深度神经网络
深度神经网络 (DNN) 是一种在输入层和输出层之间具有多个隐藏层的 ANN。与浅层 ANN 类似,DNN 可以对复杂的非线性关系进行建模。
神经网络的主要目的是接收一组输入,对其进行逐渐复杂的计算,并给出输出以解决分类等现实世界问题。我们将自己限制在前馈神经网络中。
在深度网络中,我们有输入、输出和连续数据流。
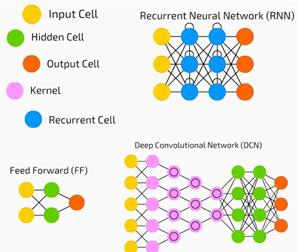
神经网络广泛用于监督学习和强化学习问题。这些网络基于一组相互连接的层。
在深度学习中,隐藏层的数量(大多是非线性的)可能很大;大约 1000 层。
DL 模型比普通 ML 网络产生更好的结果。
我们主要使用梯度下降法来优化网络并最小化损失函数。
我们可以使用 Imagenet(一个包含数百万张数字图像的存储库)将数据集分类为猫和狗等类别。除了静态图像外,DL 网络越来越多地用于动态图像以及时间序列和文本分析。
训练数据集是深度学习模型的重要组成部分。此外,反向传播是训练深度学习模型的主要算法。
深度学习处理具有复杂输入输出转换的大型神经网络的训练。
深度学习的一个例子是将照片映射到照片中人物的姓名,就像他们在社交网络上所做的那样,用短语描述图片是深度学习的另一个近期应用。
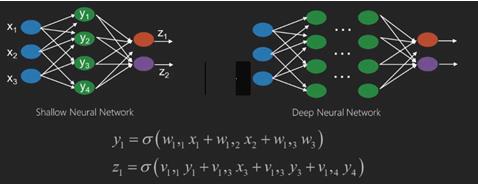
神经网络是具有输入(如 x1、x2、x3……)的函数,这些输入在两个(浅层网络)或多个中间操作(也称为层(深层网络))中转换为输出(如 z1、z2、z3 等)。
权重和偏差从一层到另一层都在变化。 'w' 和 'v' 是神经网络层的权重或突触。
深度学习的最佳用例是监督学习问题。在这里,我们有大量的数据输入和一组期望的输出。
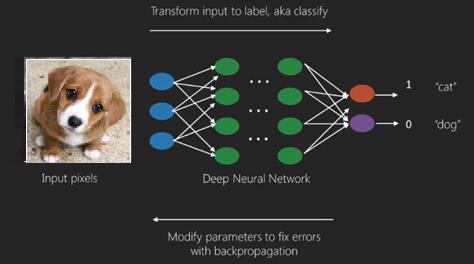
在这里我们应用反向传播算法来获得正确的输出预测。
深度学习最基本的数据集是 MNIST,一个手写数字的数据集。
我们可以使用 Keras 深度训练卷积神经网络,以对该数据集中的手写数字图像进行分类。
神经网络分类器的触发或激活会产生分数。例如,要将患者分类为患病和健康,我们会考虑身高、体重、体温、血压等参数。
高分表示患者患病,低分表示患者健康。
输出层和隐藏层中的每个节点都有自己的分类器。输入层接收输入并将其分数传递到下一个隐藏层以进行进一步激活,并一直持续到输出。
从左到右向前从输入到输出的这种进程称为前向传播
神经网络中的信用分配路径 (CAP) 是从输入到输出的一系列转换。CAP 阐述了输入和输出之间可能的因果关系。
给定前馈神经网络的 CAP 深度或 CAP 深度是隐藏层的数量加上一个,因为包含输出层。对于循环神经网络,信号可能在某一层中传播数次,CAP 深度可能无限大。
深度网络和浅层网络
没有明确的深度阈值将浅层学习与深度学习区分开来;但大多数人认为,对于具有多个非线性层的深度学习,CAP 必须大于 2。
神经网络中的基本节点是模仿生物神经网络中神经元的感知。然后我们有多层感知或 MLP。每组输入都由一组权重和偏差进行修改;每个边都有唯一的权重,每个节点都有唯一的偏差。
神经网络的预测准确度取决于其权重和偏差。
提高神经网络准确度的过程称为训练。前向传播网络的输出与已知正确的值进行比较。
成本函数或损失函数是生成的输出与实际输出之间的差值。
训练的目的是在数百万个训练示例中尽可能降低训练成本。为此,网络会调整权重和偏差,直到预测与正确的输出相匹配。
一旦训练良好,神经网络就有可能每次都做出准确的预测。
当模式变得复杂并且您希望计算机识别它们时,您必须使用神经网络。在这种复杂的模式场景中,神经网络优于所有其他竞争算法。
现在有 GPU 可以比以往更快地训练它们。深度神经网络已经彻底改变了人工智能领域
事实证明,计算机擅长执行重复计算和遵循详细的指令,但在识别复杂模式方面却不太擅长。
如果存在简单模式识别的问题,支持向量机 (svm) 或逻辑回归分类器可以很好地完成这项工作,但随着模式的复杂性增加,只能使用深度神经网络。
因此,对于像人脸这样的复杂模式,浅层神经网络无法发挥作用,只能使用具有更多层的深度神经网络。深度网络能够通过将复杂模式分解为更简单的模式来完成其工作。例如,人脸;深度网络会使用边缘来检测嘴唇、鼻子、眼睛、耳朵等部位,然后将它们重新组合在一起形成人脸。
