XGBoost - 引导方法
引导方法可以与可替换采样相结合,以重新采样数据并生成许多训练集。因此,XGBoost 中的引导策略可以定义为一种方法,我们在数据的许多随机子集上训练模型以改进它。
它是如何工作的?
为每个重新采样的集合训练一个 XGBoost 模型,并为测试数据点生成预测。这些预测的分布提供了预测不确定性的粗略估计。
因此,XGBoost 中的引导策略是指通过在数据的许多随机子集上训练模型来改进模型的方法。
XGBoost 生成大量小模型,每个模型都在可用数据的不同部分上进行训练。这种随机采样称为"引导"。 XGBoost 将这些小模型的输出组合起来,并在数据的各个子集上进行训练,以产生单一、强大的预测。
使用不同的随机样本,此策略试图减少错误并提高模型准确性。它还帮助 XGBoost 模型避免过度拟合,当模型在训练数据上表现良好但在新数据上表现不佳时就会发生过度拟合。
这类似于人们通过获得新经验来学习的方式。
将引导程序应用于模型
正如我们在引导程序方法中看到的那样,使用训练数据的重采样版本训练多个模型,并将它们的预测组合起来。基本思想是随机选择数据,引导多个模型,然后对以前从未见过的测试数据进行预测。通过对预测取平均值并计算其变异性,我们可以生成置信区间,以显示预测的不确定程度。
那么让我们看看将引导程序应用于 XGBoost 模型的步骤 −
1. 导入必要的库并生成合成数据
首先,我们将加载 XGBoost、NumPy 和 Matplotlib 等库来训练和分析模型。接下来,我们生成合成数据来训练模型。
# 在此处导入库 import xgboost as xgb import numpy as np import matplotlib.pyplot as plt # 生成随机训练和测试数据 np.random.seed(123) X_train_data = np.random.rand(150, 8) y_train_target = np.random.rand(150) # 生成 30 个具有 8 个特征的样本用于测试 X_test_data = np.random.rand(30, 8)
2. Bootstrapping
现在我们将使用上述 bootstrapping 方法创建多个模型。每次我们随机重新采样训练集,用 XGBoost 模型拟合它,然后对测试集进行预测。当我们试图从多个引导数据集中收集预测集合时,此方法将重复多次。
# 引导模型的数量
n_iterations = 120
# 用于存储每个模型的预测的列表
all_preds = []
for iteration in range(n_iterations):
