Value of errno: %d
", errno);
return 0;
}
输出
它将产生以下输出 -
Value of errno: 2
C 编程语言提供了 perror() 和 strerror() 函数,可用于显示与 errno 关联的文本消息。
perror() 函数
显示传递给它的字符串,后跟冒号、空格,然后是当前 errno 值的文本表示。
void perror(const char *str);
示例
在上面的例子中,"errno = 2"与消息 No such file or directory 关联,可以使用 perror() 函数打印该消息。
#include <stdio.h>
#include <errno.h>
int main(){
FILE* fp;
// 打开不存在的文件
fp = fopen("nosuchfile.txt", "r");
printf("Value of errno: %d
", errno);
perror("Error message:");
return 0;
}
输出
运行此代码时,将产生以下输出 -
Value of errno: 2 Error message: No such file or directory
strerror() 函数
此函数返回指向当前 errno 值文本表示的指针。
char *strerror(int errnum);
让我们使用此函数显示 errno=2 的文本表示
示例
请看以下示例 -
#include <stdio.h>
#include <errno.h>
int main() {
FILE* fp;
// 打开不存在的文件
fp = fopen("nosuchfile.txt", "r");
printf("Value of errno: %d
", errno);
printf("The error message is : %s
", strerror(errno));
return 0;
}
输出
Value of errno: 2 he error message is : No such file or directory
ferror() 函数
此函数用于检查文件操作期间是否发生错误。
int ferror(FILE *stream);
示例
此处,我们尝试读取以 w 模式打开的文件。ferror() 函数用于打印错误消息。
#include <stdio.h>
int main(){
FILE *fp;
fp = fopen("test.txt","w");
char ch = fgetc(fp); // 尝试从可写文件读取数据
if(ferror(fp)){
printf("File is opened in writing mode! You cannot read data from it!");
}
fclose(fp);
return(0);
}
输出
运行代码并检查其输出 −
File is opened in writing mode! You cannot read data from it!
clearerr() 函数
clearerr() 函数用于清除文件流的文件结束指示符和错误指示符。
void clearerr(FILE *stream);
示例
请看以下示例 -
#include <stdio.h>
int main(){
FILE *fp;
fp = fopen("test.txt","w");
char ch = fgetc(fp); // 尝试从可写文件读取数据
if(ferror(fp)){
printf("File is opened in writing mode! You cannot read data from it!
");
}
// 清除文件流中的错误指示
// 后续的 ferror() 不会显示错误
clearerr(fp);
if(ferror(fp)){
printf("Error again in reading from file!");
}
fclose(fp);
return(0);
}
除以零的错误
一个常见的问题是,程序员在进行任何数的除法运算时,都没有检查除数是否为零,最终会导致运行时错误。
示例 1
以下代码通过在除法之前检查除数是否为零来修复此错误 -
#include <stdio.h>
#include <stdlib.h>
int main() {
int dividend = 20;
int divisor = 0;
int quotient;
if( divisor == 0){
fprintf(stderr, "Division by zero! Exiting...
");
exit(-1);
}
quotient = dividend / divisor;
fprintf(stderr, "Value of quotient : %d
", quotient );
exit(0);
}
输出
当编译并执行上述代码时,将产生以下结果
Division by zero! Exiting... Program Exit Status
如果程序在操作成功后退出,通常的做法是返回 EXIT_SUCCESS 状态。此处,EXIT_SUCCESS 是一个宏,其定义为 0。
示例 2
如果程序中出现错误,并且您正在退出,则应该返回 EXIT_FAILURE 状态,其定义为"-1"。因此,我们将上述程序编写如下:
#include <stdio.h>
#include <stdlib.h>
int main() {
int dividend = 20;
int divisor = 5;
int quotient;
if(divisor == 0) {
fprintf(stderr, "Division by zero! Exiting...
