ChatGPT 如何工作?
人工智能 (AI) 已成为我们生活、工作和与周围世界互动不可或缺的一部分。在 AI 中,有几个垂直领域,例如自然语言处理 (NLP)、计算机视觉、机器学习、机器人技术等。其中,NLP 已成为研究和开发的关键领域。OpenAI 开发的 ChatGPT 是 NLP 进步的最佳示例之一。
阅读本章以了解 ChatGPT 的工作原理、它经历的严格训练过程以及其生成响应背后的机制。
什么是 GPT?
ChatGPT 的核心是强大的技术 GPT,它代表"生成预训练转换器"。它是 OpenAI 开发的一种 AI 语言模型。 GPT 模型旨在像人类一样理解和生成自然语言文本。
下图总结了 GPT 的主要要点 −
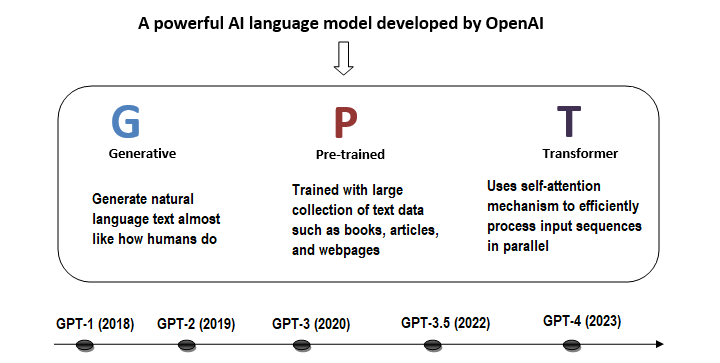
GPT 的组成部分
让我们分解一下 GPT 的每个组成部分 −
生成式
简单来说,生成式是指模型根据从训练数据中学习到的模式生成文本、图像或音乐等新内容的能力。在 GPT 的背景下,它生成的原始文本听起来像是人类写的。
预训练
预训练涉及在大型数据集上训练模型。在此阶段,模型基本上会学习与数据之间的关系。对于 GPT,该模型使用无监督学习对来自书籍、文章、网站等的大量文本进行了预训练。这有助于 GPT 学习预测序列中的下一个单词。
Transformer
Transformer 是 GPT 模型中使用的深度学习架构。Transformer 使用一种称为自我注意的机制来衡量序列中不同单词的重要性。它使 GPT 能够理解单词之间的关系,并使其产生更像人类的输出。
ChatGPT 是如何训练的?
ChatGPT 是使用 GPT 架构的变体进行训练的。以下是训练 ChatGPT 所涉及的阶段 −
语言建模
ChatGPT 是在来自互联网的大量文本数据上进行预训练的,例如书籍、文章、网站和社交媒体。此阶段涉及训练模型,根据序列中所有前面的单词来预测文本序列中的下一个单词。
此预训练步骤可帮助模型学习自然语言的统计特性并对人类语言形成一般理解。
微调
经过预训练后,ChatGPT 针对对话式 AI 任务进行了微调。此阶段涉及在具有对话记录或聊天记录等数据的较小数据集上进一步训练模型。
在微调过程中,模型使用迁移学习等技术来学习生成与用户查询相关的上下文响应。
迭代改进
在训练过程中,模型会根据响应连贯性、相关性和流畅性等各种指标进行评估。基于这些评估,为了提高性能,可以迭代训练过程。
ChatGPT 如何生成响应?
ChatGPT 的响应生成过程使用神经网络架构、注意力机制和概率建模等组件。借助这些组件,ChatGPT 可以为用户生成与上下文相关的快速响应。
让我们了解 ChatGPT 响应生成过程中涉及的步骤 −
编码
ChatGPT 的响应生成过程从将输入文本编码为数字格式开始,以便模型可以处理它。此步骤将单词或子单词转换为嵌入,模型使用该嵌入来捕获有关用户输入的语义信息。
语言理解
编码的输入文本现在被输入到预先训练的 ChatGPT 模型中,该模型通过多层转换器块进一步处理文本。如前所述,转换器块使用自注意力机制来衡量每个标记相对于其他标记的重要性。这有助于模型根据上下文理解输入。
概率分布
在对输入文本进行预处理后,ChatGPT 现在会在词汇表中生成序列中下一个单词的概率分布。在给定所有前面的单词的情况下,此概率分布使每个单词都是序列中的下一个单词。
采样
最后,ChatGPT 使用此概率分布来选择下一个单词。然后将该单词添加到生成的响应中。此响应生成过程持续进行,直到满足预定义的停止条件或生成序列结束标记。
结论
在本章中,我们首先解释了 ChatGPT 的基础,这是一种称为生成式预训练转换器 (GPT) 的 AI 语言模型。
然后,我们解释了 ChatGPT 的训练过程。语言建模、微调和迭代改进是其训练过程中涉及的阶段。
我们还简要讨论了 ChatGPT 如何生成与上下文相关的快速响应。它涉及编码、语言理解、概率分布和采样,我们对此进行了详细讨论。
ChatGPT 通过集成 GPT 架构、严格的训练过程和先进的响应生成机制,代表了 AI 驱动对话代理的重大进步。


