Kibana - 聚合和指标
在学习 Kibana 期间,您经常遇到的两个术语是 Bucket 和指标聚合。本章讨论它们在 Kibana 中的作用以及有关它们的更多详细信息。
什么是 Kibana 聚合?
聚合是指从特定搜索查询或过滤器获得的文档集合或一组文档。聚合是 Kibana 中构建所需可视化的主要概念。
每当执行任何可视化时,您都需要确定标准,这意味着您希望以何种方式对数据进行分组以对其执行度量。
在本节中,我们将讨论两种类型的聚合 −
- 存储桶聚合
- 度量聚合
存储桶聚合
存储桶主要由一个键和一个文档组成。执行聚合时,文档将放置在相应的存储桶中。所以最后你应该有一个存储桶列表,每个存储桶都有一个文档列表。在 Kibana 中创建可视化时,您将看到的 Bucket Aggregation 列表如下所示 −
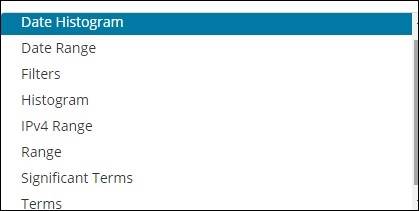
Bucket Aggregation 具有以下列表 −
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要术语
- 术语
在创建时,您需要为 Bucket Aggregation 决定其中一个,即将存储桶内的文档分组。
例如,为了进行分析,请考虑我们在开始时上传的国家/地区数据本教程。国家/地区索引中可用的字段是国家/地区名称、面积、人口、地区。在国家/地区数据中,我们有国家/地区名称及其人口、地区和面积。
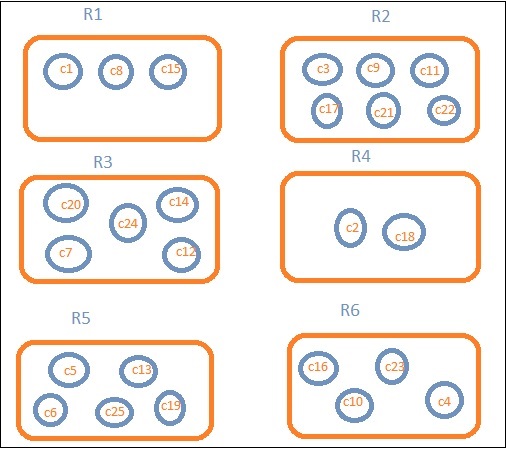
假设我们需要按地区划分的数据。然后,每个地区可用的国家将成为我们的搜索查询,因此在这种情况下,地区将形成我们的存储桶。下面的框图显示 R1、R2、R3、R4、R5 和 R6 是我们得到的存储桶,而 c1、c2 ..c25 是属于存储桶 R1 至 R6 的文档列表。
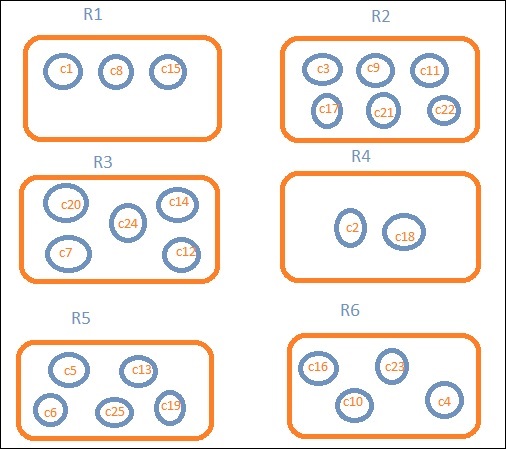
我们可以看到每个存储桶中都有一些圆圈。它们是基于搜索条件的文档集,被认为属于每个存储桶。在存储桶 R1 中,我们有文档 c1、c8 和 c15。这些文档是属于该地区的国家,其他国家也是一样。因此,如果我们计算存储桶 R1 中的国家,则有 3 个,R2 有 6 个,R3 有 6 个,R4 有 2 个,R5 有 5 个,R6 有 4 个。
因此,通过存储桶聚合,我们可以将文档聚合到存储桶中,并在这些存储桶中获得文档列表,如上所示。
到目前为止,我们拥有的存储桶聚合列表是 −
- 日期直方图
- 日期范围
- 过滤器
- 直方图