");
exit(EXIT_FAILURE);
}
quotient = dividend / divisor;
fprintf(stderr, "Value of quotient: %d
", quotient );
exit(EXIT_SUCCESS);
}
输出
当编译并执行上述代码时,将产生以下结果
Value of quotient: 4
C 语言中的递归
递归是指函数调用自身的过程。C 语言允许编写此类函数,通过调用自身将复杂问题分解为简单易行的问题来解决。这些函数被称为递归函数。
什么是 C 语言中的递归函数?
C 语言中的递归函数是指函数调用自身的函数。当某个问题根据自身进行定义时,就会使用递归函数。虽然递归函数涉及迭代,但使用迭代方法解决此类问题可能会非常繁琐。递归方法为看似复杂的问题提供了非常简洁的解决方案。
语法
通用递归函数如下所示 -
void recursive_function(){
recursion(); // 函数调用自身
}
int main(){
recursive_function();
}
使用递归时,程序员需要谨慎定义函数的退出条件,否则会陷入无限循环。
为什么在 C 语言中使用递归?
递归用于执行复杂任务,例如树和图结构的遍历。常见的递归编程解决方案包括阶乘、二分查找、树遍历、汉诺塔、国际象棋中的八皇后问题等。
递归程序简洁,不易理解。即使代码大小可以减少,由于涉及对函数的多次IO调用,也需要更多的处理器资源。
使用递归计算阶乘
递归函数在解决许多数学问题中非常有用,例如计算数字的阶乘、生成斐波那契数列等。
递归最常见的例子是计算阶乘。从数学上讲,阶乘定义为 -
n! = n X (n-1)!
可以看出,我们使用阶乘本身来定义阶乘。因此,这是一个编写递归函数的合适案例。让我们扩展上述定义,以计算阶乘值 5。
5! = 5 X 4! 5 X 4 X 3! 5 X 4 X 3 X 2! 5 X 4 X 3 X 2 X 1! 5 X 4 X 3 X 2 X 1 = 120
虽然我们可以使用循环来执行此计算,但它的递归函数需要通过递减数字直至达到 1 来连续调用它。
示例:非递归阶乘函数
以下程序展示了如何使用非递归函数计算数字的阶乘 -
#include <stdio.h>
#include <math.h>
// 函数声明
int factorial(int);
int main(){
int a = 5;
int f = factorial(a);
printf("a: %d
", a);
printf("Factorial of a: %d", f);
}
int factorial(int x){
int i;
int f = 1;
for (i = 5; i >= 1; i--){
f *= i;
}
return f;
}
输出
运行此代码时,将产生以下输出 -
a: 5 Factorial of a: 120
示例:递归阶乘函数
现在让我们编写一个递归函数来计算给定数字的阶乘。
以下示例使用递归函数计算给定数字的阶乘 -
#include <stdio.h>
#include <math.h>
/* 函数声明 */
int factorial(int i){
if(i <= 1){
return 1;
}
return i * factorial(i - 1);
}
int main(){
int a = 5;
int f = factorial(a);
printf("a: %d
", a);
printf("Factorial of a: %d", f);
return 0;
}
输出
运行代码并检查其输出 −
a: 5 Factorial of a: 120
当 main() 函数通过传递变量"a"调用 factorial() 函数时,其值存储在"i"中。factorial() 函数会依次调用自身。
每次调用时,"i"的值都会减 1 后乘以先前的值,直到等于 1。当 i 达到 1 时,将参数初始值与 1 之间的所有值的乘积返回给 main() 函数。
使用递归进行二分查找
让我们看另一个示例来理解递归的工作原理。当前的问题是检查给定数字是否存在于数组中。
虽然我们可以使用for循环并比较每个数字来顺序搜索列表中的某个数字,但顺序搜索效率不高,尤其是在列表过长的情况下。
二分搜索算法检查索引"start"是否大于索引"end"。根据变量"mid"的值,再次调用该函数来查找元素。
我们有一个按升序排列的数字列表。然后,我们找到列表的中点,并根据所需数字是小于还是大于中点的数字,将检查范围限制在中点的左侧或右侧。
示例:递归二分查找
以下代码实现了递归二分查找技术 -
#include <stdio.h>
int bSearch(int array[], int start, int end, int element){
if (end >= start){
int mid = start + (end - start ) / 2;
