在机器学习中使用 GPU
机器学习最近吸引了更多关注。GPU,有时被称为"图形处理单元",是可以持续管理大量数据的专用计算系统。因此,GPU 是机器学习应用程序的理想平台。这篇文章将解释如何开始,同时探索 GPU 对机器学习的几个优势。
使用 GPU 的好处
由于以下因素,GPU 是加速机器学习工作负载的有效工具 -
并行处理 - GPU 的同时多任务特性使大规模机器学习方法并行化成为可能。因此,复杂的模型训练时间可以从几天缩短到几小时甚至几分钟。
高内存带宽 − 由于 GPU 的内存带宽高于 CPU,因此数据可以在 GPU 内存和主内存之间更快地发送。结果是机器学习模型的训练时间更短。
经济高效 − 价格低廉的 GPU 能够执行需要大量 CPU 的相同工作。
您有几种选择来访问专用 GPU。您可以利用带有专用 GPU 的本地计算机立即执行机器学习工作。但是,如果您更愿意使用基于云的解决方案,Google Cloud、Amazon AWS 或 Microsoft Azure 等服务提供的 GPU 实例可从任何地方轻松设置和使用。
设置 GPU
在使用 GPU 进行机器学习之前,需要设置一些东西 −
GPU 硬件 − 要开始将其用于机器学习,需要 GPU。由于其出色的性能以及与 TensorFlow、PyTorch 和 Keras 等知名机器学习框架的互操作性,NVIDIA GPU 在机器学习社区中得到最广泛使用和最受欢迎的 GPU。如果您还没有 GPU 租赁,AWS、Google Cloud 或 Azure 等云服务公司可以提供 GPU 租赁服务。
驱动程序和库 − 获得硬件后,需要安装适当的驱动程序和库。机器学习 GPU 加速所需的驱动程序和库是 NVIDIA 提供的 CUDA 工具包的一部分。还必须安装所需机器学习框架的 GPU 版本。
验证设置 − 安装后运行快速机器学习程序并确保 GPU 正在用于计算,这将允许您确认配置。
使用 GPU 进行机器学习
配置 GPU 后,即可开始进行机器学习。您应该执行以下操作 −
导入必要的库 − 需要导入允许 GPU 加速的适当库才能使用 GPU 进行机器学习。以 TensorFlow 为例,请使用 tensorflow-gpu 库,而不是标准 Tensorflow 库。
定义模式 − 导入所需库后,必须定义机器学习模型。允许 GPU 加速的神经网络、决策树和其他机器学习算法都可以用作模型。
编译模型 - 构建模型后,您必须通过定义指标、优化器和损失函数来编译它。此外,还必须在此阶段指定输入形状、输出形状和模型隐藏层的数量。
拟合模型 - 构建模型后,您可以通过确定批次大小、时期数和验证分割来将数据拟合到模型中。要使用 CPU 或 GPU 进行计算,您还必须提及这一点。通过将"use_gpu"选项设置为"True"来使用 GPU。
评估模型 - 在模型拟合后计算准确度、精确度、召回率和 F1 分数,您可以评估其性能。还可以使用多个绘图库(包括 matplotlib 和 sea born)来可视化结果。
在 Google Colab 中使用 GPU 的代码示例
Google colab 为您提供了选择 CPU 或 GPU 来训练机器学习模型的功能。您将在运行时部分找到它并更改运行时。因此,您可以在运行时选择 GPU。
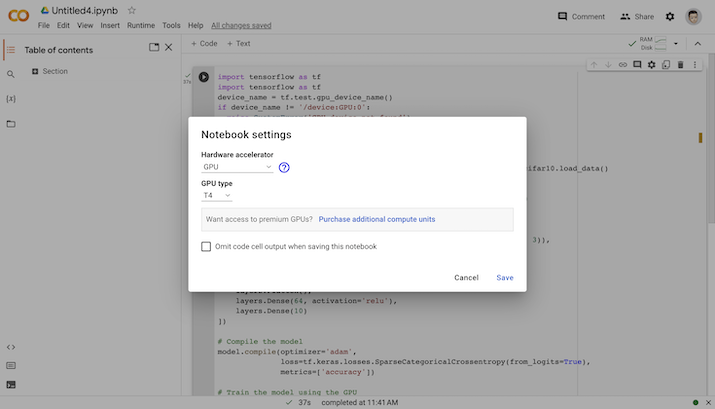
在 Google Colab 中选择 GPU
机器学习中的 GPU
import tensorflow as tf
from tensorflow.keras import datasets, layer, models
# 加载 CIFAR-10 数据集
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 将像素值标准化为 0 到 1 之间
train_images, test_images = train_images / 255.0, test_images / 255.0
# 定义模型架构
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 使用 GPU 训练模型
with tf.device('/GPU:0'):
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
输出
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170498071/170498071 [==============================] - 5s 0us/step Epoch 1/10 1563/1563 [==============================] - 74s 46ms/step - loss: 1.5585 - accuracy: 0.4281 - val_loss: 1.3461 - val_accuracy: 0.5172 Epoch 2/10 1563/1563 [==============================] - 73s 47ms/step - loss: 1.1850 - accuracy: 0.5775 - val_loss: 1.1289 - val_accuracy: 0.5985 Epoch 3/10 1563/1563 [==============================] - 72s 46ms/step - loss: 1.0245 - accuracy: 0.6394 - val_loss: 0.9837 - val_accuracy: 0.6557 Epoch 4/10 1563/1563 [==============================] - 73s 47ms/step - loss: 0.9284 - accuracy: 0.6741 - val_loss: 0.9478 - val_accuracy: 0.6640 Epoch 5/10 1563/1563 [==============================] - 72s 46ms/step - loss: 0.8537 - accuracy: 0.7000 - val_loss: 0.9099 - val_accuracy: 0.6844 Epoch 6/10 1563/1563 [==============================] - 75s 48ms/step - loss: 0.7992 - accuracy: 0.7182 - val_loss: 0.8807 - val_accuracy: 0.6963 Epoch 7/10 1563/1563 [==============================] - 73s 47ms/step - loss: 0.7471 - accuracy: 0.7381 - val_loss: 0.8739 - val_accuracy: 0.7065 Epoch 8/10 1563/1563 [==============================] - 76s 48ms/step - loss: 0.7082 - accuracy: 0.7491 - val_loss: 0.8840 - val_accuracy: 0.6977 Epoch 9/10 1563/1563 [==============================] - 72s 46ms/step - loss: 0.6689 - accuracy: 0.7640 - val_loss: 0.8708 - val_accuracy: 0.7096 Epoch 10/10 1563/1563 [==============================] - 75s 48ms/step - loss: 0.6348 - accuracy: 0.7779 - val_loss: 0.8644 - val_accuracy: 0.7147
计算是在 GPU 上借助 tf.device('/GPU:0') 上下文管理器完成的。
结论
使用 GPU 进行机器学习可以显著提高模型的性能,并且训练时间可以从几天缩短到几小时甚至几分钟。在使用 GPU 进行机器学习之前,您必须先通过安装所需的驱动程序和库、检查配置来配置它,然后继续。这将减少运行时间并更快地执行代码。


