PyBrain - 示例
本章列出了使用 PyBrain 执行的所有可能示例。
示例 1
使用 NOR 真值表并测试其正确性。
from pybrain.tools.shortcuts import buildNetwork from pybrain.structure import TanhLayer from pybrain.datasets import SupervisedDataSet from pybrain.supervised.trainers import BackpropTrainer # 创建一个具有两个输入、三个隐藏和一个输出的网络 nn = buildNetwork(2, 3, 1, bias=True, hiddenclass=TanhLayer) # 创建一个与网络输入和输出大小匹配的数据集: norgate = SupervisedDataSet(2, 1) # 创建一个用于测试的数据集。 nortrain = SupervisedDataSet(2, 1) # 将输入和目标值添加到数据集 # NOR 真值表的值 norgate.addSample((0, 0), (1,)) norgate.addSample((0, 1), (0,)) norgate.addSample((1, 0), (0,)) norgate.addSample((1, 1), (0,)) # 将输入和目标值添加到数据集 # NOR 真值表的值 nortrain.addSample((0, 0), (1,)) nortrain.addSample((0, 1), (0,)) nortrain.addSample((1, 0), (0,)) nortrain.addSample((1, 1), (0,)) # 使用数据集 norgate 训练网络。 trainer = BackpropTrainer(nn, norgate) # 将运行循环 1000 次来训练它。 for epoch in range(1000): trainer.train() trainer.testOnData(dataset=nortrain, verbose = True)
输出
C:\pybrain\pybrain\src>python testnetwork.py
Testing on data:
('out: ', '[0.887 ]')
('correct:', '[1 ]')
error: 0.00637334
('out: ', '[0.149 ]')
('correct:', '[0 ]')
error: 0.01110338
('out: ', '[0.102 ]')
('correct:', '[0 ]')
error: 0.00522736
('out: ', '[-0.163]')
('correct:', '[0 ]')
error: 0.01328650
('All errors:', [0.006373344564625953, 0.01110338071737218,
0.005227359234093431, 0.01328649974219942])
('Average error:', 0.008997646064572746)
('Max error:', 0.01328649974219942, 'Median error:', 0.01110338071737218)
示例 2
对于数据集,我们将使用来自 sklearn 数据集的数据集,如下所示:请参考 sklearn 中的 load_digits 数据集: scikit-learn.org
它有 10 个类,即要预测的数字从 0 到 9。
X 中的总输入数据为 64。
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10) )
# 我们的输入是 64 个 dim 数组,由于数字从 0 到 9,因此考虑的类别是 10。
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # 将样本添加到数据集
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
# 将数据集拆分为 25% 作为测试数据,75% 作为训练数据
# 在数据集上使用 splitWithProportion() 方法将数据集转换为
#superviseddataset,因此我们将数据集转换回分类数据集
#如上一步所示。
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(
training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer
)
#创建一个网络,其中输入和输出来自训练数据。
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01
)
#训练网络
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
#可视化错误和验证数据
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))
输出
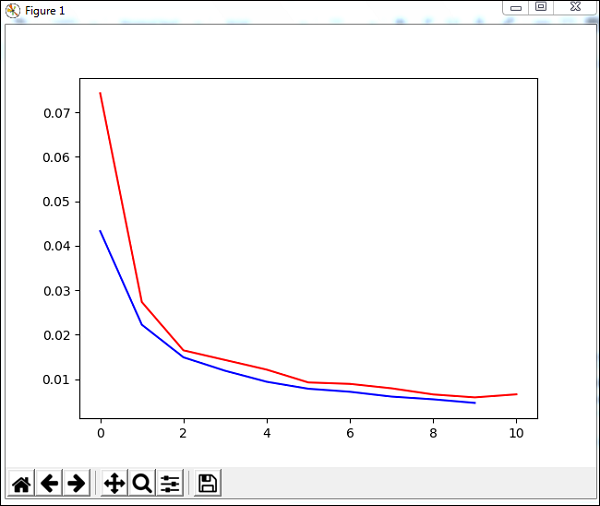
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
Percent Error on testData: 3.34075723830735