if (array[mid] == element)
return mid;
if (array[mid] > element)
return bSearch(array, start, mid-1, element);
return bSearch(array, mid+1, end, element);
}
return -1;
}
int main(void){
int array[] = {5, 12, 23, 45, 49, 67, 71, 77, 82};
int n = 9;
int element = 67;
int index = bSearch(array, 0, n-1, element);
if(index == -1 ){
printf("Element not found in the array ");
}
else{
printf("Element found at index: %d", index);
}
return 0;
}
输出
运行代码并检查其输出 −
Element found at index: 5
使用递归生成斐波那契数列
在斐波那契数列中,一个数字是其前两个数字之和。要生成斐波那契数列,第 i 个数字是 i-1 和 i-2 之和。
示例
以下示例使用递归函数生成给定数字的斐波那契数列的前 10 个数字 -
#include <stdio.h>
int fibonacci(int i){
if(i == 0){
return 0;
}
if(i == 1){
return 1;
}
return fibonacci(i-1) + fibonacci(i-2);
}
int main(){
int i;
for (i = 0; i < 10; i++){
printf("%d
", fibonacci(i));
}
return 0;
}
输出
当编译并执行上述代码时,它会产生以下结果 -
0 1 1 2 3 5 8 13 21 34
在程序中实现递归对于初学者来说比较困难。虽然任何迭代过程都可以转换为递归过程,但并非所有递归情况都能轻松地用迭代方式表达。
C 语言中的可变参数
有时,您可能会遇到这样的情况:您希望一个函数能够接受可变数量的参数(形参),而不是预定义数量的参数。C 编程语言为这种情况提供了一种解决方案。
阅读本章,了解如何根据您的需求定义一个可以接受可变数量参数的函数。
以下示例展示了此类函数的定义 -
int func(int, ... ) {
...
...
}
int main() {
func(1, 2, 3);
func(1, 2, 3, 4);
}
需要注意的是,函数 func() 的最后一个参数为 省略号,即三个点 (...),而省略号之前的参数始终为 int,表示传递的可变参数总数。
要实现此功能,您需要使用 stdarg.h 头文件,该文件提供了实现可变参数功能的函数和宏。
请按照以下步骤操作 -
- 定义一个函数,其最后一个参数为省略号,而省略号之前的参数始终为 int,表示参数的数量。
- 在函数定义中创建一个 va_list 类型变量。此类型在 stdarg.h 头文件中定义。
- 使用 int 参数和 va_start 宏将 va_list 变量初始化为参数列表。宏 va_start 在 stdarg.h 头文件中定义。
- 使用 va_arg 宏和 va_list 变量访问参数列表中的每个项目。
- 使用宏 va_end 清理分配给 va_list 变量的内存。
示例
现在让我们按照上述步骤编写一个简单的函数,该函数可以接受可变数量的参数并返回它们的平均值 -
#include <stdio.h>
#include <stdarg.h>
double average(int num,...) {
va_list valist;
double sum = 0.0;
int i;
/* 初始化 valist,包含 num 个参数 */
va_start(valist, num);
/* 访问赋值给 valist 的所有参数 */
for (i = 0; i < num; i++) {
sum += va_arg(valist, int);
}
/* 清理为 valist 保留的内存 */
va_end(valist);
return sum/num;
}
int main() {
printf("Average of 2, 3, 4, 5 = %f
", average(4, 2,3,4,5));
printf("Average of 5, 10, 15 = %f
", average(3, 5,10,15));
}
输出
编译并执行上述代码后,将产生以下输出 -
Average of 2, 3, 4, 5 = 3.500000 Average of 5, 10, 15 = 10.000000
需要注意的是,函数 average() 被调用了两次,每次调用时第一个参数都代表传递的可变参数的总数。省略号仅用于传递可变数量的参数。
C 语言的内存管理
