Seaborn.clustermap() 方法
Seaborn.clustermap() 方法用于将数据集绘制为分层聚类热图。
聚类地图 是一种交互式地图,当绘制的数据点太多且彼此距离太近以致难以确定变化并从给定数据得出结论时,它非常有用。 也称为气泡图,它衡量集群在不同位置的性能、大小和存在情况。
语法
以下是 seaborn.clustermap() 方法的语法 −
参数
下面讨论了 seaborn.clustermap() 方法的一些参数。
| S.No | 名称和描述 |
|---|---|
| 1 | Data 它以矩形数据集作为输入。 可以强制转换为二维数据集的 ndarray。 如果提供了 Pandas DataFrame,列和行将使用索引和列信息进行标记。 |
| 2 | Vmin, vmax 这个可选参数将浮点值作为输入,这些值用作颜色图锚点; 如果不是,将使用数据和其他关键字参数来推断它们。 |
| 3 | Cmap 此可选参数将 matplotlib 颜色或颜色列表作为输入。 它执行数据值到颜色空间的转换。 如果未指定,默认值将取决于是否设置了 center。 |
| 4 | Metric 获取字符串值并确定用于计算聚类的链接方法。 |
| 5 | Mask 采用 bool 数组或 DataFrame 并且是可选参数。 如果通过,数据将不会显示在 mask 为 True 的单元格中。 |
| 6 | Standard_scale 此可选参数采用整数值和一或零行或列。 传递的值决定是否对该维度进行标准化,这需要将每行或每列的最大值除以其最小值。 |
| 7 | {row,col}_cluster 采用布尔值,如果传递的是 True,则聚类 {row,column}。 |
| 8 | {row,col}_linkage 将 numpy.ndarray 作为输入,并使用它获得行或列的预计算连接矩阵。 |
| 9 | cbar 采用布尔值并确定是否应绘制颜色条。 |
返回值
此方法返回一个 ClusterGrid 实例。
加载 seaborn 库
让我们在继续开发绘图之前加载 seaborn 库和数据集。 要加载或导入 seaborn 库,可以使用以下代码行。
Import seaborn as sns
加载数据集
在本文中,我们将使用 seaborn 库中内置的航班数据集。 以下命令用于加载数据集。
flights=sns.load_dataset("flights")
下面提到的命令用于查看数据集中的前 5 行。 这使我们能够了解哪些变量可用于绘制图形。
flights.head()
以下是上面这段代码的输出。
index,year,passengers 0,1949,112 1,1949,118 2,1949,132 3,1949,129 4,1949,121
既然我们已经加载了数据集,我们将探索几个例子。
示例 1
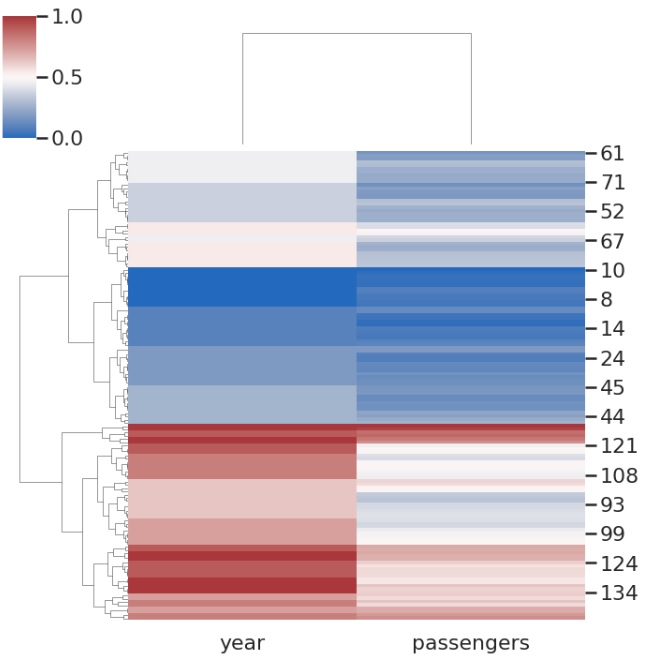
