数据流架构
在数据流架构中,整个软件系统被视为对连续的输入数据或输入数据集合进行的一系列转换,其中数据和操作彼此独立。在这种方法中,数据进入系统,然后逐个流经模块,直到它们被分配到某个最终目的地(输出或数据存储)。
组件或模块之间的连接可以实现为 I/O 流、I/O 缓冲区、管道或其他类型的连接。数据可以在具有循环的图形拓扑中、无循环的线性结构中或树型结构中流动。
这种方法的主要目标是实现重用和可修改性。它适用于涉及对有序定义的输入和输出进行一系列明确定义的独立数据转换或计算的应用程序,例如编译器和业务数据处理应用程序。模块之间有三种执行顺序−
- 批量顺序
- 管道和过滤器或非顺序管道模式
- 过程控制
批量顺序
批量顺序是一种经典的数据处理模型,其中数据转换子系统只有在其前一个子系统完全完成后才能启动其进程−
数据流将一批数据作为一个整体从一个子系统传送到另一个子系统。
模块之间的通信是通过临时中间文件进行的,这些中间文件可以由后续子系统删除。
它适用于那些数据被批处理的应用程序,每个子系统读取相关的输入文件并写入输出文件。
这种架构的典型应用包括银行和公用事业等业务数据处理计费。

优点
提供更简单的子系统划分。
每个子系统都可以是一个独立的程序,处理输入数据并产生输出数据。
缺点
提供高延迟和低吞吐量。
不提供并发性和交互界面。
需要外部控制才能实现。
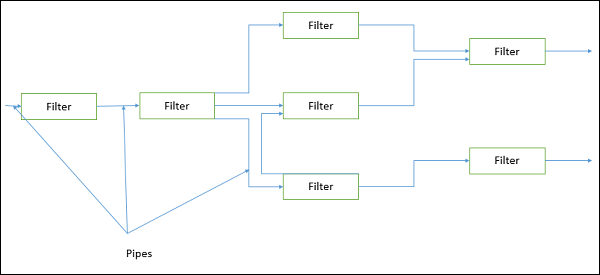
管道和过滤器架构
这种方法强调通过连续组件对数据进行增量转换。在这种方法中,数据流由数据驱动,整个系统分解为数据源、过滤器、管道和数据接收器的组件。
模块之间的连接是数据流,它是先进先出的缓冲区,可以是字节流、字符流或任何其他类型的流。这种架构的主要特点是其并发和增量执行。
过滤器
过滤器是一个独立的数据流转换器或流传感器。它转换输入数据流的数据,对其进行处理,并将转换后的数据流写入管道,以供下一个过滤器处理。它以增量模式工作,即数据通过连接的管道到达后立即开始工作。有两种类型的过滤器:主动过滤器和被动过滤器。
主动过滤器
主动过滤器允许连接的管道拉入数据并推出转换后的数据。它使用被动管道进行操作,为拉取和推送提供读/写机制。此模式用于 UNIX 管道和过滤器机制。
被动过滤器
被动过滤器让连接的管道将数据推送入和拉出。它与主动管道一起运行,主动管道从一个过滤器拉出数据并将数据推送到下一个过滤器。它必须提供读/写机制。
优点
为过多的数据处理提供并发性和高吞吐量。
提供可重用性并简化系统维护。
提供可修改性和过滤器之间的低耦合。
通过提供管道连接的任意两个过滤器之间的明确划分来提供简单性。
通过支持顺序和并行执行来提供灵活性。
缺点
不适合动态交互。
传输需要低公分母ASCII 格式的数据。
过滤器之间的数据转换开销。
不提供过滤器协作解决问题的方法。
难以动态配置此架构。
管道
管道是无状态的,它们承载着存在于两个过滤器之间的二进制或字符流。它可以将数据流从一个过滤器移动到另一个过滤器。管道使用少量上下文信息,在实例化之间不保留任何状态信息。
过程控制架构
它是一种数据流架构,其中数据既不是批量顺序的也不是流水线流。数据流来自一组变量,这些变量控制着过程的执行。它将整个系统分解为子系统或模块并将它们连接起来。
子系统的类型
过程控制架构将有一个用于更改过程控制变量的处理单元和一个用于计算更改量的控制器单元。
控制器单元必须具有以下元素 −
受控变量 −受控变量为底层系统提供值,应由传感器测量。例如,巡航控制系统中的速度。
输入变量 − 测量过程的输入。例如,温度控制系统中的回风温度
操纵变量 − 操纵变量值由控制器调整或更改。
过程定义 − 它包括操纵某些过程变量的机制。
传感器 − 获取与控制相关的过程变量值,可用作重新计算操纵变量的反馈参考。
设定点 − 它是受控变量的期望值。
控制算法 −它用于决定如何操纵过程变量。
应用领域
过程控制架构适用于以下领域 −
嵌入式系统软件设计,其中系统由过程控制变量数据操纵。
应用程序,其目的是将过程输出的指定属性保持在给定的参考值。
适用于汽车巡航控制和建筑温度控制系统。
用于控制汽车防抱死制动系统、核电站等的实时系统软件。


