Python 中的逻辑回归 - 准备数据
为了创建分类器,我们须以分类器构建模块要求的格式准备数据。 通过执行 One Hot Encoding 来准备数据。
编码数据
讨论我们所说的编码数据的含义。 首先,让我们运行一下代码。 在代码窗口中运行以下命令。
In [10]: # creating one hot encoding of the categorical columns. data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])
正如评论所说,上面的语句将创建数据的唯一热编码。 让我们看看它创造了什么? 通过打印数据库中的头记录来检查名为"data"的创建数据。
In [11]: data.head()
您将看到以下输出 −
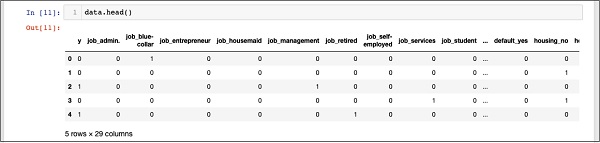
为了理解上述数据,我们将通过运行 data.columns 命令列出列名,如下所示 −
In [12]: data.columns Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown', 'default_no', 'default_unknown', 'default_yes', 'housing_no', 'housing_unknown', 'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
现在,我们将解释如何通过 get_dummies 命令进行单热编码。新生成的数据库中的第一列是"y"字段,表示该客户端是否订阅了 TD。现在,让我们看一下编码的列。 第一个编码列是 "job"。在数据库中,你会发现"job"列有很多可能的值,比如"admin"、"blue-collar"、"entrepreneur"等等。对于每个可能的值,我们在数据库中创建了一个新列,并附加了列名作为前缀。
因此,我们有名为"job_admin"、"job_blue-collar"等的列。 对于我们原始数据库中的每个编码字段,您会在创建的数据库中找到一个列列表,其中包含该列在原始数据库中采用的所有可能值。 仔细检查列的列表以了解数据是如何映射到新数据库的。
了解数据映射
为了理解生成的数据,让我们使用数据命令打印出整个数据。 运行该命令后的部分输出如下所示。
In [13]: data
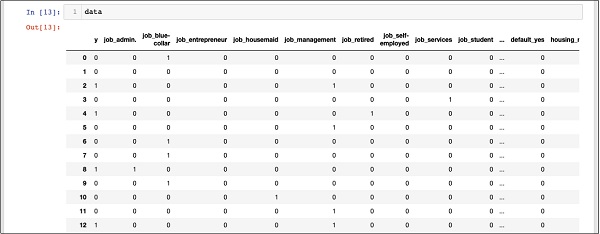
上面的屏幕显示了前十二行。 如果进一步向下滚动,您会看到所有行都完成了映射。
此处显示了数据库下方的部分屏幕输出,供您快速参考。
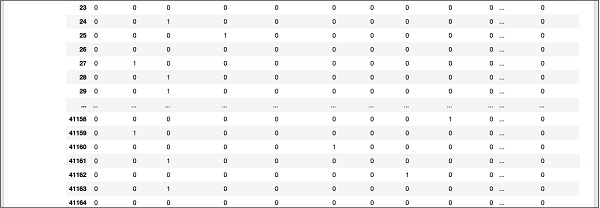
要了解映射数据,让我们检查第一行。

它表示该客户尚未订阅 TD,如"y"字段中的值所示。这也表明该客户是"蓝领"客户。 水平向下滚动,它会告诉你他有"住房",没有"贷款"。
在这一次热编码之后,我们需要更多的数据处理才能开始构建我们的模型。
去掉"unknown"
如果我们检查映射数据库中的列,您会发现很少有以"unknown"结尾的列。 例如,使用屏幕截图中显示的以下命令检查索引 12 处的列 −
In [14]: data.columns[12] Out[14]: 'job_unknown'
这表示指定客户的工作未知。 显然,在我们的分析和模型构建中包含这些列是没有意义的。 因此,所有具有"unknown"值的列都应该被删除。 这是通过以下命令完成的 −
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)
确保您指定了正确的列号。 如有疑问,您可以随时通过在列命令中指定其索引来检查列名,如前所述。
删除不需要的列后,您可以检查最终的列列表,如以下输出所示 −
In [16]: data.columns Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'marital_divorced', 'marital_married', 'marital_single', 'default_no', 'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
至此,我们的数据已准备好用于模型构建。