正确预测的准确性已经变得如此准确,以至于最近在 Google 模式识别挑战赛中,深度网络击败了人类。
分层感知器网络的想法已经存在了一段时间;在这个领域,深度网络模仿人类大脑。但这样做的一个缺点是它们需要很长时间进行训练,这是硬件限制。
然而,最近的高性能 GPU 能够在一周内训练这样的深度网络;而快速 CPU 可能需要数周甚至数月才能完成同样的训练。
选择深度网络
如何选择深度网络?我们必须决定是构建分类器,还是尝试在数据中寻找模式,以及是否要使用无监督学习。为了从一组未标记的数据中提取模式,我们使用受限玻尔兹曼机或自动编码器。
选择深度网络时请考虑以下几点 −
对于文本处理、情感分析、解析和名称实体识别,我们使用循环网络或递归神经张量网络或 RNTN;
对于任何在字符级别运行的语言模型,我们都使用循环网络。
对于图像识别,我们使用深度信念网络 DBN 或卷积网络。
对于对象识别,我们使用 RNTN 或卷积网络。
对于语音识别,我们使用循环网络。
一般来说,深度信念网络和具有整流线性单元或 RELU 的多层感知器都是分类的不错选择。
对于时间序列分析,始终建议使用循环网络。
神经网络已经存在了 50 多年;但直到现在它们才开始受到重视。原因是它们很难训练;当我们尝试使用一种称为反向传播的方法来训练它们时,我们会遇到一个称为消失或爆炸梯度的问题。当发生这种情况时,训练需要更长的时间,而准确性则退居次要地位。在训练数据集时,我们会不断计算成本函数,即一组标记训练数据的预测输出与实际输出之间的差异。然后通过调整权重和偏差值来最小化成本函数,直到获得最低值。训练过程使用梯度,即成本随权重或偏差值的变化而变化的速率。
受限玻尔兹曼网络或自动编码器 - RBN
2006 年,在解决梯度消失问题方面取得了突破。Geoff Hinton 设计了一种新颖的策略,从而开发了受限玻尔兹曼机 - RBM,这是一种浅层两层网络。
第一层是可见层,第二层是隐藏层。可见层中的每个节点都连接到隐藏层中的每个节点。该网络被称为受限网络,因为同一层内的任何两层都不允许共享连接。
自动编码器是将输入数据编码为向量的网络。它们创建原始数据的隐藏或压缩表示。向量在降维方面很有用;向量将原始数据压缩为较少的基本维度。自动编码器与解码器配对,解码器允许基于其隐藏表示重建输入数据。
RBM 是双向转换器的数学等价物。前向传递接收输入并将其转换为一组对输入进行编码的数字。同时,反向传递接收这组数字并将它们转换回重建的输入。训练有素的网络可以高度准确地执行反向传播。
在任何一个步骤中,权重和偏差都起着关键作用;它们帮助 RBM 解码输入之间的相互关系并决定哪些输入对于检测模式至关重要。通过前向和后向传递,RBM 被训练以不同的权重和偏差重建输入,直到输入和构造尽可能接近。RBM 的一个有趣方面是数据不需要标记。这对于现实世界的数据集(如照片、视频、语音和传感器数据)非常重要,所有这些数据集往往都没有标记。 RBM 无需人工标记数据,而是自动对数据进行分类;通过适当调整权重和偏差,RBM 能够提取重要特征并重建输入。RBM 是特征提取神经网络系列的一部分,旨在识别数据中的固有模式。它们也被称为自动编码器,因为它们必须编码自己的结构。

深度信念网络 - DBN
深度信念网络 (DBN) 是通过组合 RBM 并引入巧妙的训练方法形成的。我们有一个新模型,最终解决了梯度消失的问题。Geoff Hinton 发明了 RBM 和深度信念网络作为反向传播的替代方案。
DBN 在结构上与 MLP(多层感知器)相似,但在训练方面却截然不同。正是训练使 DBN 能够胜过浅层感知器
DBN 可以可视化为 RBM 的堆栈,其中一个 RBM 的隐藏层是其上方 RBM 的可见层。第一个 RBM 经过训练,可以尽可能准确地重建其输入。
第一个 RBM 的隐藏层被用作第二个 RBM 的可见层,第二个 RBM 使用第一个 RBM 的输出进行训练。这个过程不断迭代,直到网络中的每一层都经过训练。
