LightGBM - 绘图功能
LightGBM 提供各种工具来创建绘图,帮助您可视化模型的性能、特征重要性等。因此,在本章中,我们将编写一些可用于 LightGBM 的常见绘图函数。
LightGBM 绘图函数
因此,这里是 LightGBM 中常用的绘图函数列表 −
plot_importance()
plot_importance() 方法使用 booster 对象,然后绘制特征重要性。此方法使用一个名为importance_type 的参数,该参数用于设置为字符串拆分,它将绘制特征用于拆分的次数,并在设置为字符串增益时绘制拆分的增益。参数importance_type 的值为 split。
该函数还有一个名为 max_num_features 的参数,它接受一个整数,该整数显示我们需要在图中包括多少个特征。我们还可以借助此参数限制特征的数量。
语法
以下是我们可以用于 plot_importance() 函数的语法 −
lightgbm.plot_importance( ax=None, booster, height=0.2, ylim=None, xlim=None, xlabel='Feature importance', title='Feature importance', importance_type='split', ylabel='Features', ignore_zero=True, max_num_features=None, grid=True, figsize=None, precision=3 )
参数
使用plot_importance()函数所需的参数如下 −
booster − 是经过训练的LightGBM模型。
importance_type − 用于定义如何计算特征重要性。它有两个值split和gain。默认值为split。
max_num_features − 用于限制顶级特征的数量。
figsize − 它是一个元组,用于显示图的大小,例如(10, 6)。
xlabel, ylabel −这些是 x 轴和 y 轴的标签。
title − 它定义图的标题。
ignore_zero − 如果设置为 True,则基本上会忽略不重要的特征。
