LightGBM - 与其他 Boosting 算法的比较
LightGBM 也适用于分类数据集,因为它使用拆分或分组方法处理分类特征。我们将所有分类特征转换为类别数据类型,以便与 LightGBM 中的分类特征交互。完成后,分类数据将自动处理,无需手动管理。
LightGBM 使用 GOSS 方法在训练决策树时对数据进行采样。此方法设置每个数据样本的方差并按降序排列。方差较小的数据样本已经表现良好,因此在对数据集进行采样时,它们的权重会较低。
因此,在本章中,我们将重点介绍增强算法之间的差异,并将它们与 LightGBM 进行比较。
您应该使用哪种增强算法?
现在,问题很简单:如果这些机器学习算法都表现良好、速度快且精度更高,您应该选择哪一种?!!
这些问题的答案不能是单一的增强策略,因为每种策略都最适合您将要处理的问题类型。
例如,如果您认为您的数据集需要正则化,那么您绝对可以使用 XGBoost。CatBoost 和 LightGBM 是处理分类数据的不错选择。如果您需要更多社区对该方法的支持,请探索多年前开发的 XGBoost 或 Gradient Boosting 等算法。
Boosting 算法之间的比较
将数据拟合到模型后,所有策略都提供相对相似的结果。与其他算法相比,LightGBM 的表现似乎较差,但 XGBoost 在这种情况下表现良好。
为了展示每种算法在相同数据上的表现,我们可以展示它们的 y_test 和 y_pred 值的图表。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 示例数据
y_test = np.linspace(0, 100, 100)
# 带有一些噪声的预测
y_pred1 = y_test + np.random.normal(0, 10, 100)
y_pred2 = y_test + np.random.normal(0, 8, 100)
y_pred3 = y_test + np.random.normal(0, 6, 100)
y_pred4 = y_test + np.random.normal(0, 4, 100)
y_pred5 = y_test + np.random.normal(0, 2, 100)
fig, ax = plt.subplots(figsize=(11, 5))
# 绘制每个模型的预测
sns.lineplot(x=y_test, y=y_pred1, label='GradientBoosting', ax=ax)