在 DBN 中,每个 RBM 都会学习整个输入。DBN 通过连续微调整个输入来全局工作,因为模型会慢慢改进,就像相机镜头慢慢聚焦图片一样。一堆 RBM 的表现优于单个 RBM,就像多层感知器 MLP 的表现优于单个感知器一样。
在此阶段,RBM 已检测到数据中的固有模式,但没有任何名称或标签。要完成 DBN 的训练,我们必须为模式引入标签,并使用监督学习微调网络。
我们需要一组非常小的带标签样本,以便将特征和模式与名称相关联。这组小标签数据集用于训练。与原始数据集相比,这组标签数据集可能非常小。
权重和偏差略有改变,导致网络对模式的感知发生微小变化,并且总体准确率通常会略有提高。
使用 GPU 也可以在合理的时间内完成训练,与浅层网络相比,训练结果非常准确,我们也看到了消失梯度问题的解决方案。
生成对抗网络 - GAN
生成对抗网络是由两个网络组成的深度神经网络,一个对抗另一个,因此得名"对抗"。
2014 年,蒙特利尔大学的研究人员在一篇论文中介绍了 GAN。Facebook 的人工智能专家 Yann LeCun 在提到 GAN 时称对抗训练是"机器学习领域过去 10 年最有趣的想法"。
GAN 的潜力巨大,因为网络扫描可以学习模仿任何数据分布。 GAN 可以被训练在任何领域创建与我们的世界惊人相似的平行世界:图像、音乐、演讲、散文。从某种意义上说,它们是机器人艺术家,它们的输出相当令人印象深刻。
在 GAN 中,一个神经网络(称为生成器)生成新的数据实例,而另一个神经网络(鉴别器)评估它们的真实性。
假设我们试图生成像 MNIST 数据集中发现的手写数字,该数据集取自现实世界。当向鉴别器展示来自真实 MNIST 数据集的实例时,鉴别器的工作是将它们识别为真实的。
现在考虑 GAN 的以下步骤 −
生成器网络以随机数的形式接受输入并返回图像。
生成的图像与从实际数据集中获取的图像流一起作为鉴别器网络的输入。
鉴别器同时接收真实图像和假图像并返回概率,概率是一个介于 0 和 1 之间的数字,其中 1 表示预测真实性,0 表示假图像。
因此,您有一个双反馈回路 −
鉴别器与图像的基本事实处于反馈回路中,我们知道这一点。
生成器与鉴别器处于反馈回路中。
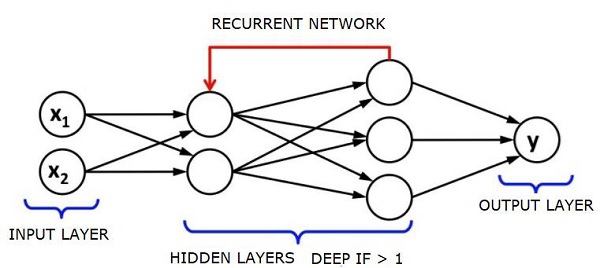
循环神经网络 - RNN
RNNSare 神经网络,其中数据可以以任何方式流动方向。这些网络用于语言建模或自然语言处理 (NLP) 等应用。
RNN 的基本概念是利用顺序信息。在正常的神经网络中,假设所有输入和输出都是相互独立的。如果我们想预测句子中的下一个单词,我们必须知道在它之前有哪些单词。
RNN 之所以被称为循环,是因为它们对序列中的每个元素重复相同的任务,输出基于先前的计算。因此可以说 RNN 具有"记忆",可以捕获有关先前计算的信息。理论上,RNN 可以使用非常长的序列中的信息,但实际上,它们只能回顾几个步骤。
长短期记忆网络 (LSTM) 是最常用的 RNN。
与卷积神经网络一起,RNN 已被用作模型的一部分,用于生成未标记图像的描述。这似乎效果很好,真是令人惊讶。
卷积深度神经网络 - CNN
如果我们增加神经网络的层数以使其更深,则会增加网络的复杂性,并允许我们建模更复杂的函数。但是,权重和偏差的数量将呈指数级增长。事实上,对于普通神经网络来说,学习如此困难的问题可能变得不可能。这导致了一个解决方案,即卷积神经网络。
CNN 广泛应用于计算机视觉;也已应用于自动语音识别的声学建模。
卷积神经网络背后的想法是"移动过滤器"的想法,它穿过图像。这种移动过滤器或卷积适用于某个节点邻域,例如可能是像素,其中应用的过滤器是 0.5 x 节点值减去;
著名研究员 Yann LeCun 开创了卷积神经网络。 Facebook 的面部识别软件使用这些网络。CNN 一直是机器视觉项目的首选解决方案。卷积网络有很多层。在 Imagenet 挑战赛中,一台机器在 2015 年的物体识别比赛中击败了人类。
简而言之,卷积神经网络 (CNN) 是多层神经网络。这些层有时多达 17 层或更多,并假设输入数据是图像。
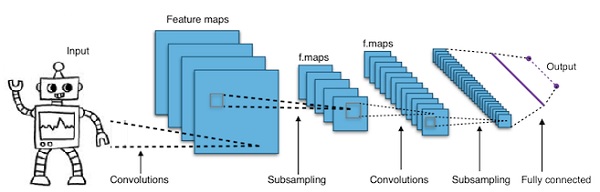
CNN 大大减少了需要调整的参数数量。因此,CNN 可以有效地处理原始图像的高维性。


