Amazon Web Services - Elastic MapReduce
Amazon Elastic MapReduce (EMR) 是一种 Web 服务,它提供托管框架,以简单、经济高效且安全的方式运行 Apache Hadoop、Apache Spark 和 Presto 等数据处理框架。
它用于数据分析、Web 索引、数据仓库、财务分析、科学模拟等。
如何设置 Amazon EMR?
按照以下步骤设置 Amazon EMR −
步骤 1 − 登录 AWS 帐户并在管理控制台上选择 Amazon EMR。
步骤 2 − 为集群日志和输出数据创建 Amazon S3 存储桶。(过程在 Amazon S3 部分中有详细说明)
步骤 3 −启动 Amazon EMR 集群。
以下是创建集群并将其启动到 EMR 的步骤。
使用此链接打开 Amazon EMR 控制台 − https://console.aws.amazon.com/elasticmapreduce/home
选择创建集群并在集群配置页面上提供所需的详细信息。
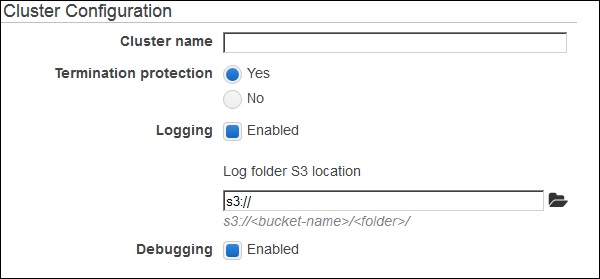
将标签部分选项保留为默认值并继续。
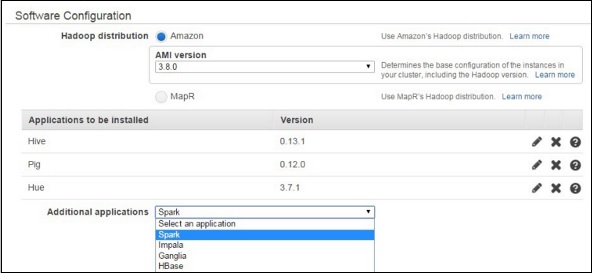
在软件配置部分,将选项设置为默认值。
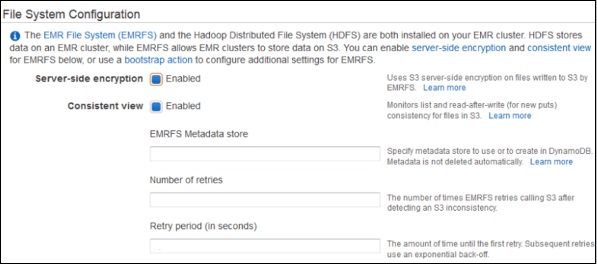
在文件系统配置部分,保留选项默认设置为 EMRFS。EMRFS 是 HDFS 的一种实现,它允许 Amazon EMR 集群将数据存储在 Amazon S3 上。
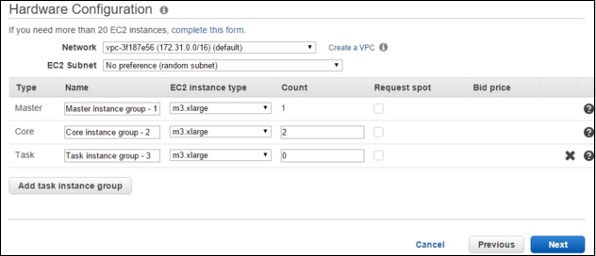
在"硬件配置"部分,在 EC2 实例类型字段中选择 m3.xlarge,其他设置保留为默认设置。单击下一步按钮。
在安全和访问部分,对于 EC2 密钥对,从 EC2 密钥对字段的列表中选择该对,并将其他设置保留为默认设置。
在引导操作部分,将字段保留为默认设置,然后单击添加按钮。引导操作是在每个集群节点上启动 Hadoop 之前在设置期间执行的脚本。
在步骤部分,将设置保留为默认设置并继续。
单击创建集群按钮,将打开集群详细信息页面。在这里,我们应该将 Hive 脚本作为集群步骤运行,并使用 Hue Web 界面查询数据。
步骤 4 − 使用以下步骤运行 Hive 脚本。
打开 Amazon EMR 控制台并选择所需的集群。
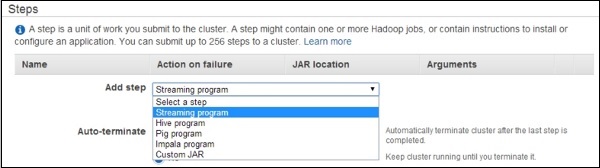
移至"步骤"部分并展开它。然后单击"添加步骤"按钮。
将打开"添加步骤"对话框。填写必填字段,然后单击"添加"按钮。
要查看 Hive 脚本的输出,请使用以下步骤 −
打开 Amazon S3 控制台并选择用于输出数据的 S3 存储桶。
选择输出文件夹。
查询将结果写入单独的文件夹。选择 os_requests。
输出存储在文本文件中。此文件可以下载。
Amazon EMR 的优势
以下是 Amazon EMR 的优势 −
易于使用 − Amazon EMR 易于使用,即易于设置集群、Hadoop 配置、节点配置等。
可靠 −它的可靠性在于它会重试失败的任务并自动替换性能不佳的实例。
弹性 − Amazon EMR 允许计算大量实例以处理任何规模的数据。它可以轻松增加或减少实例数量。
安全 − 它会自动配置 Amazon EC2 防火墙设置、控制对实例的网络访问、在 Amazon VPC 中启动集群等。
灵活 − 它允许完全控制集群并访问每个实例的根目录。它还允许安装其他应用程序并根据需要自定义集群。
经济高效 − 它的价格很容易估算。它按小时对每个使用的实例收费。


