数据挖掘 - 挖掘万维网
万维网包含大量信息,为数据挖掘提供了丰富的资源。
网络挖掘面临的挑战
根据以下观察,网络对资源和知识发现提出了巨大的挑战−
网络太大了 − 网络的规模非常巨大并且正在迅速增长。 对于数据仓库和数据挖掘来说,网络似乎太大了。
网页的复杂性 − 网页没有统一的结构。 与传统的文本文档相比,它们非常复杂。 网络数字图书馆中有海量的文献。 这些库没有按照任何特定的排序顺序排列。
网络是动态信息源 − 网络上的信息更新很快。 新闻、股市、天气、体育、购物等数据定期更新。
用户社区的多样性 − 网络上的用户社区正在迅速扩大。 这些用户有不同的背景、兴趣和使用目的。 连接到互联网的工作站超过 1 亿个,并且仍在快速增长。
信息的相关性 − 人们认为,特定的人通常只对网络的一小部分感兴趣,而网络的其余部分包含与用户不相关的信息并且可能淹没期望的结果。
挖掘网页布局结构
网页的基本结构基于文档对象模型(DOM)。 DOM结构是指一种树状结构,其中页面中的HTML标签对应于DOM树中的节点。 我们可以使用 HTML 中预定义的标签来分割网页。 HTML 语法非常灵活,因此网页不遵循 W3C 规范。 不遵循W3C规范可能会导致DOM树结构出现错误。
DOM结构最初是为了在浏览器中呈现而引入的,而不是为了描述网页的语义结构。 DOM结构无法正确识别网页不同部分之间的语义关系。
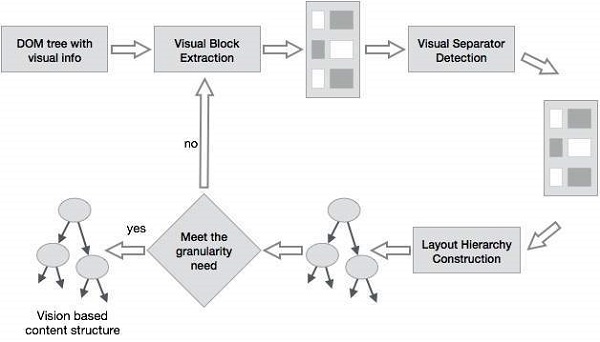
基于视觉的页面分割 (VIPS)
VIPS 的目的是根据网页的视觉呈现来提取网页的语义结构。
这样的语义结构对应于树结构。 在这棵树中,每个节点对应一个块。
为每个节点分配一个值。 该值称为相干度。 该值被分配来指示基于视觉感知的块中的连贯内容。
VIPS 算法首先从 HTML DOM 树中提取所有合适的块。 之后它会找到这些块之间的分隔符。
分隔符是指网页中视觉上没有遮挡的水平或垂直线。
网页的语义就是在这些块的基础上构建的。
下图为VIPS算法流程 −