并行计算机架构 - 模型
并行处理已成为现代计算机中的一项有效技术,可满足实际应用中对更高性能、更低成本和更准确结果的需求。由于多道程序设计、多处理或多计算的实践,当今计算机中并发事件很常见。
现代计算机拥有强大而广泛的软件包。要分析计算机性能的发展,首先我们必须了解硬件和软件的基本发展。
计算机发展里程碑 − 计算机发展有两个主要阶段 - 机械 或 机电 部件。现代计算机是在引入电子元件后发展起来的。电子计算机中的高迁移率电子取代了机械计算机中的操作部件。对于信息传输,以接近光速的电信号取代了机械齿轮或杠杆。
现代计算机的要素 − 现代计算机系统由计算机硬件、指令集、应用程序、系统软件和用户界面组成。
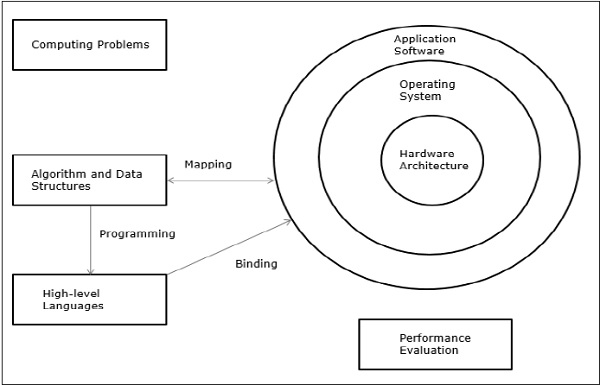
计算问题分为数值计算、逻辑推理和事务处理。一些复杂的问题可能需要三种处理模式的结合。
计算机体系结构的演变 − 在过去的四十年里,计算机体系结构经历了革命性的变化。我们从冯·诺依曼架构开始,现在我们有了多计算机和多处理器。
计算机系统的性能 − 计算机系统的性能取决于机器能力和程序行为。机器能力可以通过更好的硬件技术、先进的架构特性和高效的资源管理来提高。程序行为是不可预测的,因为它取决于应用程序和运行时条件
多处理器和多计算机
在本节中,我们将讨论两种类型的并行计算机 −
- 多处理器
- 多计算机
共享内存多计算机
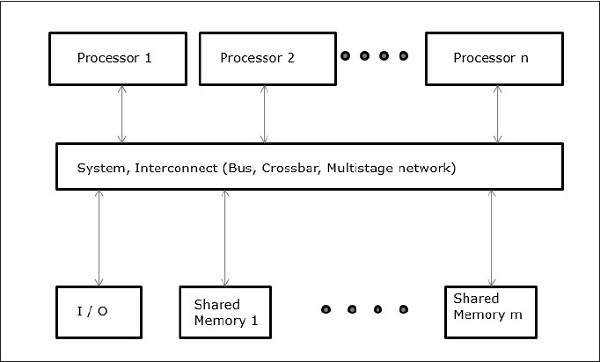
三种最常见的共享内存多处理器模型是 −
统一内存访问 (UMA)
在此模型中,所有处理器统一共享物理内存。所有处理器对所有内存字的访问时间均等。每个处理器可能都有一个私有缓存。外围设备也遵循相同的规则。
当所有处理器对所有外围设备都有同等的访问权限时,系统称为对称多处理器。当只有一个或几个处理器可以访问外围设备时,系统被称为非对称多处理器。
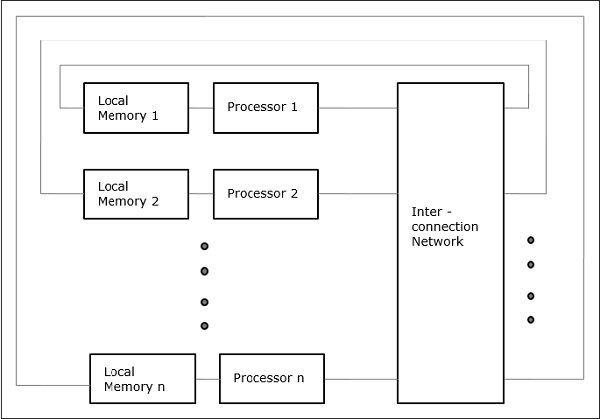
非统一内存访问 (NUMA)