- IPv4 范围
- 范围
- 重要术语
- 术语
现在让我们详细讨论如何逐一形成这些存储桶。
日期直方图
日期直方图聚合用于日期字段。因此,您用于可视化的索引,如果该索引中有日期字段,则只能使用此聚合类型。这是一个多存储桶聚合,这意味着您可以将一些文档作为 1 个以上存储桶的一部分。此聚合有一个间隔要使用,详细信息如下所示 −
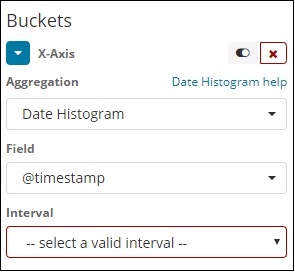
当您选择存储桶聚合作为日期直方图时,它将显示字段选项,该选项仅提供与日期相关的字段。选择字段后,您需要选择具有以下详细信息的间隔 −
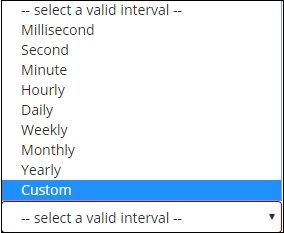
因此,所选索引中的文档以及基于所选字段和间隔的文档将按存储桶分类。例如,如果您选择间隔为每月,则基于日期的文档将转换为存储桶,并基于月份(即 1 月至 12 月)将文档放入存储桶中。此处,Jan、Feb、..Dec 将成为存储桶。
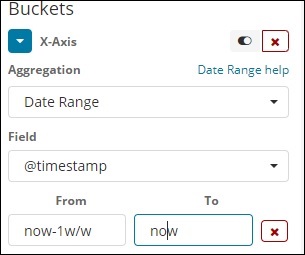
日期范围
您需要一个日期字段才能使用此聚合类型。此处我们将有一个日期范围,即给出起始日期和截止日期。存储桶将根据给定的表单和截止日期拥有其文档。
过滤器
使用过滤器类型聚合,存储桶将根据过滤器形成。在这里,您将获得一个基于过滤条件形成的多存储桶,一个文档可以存在于一个或多个存储桶中。
使用过滤器,用户可以在过滤器选项中编写查询,如下所示 −
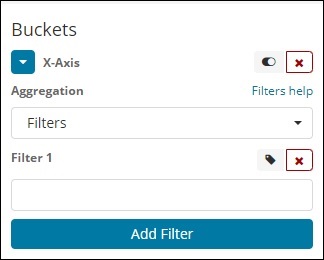
您可以使用"添加过滤器"按钮添加您选择的多个过滤器。
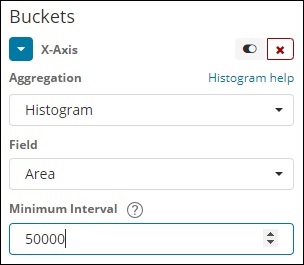
直方图
这种类型的聚合应用于数字字段,它将根据应用的间隔将文档分组到存储桶中。例如,0-50、50-100、100-150 等。
IPv4 范围
这种类型的聚合主要用于 IP 地址。
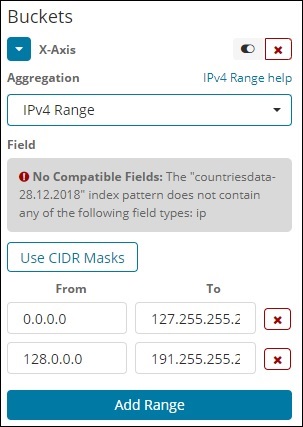
我们拥有的索引 contriesdata-28.12.2018 没有 IP 类型的字段,因此它会显示一条消息,如上所示。如果您恰好有 IP 字段,则可以在其中指定 From 和 To 值,如上所示。
范围
这种类型的聚合需要字段为数字类型。您需要指定范围,文档将列在该范围内的存储桶中。
如果需要,您可以单击"添加范围"按钮来添加更多范围。
重要术语
这种类型的聚合主要用于字符串字段。
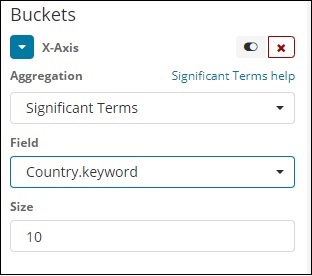