C 语言的一个重要特性是编译器负责管理代码中声明的变量的内存分配。一旦编译器分配了所需的内存字节,就无法在运行时更改。
编译器采用静态内存分配方法。但是,有时您可能需要在运行时按需分配内存。阅读本章以了解 C 语言中动态内存管理的工作原理。
C 语言中动态内存管理函数
C 编程语言提供了多个用于动态内存分配和管理的函数。这些函数可以在 <stdlib.h> 头文件 中找到。
| 函数 | 描述 |
|---|---|
| void *calloc(int num, int size); | 此函数分配一个由 num 个元素组成的数组,每个元素的大小为 size(以字节为单位)。 |
| void free(void *address); | 此函数释放由地址指定的内存块。 |
| void *malloc(size_t size); | 此函数分配一个包含 num 个字节的数组,并使其保持未初始化状态。 |
| void *realloc(void *address, int newsize); | 此函数重新分配内存,并将其扩展到 newsize。 |
动态分配内存
如果您知道数组的大小,那么操作起来就很简单,您可以将其定义为数组。例如,如果您需要存储一个人的姓名,那么您可以安全地定义一个最多可容纳 100 个字符的数组(假设姓名不超过 100 个字符)。因此,您可以按如下方式定义数组:
char name[100];
这是一个静态内存分配的示例。现在让我们考虑一种您不知道需要存储的文本长度的情况,例如,您想要存储关于某个主题的详细描述。在这种情况下,如果内容小于分配的大小,则在程序执行期间分配的内存将被浪费。
另一方面,如果所需大小超过已分配的内存大小,则可能导致不可预测的行为,包括导致数据损坏,因为数组的大小无法动态更改。
在这种情况下,您需要使用本章所述的动态内存分配方法。
malloc() 函数
此函数定义在 stdlib.h 头文件中。它分配所需大小的内存块,并返回一个 void 指针。
void *malloc (size)
size 参数指的是内存块大小(以字节为单位)。要为指定数据类型分配所需的内存,您需要使用类型转换运算符。
例如,以下代码片段分配存储 int 类型所需的内存 -
int *ptr; ptr = (int *) malloc (sizeof (int));
这里我们需要定义一个指向字符的指针,但不定义所需的内存大小,之后根据需要分配内存。
示例
以下示例使用 malloc() 函数分配所需的内存来存储字符串(而不是声明固定大小的 char 数组)-
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *name;
name = (char *) malloc(strlen("TutorialsPoint"));
strcpy(name, "TutorialsPoint");
if(name == NULL) {
fprintf(stderr, "Error - unable to allocate required memory
");
} else {
printf("Name = %s
", name);
}
}
输出
当编译并执行上述代码时,它会产生以下输出 -
Name = TutorialsPoint
calloc() 函数
calloc() 函数(代表连续分配)分配请求的内存并返回指向该内存的指针。
void *calloc(n, size);
其中,"n"表示要分配的元素数量,"size"表示每个元素的字节大小。
以下代码片段分配了存储 10 个 int 类型所需的内存 -
int *ptr; ptr = (int *) calloc(25, sizeof(int));
示例
让我们使用 calloc() 函数重写上面的程序。您需要做的就是将 malloc 替换为 calloc −
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *name;
name = (char *) calloc(strlen("TutorialsPoint"), sizeof(char));
strcpy(name, "TutorialsPoint");
if(name == NULL) {
fprintf(stderr, "Error - unable to allocate required memory
");
} else {
printf("Name = %s
", name);
}
}
因此,您可以完全控制内存分配,并且可以在分配内存时传递任意大小的值,这与数组不同,数组的大小一旦定义就无法更改。
调整大小和释放内存
程序运行时,操作系统会自动释放程序分配的所有内存。但是,当您不再需要使用分配的内存时,最好通过调用 free() 函数显式释放它。
在本节中,我们将重点介绍两个函数 realloc() 和 free() 的使用,您可以使用它们来调整分配的内存大小并释放它。