在 NUMA 多处理器模型中,访问时间随内存字的位置而变化。在这里,共享内存物理分布在所有处理器之间,称为本地内存。所有本地内存的集合形成一个全局地址空间,所有处理器都可以访问该空间。
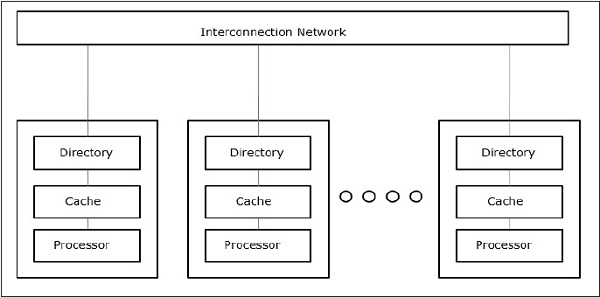
仅缓存内存架构 (COMA)
COMA 模型是 NUMA 模型的一个特例。在这里,所有分布式主存储器都转换为高速缓存存储器。
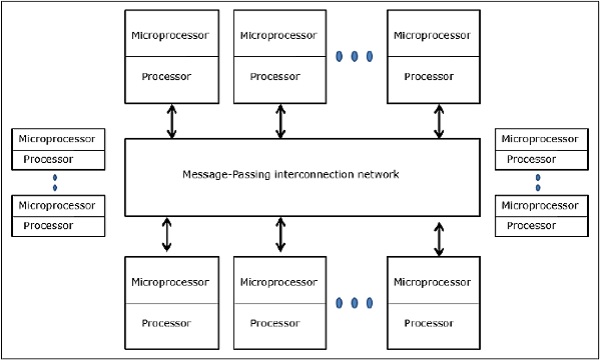
分布式内存多计算机 − 分布式内存多计算机系统由多台计算机(称为节点)组成,这些计算机通过消息传递网络相互连接。每个节点都充当一台自主计算机,具有处理器、本地内存,有时还具有 I/O 设备。在这种情况下,所有本地内存都是私有的,只有本地处理器可以访问。这就是为什么传统机器被称为无远程内存访问 (NORMA) 机器。
多向量和 SIMD 计算机
在本节中,我们将讨论用于向量处理和数据并行性的超级计算机和并行处理器。
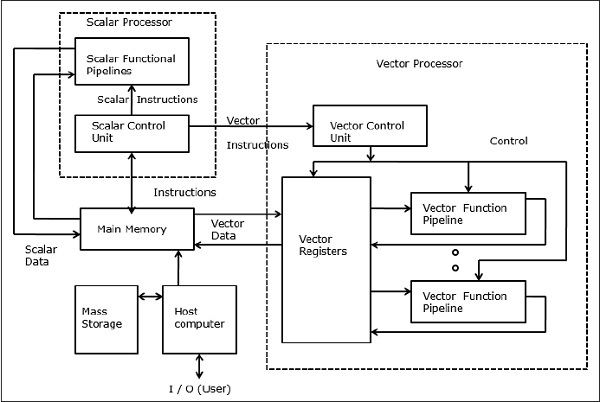
向量超级计算机
在向量计算机中,向量处理器作为可选功能连接到标量处理器。主机首先将程序和数据加载到主内存。然后标量控制单元解码所有指令。如果解码后的指令是标量操作或程序操作,标量处理器将使用标量功能管道执行这些操作。
另一方面,如果解码后的指令是矢量操作,则指令将被发送到矢量控制单元。
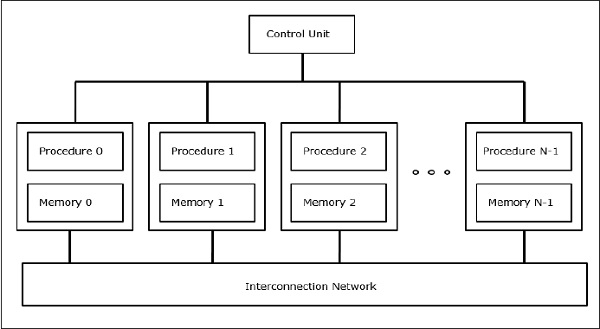
SIMD 超级计算机
在 SIMD 计算机中,'N' 个处理器连接到控制单元,所有处理器都有各自的内存单元。所有处理器都通过互连网络连接。
PRAM 和 VLSI 模型
理想模型为开发并行算法提供了一个合适的框架,无需考虑物理约束或实现细节。
可以实施这些模型以获得并行计算机上的理论性能界限,或在制造芯片之前评估 VLSI 在芯片面积和操作时间上的复杂性。
并行随机存取机
Sheperdson 和 Sturgis (1963) 将传统的单处理器计算机建模为随机存取机 (RAM)。Fortune 和 Wyllie (1978) 开发了一个并行随机存取机 (PRAM) 模型,用于建模具有零内存访问开销和同步的理想并行计算机。
