SAS - 数据集排序
SAS 中的数据集可以根据其中存在的任何变量进行排序。 这有助于数据分析和执行其他选项,如合并等。排序可以发生在任何单个变量以及多个变量上。 用于在 SAS 数据集中进行排序的 SAS 过程被命名为 PROC SORT。 排序后的结果存储在一个新的数据集中,原始数据集保持不变。
语法
SAS 中数据集中排序操作的基本语法是 −
PROC SORT DATA = original dataset OUT = Sorted dataset; BY variable name;
以下是使用的参数说明 −
variable name 是发生排序的列名。
Original dataset 是要排序的数据集名称。
Sorted dataset 是排序后的数据集名称。
示例
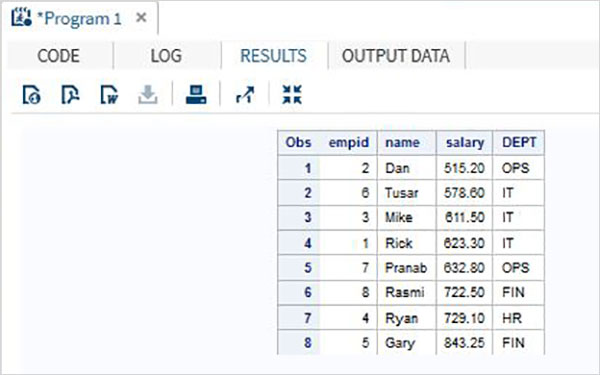
让我们考虑以下包含组织员工详细信息的 SAS 数据集。 我们可以使用下面给出的代码对薪水数据集进行排序。
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_sal ; BY salary; RUN ; PROC PRINT DATA = Sorted_sal; RUN ;
当上面的代码执行时,我们得到如下输出。
降序(反向排序)
默认排序选项是按升序排列的,这意味着观察值按照排序变量的从低到高排列。 但我们也可能希望排序按升序进行。
示例
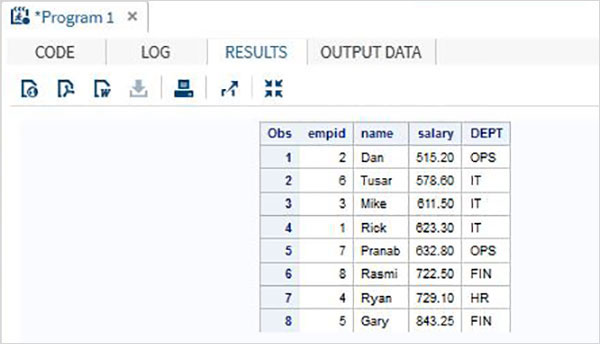
在下面的代码中,反向排序是通过使用 DESCENDING 语句实现的。
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_sal_reverse ; BY DESCENDING salary; RUN ; PROC PRINT DATA = Sorted_sal_reverse; RUN ;
当上面的代码执行时,我们得到如下输出。
对多个变量进行排序
通过将它们与 BY 语句一起使用,可以将排序应用于多个变量。 变量按从左到右的优先级排序。
示例
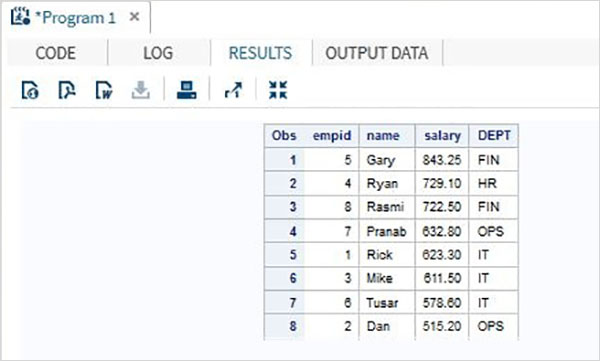
在下面的代码中,数据集首先按变量部门名称排序,然后按变量名称薪水排序。
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC SORT DATA = Employee OUT = Sorted_dept_sal ; BY salary DEPT; RUN ; PROC PRINT DATA = Sorted_dept_sal; RUN ;
当上面的代码执行时,我们得到如下输出。