CNTK - 卷积神经网络
在本章中,我们将学习如何在 CNTK 中构建卷积神经网络 (CNN)。
简介
卷积神经网络 (CNN) 也是由具有可学习权重和偏差的神经元组成的。这就是为什么它们在这方面与普通神经网络 (NN) 很相似。
如果我们回想一下普通神经网络的工作原理,每个神经元都会接收一个或多个输入,进行加权求和,然后通过激活函数产生最终输出。这里出现了一个问题,如果 CNN 和普通神经网络有如此多的相似之处,那么是什么让这两个网络彼此不同?
它们的不同之处在于对输入数据的处理和层的类型?普通 NN 会忽略输入数据的结构,将所有数据转换为一维数组,然后再将其输入网络。
但是,卷积神经网络架构可以考虑图像的二维结构,对其进行处理并允许其提取特定于图像的属性。此外,CNN 的优势在于具有一个或多个卷积层和池化层,这是 CNN 的主要构建块。
这些层后面是一个或多个完全连接的层,就像在标准多层 NN 中一样。因此,我们可以将 CNN 视为完全连接网络的一个特例。
卷积神经网络 (CNN) 架构
CNN 的架构基本上是将 3 维(即图像体积的宽度、高度和深度)转换为 3 维输出体积的层列表。这里要注意的一点是,当前层中的每个神经元都连接到前一层输出的一小部分,这就像在输入图像上叠加一个 N*N 过滤器。
它使用 M 个过滤器,这些过滤器基本上是提取边缘、角落等特征的特征提取器。以下是用于构建卷积神经网络 (CNN) 的层[INPUT-CONV-RELU-POOL-FC]−
INPUT− 顾名思义,此层保存原始像素值。原始像素值表示图像的原始数据。例如,INPUT [64×64×3] 是宽度为 64、高度为 64 和深度为 3 的 3 通道 RGB 图像。
CONV−此层是 CNN 的构建块之一,因为大多数计算都在此层中完成。例如 - 如果我们在上述输入 [64×64×3] 上使用 6 个过滤器,则可能导致体积 [64×64×6]。
RELU−也称为整流线性单元层,它将激活函数应用于前一层的输出。换句话说,RELU 会将非线性添加到网络中。
POOL− 此层,即池化层,是 CNN 的另一个构建块。此层的主要任务是下采样,这意味着它对输入的每个切片独立操作并在空间上调整其大小。
FC− 它被称为全连接层,或更具体地说是输出层。它用于计算输出类别得分,结果输出为大小为 1*1*L 的体积,其中 L 是与类别得分相对应的数字。
下图表示 CNN 的典型架构−
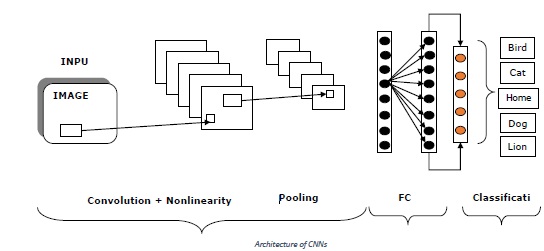
创建 CNN 结构
我们已经了解了 CNN 的架构和基础知识,现在我们将使用 CNTK 构建卷积网络。在这里,我们首先将了解如何组合 CNN 的结构,然后我们将了解如何训练它的参数。
最后,我们将看到如何通过使用各种不同的层设置来改变其结构来改进神经网络。我们将使用 MNIST 图像数据集。
因此,首先让我们创建一个 CNN 结构。通常,当我们构建一个用于识别图像模式的 CNN 时,我们会执行以下操作−
我们使用卷积层和池化层的组合。
网络末尾有一个或多个隐藏层。
最后,我们使用 softmax 层完成网络以进行分类。
借助以下步骤,我们可以构建网络结构 −
步骤 1− 首先,我们需要导入 CNN 所需的层。
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
步骤 2− 接下来,我们需要导入 CNN 的激活函数。
from cntk.ops import log_softmax, relu
步骤 3− 之后,为了稍后初始化卷积层,我们需要导入 glorot_uniform_initializer,如下所示−
from cntk.initializer import glorot_uniform
步骤 4−接下来,要创建输入变量,请导入 input_variable 函数。并导入 default_option 函数,以使 NN 的配置更容易一些。
from cntk import input_variable, default_options
步骤 5− 现在要存储输入图像,请创建一个新的 input_variable。它将包含三个通道,即红色、绿色和蓝色。它的大小为 28 x 28 像素。
features = input_variable((3,28,28))
步骤 6−接下来,我们需要创建另一个 input_variable 来存储要预测的标签。
labels = input_variable(10)
步骤 7−现在,我们需要为 NN 创建 default_option。并且,我们需要使用 glorot_uniform 作为初始化函数。
with default_options(initialization=glorot_uniform,activation=relu):
步骤 8−接下来,为了设置 NN 的结构,我们需要创建一个新的 Sequential 层集。
步骤 9− 现在我们需要在 Sequential 层集内添加一个 Convolutional2D 层,其 filter_shape 为 5,strides 设置为 1。此外,启用填充,以便填充图像以保留原始尺寸。
model = Sequential([ Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
步骤 10− 现在是时候添加一个 MaxPooling 层,其中 filter_shape 为 2,strides 设置为 2,以将图像压缩一半。
MaxPooling(filter_shape=(2,2), strides=(2,2)),
步骤 11− 现在,正如我们在步骤 9 中所做的那样,我们需要添加另一个 Convolutional2D 层,其中filter_shape 为 5,strides 设置为 1,使用 16 个过滤器。此外,启用填充,以便保留前一个池化层生成的图像的大小。
