并行随机存取机
一种对随机存取机模型作直接扩展而形成的并行计算模型。它假设有一个无限大容量的共享存储器,并且有多个功能相同的处理器。在任意时刻,任意处理器都可在一个周期内访问任意的共享存储单元。
并行随机存取机(PRAM)是大多数并行算法都考虑的模型。 在这里,多个处理器连接到单个内存块。 PRAM 模型包含 −
一组类似类型的处理器。
所有处理器共享一个公共内存单元。 处理器之间只能通过共享内存进行通信。
内存访问单元 (MAU) 将处理器与单个共享内存连接起来。
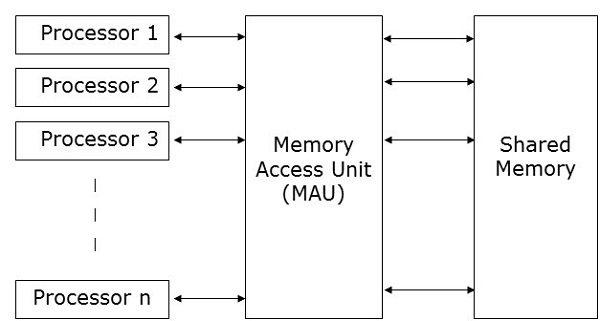
这里,n 个处理器可以在特定时间单位内对 n 个数据执行独立操作。 这可能会导致不同处理器同时访问同一内存位置。
为了解决这个问题,对 PRAM 模型施加了以下约束 −
独占读独占写(EREW) − 这里不允许两个处理器同时读取或写入同一内存位置。
独占读取并发写入 (ERCW) − 这里不允许两个处理器同时从同一内存位置读取数据,但允许同时向同一内存位置写入数据。
并发读独占写 (CREW) − 这里允许所有处理器同时从同一内存位置读取,但不允许同时写入同一内存位置。
并发读取并发写入 (CRCW) − 所有处理器都可以同时读取或写入同一内存位置。
实现 PRAM 模型的方法有很多,但最突出的是 −
- 共享内存模型
- 消息传递模型
- 数据并行模型
共享内存模型
共享内存强调控制并行性而不是数据并行性。 在共享内存模型中,多个进程独立地在不同的处理器上执行,但它们共享公共的内存空间。 由于任何处理器活动,如果任何内存位置发生任何更改,其余处理器都可以看到。
当多个处理器访问同一内存位置时,可能会发生在任何特定时间点,多个处理器正在访问同一内存位置的情况。 假设一个人正在读取该位置,另一个人正在该位置上写入。 它可能会造成混乱。 为了避免这种情况,实现了一些控制机制,例如锁/信号量来确保互斥。
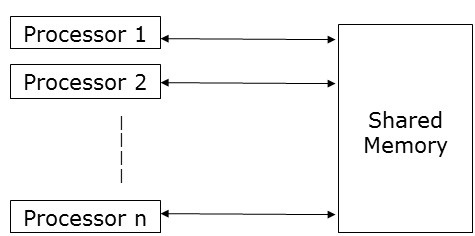
共享内存编程已实现如下 −
线程库 − 线程库允许多个控制线程在同一内存位置同时运行。 线程库提供了一个通过子程序库支持多线程的接口。 它包含子例程
- 创建和销毁线程
- 调度线程的执行
- 在线程之间传递数据和消息
- 保存和恢复线程上下文
线程库的示例包括 − 用于 Solaris 的 SolarisTM 线程、Linux 中实现的 POSIX 线程、Windows NT 和 Windows 2000 中可用的 Win32 线程以及作为标准 JavaTM 开发工具包 (JDK) 一部分的 JavaTM 线程。
分布式共享内存(DSM)系统 − DSM系统在松耦合架构上创建共享内存的抽象,以便在没有硬件支持的情况下实现共享内存编程。 它们实现标准库并使用现代操作系统中存在的高级用户级内存管理功能。 示例包括 Tread Marks System、Munin、IVY、Shasta、Brazos 和 Cashmere。
程序注释包 − 这是在具有统一存储器访问特性的架构上实现的。 程序注释包最著名的例子是 OpenMP。 OpenMP 实现功能并行。 主要关注循环的并行化。
共享内存的概念提供了对共享内存系统的低级控制,但它往往是乏味且错误的。 它比应用程序编程更适用于系统编程。
共享内存编程的优点
全局地址空间提供了一种用户友好的内存编程方法。
由于内存距离CPU较近,进程之间的数据共享快速且统一。
无需明确指定进程之间的数据通信。
进程通信开销可以忽略不计。
非常容易学习。
共享内存编程的缺点
- 它不可移植。
- 管理数据局部性非常困难。
消息传递模型
消息传递是分布式内存系统中最常用的并行编程方法。 在这里,程序员必须确定并行度。 在该模型中,所有处理器都有自己的本地存储单元,并通过通信网络交换数据。
