MapReduce - Hadoop 管理
本章介绍 Hadoop 管理,包括 HDFS 和 MapReduce 管理。
HDFS 管理包括监控 HDFS 文件结构、位置和更新的文件。
MapReduce 管理包括监控应用程序列表、节点配置、应用程序状态等。
HDFS 监控
HDFS(Hadoop 分布式文件系统)包含用户目录、输入文件和输出文件。使用 MapReduce 命令 put 和 get 进行存储和检索。
通过在"/$HADOOP_HOME/sbin"上传递命令"start-all.sh"启动 Hadoop 框架(守护进程)后,将以下 URL 传递到浏览器"http://localhost:50070"。您应该会在浏览器上看到以下屏幕。
以下屏幕截图显示了如何浏览 HDFS。
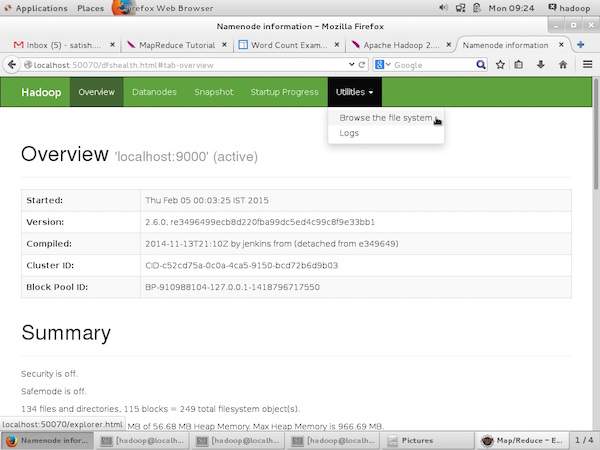
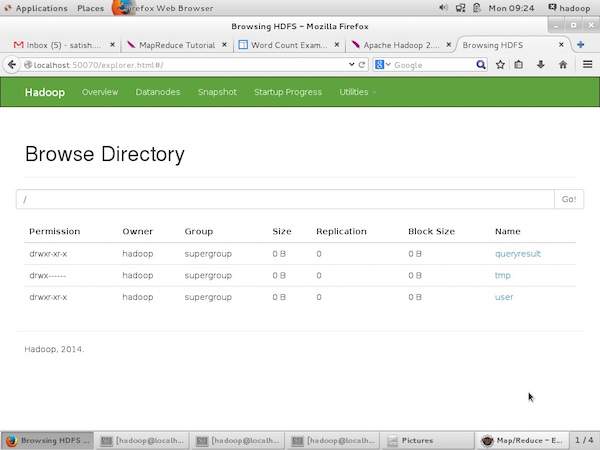
以下屏幕截图显示了 HDFS 的文件结构。它显示了"/user/hadoop"目录中的文件。
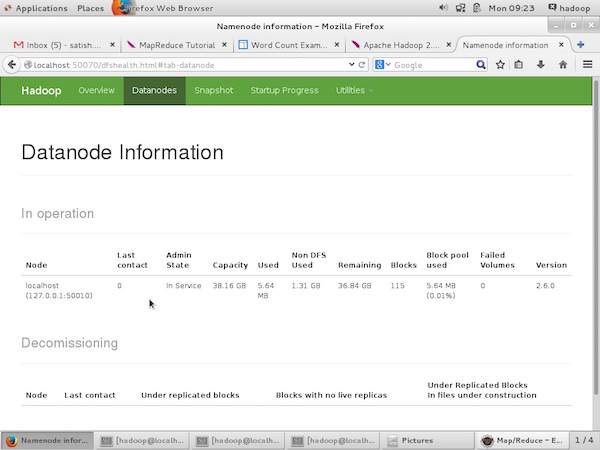
以下屏幕截图显示了集群中的 Datanode 信息。在这里您可以找到一个节点及其配置和容量。
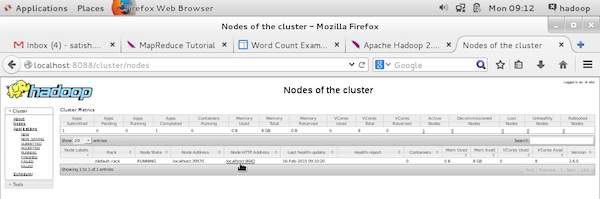
MapReduce 作业监控
MapReduce 应用程序是作业(Map 作业、Combiner、Partitioner 和 Reduce 作业)的集合。必须监控和维护以下内容 −
- 应用程序适用的数据节点配置。
- 每个应用程序使用的数据节点和资源数量。
要监控所有这些内容,我们必须有一个用户界面。通过在"/$HADOOP_HOME/sbin"上传递命令"start-all.sh"启动 Hadoop 框架后,将以下 URL 传递到浏览器"http://localhost:8080"。您应该在浏览器上看到以下屏幕。
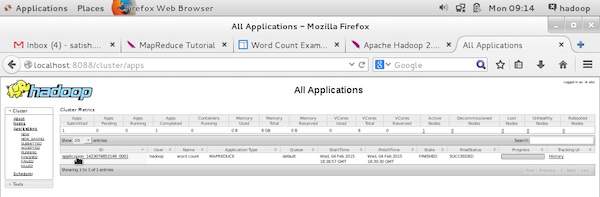
在上面的屏幕截图中,手形指针位于应用程序 ID 上。只需单击它即可在浏览器上找到以下屏幕。它描述了以下内容 −
当前应用程序在哪个用户上运行
应用程序名称
该应用程序的类型
当前状态、最终状态
应用程序启动时间、已用时间(完成时间)、监控时是否完成
此应用程序的历史记录,即日志信息
最后,节点信息,即参与运行应用程序的节点。
以下屏幕截图显示了特定应用程序 −
的详细信息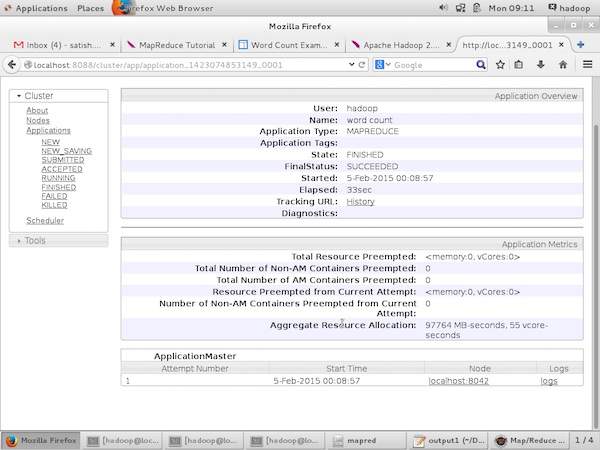
以下屏幕截图描述了当前正在运行的节点信息。此处截图仅包含一个节点。手形指针显示正在运行的节点的本地主机地址。