Python 深度学习 - 实现
在此深度学习实现中,我们的目标是预测某家银行的客户流失或流失数据 - 哪些客户可能会离开该银行服务。使用的数据集相对较小,包含 10000 行和 14 列。我们使用 Anaconda 发行版以及 Theano、TensorFlow 和 Keras 等框架。Keras 建立在 Tensorflow 和 Theano 之上,后者作为其后端。
# 人工神经网络 # 安装 Theano pip install --upgrade theano # 安装 Tensorflow pip install –upgrade tensorflow # 安装 Keras pip install --upgrade keras
步骤 1:数据预处理
In[]:
# 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 导入数据库
dataset = pd.read_csv('Churn_Modelling.csv')
步骤 2
我们创建数据集特征和目标变量的矩阵,即第 14 列,标记为"Exited"。
数据的初始外观如下所示 −
In[]: X = dataset.iloc[:, 3:13].values Y = dataset.iloc[:, 13].values X
输出
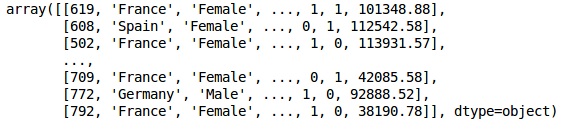
步骤 3
Y
输出
array([1, 0, 1, ..., 1, 1, 0], dtype = int64)
步骤 4
我们通过编码字符串变量使分析更简单。我们使用 ScikitLearn 函数"LabelEncoder"自动对列中的不同标签进行编码,值介于 0 到 n_classes-1 之间。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X[:,1] = labelencoder_X_1.fit_transform(X[:,1]) labelencoder_X_2 = LabelEncoder() X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2]) X
输出
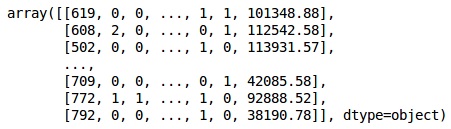
在上面的输出中,国家名称被替换为 0、1 和 2;而男性和女性被替换为 0 和 1。
步骤 5
标记编码数据
我们使用相同的 ScikitLearn 库和另一个名为 OneHotEncoder 的函数来传递列号,从而创建一个虚拟变量。
onehotencoder = OneHotEncoder(categorical features = [1]) X = onehotencoder.fit_transform(X).toarray() X = X[:, 1:] X
现在,前两列代表国家,第四列代表性别。
输出
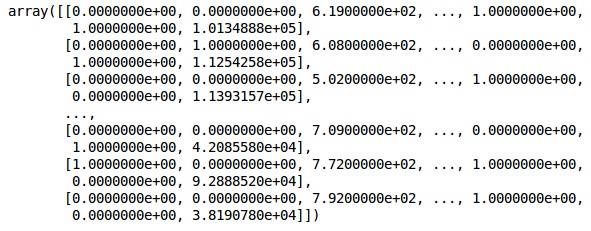
我们总是将数据分为训练和测试部分;我们在训练数据上训练模型,然后在测试数据上检查模型的准确性,这有助于评估模型的效率。
第 6 步
我们使用 ScikitLearn 的 train_test_split 函数将数据分为训练集和测试集。我们将训练与测试的分割比例保持在 80:20。
#将数据集分割为训练集和测试集 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
有些变量的值以千为单位,而有些变量的值以十或个为单位。我们对数据进行缩放,使其更具代表性。
第 7 步
在此代码中,我们使用 StandardScaler 函数拟合和转换训练数据。我们对缩放进行标准化,以便使用相同的拟合方法来转换/缩放测试数据。
# Feature Scaling
fromsklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
输出
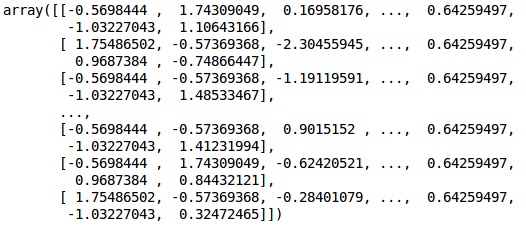
数据现在已正确缩放。最后,我们完成了数据预处理。现在,我们将开始我们的模型。
第 8 步
我们在这里导入所需的模块。我们需要 Sequential 模块来初始化神经网络,以及密集模块来添加隐藏层。
# 导入 Keras 库和包 import keras from keras.models import Sequential from keras.layers import Dense
第 9 步
我们将模型命名为分类器,因为我们的目标是对客户流失进行分类。然后我们使用 Sequential 模块进行初始化。
#初始化神经网络 classifier = Sequential()
第 10 步
我们使用密集函数逐个添加隐藏层。在下面的代码中,我们将看到许多参数。
我们的第一个参数是 output_dim。它是我们添加到此层的节点数。init 是随机梯度下降的初始化。在神经网络中,我们为每个节点分配权重。在初始化时,权重应接近于零,我们使用均匀函数随机初始化权重。input_dim 参数仅对第一层有用,因为模型不知道我们的输入变量的数量。这里输入变量的总数是11。在第二层,模型会自动从第一个隐藏层知道输入变量的数量。
执行下面这行代码,将输入层和第一个隐藏层相加 −
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 11))
执行以下代码行添加第二个隐藏层 −
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu'))
执行以下代码行添加输出层 −
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
第 11 步
编译 ANN
到目前为止,我们已经为分类器添加了多个层。现在我们将使用 compile 方法编译它们。在最终编译控制中添加的参数完成了神经网络。因此,我们需要小心这一步。
下面是参数的简要说明。
第一个参数是优化器。这是一种用于查找最佳权重集的算法。该算法称为随机梯度下降 (SGD)。在这里我们使用几种类型中的一种,称为"Adam 优化器"。SGD 取决于损失,因此我们的第二个参数是损失。如果我们的因变量是二进制的,我们使用称为"binary_crossentropy"的对数损失函数,如果我们的因变量在输出中有两个以上的类别,那么我们使用"categorical_crossentropy"。我们希望基于准确度来提高神经网络的性能,因此我们添加指标作为准确度。