grid −如果设置为 True,则会在图中显示网格。
示例
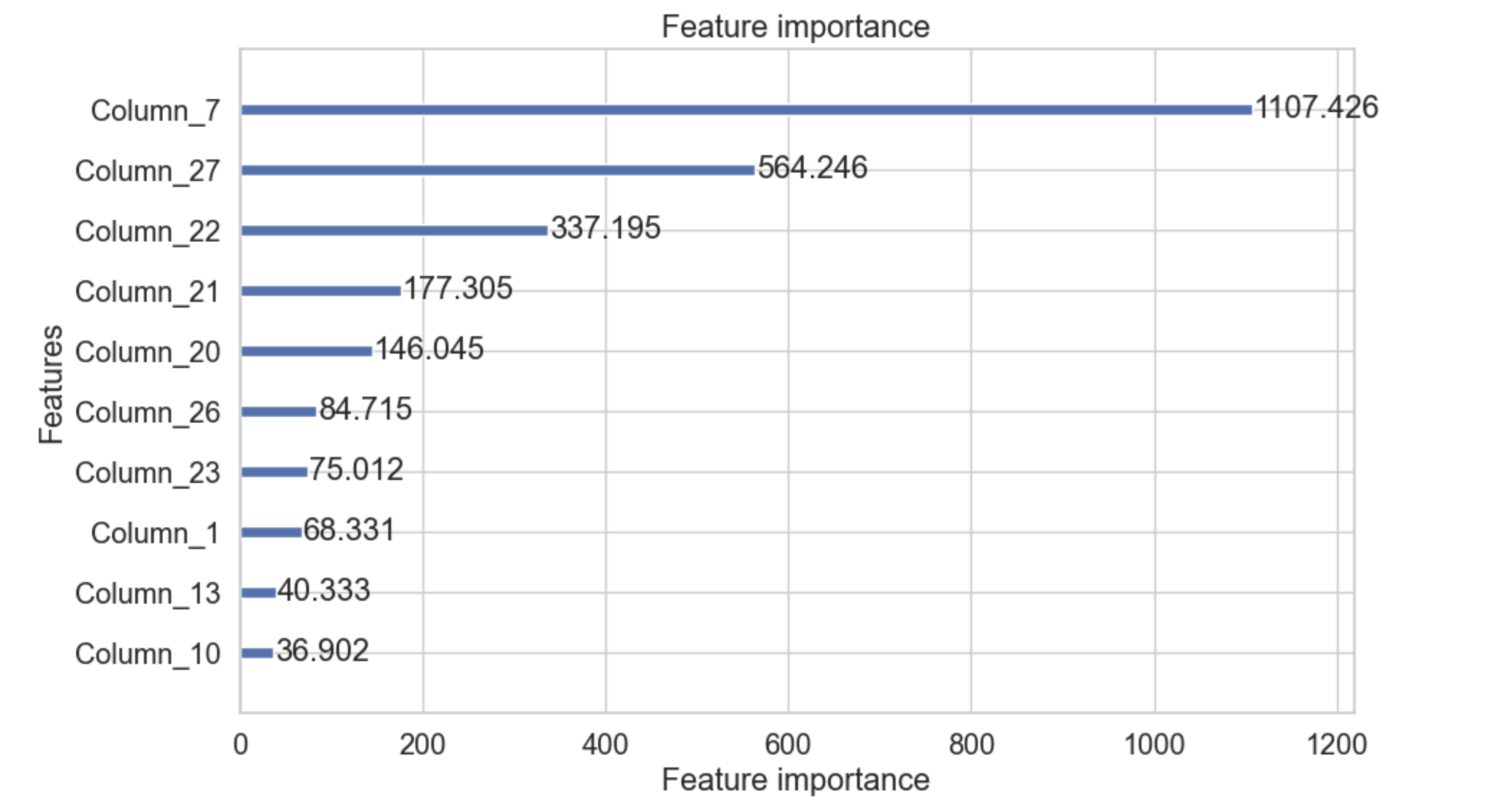
下面显示的示例向您展示了 plot_importance() 函数的用法 −
import lightgbm as lgb import matplotlib.pyplot as plt # 假设您有一个经过训练的模型 `gbm` lgb.plot_importance(gbm, significance_type='gain', max_num_features=10, figsize=(10, 6)) plt.show()
输出
以下是上述代码的输出 −
plot_metric()
plot_metric() 函数用于绘制评估指标的结果。要使用此函数,我们必须在方法内部提供一个 booster 对象来绘制在数据集上评估的评估指标。
语法
以下是我们可以用于 plot_metric() 函数的语法 −
lightgbm.plot_metric( eval_result, metric=None, dataset_names=None, ax=None, title='Metric during training', xlabel='Iterations', ylabel='Auto', figsize=None, grid=True )
参数
以下是 plot_metric() 函数所需的参数 −
eval_result − 它是 train() 方法返回的字典。它基本上包含评估结果。
metric − 它是您要绘制的评估指标。它为 none,因此绘制了所有指标。
dataset_names − 它是绘图中使用的数据集名称列表。
ax − 它是要绘制的 Matplotlib 轴对象。如果将其设置为 None,则会创建一个新图。
title −这是图表的标题。
xlabel − 这是 X 轴的标签。
ylabel − 这是 Y 轴的标签。
figsize − 这是图形大小的元组。
grid − 用于显示网格。其默认值为 True。
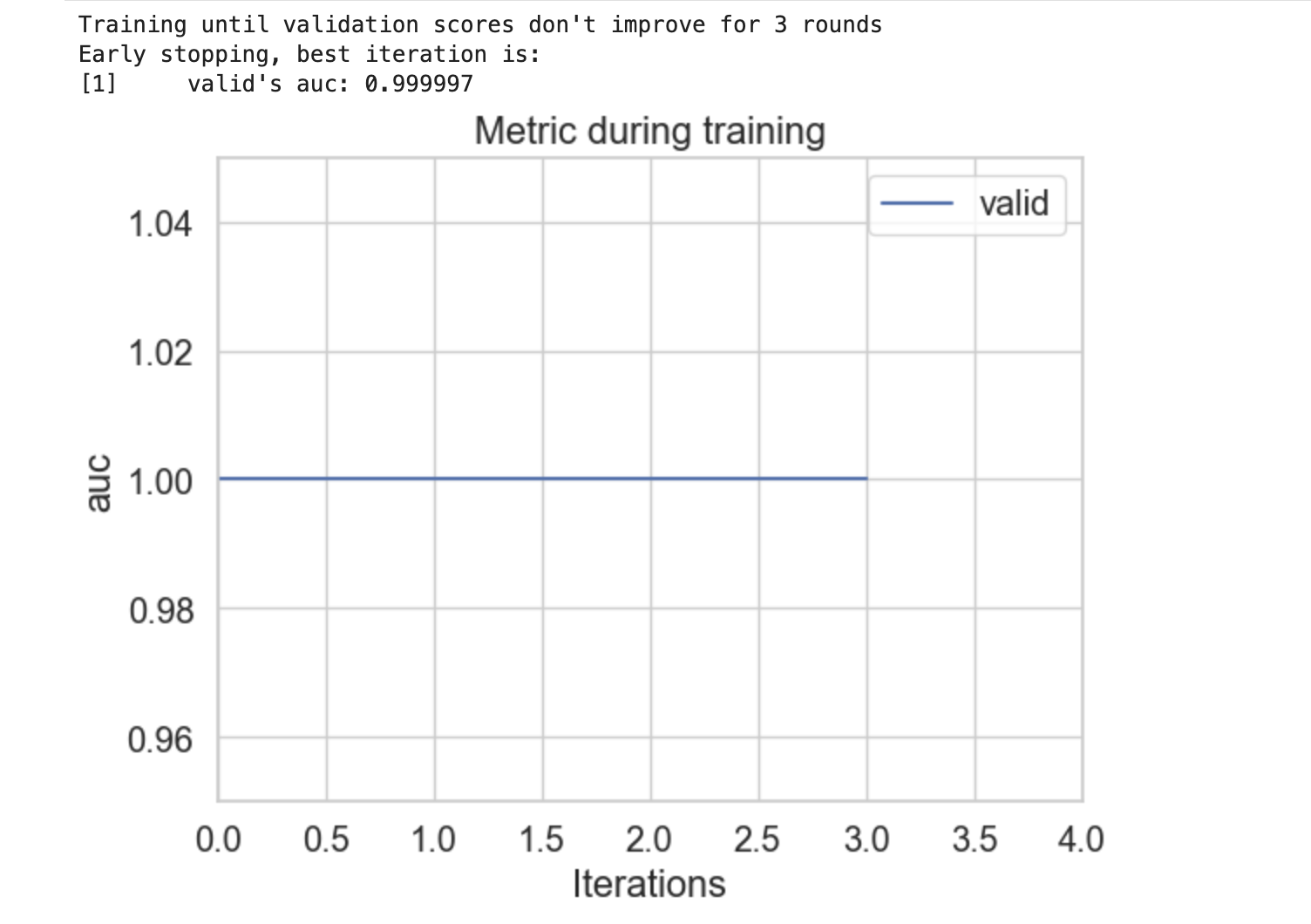
示例