我们正在使用上面提到的航班数据集,因为我们要绘制一个聚类图,我们将不得不从数据集中弹出分类变量。 所以在这种情况下,月份列被弹出/删除,然后生成 clustermap。 然后我们将航班数据帧连同 figsize 和 cmap 参数一起传递给 clustermap 函数。 figsize 参数决定绘图的大小参数,cmap 决定绘图的颜色。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
data=flights.pop('month')
sns.clustermap(flights, cmap='vlag', figsize=(7, 7))
plt.show()
输出
示例 2
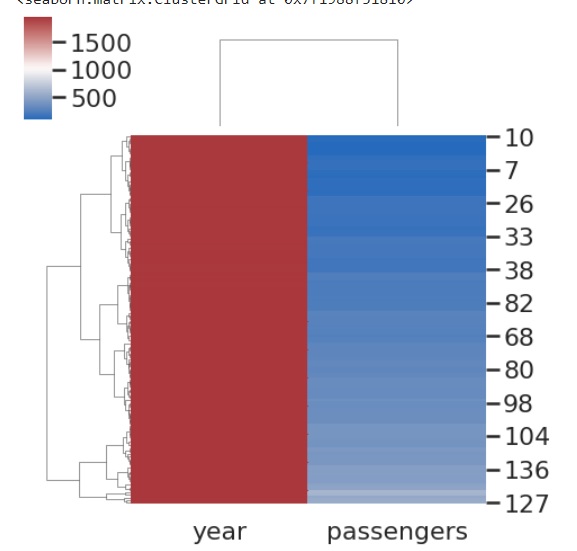
在这个例子中,我们将传递 vmin 和 vmax 参数以及 cmap 和数据帧。 Vmax 和 vmin 是可选参数,将浮点值作为输入,这些值用作颜色图锚点; 如果不是,将使用数据和其他关键字参数来推断它们。 当这些通过时,我们会注意到的变化,
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, cmap="mako", vmin=0, vmax=1000)
plt.show()
输出
示例 3
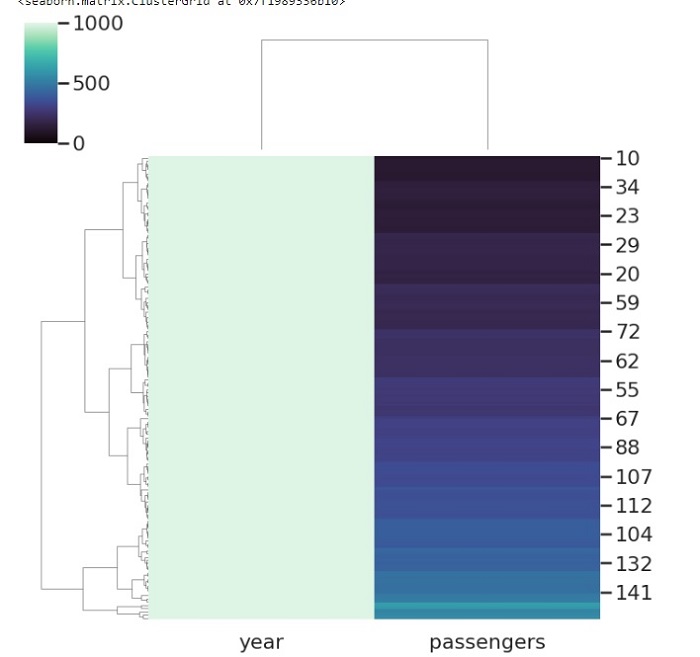
Metric 是一个非常有用的参数,它是 seaborn 库中 clustermap() 方法的一部分。 它采用字符串值并确定用于计算聚类的链接方法。
在下面的代码中,我们在 clustermap 函数中传递 flights 数据框以及 metric 参数。 度量参数采用不同的值,我们在此示例中传递相关性。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, metric="correlation")
plt.show()
输出
示例 4
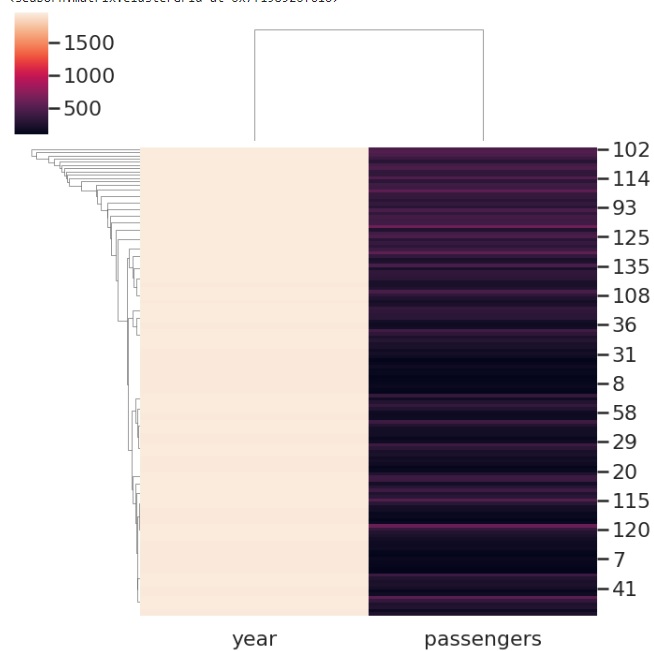
Standard_scale 是另一个常用的参数,在下面的示例中,我们将使用此参数并获取航班数据集上的聚类图。
standard_scale 是一个可选参数,采用整数值和一或零行或列。 传递的值决定是否对该维度进行标准化,这需要将每行或每列的最大值除以其最小值。
import seaborn as sns
import matplotlib.pyplot as plt
flights=sns.load_dataset("flights")
flights.head()
sns.clustermap(flights, standard_scale=1,cmap="vlag")
plt.show()
输出
运行上面这行代码得到的图如下,