realloc() 函数
C 语言中的 realloc()(重新分配)函数用于动态更改先前分配的内存的分配。您可以通过调用 realloc() 函数来增加或减少已分配内存块的大小。
realloc() 函数的原型如下:
void *realloc(*ptr, size);
这里,第一个参数"ptr"是指向先前使用 malloc、calloc 或 realloc 分配的内存块的指针,该内存块将被重新分配。如果该参数为 NULL,则将分配一个新的内存块,并返回指向该内存块的指针。
第二个参数"size"是内存块的新大小,以字节为单位。如果值为"0",且 ptr 指向现有内存块,则 ptr 指向的内存块将被释放,并返回 NULL 指针。
示例
以下示例演示了如何在 C 程序中使用 realloc() 函数 -
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *name;
name = (char *) calloc(strlen("TutorialsPoint"), sizeof(char));
strcpy(name, "TutorialsPoint");
name = (char *) realloc(name, strlen(" India Private Limited"));
strcat(name, " India Private Limited");
if(name == NULL) {
fprintf(stderr, "Error - unable to allocate required memory
");
} else {
printf("Name = %s
", name);
}
}
输出
上述代码编译并执行后,将产生以下输出:
Name = TutorialsPoint India Private Limited
free() 函数
C 语言中的 free() 函数用于动态释放使用 malloc() 和 calloc() 等函数分配的内存,因为这些内存不会被自动释放。
在 C 语言编程中,任何对未使用内存的引用都会产生垃圾回收,这可能导致程序崩溃等问题。因此,使用 free() 函数手动清理已分配的内存是明智之举。
以下是使用 free() 函数的原型:
void free(void *ptr);
其中 ptr 是指向先前分配的内存块的指针。
示例
以下示例演示了如何在 C 程序中使用 free() 函数 -
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *name;
name = (char *) calloc(strlen("TutorialsPoint"), sizeof(char));
strcpy(name, "TutorialsPoint");
if(name == NULL) {
fprintf(stderr, "Error - unable to allocate required memory
");
} else {
printf("Name = %s
", name);
free(name);
}
}
输出
在代码的末尾,分配给 char * 指针 的内存被取消分配。
Name = TutorialsPoint India Private Limited
C 语言中的命令行参数
任何 C 程序中都可能有多个函数,但 main() 函数始终是程序执行的入口点。其他函数可能有一个或多个参数和一个返回类型,而 main() 函数通常不带参数。main() 函数的返回值也是"0"。
int main() {
...
...
return 0;
}
在 main() 函数内部,可能存在 scanf() 语句,用于让用户输入某些值,然后程序会使用这些值。
#include <stdio.h>
int main() {
int a;
scanf("%d", &a);
printf("%d", a);
return 0;
}
什么是命令行参数?
除了从程序内部调用输入语句之外,还可以在程序执行时将数据从命令行传递到 main() 函数。这些值称为命令行参数。
命令行参数对您的程序非常重要,尤其是当您想从外部控制程序,而不是将这些值硬编码在代码内部时。
假设您要编写一个 C 程序"hello.c",用于向用户打印"hello"消息。我们不想使用 scanf() 从程序内部读取名称,而是希望从命令行传递名称,如下所示:-
C:\users\user>hello Prakash
该字符串将用作 main() 函数的参数,然后应显示"Hello Prakash"消息。
argc 和 argv
为了方便 main() 函数从命令行接受参数,您应该在 main() 函数中定义两个参数:argc 和 argv[]。
argc 表示传递的参数数量,argv[] 是一个指针数组,指向传递给程序的每个参数。
int main(int argc, char *argv[]) {
...