以下是使用该模型并展示 plot_metric() 函数用法的 Python 完整代码 −
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# 生成样本二分类数据
X, y = make_blobs(n_samples=10_000, centers=2)
# 分割数据
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8)
# 为 LightGBM 准备数据集
dtrain = lgb.Dataset(X_train, label=y_train)
dvalid = lgb.Dataset(X_valid, label=y_valid)
# 存储结果的字典
evals_result = {}
# 训练模型
model = lgb.train(
params={
"objective": "binary",
"metric": "auc",
},
train_set=dtrain,
valid_sets=[dvalid],
valid_names=['valid'],
num_boost_round=10,
callbacks=[
lgb.early_stopping(stopping_rounds=3),
lgb.record_evaluation(evals_result)
]
)
# 绘制评估指标
lgb.plot_metric(evals_result, metric='auc')
plt.show()
输出
以下是上述代码的结果 −
plot_split_value_histogram()
plot_split_value_histogram() 函数基本上接受输入增强器对象和特征名称/索引。之后,它会为给定的特征绘制分割值直方图。
语法
以下是可用于 plot_split_value_histogram() 函数的语法 −
lightgbm.plot_split_value_histogram( booster, feature, bins=100, ax=None, width_coef=0.8, xlim=None, ylim=None, title=None, xlabel=None, ylabel=None, figsize=None, dpi=None, grid=False, )
