敏捷数据科学 - 数据可视化
数据可视化在数据科学中发挥着非常重要的作用。 我们可以将数据可视化视为数据科学的一个模块。 数据科学不仅仅包括构建预测模型。 它包括模型的解释以及使用它们来理解数据和做出决策。 数据可视化是以最令人信服的方式呈现数据的一个组成部分。
从数据科学的角度来看,数据可视化是展示变化和趋势的一个亮点。
考虑以下有效数据可视化指南 −
沿通用比例定位数据。
与圆形和正方形相比,使用条形更有效。
散点图应使用适当的颜色。
使用饼图来显示比例。
旭日图可视化对于层次图更有效。
敏捷需要一种简单的脚本语言来进行数据可视化,并与数据科学进行协作,"Python"是数据可视化的建议语言。
示例 1
以下示例演示了特定年份计算的 GDP 的数据可视化。 "Matplotlib"是 Python 中最好的数据可视化库。 该库的安装如下所示−

请考虑以下代码来理解这一点 −
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()
输出
上面的代码生成以下输出−
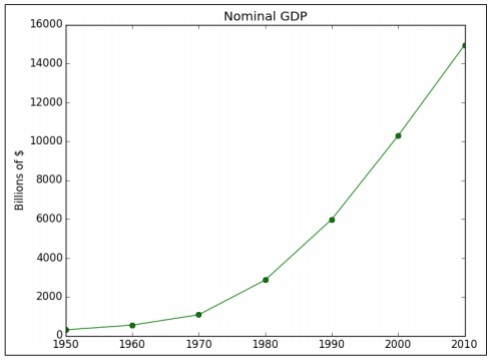
有多种方法可以使用轴标签、线条样式和点标记来自定义图表。 让我们关注下一个示例,它演示了更好的数据可视化。 这些结果可用于更好的输出。
Example 2
import datetime import random import matplotlib.pyplot as plt # make up some data x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)] y = [i+random.gauss(0,1) for i,_ in enumerate(x)] # plot plt.plot(x,y) # beautify the x-labels plt.gcf().autofmt_xdate() plt.show()
输出
上面的代码生成以下输出−