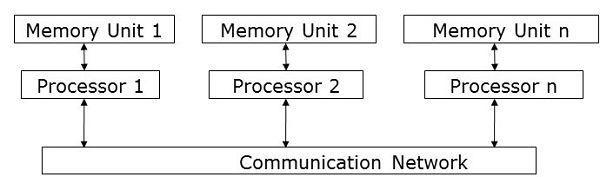
处理器使用消息传递库在它们之间进行通信。 除了发送的数据外,消息还包含以下组件 −
发送消息的处理器的地址;
发送处理器中数据存储位置的起始地址;
发送数据的数据类型;
发送数据的数据大小;
消息发送到的处理器的地址;
接收处理器中数据的内存位置的起始地址。
处理器之间可以通过以下任意一种方法进行通信 −
- 点对点通信
- 集体沟通
- 消息传递接口
点对点通信
点对点通信是最简单的消息传递形式。 这里,消息可以通过以下任意一种传输模式从发送处理器发送到接收处理器 −
同步模式 − 只有在收到前一条消息已送达的确认后才会发送下一条消息,以保持消息的顺序。
异步模式 − 要发送下一条消息,不需要收到上一条消息的送达确认。
集体交流
集体通信涉及两个以上的处理器来传递消息。 以下模式允许集体通信 −
障碍 − 如果通信中包含的所有处理器都运行特定的块(称为屏障块)来传递消息,则屏障模式是可能的。
广播 − 广播有两种类型−
一对多 − 在这里,一个处理器执行单个操作向所有其他处理器发送相同的消息。
全部到全部 − 在这里,所有处理器向所有其他处理器发送消息。
广播的消息可以分为三种类型 −
个性化 − 唯一的消息将发送到所有其他目标处理器。
非个性化 − 所有目标处理器都会收到相同的消息。
减少 − 在缩减广播中,组中的一个处理器收集来自组中所有其他处理器的所有消息,并将它们组合成一条消息,组中的所有其他处理器都可以访问。
消息传递的优点
- 提供低级并行控制;
- 它是便携式的;
- 不易出错;
- 并行同步和数据分发的开销更少。
消息传递的缺点
与并行共享内存代码相比,消息传递代码通常需要更多的软件开销。
消息传递库
有许多消息传递库。 在这里,我们将讨论两个最常用的消息传递库 −
- 消息传递接口 (MPI)
- 并行虚拟机 (PVM)
消息传递接口(MPI)
它是一个通用标准,用于在分布式内存系统中的所有并发进程之间提供通信。 大多数常用的并行计算平台都提供至少一种消息传递接口的实现。 它已被实现为称为 library 的预定义函数的集合,并且可以从 C、C++、Fortran 等语言进行调用。与其他消息传递库相比,MPI 既快速又可移植。
消息传递接口的优点
仅在共享内存架构或分布式内存架构上运行;
每个处理器都有自己的局部变量;
与大型共享内存计算机相比,分布式内存计算机更便宜。
消息传递接口的缺点
- 并行算法需要更多编程更改;
- 有时很难调试; 和
- 在节点之间的通信网络中表现不佳。
并行虚拟机 (PVM)
PVM 是一种便携式消息传递系统,旨在连接单独的异构主机以形成单个虚拟机。 它是单个可管理的并行计算资源。 通过使用内存和许多计算机的聚合能力,可以更经济有效地解决超导研究、分子动力学模拟和矩阵算法等大型计算问题。 它管理不兼容计算机体系结构网络中的所有消息路由、数据转换、任务调度。
PVM的特点
- 非常容易安装和配置;
- 多个用户可以同时使用 PVM;
- 一个用户可以执行多个应用程序;
- 这是一个小包装;
- 支持 C、C++、Fortran;
- 对于 PVM 程序的给定运行,用户可以选择计算机组;
- 这是一个消息传递模型,
- 基于流程的计算;
- 支持异构架构。
数据并行编程
数据并行编程模型的主要焦点是同时对数据集执行操作。 数据集被组织成某种结构,如数组、超立方体等。处理器集体对同一数据结构执行操作。 每个任务都在相同数据结构的不同分区上执行。
它具有限制性,因为并非所有算法都可以根据数据并行性来指定。 这就是数据并行性不通用的原因。
数据并行语言有助于指定数据分解和到处理器的映射。 它还包括数据分布语句,允许程序员控制数据(例如,哪些数据将传输到哪个处理器),以减少处理器内的通信量。


