NGN - 脉冲编码调制
高速语音和数据通信的出现带来了对快速信息传输介质的需求。 数字电路或链路是从以数字形式传输语音或数据的需要演变而来的。
从模拟形式到数字形式的转换遵循四个阶段的过程(参见下图),并将在以下部分中详细介绍。

采样
语音频率采用模拟信号的形式,即正弦波(参见下图)。该信号必须转换为二进制形式才能通过数字介质传输。 此转换的第一阶段是将音频信号转换为脉冲幅度调制(PAM)信号。 此过程通常称为采样。
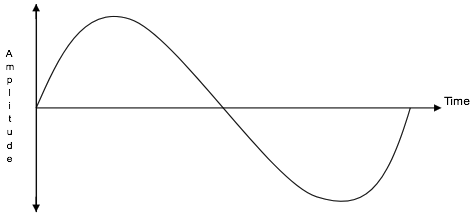
采样过程必须从传入的语音频率中收集足够的信息,以便能够制作原始信号的副本。 语音频率通常在 300Hz 至 3400Hz 范围内,通常称为商业语音频段。
为了获得样本,采样频率应用于原始语音频率。 采样频率由奈奎斯特采样定理确定,该定理规定"采样频率应至少是最高频率分量的两倍。"
这确保了每个半周期至少采样一次,从而消除了在周期零点采样的可能性,因为零点采样没有幅度。 这导致采样频率至少为 6.8 KHz。
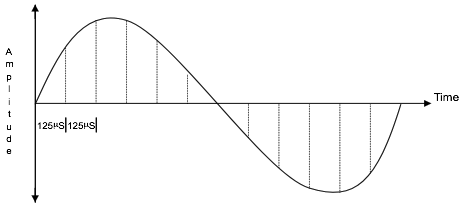
欧洲标准以 8 KHZ 对输入信号进行采样,确保每 125 微秒 或 1/8000 秒采样一次(请参阅下图)。
量化
理想情况下,每个样本的幅度都会分配一个二进制代码(1 或 0),但由于幅度可以有无限多个; 因此,需要有无限数量的可用二进制代码。 这是不切实际的,因此必须采用另一个过程,即量化。
量化将 PAM 信号与量化标度进行比较,量化标度具有有限数量的离散级别。 量化尺度分为256个量化级别,其中128个为正级别,128个为负级别。
量化阶段涉及分配一个独特的 8 位二进制代码,该代码适合 PAM 信号幅度所属的量化间隔(参见下图)。
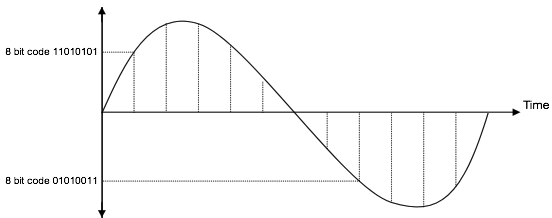
这由 1 个极性位组成,其余 7 位用于识别量化级别(如上图所示)。
前面看到的第一位是极性位,接下来的三位是段代码,给出了八个段代码,剩下的四位是量化级别,给出了十六个量化级别。
压缩
量化过程本身会导致一种称为量化失真的现象。当采样信号幅度落在量化级别之间时,就会发生这种情况。 信号始终向上舍入到最接近的整数电平。 采样电平和量化电平之间的差异就是量化失真。
信号幅度的变化率在周期的不同部分有所不同。 这种情况在高频时最常发生,因为信号幅度的变化比低频时更快。 为了克服这个问题,第一段代码的量化级别非常接近。下一个段代码的高度是前一个段代码的两倍,依此类推。 此过程称为压缩扩展,因为它压缩较大的信号并扩展较小的信号。

在欧洲,他们使用压扩的A 定律,而北美和日本则使用μ 定律。
由于量化失真相当于噪声,压扩可以提高低幅度信号的信噪比,并在整个幅度范围内产生可接受的信噪比。
编码
为了通过数字路径传输二进制信息,必须将信息修改为合适的线路代码。欧洲采用的编码技术称为高密度双极 3 (HDB3)。
HDB3 源自称为 AMI 或交替标记反转的线路代码。在AMI编码中,使用了3个值:无信号表示二进制0,以及交替使用正或负信号表示二进制1。
当传输一长串零时,会出现与 AMI 编码相关的一个问题。 这可能会导致远端接收器出现锁相环问题。
HDB3 的工作方式与 AMI 类似,但包含一个额外的编码步骤,该步骤将任何四个零的字符串替换为三个零,后跟 '违规位'。此违规与之前的转换(见下图)具有相同的极性。

从示例中可以看出,000V 替换了第一串四个零。 然而,使用这种类型的编码可能会导致信号中引入平均直流电平,因为可能存在一长串零,所有零都以相同的方式进行编码。 为了避免这种情况,通过使用极性交替的"双极性违规"位,将每个连续的四个零的编码更改为 B00V。
据此,可以假设使用 HDB3 编码时,没有过渡的零的最大数量为 3。 这种编码技术通常称为调制格式。

