数据仓库 - 分区策略
分区的目的是提高性能并促进数据的轻松管理。 分区还有助于平衡系统的各种要求。 它通过将每个事实表划分为多个单独的分区来优化硬件性能并简化数据仓库的管理。 在本章中,我们将讨论不同的分区策略。
为什么需要分区?
分区很重要,原因如下 −
- 为了便于管理,
- 为了协助备份/恢复,
- 提高性能。
方便管理
数据仓库中的事实表的大小可以增长到数百GB。 如此巨大的事实表很难作为单个实体进行管理。 因此需要分区。
协助备份/恢复
如果我们不对事实表进行分区,那么我们必须加载包含所有数据的完整事实表。 分区允许我们只加载定期所需的数据。 它减少了加载时间并增强了系统的性能。
注意 − 为了减少备份大小,当前分区以外的所有分区都可以标记为只读。 然后我们就可以将这些分区置于不可修改的状态。 然后就可以备份它们了。 表示只备份当前分区。
提高性能
通过将事实表划分为数据集,可以增强查询过程。 查询性能得到增强,因为现在查询仅扫描那些相关的分区。 它不必扫描整个数据。
水平分区
事实表的分区方式有很多种。 在水平分区时,我们要考虑到数据仓库的可管理性要求。
按时间划分为相等的段
在此分区策略中,事实表根据时间段进行分区。 这里每个时间段都代表企业内的一个重要保留期。 例如,如果用户查询本月至今的数据,那么将数据划分为每月段是合适的。 我们可以通过删除分区表中的数据来重用分区表。
按时间划分为不同大小的段
这种分区是在不经常访问老化数据的情况下进行的。 它被实现为一组用于相对当前数据的小分区,用于非活动数据的较大分区。
注意事项
详细信息仍然可以在线获取。
物理表数量保持相对较少,从而降低了运营成本。
此技术适用于需要混合使用近期历史数据和整个历史数据挖掘的情况。
当分区配置文件定期更改时,此技术没有用,因为重新分区会增加数据仓库的运营成本。
不同维度上的分区
事实表还可以根据时间以外的维度进行分区,例如产品组、区域、供应商或任何其他维度。 让我们举个例子。
假设市场功能已被构建为不同的区域部门,例如逐个州。 如果每个区域想要查询在其区域内捕获的信息,则将事实表划分为区域分区将被证明更有效。 这将导致查询速度加快,因为它不需要扫描不相关的信息。
注意事项
查询不必扫描不相关的数据,从而加快了查询过程。
如果尺寸将来不太可能改变,则此技术不合适。 因此,值得确定尺寸将来不会改变。
如果维度发生变化,则整个事实表必须重新分区。
注意 − 我们建议仅根据时间维度执行分区,除非您确定建议的维度分组在数据仓库的生命周期内不会发生变化。
按表大小分区
当在任何维度上对事实表进行分区都没有明确的依据时,那么我们应该根据事实表的大小对事实表进行分区。我们可以将预定的大小设置为临界点。 当表超过预定大小时,将创建新的表分区。
注意事项
这种分区管理起来很复杂。
它需要元数据来识别每个分区中存储的数据。
分区维度
如果一个维度包含大量条目,则需要对维度进行分区。 这里我们必须检查维度的大小。
考虑一个随时间变化的大型设计。 如果我们需要存储所有变化以便进行比较,那么该维度可能会非常大。 这肯定会影响响应时间。
循环分区
在循环技术中,当需要新分区时,旧分区将被存档。 它使用元数据允许用户访问工具引用正确的表分区。
这种技术可以轻松实现数据仓库内表管理设施的自动化。
垂直分区
垂直分区,垂直分割数据。 下图描述了如何完成垂直分区。
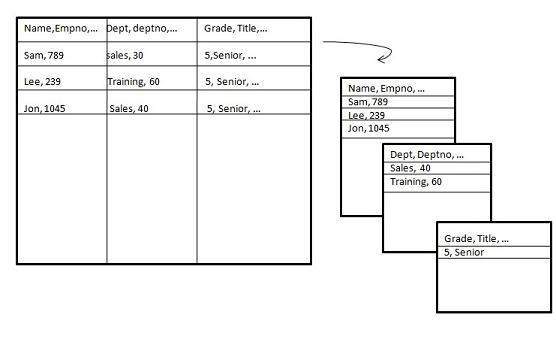
垂直分区可以通过以下两种方式进行 −
- 标准化
- 行分割
标准化
规范化是数据库组织的标准关系方法。 在这种方法中,行被折叠成一行,因此减少了空间。 查看下表,了解如何执行标准化。
标准化前的表格
| Product_id | Qty | Value | sales_date | Store_id | Store_name | Location | Region |
|---|---|---|---|---|---|---|---|
| 30 | 5 | 3.67 | 3-Aug-13 | 16 | sunny | Bangalore | S |
| 35 | 4 | 5.33 | 3-Sep-13 | 16 | sunny | Bangalore | S |
| 40 | 5 | 2.50 | 3-Sep-13 | 64 | san | Mumbai | W |
| 45 | 7 | 5.66 | 3-Sep-13 | 16 | sunny | Bangalore | S |
标准化后的表格
| Store_id | Store_name | Location | Region |
|---|---|---|---|
| 16 | sunny | Bangalore | W |
| 64 | san | Mumbai | S |
| Product_id | Quantity | Value | sales_date | Store_id |
|---|---|---|---|---|
| 30 | 5 | 3.67 | 3-Aug-13 | 16 |
| 35 | 4 | 5.33 | 3-Sep-13 | 16 |
| 40 | 5 | 2.50 | 3-Sep-13 | 64 |
| 45 | 7 | 5.66 | 3-Sep-13 | 16 |
行分割
行分割往往会在分区之间留下一对一的映射。 行拆分的动机是通过减小大表的大小来加速对大表的访问。
注意 − 使用垂直分区时,请确保不需要在两个分区之间执行主要连接操作。
识别分区键
选择正确的分区键非常重要。 选择错误的分区键将导致事实表的重新组织。 让我们举个例子。 假设我们要对下表进行分区。
Account_Txn_Table transaction_id account_id transaction_type value transaction_date region branch_name
我们可以选择在任何键上进行分区。 两个可能的键可能是
- region
- transaction_date
假设该企业分布在 30 个地理区域,每个区域有不同数量的分支机构。 这将为我们提供 30 个分区,这是合理的。 这种分区足够好,因为我们的需求捕获表明绝大多数查询仅限于用户自己的业务区域。
如果我们按 transaction_date 而不是按区域分区,那么每个区域的最新交易将位于一个分区中。 现在用户想要查看自己区域内的数据就必须跨多个分区查询。
因此,确定正确的分区键是值得的。


