Beautiful Soup - Souping 文档页面
在前面的代码示例中,我们使用字符串方法通过 BeautifulSoup 构造函数解析文档。 另一种方法是通过打开的文件句柄传递文档。
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")
首先将文档转为Unicode,HTML实体转为Unicode字符:</p>
import bs4 html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>''' soup = bs4.BeautifulSoup(html, 'lxml') print(soup)
输出
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>
BeautifulSoup 然后使用 HTML 解析器解析数据,或者您明确地告诉它使用 XML 解析器解析。
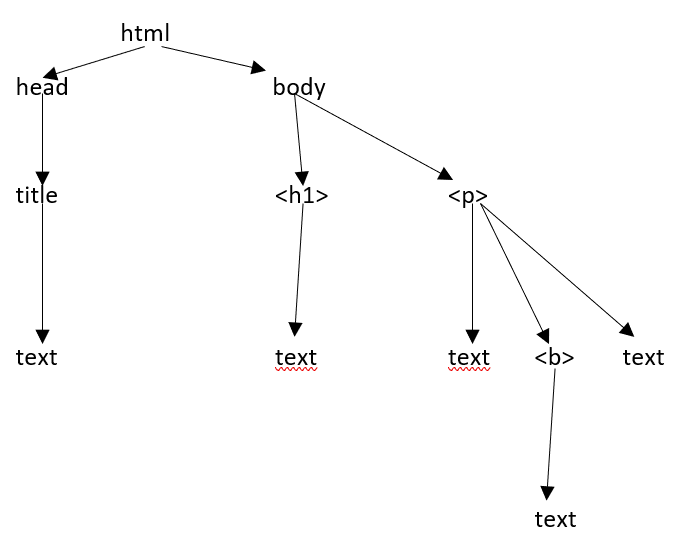
HTML 树结构
在研究 HTML 页面的不同组件之前,让我们首先了解 HTML 树结构。
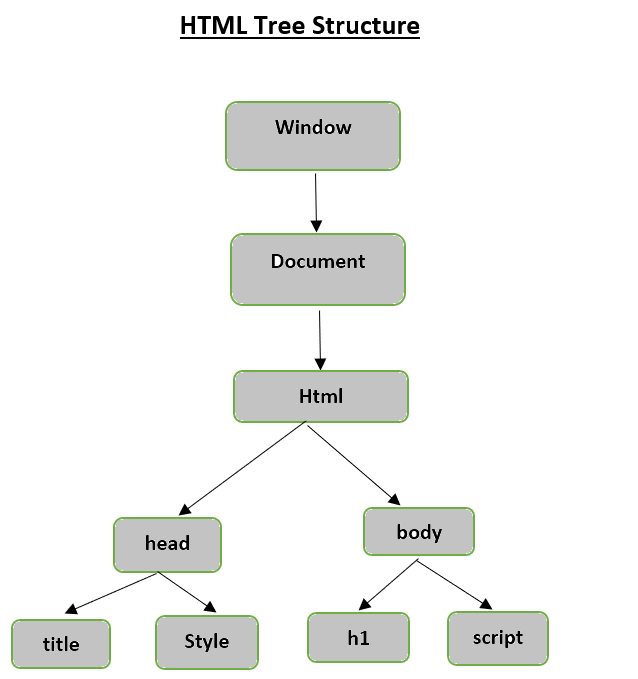
文档树中的根元素是 html,它可以有父元素、子元素和兄弟元素,这取决于它在树结构中的位置。 要在 HTML 元素、属性和文本之间移动,您必须在树结构中的节点之间移动。
假设网页如下图所示 −
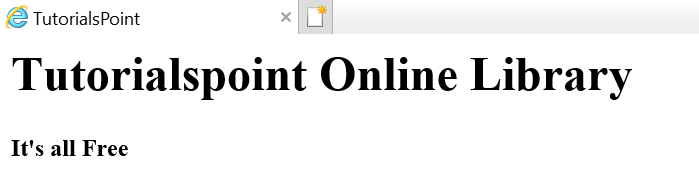
其中翻译成html文档如下 −
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>
简单来说,对于上面的 html 文档,我们有一个 html 树结构如下 −