...
return 0;
}
argc 参数应始终为非负数。argv 参数是一个指向所有参数的字符指针数组,argv[0] 是程序的名称。之后直到"argv [argc - 1]",每个元素都是一个命令行参数。
打开任意文本编辑器,将以下代码保存为"hello.c"−
#include <stdio.h>
int main (int argc, char * argv[]){
printf("Hello %s", argv[1]);
return 0;
}
程序应该从 argv[1] 获取名称,并在 printf() 语句中使用它。
不要从任何 IDE(例如 VS Code 或 CodeBlocks)的"运行"菜单运行程序,而是从命令行编译它 -
C:\Users\user>gcc -c hello.c -o hello.o
构建可执行文件 -
C:\Users\user>gcc -o hello.exe hello.o
将名称作为命令行参数传递 -
C:\Users\user>hello Prakash Hello Prakash
如果在 Linux 上,编译默认生成目标文件"a.out"。我们需要在运行之前添加前缀"./",使其可执行。
$ chmod a+x a.o $ ./a.o Prakash
示例
下面是一个简单的示例,它检查命令行中是否提供了任何参数,并相应地执行相应操作 -
#include <stdio.h>
int main (int argc, char *argv[]) {
if(argc == 2) {
printf("The argument supplied is %s
", argv[1]);
}
else if(argc > 2) {
printf("Too many arguments supplied.
");
}
else {
printf("One argument expected.
");
}
}
输出
当使用单个参数编译并执行上述代码时,将产生以下输出 -
$./a.out Testing The argument supplied is testing.
当使用两个参数编译并执行上述代码时,将产生以下输出 -
$./a.out Testing1 Testing2 Too many arguments supplied.
当不使用任何参数编译并执行上述代码时,将产生以下输出 -
$./a.out One argument expected
需要注意的是,argv[0] 保存的是程序本身的名称,argv[1] 是指向提供的第一个命令行参数的指针,而 *argv[n] 是最后一个参数。如果没有提供任何参数,则 argc 将被设置为"1";如果传递一个参数,则 argc 将被设置为"2"。
从命令行传递数字参数
让我们编写一个 C 程序,读取两个命令行参数,并执行 argv[1] 和 argv[2] 的加法运算。
示例
首先保存以下代码 -
#include <stdio.h>
int main (int argc, char * argv[]) {
int c = argv[1] + argv[2];
printf("addition: %d", c);
return 0;
}
输出
当我们尝试编译时,您会收到错误消息 -
error: invalid operands to binary + (have 'char *' and 'char *')
int c = argv[1]+argv[2];
~~~~~~~~~~~~~~
这是因为"+"运算符不能包含非数字操作数。
atoi() 函数
为了解决这个问题,我们需要使用库函数 atoi(),它将数字的字符串表示形式转换为整数。
示例
以下示例展示了如何在 C 程序中使用 atoi() 函数 -
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char * argv[]) {
int c = atoi(argv[1]) + atoi(argv[2]);
printf("addition: %d", c);
return 0;
}
输出
从"add.c"编译并构建一个可执行文件,并从命令行运行,传递数字参数 -
C:\Users\user>add 10 20 addition: 30
示例
所有命令行参数均以空格分隔传递,但如果参数本身带有空格,则可以使用双引号 (" ") 或单引号 (' ') 来传递这些参数。
在本例中,我们将传递一个用双引号括起来的命令行参数 -
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Program name %s
", argv[0]);
if(argc == 2) {
printf("The argument supplied is %s
", argv[1]);
}
else if(argc > 2) {
printf("Too many arguments supplied.
");
}
else {
printf("One argument expected.
");
}
}
输出
当编译并使用空格分隔但在双引号内的单个参数执行上述代码时,它会产生以下输出 -
$./a.out "testing1 testing2" Program name ./a.out The argument supplied is testing1 testing2


