Keras - 模型编译
之前,我们学习了如何使用顺序和函数 API 创建模型的基础知识。本章介绍如何编译模型。编译是创建模型的最后一步。编译完成后,我们就可以进入训练阶段了。
让我们学习一些概念,以便更好地理解编译过程。
损失
在机器学习中,损失函数用于在学习过程中查找错误或偏差。Keras 在模型编译过程中需要损失函数。
Keras 在 losses 模块中提供了相当多的损失函数,它们如下 −
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- squared_hinge
- hinge
- categorical_hinge
- logcosh
- huber_loss
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson
- cosine_proximity
- is_categorical_crossentropy
以上所有损失函数都接受两个参数−
y_true − true 标签作为张量
y_pred − 与 y_true 具有相同形状的预测
在使用损失函数之前,请先导入损失模块,如下所示 −
from keras import losses
优化器
在机器学习中,优化是一个重要的过程,它通过比较预测和损失函数来优化输入权重。 Keras 提供了相当多的优化器作为模块,optimizers,它们如下::
SGD − 随机梯度下降优化器。
keras.optimizers.SGD(learning_rate = 0.01, motivation = 0.0, nesterov = False)
RMSprop − RMSProp 优化器。
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)
Adagrad − Adagrad 优化器。
keras.optimizers.Adagrad(learning_rate = 0.01)
Adadelta − Adadelta 优化器。
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)
Adam − Adam 优化器。
keras.optimizers.Adam( learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False )
Adamax − Adam 的 Adamax 优化器。
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)
Nadam − Nesterov Adam 优化器。
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)
使用优化器之前,请先导入优化器模块,如下所示 −
from keras import optimizers
Metrics(指标)
在机器学习中,Metrics(指标)用于评估模型的性能。它类似于损失函数,但不用于训练过程。 Keras 以模块形式提供了相当多的指标,metrics,它们如下
- accuracy
- binary_accuracy
- categorical_accuracy
- sparse_categorical_accuracy
- top_k_categorical_accuracy
- sparse_top_k_categorical_accuracy
- cosine_proximity
- clone_metric
与损失函数类似,metrics 也接受以下两个参数 −
y_true − true 标签作为张量
y_pred −与 y_true 形状相同的预测
在使用指标之前,请先导入指标模块,如下所示 −
from keras import metrics
编译模型
Keras 模型提供了一种方法 compile() 来编译模型。compile() 方法的参数和默认值如下
compile( optimizer, loss = None, metrics = None, loss_weights = None, sample_weight_mode = None, weighted_metrics = None, target_tensors = None )
重要参数如下 −
- loss function
- Optimizer
- metrics
编译模式的示例代码如下 −
from keras import losses from keras import optimizers from keras import metrics model.compile(loss = 'mean_squared_error', optimizer = 'sgd', metrics = [metrics.categorical_accuracy])
其中,
loss 函数设置为 mean_squared_error
optimizer 设置为 sgd
metrics 设置为 metrics.categorical_accuracy
模型训练
使用 fit() 通过 NumPy 数组训练模型。此 fit 函数的主要目的是评估训练中的模型。这也可以用于绘制模型性能图表。它具有以下语法 −
model.fit(X, y, epochs = , batch_size = )
这里,
X, y − 它是一个用于评估数据的元组。
epochs − 训练期间需要评估模型的次数。
batch_size − 训练实例。
让我们以 numpy 随机数据的简单示例来使用这个概念。
创建数据
让我们在下面提到的命令的帮助下使用 numpy 为 x 和 y 创建随机数据 −
import numpy as np x_train = np.random.random((100,4,8)) y_train = np.random.random((100,10))
现在,创建随机验证数据,
x_val = np.random.random((100,4,8)) y_val = np.random.random((100,10))
创建模型
让我们创建简单的顺序模型 −
from keras.models import Sequential model = Sequential()
添加层
创建层以添加模型 −
from keras.layers import LSTM, Dense # 添加维度为 16 的向量序列 model.add(LSTM(16, return_sequences = True)) model.add(Dense(10,activation = 'softmax'))
编译模型
现在模型已定义。您可以使用以下命令进行编译−
model.compile( loss = 'categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy'] )
应用 fit()
现在我们应用 fit() 函数来训练我们的数据 −
model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data = (x_val, y_val))
创建多层感知器 ANN
我们已经学会了创建、编译和训练 Keras 模型。
让我们应用我们的学习并创建一个简单的基于 MPL 的 ANN。
数据集模块
在创建模型之前,我们需要选择一个问题,需要收集所需的数据并将数据转换为 NumPy 数组。一旦收集到数据,我们就可以准备模型并使用收集到的数据对其进行训练。数据收集是机器学习最困难的阶段之一。 Keras 提供了一个特殊的模块 datasets,用于下载在线机器学习数据以进行训练。它从在线服务器获取数据,处理数据并将数据作为训练和测试集返回。让我们检查一下 Keras 数据集模块提供的数据。模块中可用的数据如下,
- CIFAR10 小图像分类
- CIFAR100 小图像分类
- IMDB 电影评论情绪分类
- 路透社新闻专线主题分类
- 手写数字的 MNIST 数据库
- 时尚文章的 Fashion-MNIST 数据库
- 波士顿房价回归数据集
让我们使用 MNIST 手写数字数据库(或 minst)作为输入。minst 是 60,000 个 28x28 灰度图像的集合。它包含 10 个数字。它还包含 10,000 张测试图像。
