建模与模拟 - 数据库
建模与模拟中数据库的目的是为分析和测试目的提供数据表示及其关系。第一个数据模型由 Edgar Codd 于 1980 年提出。以下是该模型的显著特点。
数据库是定义信息及其关系的不同数据对象的集合。
规则用于定义对象中数据的约束。
可以对对象应用操作以检索信息。
最初,数据建模基于实体和关系的概念,其中实体是数据的信息类型,关系表示实体之间的关联。
数据建模的最新概念是面向对象设计,其中实体表示为类,在计算机编程中用作模板。一个类,具有其名称、属性、约束以及与其他类的对象的关系。
其基本表示形式类似于 −
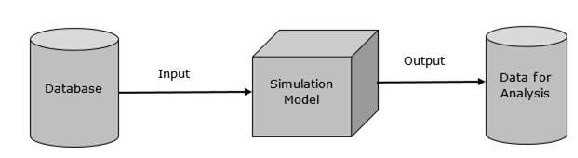
数据表示
事件的数据表示
模拟事件具有其属性,例如事件名称及其相关的时间信息。它表示使用与输入文件参数相关联的一组输入数据执行提供的模拟,并将其结果作为一组输出数据提供,存储在与数据文件相关联的多个文件中。
输入文件的数据表示
每个模拟过程都需要一组不同的输入数据及其相关的参数值,这些值在输入数据文件中表示。输入文件与处理模拟的软件相关联。数据模型通过与数据文件的关联来表示引用的文件。
输出文件的数据表示
模拟过程完成后,它会生成各种输出文件,每个输出文件都表示为一个数据文件。每个文件都有其名称、描述和通用因子。数据文件分为两个文件。第一个文件包含数值,第二个文件包含数值文件内容的描述信息。
建模和模拟中的神经网络
神经网络是人工智能的一个分支。神经网络是由许多处理器组成的网络,这些处理器被称为单元,每个单元都有自己的小型本地内存。每个单元通过单向通信通道(称为连接)连接,这些通道承载数字数据。每个单元仅处理其本地数据和从连接接收的输入。
历史
模拟的历史视角按时间顺序列举。
第一个神经模型由 McCulloch 和 Pitts 于 1940 年开发。
在 1949 年,Donald Hebb 写了一本书《行为的组织》,其中指出了神经元的概念。
在 1950 年,随着计算机的进步,基于这些理论建立模型成为可能。这是由 IBM 研究实验室完成的。然而,这一努力失败了,后来的尝试取得了成功。
在 1959 年,Bernard Widrow 和 Marcian Hoff 开发了称为 ADALINE 和 MADALINE 的模型。这些模型具有多个自适应线性元素。 MADALINE 是第一个应用于实际问题的神经网络。
1962 年,Rosenblatt 开发了感知器模型,能够解决简单的模式分类问题。
1969 年,Minsky 和 Papert 提供了感知器模型在计算方面的局限性的数学证明。据说感知器模型无法解决 X-OR 问题。这些缺点导致神经网络暂时衰落。
1982 年,加州理工学院的 John Hopfield 向美国国家科学院提交了他的论文,使用双向线路制造机器。此前,使用的是单向线路。
当涉及符号方法的传统人工智能技术失败时,就需要使用神经网络。神经网络具有大规模并行技术,可提供解决此类问题所需的计算能力。
应用领域
神经网络可用于语音合成机、模式识别、检测诊断问题、机器人控制板和医疗设备。
建模和仿真中的模糊集
如前所述,连续模拟的每个过程都依赖于微分方程及其参数,例如 a、b、c、d > 0。通常,在模型中计算和使用点估计。但是,有时这些估计是不确定的,因此我们需要微分方程中的模糊数,它提供未知参数的估计值。
什么是模糊集?
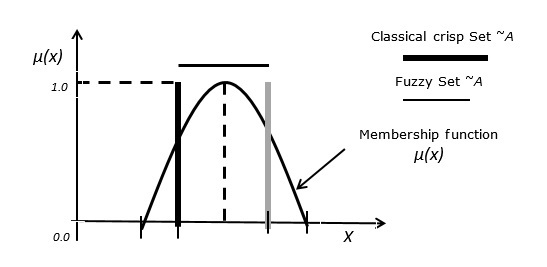
在经典集合中,元素要么是集合的成员,要么不是。模糊集根据经典集合 X 定义为 −
A = {(x,μA(x))| x ∈ X
情况 1 − 函数 μA(x) 具有以下属性 −
∀x ∈ X μA(x) ≥ 0
sup x ∈ X {μA(x)} = 1
情况 2 −设模糊集B定义为A = {(3, 0.3), (4, 0.7), (5, 1), (6, 0.4)>,则其标准模糊符号写为A = {0.3/3, 0.7/4, 1/5, 0.4/6>
任何成员等级为零的值都不会出现在集合的表达式中。
情况 3 − 模糊集与经典清晰集之间的关系。
下图描绘了模糊集与经典清晰集之间的关系。