网页抓取的合法性
使用 Python,我们可以抓取任何网站或网页的特定元素,但您知道这是否合法吗? 在抓取任何网站之前,我们必须了解网络抓取的合法性。 本章将解释与网络抓取合法性相关的概念。
简介
一般来说,如果您打算将抓取的数据用于个人用途,那么可能不会有任何问题。 但是,如果您打算重新发布该数据,那么在这样做之前,您应该向所有者提出下载请求,或者对政策以及您要抓取的数据进行一些背景研究。
抓取前需要进行研究
如果您的目标是要从中抓取数据的网站,我们需要了解其规模和结构。 以下是我们在开始网络抓取之前需要分析的一些文件。
Analyzing robots.txt
实际上,大多数发布者都允许程序员在某种程度上抓取他们的网站。 换句话说,发布者希望抓取网站的特定部分。 为了定义这一点,网站必须制定一些规则来说明哪些部分可以被抓取,哪些部分不能。 此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于识别允许和不允许抓取的网站部分。 robots.txt 文件没有标准格式,网站发布者可以根据需要进行修改。 我们可以通过在该网站的 url 后提供斜杠和 robots.txt 来检查特定网站的 robots.txt 文件。 比如我们要查google.com,那么我们需要输入https://www.google.com/robots.txt,我们会得到如下的东西 −
User-agent: * Disallow: /search Allow: /search/about Allow: /search/static Allow: /search/howsearchworks Disallow: /sdch Disallow: /groups Disallow: /index.html? Disallow: /? Allow: /?hl= Disallow: /?hl=*& Allow: /?hl=*&gws_rd=ssl$ and so on……..
网站的 robots.txt 文件中定义的一些最常见的规则如下 −
User-agent: BadCrawler Disallow: /
上述规则意味着 robots.txt 文件要求带有 BadCrawler 用户代理的爬虫不要爬取他们的网站。
User-agent: * Crawl-delay: 5 Disallow: /trap
上述规则意味着 robots.txt 文件会在所有用户代理的下载请求之间延迟爬虫 5 秒,以避免服务器过载。 /trap 链接将尝试阻止跟踪不允许链接的恶意爬虫。 网站发布者可以根据他们的要求定义更多规则。 其中一些在这里讨论 −
分析站点地图文件
如果您想抓取网站以获取更新信息,您应该怎么做? 您将抓取每个网页以获取更新的信息,但这会增加该特定网站的服务器流量。 这就是为什么网站提供站点地图文件来帮助爬虫找到更新内容而无需爬取每个网页的原因。 站点地图标准在 http://www.sitemaps.org/protocol.html 中定义。
站点地图文件的内容
以下是在robot.txt文件中发现的 https://www.microsoft.com/robots.txt 的sitemap文件内容 −
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml Sitemap: https://www.microsoft.com/learning/sitemap.xml Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8 Sitemap: https://www.microsoft.com/store/collections.xml Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
以上内容表明站点地图列出了网站上的 URL,并进一步允许网站管理员指定一些附加信息,如最后更新日期、内容更改、URL 相对于其他 URL 的重要性等。
什么是网站大小?
网站的大小,即网站的网页数量会影响我们抓取的方式吗? 当然可以。因为如果我们要抓取的网页数量较少,那么效率就不是一个严重的问题,但是假设如果我们的网站有数百万个网页,例如 Microsoft.com,那么按顺序下载每个网页将需要几个月的时间,那么效率将是一个严重的问题。
检查网站的大小
通过检查 Google 爬虫结果的大小,我们可以估算网站的大小。 我们的结果可以在进行 Google 搜索时使用关键字 site 进行过滤。 例如估计 https://authoraditiagarwal.com/ 的大小如下 −
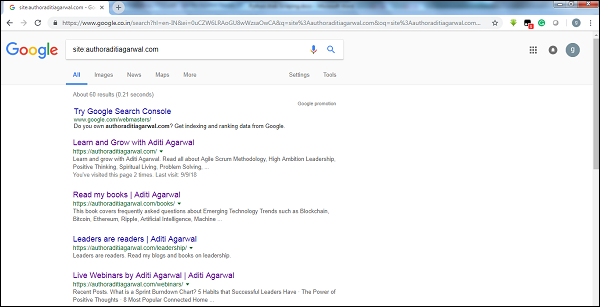
可以看到大约有60个结果,这意味着它不是一个大网站,爬取不会导致效率问题。
网站使用了哪些技术?
另一个重要的问题是网站使用的技术是否会影响我们抓取的方式? 是的,有影响。 但是我们如何检查网站使用的技术呢? 有一个名为 builtwith 的 Python 库,借助它我们可以了解网站使用的技术。
示例
在这个例子中,我们将在 Python 库 builtwith 的帮助下检查网站 https://authoraditiagarwal.com 使用的技术。 但是在使用这个库之前,我们需要按如下方式安装 −
(base) D:\ProgramData>pip install builtwith Collecting builtwith Downloading https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0 2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz Requirement already satisfied: six in d:\programdata\lib\site-packages (from builtwith) (1.10.0) Building wheels for collected packages: builtwith Running setup.py bdist_wheel for builtwith ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b f926764a924873e0304f10b2524 Successfully built builtwith Installing collected packages: builtwith Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 −
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
网站所有者是谁?
网站所有者也很重要,因为如果所有者以阻止爬虫而闻名,那么爬虫在从网站上抓取数据时必须小心。 有一个名为 Whois 的协议,借助它我们可以找到有关网站所有者的信息。
示例
在这个例子中,我们将在 Whois 的帮助下检查网站的所有者 say microsoft.com。 但是在使用这个库之前,我们需要按如下方式安装 −
(base) D:\ProgramData>pip install python-whois Collecting python-whois Downloading https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8 5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s Requirement already satisfied: future in d:\programdata\lib\site-packages (from python-whois) (0.16.0) Building wheels for collected packages: python-whois Running setup.py bdist_wheel for python-whois ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b 4dcc81ab212a3d5e52ab32dc531 Successfully built python-whois Installing collected packages: python-whois Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 −
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}