# 编译神经网络 classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
第 12 步
此步骤需要执行一些代码。
将 ANN 拟合到训练集
现在我们在训练数据上训练我们的模型。我们使用 fit 方法来拟合我们的模型。我们还优化权重以提高模型效率。为此,我们必须更新权重。Batch size 是我们更新权重后的观察次数。Epoch 是迭代总数。批次大小和时期的值由试错法选择。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50)
进行预测并评估模型
# 预测测试集结果 y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
预测单个新观察值
# 预测单个新观察值 """Our goal is to predict if the customer with the following data will leave the bank: Geography: Spain Credit Score: 500 Gender: Female Age: 40 Tenure: 3 Balance: 50000 Number of Products: 2 Has Credit Card: Yes Is Active Member: Yes
步骤 13
预测测试集结果
预测结果将为您提供客户离开公司的概率。我们将该概率转换为二进制 0 和 1。
# 预测测试集结果 y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5)
new_prediction = classifier.predict(sc.transform (np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]]))) new_prediction = (new_prediction > 0.5)
步骤 14
这是我们评估模型性能的最后一步。我们已经有了原始结果,因此我们可以构建混淆矩阵来检查模型的准确性。
制作混淆矩阵
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print (cm)
输出
loss: 0.3384 acc: 0.8605 [ [1541 54] [230 175] ]
从混淆矩阵中,我们模型的准确率可以计算为 −
准确率 = 1541+175/2000=0.858
我们实现了 85.8% 的准确率,这很好。
前向传播算法
在本节中,我们将学习如何编写代码对简单的神经网络进行前向传播(预测)−
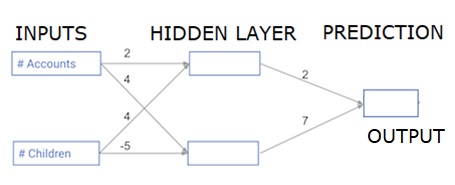
每个数据点都是一个客户。第一个输入是他们有多少个账户,第二个输入是他们有多少个孩子。该模型将预测用户明年进行多少笔交易。
输入数据已预先加载为输入数据,权重位于名为 weights 的字典中。隐藏层中第一个节点的权重数组位于 weights ['node_0'] 中,隐藏层中第二个节点的权重数组位于 weights['node_1'] 中。
输入到输出节点的权重位于 weights 中。
修正线性激活函数
"激活函数"是在每个节点上运行的函数。它将节点的输入转换为某个输出。
修正线性激活函数(称为 ReLU)广泛用于高性能网络。此函数将单个数字作为输入,如果输入为负数,则返回 0,如果输入为正数,则返回输入作为输出。
以下是一些示例 −
- relu(4) = 4
- relu(-2) = 0
我们填写 relu() 函数的定义−
- 我们使用 max() 函数计算 relu() 的输出值。
- 我们将 relu() 函数应用于 node_0_input 以计算 node_0_output。
- 我们将 relu() 函数应用于 node_1_input 以计算 node_1_output。
import numpy as np
input_data = np.array([-1, 2])
weights = {
'node_0': np.array([3, 3]),
'node_1': np.array([1, 5]),
'output': np.array([2, -1])
}
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = np.tanh(node_0_input)
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = np.tanh(node_1_input)
hidden_layer_output = np.array(node_0_output, node_1_output)
output =(hidden_layer_output * weights['output']).sum()
print(output)
def relu(input):
'''Define your relu activation function here'''
# 计算 relu 函数输出的值:输出
output = max(input,0)
# Return the value just calculated
return(output)
# 计算节点 0 值:node_0_output
node_0_input = (input_data * weights['node_0']).sum()
node_0_output = relu(node_0_input)
# 计算节点 1 值:node_1_output
node_1_input = (input_data * weights['node_1']).sum()
node_1_output = relu(node_1_input)
# 将节点值放入数组:hidden_layer_outputs
hidden_layer_outputs = np.array([node_0_output, node_1_output])
# 计算模型输出(不应用 relu)
odel_output = (hidden_layer_outputs * weights['output']).sum()
print(model_output)# Print model output
输出
0.9950547536867305 -3
将网络应用于许多观测/数据行
在本节中,我们将学习如何定义一个名为 predict_with_network() 的函数。此函数将为从上述网络中获取的多个数据观测生成预测,这些观测作为 input_data。正在使用上述网络中给出的权重。relu() 函数定义也在使用中。
