Python 数据持久化 - Cassandra 驱动程序
Cassandra 是另一种流行的 NoSQL 数据库。 高可扩展性、一致性和容错性——这些是 Cassandra 的一些重要特性。 这是列存储 数据库。 数据存储在许多商用服务器上。 因此,数据的可用性很高。
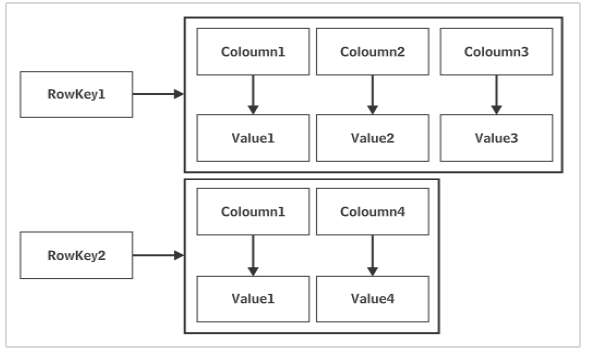
Cassandra 是 Apache 软件基金会的产品。 数据以分布式方式存储在多个节点上。 每个节点都是由 keyspace (键空间)组成的单个服务器。 Cassandra 数据库的基本构建块是 keyspace(键空间),它可以被认为类似于数据库。
Cassandra 一个节点中的数据通过对等节点网络复制到其他节点中。 这使 Cassandra 成为一个万无一失的数据库。 该网络称为数据中心。 多个数据中心可以互连形成集群。 通过在创建 keyspace 时设置复制策略和复制因子来配置复制的性质。
一个 keyspace 可能有多个列族——就像一个数据库可能包含多个表一样。 Cassandra 的 keyspace 没有预定义的模式。 Cassandra 表中的每一行可能包含名称不同且编号可变的列。
Cassandra 软件还有两个版本:社区版和企业版。 最新的 Cassandra 企业版可在 https://cassandra.apache.org/download/ 下载。 社区版位于 https://academy.datastax.com/planet-cassandra/cassandra。
Cassandra 有自己的查询语言,称为 Cassandra 查询语言 (CQL)。 CQL 查询可以从 CQLASH shell 内部执行——类似于 MySQL 或 SQLite shell。 CQL 语法看起来类似于标准 SQL。
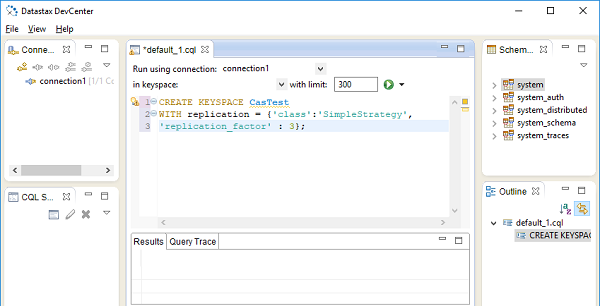
Datastax community edition,也自带一个Develcenter IDE,如下图所示 −
用于处理 Cassandra 数据库的 Python 模块称为 Cassandra Driver。 它也是由 Apache 基金会开发的。 该模块包含一个 ORM API,以及一个本质上类似于关系数据库的 DB-API 的核心 API。
使用 pip 实用程序 可以轻松安装 Cassandra 驱动程序。
pip3 install cassandra-driver
与 Cassandra 数据库的交互,是通过 Cluster 对象完成的。 Cassandra.cluster 模块定义了 Cluster 类。 我们首先需要声明 Cluster 对象。
from cassandra.cluster import Cluster clstr=Cluster()
所有事务,如插入/更新等,都是通过使用 keyspace 启动会话来执行的。
session=clstr.connect()
要创建一个新的键空间,使用会话对象的execute()方法。 execute() 方法接受一个字符串参数,该参数必须是一个查询字符串。 CQL 具有如下 CREATE KEYSPACE 语句。 完整代码如下 −
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”
这里,SimpleStrategy 是 replication strategy 的值,replication factor 设置为 3。如前所述,键空间包含一个或多个表。 每个表的特点是它的数据类型。 Python 数据类型根据下表自动解析为对应的 CQL 数据类型 −
| Python 类型 | CQL 类型 |
|---|---|
| None | NULL |
| Bool | Boolean |
| Float | float, double |
| int, long | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimal |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Date | Date |
| Datetime | Timestamp |
| Time | Time |
| list, tuple, generator | List |
| set, frozenset | Set |
| dict, OrderedDict | Map |
| uuid.UUID | timeuuid, uuid |
要创建一个表,使用 session 会话对象来执行创建表的CQL 查询。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)
这样创建的键空间可以进一步用于插入行。 INSERT 查询的 CQL 版本类似于 SQL Insert 语句。 下面的代码在 students 表中插入一行。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"
如您所料,SELECT 语句也用于 Cassandra。 如果 execute() 方法包含 SELECT 查询字符串,它会返回一个可以使用循环遍历的结果集对象。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))
Cassandra 的 SELECT 查询支持使用 WHERE 子句对要获取的结果集应用过滤器。 可以识别像 <, > == 等传统逻辑运算符。 要检索 students 表中年龄>20 的行,execute() 方法中的查询字符串应如下所示 −
rows=session.execute("select * from students WHERE age>20 allow filtering;")
请注意,使用ALLOW FILTERING。 该语句的 ALLOW FILTERING 部分允许明确允许(某些)需要过滤的查询。
Cassandra 驱动程序 API 在其 cassendra.query 模块中定义了以下语句类型类。
SimpleStatement
包含在查询字符串中的简单、未经准备的 CQL 查询。 以上所有示例都是 SimpleStatement 的示例。
BatchStatement
多个查询(如 INSERT、UPDATE 和 DELETE)放在一个批处理中并一次执行。 每行首先转换为 SimpleStatement,然后批量添加。
让我们将要添加的行以元组列表的形式添加到 Students 表中,如下所示 −
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]
要使用 BathStatement 添加以上行,请运行以下脚本 −
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)
PreparedStatement
Prepared statement 就像 DB-API 中的参数化查询。 它的查询字符串由 Cassandra 保存以备后用。 Session.prepare() 方法返回一个 PreparedStatement 实例。
对于我们的students表,一个用于INSERT查询的PreparedStatement如下 −
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")
后续只需要将参数的值传给绑定即可。 例如 −
qry=stmt.bind([1,'Ram', 23,175])
最后,执行上面的绑定语句。
session.execute(qry)
这减少了网络流量和 CPU 利用率,因为 Cassandra 不必每次都重新解析查询。

