MapReduce - 合并器
Combiner,也称为半reducer,是一个可选类,它通过接受来自 Map 类的输入,然后将输出的键值对传递给 Reducer 类来运行。
Combiner 的主要功能是汇总具有相同键的 Map 输出记录。Combiner 的输出(键值集合)将通过网络发送到实际的 Reducer 任务作为输入。
Combiner
Combiner 类用于 Map 类和 Reduce 类之间,以减少 Map 和 Reduce 之间的数据传输量。通常,map 任务的输出很大,传输到 Reduce 任务的数据也很高。
以下 MapReduce 任务图显示了 COMBINER 阶段。
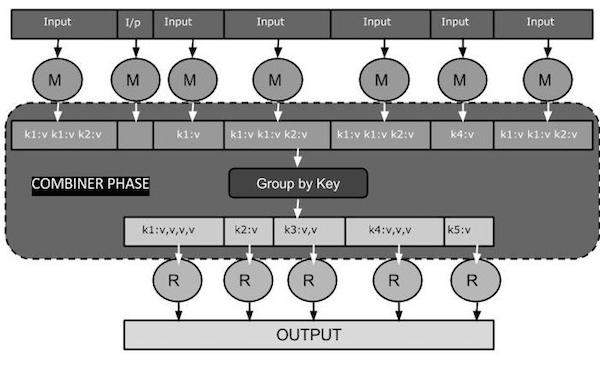
Combiner 如何工作?
以下是 MapReduce Combiner 如何工作的简要概述 −
Combiner 没有预定义的接口,它必须实现 Reducer 接口的 Reduce() 方法。
Combiner 对每个 Map 输出键进行操作。它必须具有与 Reducer 类相同的输出键值类型。
组合器可以从大型数据集生成摘要信息,因为它取代了原始 Map 输出。
尽管组合器是可选的,但它有助于将数据分成多个组以进行 Reduce 阶段,从而使处理更加容易。
MapReduce 组合器实现
以下示例提供了有关组合器的理论思想。假设我们有以下用于 MapReduce 的名为 input.txt 的输入文本文件。
What do you mean by Object What do you know about Java What is Java Virtual Machine How Java enabled High Performance
下面讨论了使用 Combiner 的 MapReduce 程序的重要阶段。
记录读取器
这是 MapReduce 的第一阶段,其中记录读取器将输入文本文件中的每一行读取为文本,并以键值对的形式输出。
输入 − 来自输入文件的逐行文本。
输出 − 形成键值对。以下是预期的键值对集。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 阶段
Map 阶段从记录读取器获取输入,对其进行处理,并生成另一组键值对的输出。
输入 − 以下键值对是从记录读取器获取的输入。
<1, What do you mean by Object> <2, What do you know about Java> <3, What is Java Virtual Machine> <4, How Java enabled High Performance>
Map 阶段读取每个键值对,使用 StringTokenizer 将每个单词从值中分离出来,将每个单词视为键,将该单词的计数视为值。以下代码片段显示了 Mapper 类和 map 函数。
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
输出 − 预期输出如下 −
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
组合器阶段
组合器阶段从 Map 阶段获取每个键值对,对其进行处理,并生成 键值集合 对的输出。
输入 − 以下键值对是从 Map 阶段获取的输入。
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1> <What,1> <do,1> <you,1> <know,1> <about,1> <Java,1> <What,1> <is,1> <Java,1> <Virtual,1> <Machine,1> <How,1> <Java,1> <enabled,1> <High,1> <Performance,1>
Combiner 阶段读取每个键值对,将常用词组合为键,将值组合为集合。通常,Combiner 的代码和操作与 Reducer 的代码和操作类似。以下是 Mapper、Combiner 和 Reducer 类声明的代码片段。
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
输出 − 预期输出如下 −
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 阶段
Reducer 阶段从 Combiner 阶段获取每个键值集合对,对其进行处理,并将输出作为键值对传递。请注意,Combiner 功能与 Reducer 相同。
输入 − 以下键值对是从 Combiner 阶段获取的输入。
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,1,1,1> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
Reducer 阶段读取每个键值对。以下是 Combiner 的代码片段。
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
输出 − Reducer 阶段的预期输出如下 −
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1> <know,1> <about,1> <Java,3> <is,1> <Virtual,1> <Machine,1> <How,1> <enabled,1> <High,1> <Performance,1>
记录写入器
这是 MapReduce 的最后一个阶段,记录写入器会写入来自 Reducer 阶段的每个键值对,并以文本形式发送输出。
输入 − 来自 Reducer 阶段的每个键值对以及输出格式。
输出 − 它以文本格式为您提供键值对。以下是预期输出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1
示例程序
以下代码块计算程序中的单词数。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
将上述程序另存为WordCount.java。程序的编译和执行如下所示。
编译和执行
假设我们在 Hadoop 用户的主目录中(例如,/home/hadoop)。
按照以下步骤编译和执行上述程序。
步骤 1 − 使用以下命令创建一个目录来存储已编译的 java 类。
$ mkdir unit
步骤 2 − 下载 Hadoop-core-1.2.1.jar,用于编译和执行 MapReduce 程序。您可以从 mvnrepository.com 下载 jar。
假设下载的文件夹是 /home/hadoop/。
步骤 3 − 使用以下命令编译 WordCount.java 程序并为该程序创建一个 jar。
$ javac -classpath hadoop-core-1.2.1.jar -d unit WordCount.java $ jar -cvf unit.jar -C unit/ .
步骤 4 −使用以下命令在 HDFS 中创建输入目录。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
步骤 5 − 使用以下命令将名为 input.txt 的输入文件复制到 HDFS 的输入目录中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dir
步骤 6 − 使用以下命令验证输入目录中的文件。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
步骤 7 −使用以下命令从输入目录中获取输入文件,运行 Word count 应用程序。
$HADOOP_HOME/bin/hadoop jar unit.jar hadoop.ProcessUnits input_dir output_dir
等待一段时间,直到文件执行。执行后,输出包含输入拆分、Map 任务和 Reducer 任务的数量。
步骤 8 − 使用以下命令验证输出文件夹中的结果文件。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
步骤 9 − 使用以下命令查看 Part-00000 文件中的输出。该文件由 HDFS 生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是 MapReduce 程序生成的输出。
What 3 do 2 you 2 mean 1 by 1 Object 1 know 1 about 1 Java 3 is 1 Virtual 1 Machine 1 How 1 enabled 1 High 1 Performance 1