让我们定义一个名为 predict_with_network() 的函数,它接受两个参数 - input_data_row 和权重 - 并返回来自网络的预测作为输出。
我们计算每个节点的输入和输出值,并将它们存储为:node_0_input、node_0_output、node_1_input 和 node_1_output。
要计算节点的输入值,我们将相关数组相乘并计算它们的总和。
要计算节点的输出值,我们将 relu() 函数应用于节点的输入值。我们使用"for 循环"来迭代 input_data −
我们还使用 predict_with_network() 为 input_data - input_data_row 的每一行生成预测。我们还将每个预测附加到结果中。
# 定义 predict_with_network() def predict_with_network(input_data_row, weights): # 计算节点 0 的值 node_0_input = (input_data_row * weights['node_0']).sum() node_0_output = relu(node_0_input) # 计算节点1的值 node_1_input = (input_data_row * weights['node_1']).sum() node_1_output = relu(node_1_input) # 将节点值放入数组:hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # 计算模型输出 input_to_final_layer = (hidden_layer_outputs*weights['output']).sum() model_output = relu(input_to_final_layer) # 返回模型输出 return(model_output) # 创建空列表来存储预测结果 results = [] for input_data_row in input_data: # 将预测附加到结果中 results.append(predict_with_network(input_data_row, weights)) print(results)# Print results
输出
[0, 12]
这里我们使用了 relu 函数,其中 relu(26) = 26 和 relu(-13)=0 等等。
深度多层神经网络
这里我们编写代码来对具有两个隐藏层的神经网络进行前向传播。每个隐藏层都有两个节点。输入数据已预加载为 input_data。第一个隐藏层中的节点称为 node_0_0 和 node_0_1。
它们的权重分别预加载为 weights['node_0_0'] 和 weights['node_0_1']。
第二个隐藏层中的节点称为 node_1_0 和 node_1_1。它们的权重分别预加载为 weights['node_1_0'] 和 weights['node_1_1']。
然后,我们使用预加载为 weights['output'] 的权重从隐藏节点创建模型输出。
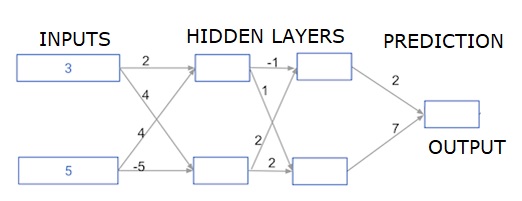
我们使用其权重 weights['node_0_0'] 和给定的 input_data 计算 node_0_0_input。然后应用 relu() 函数来获取 node_0_0_output。
我们对 node_0_1_input 执行与上述相同的操作以获取 node_0_1_output。
我们使用其权重 weights['node_1_0'] 和第一个隐藏层的输出 hidden_0_outputs 来计算 node_1_0_input。然后我们应用 relu() 函数来获取 node_1_0_output。
我们对 node_1_1_input 执行与上述相同的操作以获取 node_1_1_output。
我们使用 weights['output'] 和第二个隐藏层 hidden_1_outputs 数组的输出来计算 model_output。我们不对此输出应用 relu() 函数。

import numpy as np
input_data = np.array([3, 5])
weights = {
'node_0_0': np.array([2, 4]),
'node_0_1': np.array([4, -5]),
'node_1_0': np.array([-1, 1]),
'node_1_1': np.array([2, 2]),
'output': np.array([2, 7])
}
def predict_with_network(input_data):
# 计算第一个隐藏层的节点 0
node_0_0_input = (input_data * weights['node_0_0']).sum()
node_0_0_output = relu(node_0_0_input)
# 计算第一个隐藏层的节点1
node_0_1_input = (input_data*weights['node_0_1']).sum()
node_0_1_output = relu(node_0_1_input)
# 将节点值放入数组:hidden_0_outputs
hidden_0_outputs = np.array([node_0_0_output, node_0_1_output])
# 计算第二个隐藏层的节点0
node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum()
node_1_0_output = relu(node_1_0_input)
# 计算第二隐藏层节点1
node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum()
node_1_1_output = relu(node_1_1_input)
# 将节点值放入数组:hidden_1_outputs
hidden_1_outputs = np.array([node_1_0_output, node_1_1_output])
# 计算模型输出:model_output
model_output = (hidden_1_outputs*weights['output']).sum()
# 返回模型输出 model_output
return(model_output)
output = predict_with_network(input_data)
print(output)
输出
364