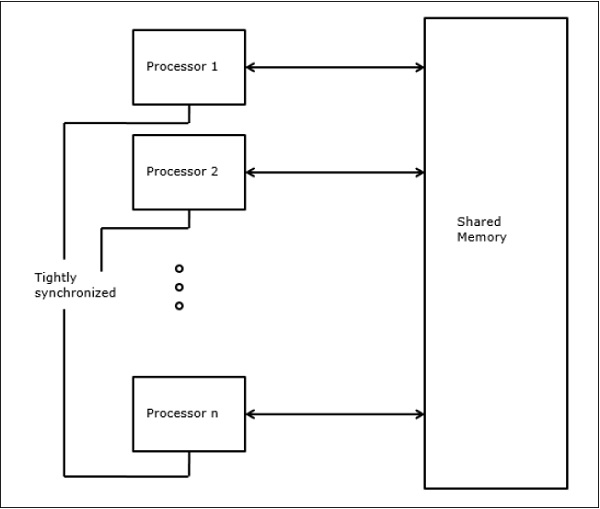
N 处理器 PRAM 具有共享内存单元。此共享内存可以集中或分布在处理器之间。这些处理器以同步的读取内存、写入内存和计算周期运行。因此,这些模型指定了如何处理并发读取和写入操作。
以下是可能的内存更新操作 −
独占读取 (ER) − 在此方法中,每个周期只允许一个处理器从任何内存位置读取。
独占写入 (EW) − 在此方法中,每次至少允许一个处理器写入内存位置。
并发读取 (CR) − 它允许多个处理器在同一周期从同一内存位置读取相同信息。
并发写入 (CW) − 它允许同时对同一内存位置执行写入操作。为了避免写入冲突,设置了一些策略。
VLSI 复杂度模型
并行计算机使用 VLSI 芯片来制造处理器阵列、内存阵列和大规模交换网络。
如今,VLSI 技术是二维的。VLSI 芯片的大小与该芯片中可用的存储(内存)空间量成正比。
我们可以通过实现该算法的 VLSI 芯片的芯片面积 (A) 来计算算法的空间复杂度。如果 T 是执行算法所需的时间(延迟),则 A.T 给出了通过芯片(或 I/O)处理的总位数的上限。对于某些计算,存在一个下限 f(s),使得
A.T2 >= O (f(s))
其中 A=芯片面积,T=时间
架构开发轨迹
我们沿着以下轨迹传播并行计算机的演进 −
- 多处理器轨迹
- 多处理器轨迹
- 多计算机轨迹
- 多数据轨迹
- 矢量轨迹
- SIMD 轨迹
- 多线程轨迹
- 多线程轨迹
- 数据流轨迹
在多处理器轨迹中,假设不同的线程在不同的处理器上并发执行,并通过共享内存(多处理器轨迹)或消息传递(多计算机轨迹)系统进行通信。
在多数据轨道中,假设对大量数据执行相同的代码。这是通过在数据元素序列(矢量轨道)上执行相同的指令或通过在相似的数据集(SIMD 轨道)上执行相同的指令序列来实现的。
在多线程轨道中,假设在同一处理器上交错执行各种线程,以隐藏在不同处理器上执行的线程之间的同步延迟。线程交错可以是粗略的(多线程轨道)或精细的(数据流轨道)。