术语
这种类型的聚合用于所有可用字段,即数字、字符串、日期、布尔值、IP 地址、时间戳等。请注意,这是我们将在本教程中要处理的所有可视化中使用的聚合。
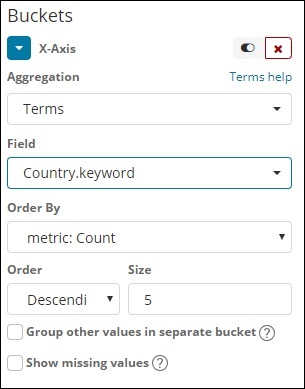
我们有一个选项顺序,我们将根据所选指标对数据进行分组。大小指的是您想要在可视化中显示的存储桶数量。
接下来,让我们谈谈指标聚合。
指标聚合
指标聚合主要是指对存储桶中存在的文档进行的数学计算。例如,如果您选择一个数字字段,您可以对其执行的指标计算是 COUNT、SUM、MIN、MAX、AVERAGE 等。
我们将讨论的指标聚合列表在此处给出 −
在本节中,让我们讨论我们将经常使用的重要指标 −
- 平均值
- 计数
- 最大值
- 最小值
- 总和
该指标将应用于我们上面已经讨论过的单个存储桶聚合。
接下来,让我们讨论这里的指标聚合列表 −
平均值
这将给出存储桶中文档值的平均值。 例如 −
R1 到 R6 是存储桶。在 R1 中,我们有 c1、c8 和 c15。假设 c1 的值为 300,c8 的值为 500,c15 的值为 700。现在获取 R1 存储桶的平均值
R1 = c1 的值 + c8 的值 + c15 的值 / 3 = 300 + 500 + 700 / 3 = 500。
存储桶 R1 的平均值是 500。这里文档的值可以是任何值,例如,如果您考虑国家/地区数据,它可能是该地区国家/地区的面积。
计数
这将给出存储桶中存在的文档数量。假设您想要该地区存在的国家/地区的数量,它将是存储桶中存在的文档总数。例如,R1 为 3,R2 = 6,R3 = 5,R4 = 2,R5 = 5 和 R6 = 4。
最大值
这将给出存储桶中存在的文档的最大值。考虑上述示例,如果我们在区域存储桶中有按区域划分的国家/地区数据。每个区域的最大值将是面积最大的国家/地区。因此,每个区域将有一个国家/地区,即 R1 至 R6。
在
这将给出存储桶中存在的文档的最小值。考虑上述示例,如果我们在区域存储桶中有按区域划分的国家/地区数据。每个区域的最小值将是面积最小的国家/地区。因此,每个区域将有一个国家/地区,即 R1 至 R6。
总和
这将给出存储桶中存在的文档的值的总和。例如,如果您考虑上述示例,如果我们想要该地区的总面积或国家,它将是该地区现有文档的总和。
例如,要知道 R1 地区中的国家总数,它将是 3、R2 = 6、R3 = 5、R4 = 2、R5 = 5 和 R6 = 4。
如果我们有该地区面积的文档,那么 R1 到 R6 将按该地区的国家/地区汇总面积。


