Seaborn.barplot() 方法
Seaborn.barplot() 方法用于将点估计和置信区间显示为矩形条。 每个矩形的高度代表对数值变量的集中趋势的估计,条形图还通过误差条显示围绕该估计的不确定性程度。
当 0 是定量变量的一个有意义的值并且您想与其进行比较时,在定量轴范围内包含 0 的条形图是一个很好的选择。 点图将使您能够专注于数据集中一个或多个分类变量水平之间的差异,其中 0 不是有意义的值。
语法
以下是 seaborn.barplot() 方法的语法 −
seaborn.barplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean at 0x7ff320f315e0>, ci=95, n_boot=1000, units=None, seed=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None, capsize=None, dodge=True, ax=None, **kwargs
参数
seaborn.barplot()方法的部分参数如下 −
| S.No | 名称和描述 |
|---|---|
| 1 | x,y 这些参数将变量名称作为绘制长格式数据的输入。 |
| 2 | data 这是用于绘制图形的数据框。 |
| 3 | hue 数据框中绘制图形所需的变量名称。 |
| 4 | linewidth 此参数采用浮动值并确定构成图中元素的灰线的宽度。 |
| 5 | dodge 此参数采用布尔值。 如果我们使用色调嵌套,将 true 传递给此参数将分离不同色调级别的条带。 如果传递了 False,每个级别的点将被绘制在彼此之上。 |
| 6 | orient 它取值"h"或"v",并以此为基础确定图形的方向。 |
| 7 | color matplotlib 颜色作为输入,这决定了所有元素的颜色。 |
| 8 | palette 此参数指定不同色调映射的颜色。 |
| 9 | capsize 将浮点值作为输入并确定误差线上限的宽度。 |
加载 seaborn 库
让我们在继续开发绘图之前加载 seaborn 库和数据集。 要加载或导入 seaborn 库,可以使用以下代码行。
Import seaborn as sns
加载数据集
在本文中,我们将使用 seaborn 库中内置的 Titanic 数据集。 以下命令用于加载数据集。
titanic=sns.load_dataset("titanic")
下面提到的命令用于查看数据集中的前 5 行。 这使我们能够了解哪些变量可用于绘制图形。
titanic.head()
以下是上面这段代码的输出。
index,survived,pclass,sex,age,sibsp,parch,fare,embarked,class,who,adult_male,deck,embark_town,alive,alone 0,0,3,male,22.0,1,0,7.25,S,Third,man,true,NaN,Southampton,no,false 1,1,1,female,38.0,1,0,71.2833,C,First,woman,false,C,Cherbourg,yes,false 2,1,3,female,26.0,0,0,7.925,S,Third,woman,false,NaN,Southampton,yes,true
既然我们已经加载了数据集,我们将探索几个例子。
示例 1
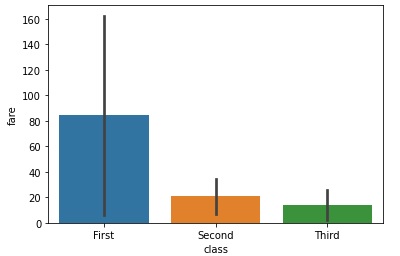
要绘制基本条形图,将参数 x、y 和数据集传递给数据参数就足够了。 在这里,我们使用 titanic(泰坦尼克号)数据集,列 class (类)和 fare (票价)分别传递给 x,y。 由于 barplot 也是一种分类图,因此需要一个分类变量来绘制图形。 可以参考下面一行代码绘制一个简单的barplot()。
import seaborn as sns
import matplotlib.pyplot as plt
titanic=sns.load_dataset("titanic")
titanic.head()
sns.barplot(x="class", y="fare", data=titanic)
plt.show()
输出
得到的输出如下 −
示例 2
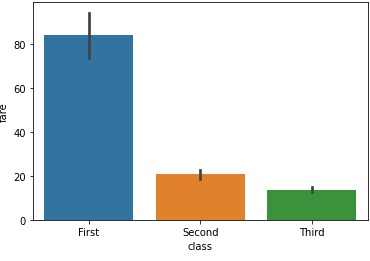
capsize 参数是 barplot() 方法中一个非常有用的参数。 它采用浮点值并确定误差线上限的宽度。 在这个例子中,我们将 capsize 参数传递给方法并观察生成的图形的变化。 下例中也传递了 hue 参数,因为图形会更清晰。
import seaborn as sns
import matplotlib.pyplot as plt
titanic=sns.load_dataset("titanic")
titanic.head()
sns.barplot(x="class", y="fare",hue="who",capsize=0.2,data=titanic)
plt.show()
输出
得到的输出如下,
示例 3
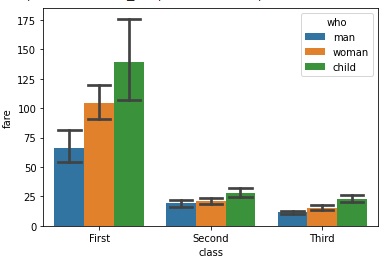
在这个例子中,我们将了解订单参数的工作原理。 此参数将值作为字符串列表。 这些字符串列表是绘制分类级别的顺序。 由于数据集中类变量的顺序是第一、第二和第三,因此下面代码行中传递的顺序与当前顺序相反。
import seaborn as sns
import matplotlib.pyplot as plt
titanic=sns.load_dataset("titanic")
titanic.head()
sns.barplot(x="class",y="fare",hue="who", data=titanic,order=["Third", "Second","First"])
plt.show()
输出
使用上面这行代码得到的输出结果如下,

示例 4
Central tendency 是一个有很多用途的参数,是一个可选参数,可以取值,float 或 none。 它是一个可选参数。 围绕估计值绘制的是不同大小的置信区间。 如果传递了"sd"值,则执行引导程序并且绘图包含观察到的标准偏差。 如果没有,则不会显示错误栏,也不会进行引导。
import seaborn as sns
import matplotlib.pyplot as plt
titanic=sns.load_dataset("titanic")
titanic.head()
sns.barplot(x="class", y="fare", ci="sd",data=titanic)
plt.show()
输出
得到的输出如下 −