# 创建引导数据集
sampled_indices = np.random.choice(len(X_train_data), len(X_train_data), replace=True)
X_resampled_data, y_resampled_target = X_train_data[sampled_indices], y_train_target[sampled_indices]
# 初始化并训练 XGBoost 回归模型
xgboost_model = xgb.XGBRegressor()
xgboost_model.fit(X_resampled_data, y_resampled_target)
# 对测试数据进行预测
test_predictions = xgboost_model.predict(X_test_data)
all_preds.append(test_predictions)
# 将预测列表转换为 NumPy 数组
all_preds = np.array(all_preds)
# 计算平均值和标准差
avg_preds = np.mean(all_preds, axis=0)
std_dev_preds = np.std(all_preds, axis=0)
# 计算 95% 置信区间
lower_confidence_bound = avg_preds - 1.96 * std_dev_preds
upper_confidence_bound = avg_preds + 1.96 * std_dev_preds
可视化结果
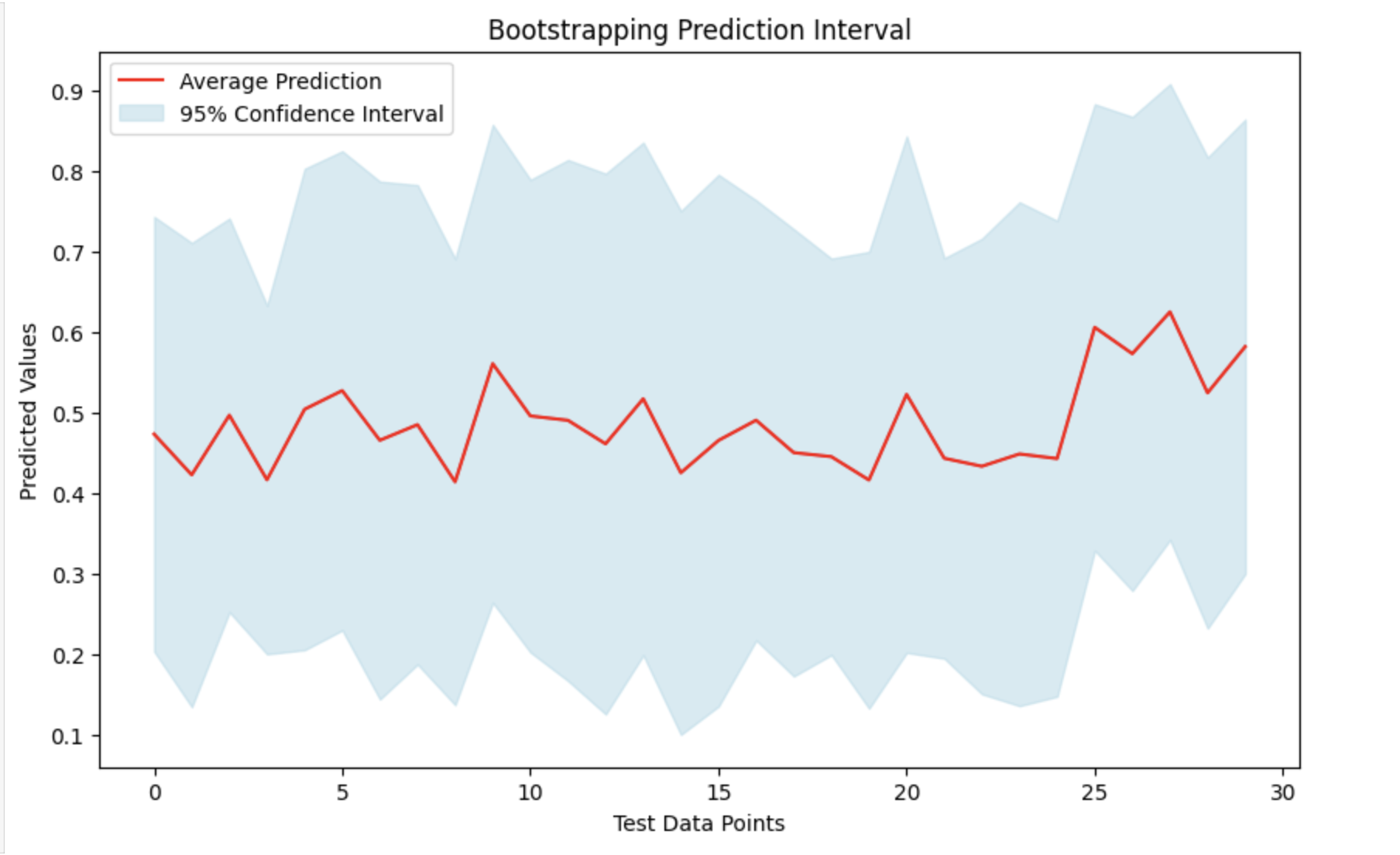
通过取所有预测的平均值(均值)及其标准差,我们可以创建一个预测区间。这将帮助我们了解实际数字可能落在哪个范围内,并提供预测不确定性的衡量标准。我们可以通过绘制平均预测值并突出显示其周围的置信区间来查看结果。
# 使用置信区间可视化预测值
# 设置图形大小
plt.figure(figsize=(10, 6))
# 绘制平均预测值
plt.plot(avg_preds, label='平均预测值', color='red')
# 填充上下置信区间之间的区域
plt.fill_between(range(len(avg_preds)), lower_confidence_bound, upper_confidence_bound, color='lightblue', alpha=0.5, label='95% 置信区间')
# 为图添加标题和标签
plt.title('引导预测区间')
plt.xlabel('测试数据点')
plt.ylabel('预测值')
# 添加图例来描述绘图线
plt.legend()
# 显示绘图
plt.show()
输出
这将产生以下结果 −