参数
以下是 plot_split_value_histogram() 函数的必需参数和可选参数:
booster − 它是经过训练的 LightGBM 模型,也称为 booster 对象。
feature − 它是您要绘制的特征的名称。
bins − 它是可用于直方图的箱数。
ax − 它是可选的 Matplotlib 轴对象。如果给出,则将在此轴上绘制图。
width_coef − 它是用于管理直方图中条形宽度的系数。
xlim − 它是 x 轴限制的元组。
ylim − 它是 y 轴限制的元组。
title − 它是图的标题。
xlabel − 它是 x 轴的标签。
ylabel − 它是 y 轴的标签。
figsize − 它是图形大小的元组。
dpi −它是绘图的每英寸点数。
grid − 此参数使用布尔值在绘图中显示网格。
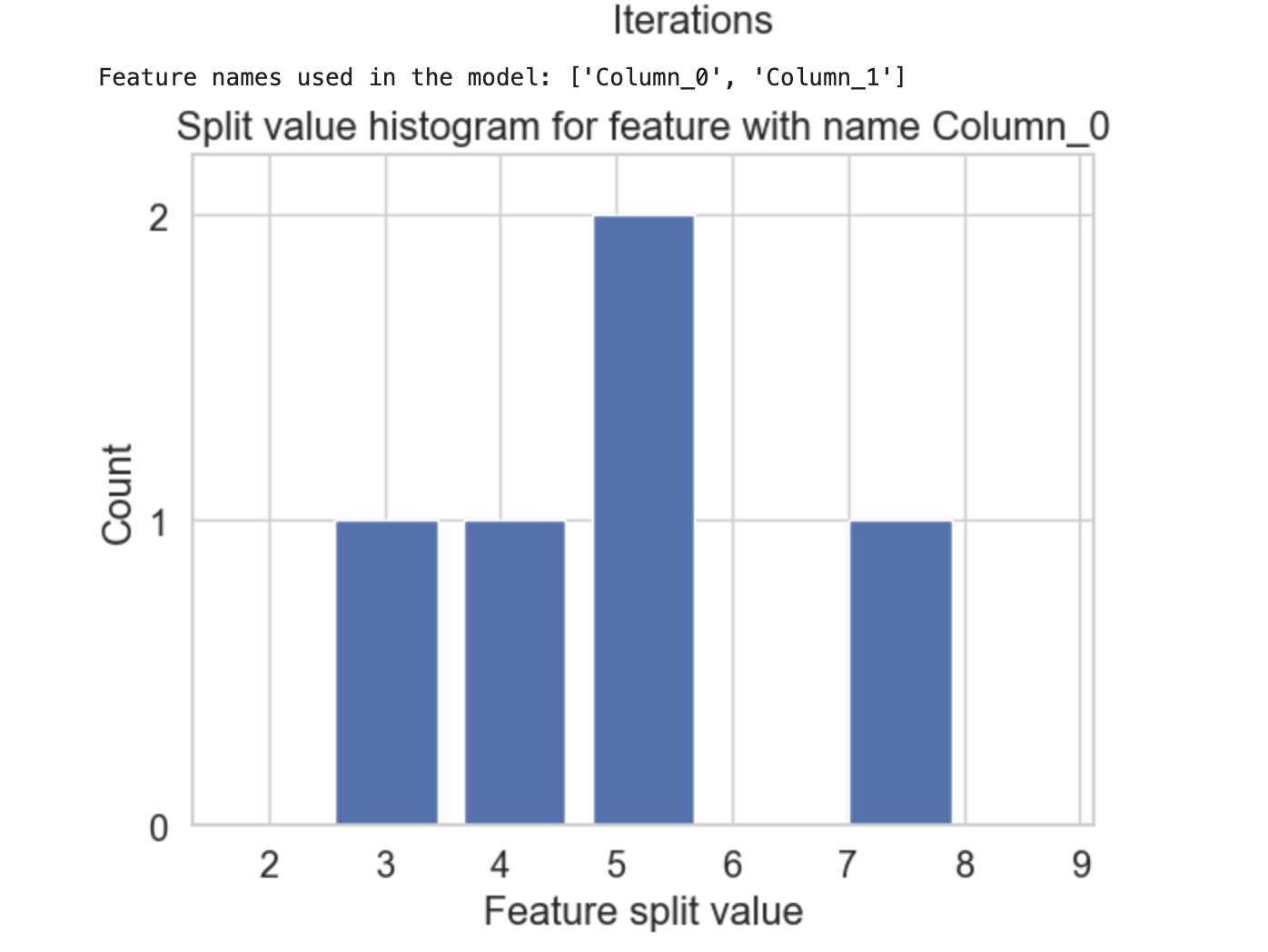
示例
以下是您可以包含 plot_split_value_histogram() 函数并查看结果的方法 −
# 完整代码与上面提到的 plot_metric() 示例类似 # 绘制分割值直方图 lgb.plot_split_value_histogram(model, feature=feature_to_plot) plt.show()
输出
这将产生以下结果:
plot_tree()
plot_tree() 函数允许您绘制集合的单个树。为此,我们必须提及一个助推器对象,其中包含我们必须绘制的树的索引。
语法
以下是您可以用于 plot_split_value_histogram() 函数的语法 −
lightgbm.plot_tree( booster, tree_index=0, figsize=(10, 10), dpi=None, show_info=True, precision=3, orientation='horizontal', example_case=None, )
参数
以下是 plot_split_value_histogram() 函数的必需参数和可选参数:
