了解机器学习中的训练和分割标准
在机器学习领域,训练-测试分割是一种简单而有效的方法。本质上,它需要将数据集分成两个独立的集合,一个用于训练模型,另一个用于评估其正确性。可以使用此方法评估模型根据新数据进行预测的效率。您可以通过为模型提供一个未经训练的全新数据集来评估模型的泛化效果,从而评估其在现实世界中的表现。训练-测试分割本质上是对模型功能的"现实检查",让您更好地了解其优缺点。这使您能够调整和改进模型以更好地实现目标,最终产生更准确、更可靠的预测。我们将在本文中研究训练和拆分标准,包括其重要性和实际应用。
什么是训练测试拆分?
机器学习中的训练测试拆分涉及将数据集拆分为两个不同的集合:一个用于训练模型,另一个用于评估其性能。这种拆分的目的是评估模型对假设数据的精度,这对于确保模型能够有效地推广并在实践中产生精确的预测至关重要。在使用训练集修改其权重和偏差后,可以通过将使用测试集做出的预测与数据集中的实际值进行比较来测试模型。为了确保整个数据集中的数据都是正确的,并且模型没有过度拟合训练集,拆分通常是随机进行的。使用此方法,您可以确保您的模型尽可能精确,并且可以准确预测未来数据。
为什么训练测试分割很重要?
必须使用数据科学来评估机器学习模型对未见数据的有效性。这是因为模型可以在训练的数据集上表现得非常好,但在使用全新的未经测试的数据时表现不佳。换句话说,对训练数据过度拟合的模型在应用于新数据时可能会产生错误的预测。当模型变得过于复杂时,就会发生过度拟合,模型开始记住训练数据而不是学习底层模式。这会导致模型对训练数据集过度调整,在测试集上表现不佳。为了避免过度拟合,并确保模型在实际应用中准确可靠,评估其在未观察数据上的表现非常重要。
了解训练测试分割的标准
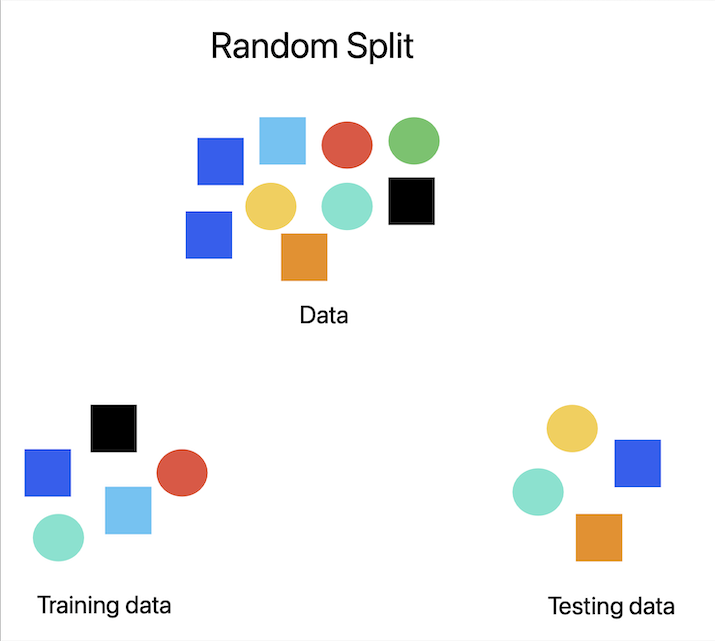
随机分割
数据分割最常通过随机分割进行。数据被随机分成两组,通常 70% 用于训练,30% 用于测试。当数据中没有您希望保留在测试集中的固有模式或结构时,这种方法非常有用。随机分割的好处是确保训练集和测试集代表整个数据集,从而降低过度拟合的可能性。
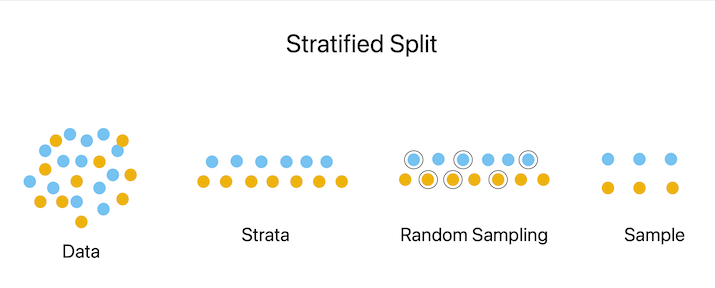
分层分割
在分层分割中,通过根据该变量将数据分割成子集,可以保留训练集和测试集中特定变量的分布。当处理不平衡的数据集时(即每个类的示例数量不相等),此标准非常有用。分层分割可以通过确保训练集和测试集的每个类具有相同数量的案例来帮助提高模型的精度。
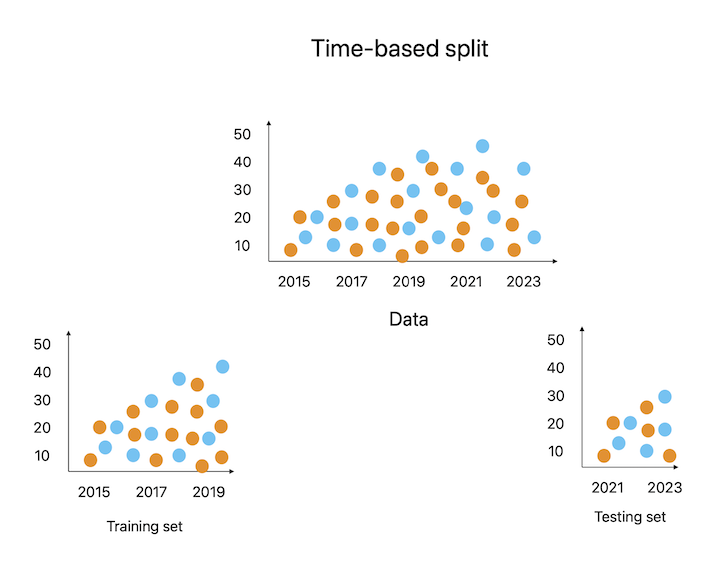
基于时间的分割
在基于时间的分割中,数据根据时间分为子组。处理时间序列数据时,事件发生的顺序很重要,因此经常使用此方法。在基于时间的分割中,测试集通常包含某个时间点之后发生的所有事件,而训练集通常包含该时刻之前发生的所有实例。在时间序列预测中,必须根据历史数据对模型进行训练,并根据预期数据进行评估。
K 折交叉验证
K 折交叉验证涉及将数据分成 K 个子集或折,使用每个折作为测试集,其余 K-1 折作为训练集。在此过程的 K 次过程中,每个折叠都用作测试集一次。当处理较小的数据集时,可能没有足够的信息来划分训练集和测试集,K 折交叉验证非常有用。

结论
机器学习中的训练测试拆分是确保您的模型能够有效概括并对全新的、未经试验的数据做出准确预测的重要阶段。数据可以分为两个子集,以便您的模型可以在一个集合上进行训练,同时在另一个集合上进行评估,从而产生最终更准确的预测。然而,选择适当的数据拆分标准的重要性不容小觑。根据数据类型和您尝试解决的问题,一些标准可能比其他标准更合适。可以提高模型的准确性,避免过度拟合,并保证模型对全新、未经测试的数据的弹性。总之,在不同情况下使用不同标准的优势最终可能会提供更准确、更可靠的机器学习模型。