以下代码可用于加载数据集 −
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
其中
第 1 行 从 keras 数据集模块导入 minst。
第 3 行 调用 load_data 函数,该函数将从在线服务器获取数据并将数据作为 2 个元组返回,第一个元组 (x_train, y_train) 表示形状为 (number_sample, 28, 28) 的训练数据及其形状为 (number_samples, ) 的数字标签。第二个元组 (x_test, y_test) 表示具有相同形状的测试数据。
也可以使用类似的 API 获取其他数据集,并且每个 API 也返回类似的数据,只是数据形状不同。数据的形状取决于数据的类型。
创建模型
让我们选择一个简单的多层感知器 (MLP),如下所示,并尝试使用 Keras 创建模型。
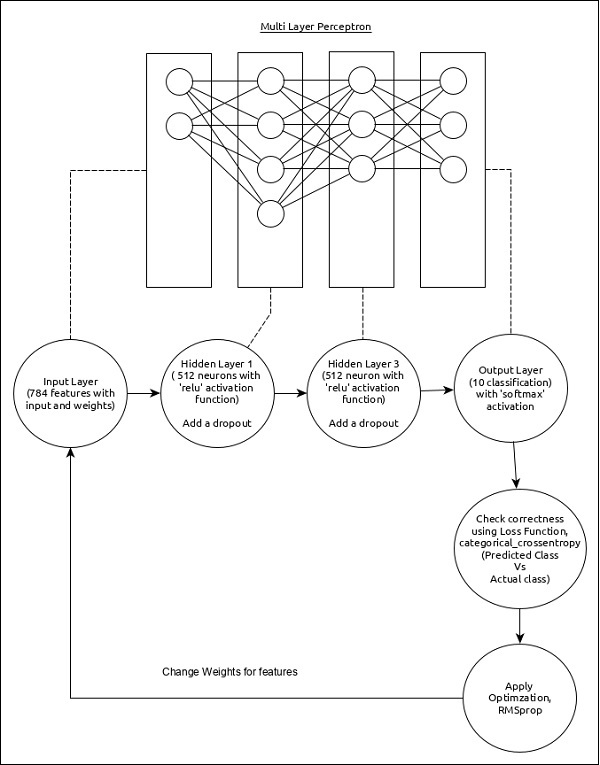
该模型的核心功能如下 −
输入层由 784 个值组成 (28 x 28 = 784)。
第一个隐藏层,Dense,由 512 个神经元和"relu"激活函数组成。
第二个隐藏层,Dropout,其值为 0.2。
第三个隐藏层,同样是 Dense,由以下层组成512 个神经元和"relu"激活函数。
第四个隐藏层,Dropout 的值为 0.2。
第五层和最后一层由 10 个神经元和"softmax"激活函数组成。
使用 categorical_crossentropy 作为损失函数。
使用 RMSprop() 作为优化器。
使用 accuracy 作为指标。
使用 128 作为批次大小。
使用 20 作为时期。
步骤 1 −导入模块
让我们导入必要的模块。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.optimizers import RMSprop import numpy as np
步骤 2 − 加载数据
让我们导入 mnist 数据集。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
步骤 3 − 处理数据
让我们根据我们的模型更改数据集,以便可以将其输入到我们的模型中。
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
其中
reshape 用于将输入从 (28, 28) 元组重塑为 (784, )
to_categorical 用于将向量转换为二进制矩阵
步骤 4 −创建模型
让我们创建实际的模型。
model = Sequential() model.add(Dense(512,activation = 'relu',input_shape = (784,))) model.add(Dropout(0.2)) model.add(Dense(512,activation = 'relu')) model.add(Dropout(0.2)) model.add(Dense(10,activation = 'softmax'))
步骤 5 −编译模型
让我们使用选定的损失函数、优化器和指标来编译模型。
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
步骤 6 − 训练模型
让我们使用 fit() 方法训练模型。
history = model.fit( x_train, y_train, batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test) )
最终想法
我们已经创建了模型,加载了数据,并将数据训练到模型中。 我们仍然需要评估模型并预测未知输入的输出,我们将在下一章中学习这一点。
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test))
执行应用程序将输出以下内容 −
Train on 60000 samples, validate on 10000 samples Epoch 1/20 60000/60000 [==============================] - 7s 118us/step - loss: 0.2453 - acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.1023 - acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.0744 - acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20 60000/60000 [==============================] - 7s 110us/step - loss: 0.0599 - acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0504 - acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20 60000/60000 [==============================] - 7s 111us/step - loss: 0.0438 - acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20 60000/60000 [==============================] - 7s 114us/step - loss: 0.0391 - acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0364 - acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20 60000/60000 [==============================] - 7s 113us/step - loss: 0.0308 - acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0289 - acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0279 - acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0260 - acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0257 - acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0229 - acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20 60000/60000 [==============================] - 7s 115us/step - loss: 0.0235 - acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20 60000/60000 [==============================] - 7s 113us/step - loss: 0.0214 - acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0219 - acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0190 - acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0197 - acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20 60000/60000 [==============================] - 7s 112us/step - loss: 0.0198 - acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828