sns.lineplot(x=y_test, y=y_pred2, label='XGBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred3, label='AdaBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred4, label='CatBoost', ax=ax)
sns.lineplot(x=y_test, y=y_pred5, label='LightGBM', ax=ax)
# 设置标签
ax.set_xlabel('y_test', color='g')
ax.set_ylabel('y_pred', color='g')
# 显示图表
plt.show()
输出
这是上述代码的结果 −
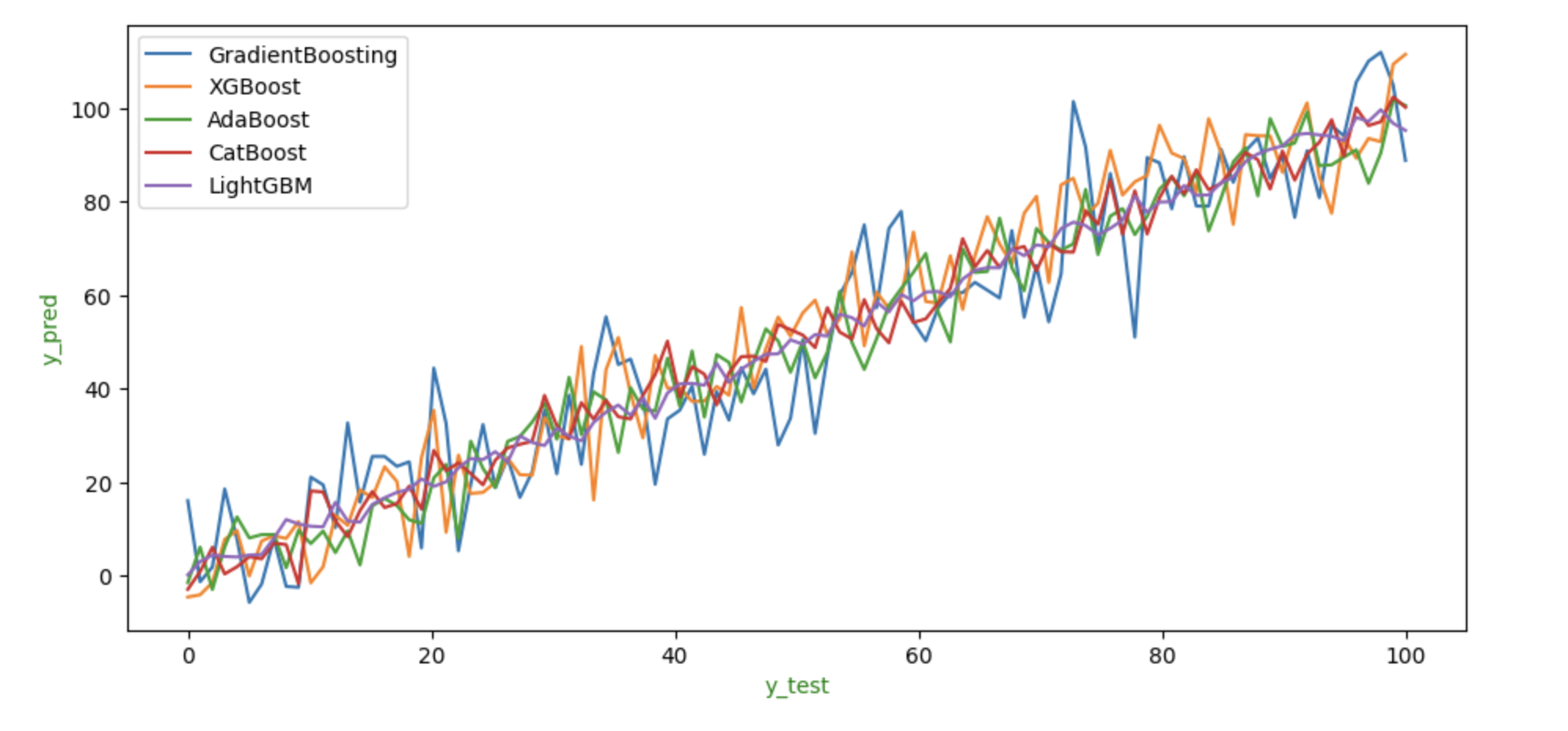
上图显示了每种方法预期的 y_test 和 y_pred 值。我们可以看到,与其他算法相比,LightGBM 和 CatBoost 的表现较差,因为它们预测的 y_pred 值比其他方法高得多或低得多。如图所示,XGBoost 和 GradientBoosting 在这些数据上的表现优于所有其他算法,预测结果似乎是所有算法的平均值。
不同 Boosting 算法之间的差异
以下是不同 Boosting 算法之间的表格差异 −
| 特征 | 梯度 Boosting | LightGBM | XGBoost | CatBoost | AdaBoost |
|---|---|---|---|---|---|
| 推出年份 | 不是具体 | 2017 | 2014 | 2017 | 1995 |
| 处理分类数据 | 需要额外步骤,如独热编码 | 需要额外步骤 | 无需特殊步骤 | 自动处理 | 无需特殊步骤需要 |
| 速度/可扩展性 | 中等 | 快速 | 快速 | 中等 | 快速 |
| 内存使用率 | 中等 | 低 | 中等 | 高 | 低 |
| 正则化(防止过度拟合) | 否 | 是 | 是 | 是 | 否 |
| 并行处理(一次运行多个任务) | 否 | 是 | 是 | 是 | 否 |
| GPU 支持(可以使用显卡) | 否 | 是 | 是 | 是 | 否 |
| 功能重要性(显示哪些功能问题) | 是的 | 是的 | 是的 | 是的 | 是的 |