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
步骤 12− 现在,像我们在步骤 10 中所做的那样,添加另一个 MaxPooling 层,其 filter_shape 为 3,strides 设置为 3,以将图像缩小到三分之一。
MaxPooling(filter_shape=(3,3), strides=(3,3)),
步骤13− 最后,为网络可以预测的 10 个可能类别添加一个包含 10 个神经元的密集层。为了将网络转变为分类模型,请使用 log_siftmax 激活函数。
Dense(10, activation=log_softmax) ])
Complete Example for creating CNN structure
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling from cntk.ops import log_softmax, relu from cntk.initializer import glorot_uniform from cntk import input_variable, default_options features = input_variable((3,28,28)) labels = input_variable(10) with default_options(initialization=glorot_uniform, activation=relu): model = Sequential([ Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True), MaxPooling(filter_shape=(2,2), strides=(2,2)), Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True), MaxPooling(filter_shape=(3,3), strides=(3,3)), Dense(10, activation=log_softmax) ]) z = model(features)
使用图像训练 CNN
既然我们已经创建了网络结构,现在是时候训练网络了。但在开始训练我们的网络之前,我们需要设置小批量源,因为训练一个处理图像的 NN 需要比大多数计算机更多的内存。
我们已经在前面的部分创建了小批量源。以下是设置两个小批量源的 Python 代码 −
由于我们有 create_datasource 函数,我们现在可以创建两个单独的数据源(一个用于训练,一个用于测试)来训练模型。
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
现在,既然我们已经准备好了图像,我们可以开始训练我们的 NN 了。正如我们在前面几节中所做的那样,我们可以在损失函数上使用 train 方法来启动训练。以下是此代码 −
from cntk import Function from cntk.losses import cross_entropy_with_softmax from cntk.metrics import classes_error from cntk.learners import sgd @Function def criterion_factory(output, target): loss = cross_entropy_with_softmax(output, target) metric = classes_error(output, target) return loss, metric loss = criterion_factory(z, labels) learner = sgd(z.parameters, lr=0.2)
借助前面的代码,我们为 NN 设置了损失和学习器。以下代码将训练和验证 NN −
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])
完整实现示例
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])
输出
------------------------------------------------------------------- average since average since examples loss last metric last ------------------------------------------------------ Learning rate per minibatch: 0.2 142 142 0.922 0.922 64 1.35e+06 1.51e+07 0.896 0.883 192 [………]
图像转换
正如我们所见,训练用于图像识别的 NN 非常困难,而且它们也需要大量数据进行训练。还有一个问题是,它们往往会过度拟合训练期间使用的图像。让我们看一个例子,当我们有直立面部照片时,我们的模型很难识别朝另一个方向旋转的面部。
为了克服这样的问题,我们可以使用图像增强,CNTK 在为图像创建小批量源时支持特定的转换。我们可以使用以下几种转换−
我们只需几行代码就可以随机裁剪用于训练的图像。
我们还可以使用比例和颜色。
让我们借助以下 Python 代码看看如何通过在之前用于创建小批量源的函数中包含裁剪转换来更改转换列表。
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
借助以上代码,我们可以增强该功能以包含一组图像变换,这样,当我们进行训练时,我们可以随机裁剪图像,从而获得更多图像变化。