booster − 它是要绘制的 booster 或 LGBMModel 对象。
tree_index − 它是目标轴对象。如果它为 None,则创建新的图形和轴。
figsize − 它是要绘制的目标树的索引。
dpi − 它是图形的分辨率。
show_info −它用于显示树中每个节点的附加信息。
precision − 它用于将浮点值的显示限制为一定的精度。
orientation − 它是树的方向。其值可以是水平或垂直。
example_case − 它是与训练数据具有相同结构的单行。
create_tree_digraph()
create_tree_digraph() 方法用于显示 LightGBM 模型中给定决策树的结构。它基本上会生成一个图表,显示树如何在每个节点上分割数据,从而可以轻松理解模型的决策过程。
语法
以下是可用于 create_tree_digraph() 函数的语法 −
lightgbm.create_tree_digraph( booster, tree_index=0, show_info=None, precision=3, orientation='horizontal', example_case=None, max_category_values=10 )
参数
create_tree_digraph() 函数的必需参数和可选参数如下:
booster − 要转换的 booster 或 LGBMModel 对象。
tree_index − 要转换的目标树的索引。
show_info − 应在节点中显示的信息。值可以是 split_gain、internal_value、internal_count、internal_weight、leaf_count、leaf_weight 和 data_percentage。
precision − 用于将浮点值的显示限制为特定精度。
orientation −它是树的方向。值可以是水平或垂直的。
example_case − 它是与训练数据具有相同结构的单行。
max_category_values − 它是树节点中显示的最大类别值数量。如果阈值大于此值,它将被折叠并显示在标签工具提示上。


