OrientDB - 快速指南
OrientDB - 概述
OrientDB 是一个开源 NoSQL 数据库管理系统。NoSQL 数据库提供了一种存储和检索无关系或非关系数据的机制,这些数据指的是除表格数据之外的数据,例如文档数据或图形数据。NoSQL 数据库越来越多地用于大数据和实时 Web 应用程序。NoSQL 系统有时也被称为"不仅仅是 SQL",以强调它们可能支持类似 SQL 的查询语言。
OrientDB 也属于 NoSQL 家族。OrientDB 是第二代分布式图形数据库,在一个产品中具有文档的灵活性,并采用 Apache 2 许可证的开源。在 OrientDB 之前,市场上有几种 NoSQL 数据库,其中之一就是 MongoDB。
MongoDB 与 OrientDB
MongoDB 和 OrientDB 包含许多共同的功能,但引擎根本不同。 MongoDB 是纯文档数据库,而 OrientDB 是带图形引擎的混合文档数据库。
| 功能 | MongoDB | OrientDB |
|---|---|---|
| 关系 | 使用 RDBMS JOINS 创建实体之间的关系。运行时成本高,并且当数据库规模增加时无法扩展。 | 像关系数据库一样嵌入和连接文档。它使用来自图形数据库世界的直接、超快速链接。 |
| 获取计划 | 昂贵的 JOIN 操作。 | 轻松返回包含互连文档的完整图形。 |
| 事务 | 不支持 ACID 事务,但支持原子操作。 | 支持 ACID 事务以及原子操作。 |
| 查询语言 | 拥有基于 JSON 的自己的语言。 | 查询语言基于 SQL 构建。 |
| 索引 | 所有索引均使用 B-Tree 算法。 | 支持三种不同的索引算法,以便用户获得最佳性能。 |
| 存储引擎 | 使用内存映射技术。 | 使用存储引擎名称 LOCAL 和 PLOCAL。 |
OrientDB 是第一个多模型开源 NoSQL DBMS,它将图形的强大功能和文档的灵活性整合到一个可扩展的高性能操作数据库中。
OrientDB - 安装
OrientDB 安装文件有两个版本 −
社区版 − OrientDB 社区版由 Apache 在 0.2 许可证下作为开源软件发布
企业版 − OrientDB 企业版作为专有软件发布,它基于社区版构建。它是社区版的扩展。
本章介绍 OrientDB 社区版的安装过程,因为它是开源的。
先决条件
社区版和企业版都可以在任何实现 Java 虚拟机 (JVM) 的操作系统上运行。 OrientDB 需要 Java 1.7 或更高版本。
使用以下步骤下载并安装 OrientDB 到您的系统中。
步骤 1 − 下载 OrientDB 二进制安装文件
OrientDB 附带内置安装文件,用于在您的系统上安装数据库。它为不同的操作系统提供不同的预编译二进制包(tarred 或 zipped 包)。您可以从 下载 OrientDB 链接下载 OrientDB 文件。
以下屏幕截图显示了 OrientDB 的下载页面。您可以通过单击适当的操作系统图标来下载压缩或 tar 文件。
下载后,您将在 Downloads 文件夹中获得二进制包。
第 2 步 − 提取并安装 OrientDB
以下是提取和安装不同操作系统的 OrientDB 的过程。
在 Linux 中
下载后,您将在 Downloads 文件夹中获得 orientdb-community-2.1.9.tar.gz 文件。您可以使用以下命令提取 tarred 文件。
$ tar –zxvf orientdb-community-2.1.9.tar.gz
您可以使用以下命令将所有 OrientDB 库文件从 orientdbcommunity-2.1.9 移动到 /opt/orientdb/ 目录。这里我们使用超级用户命令 (sudo),因此您必须提供超级用户密码才能执行以下命令。
$ sudo mv orientdb-community-2.1.9 /opt/orientdb
您可以使用以下命令注册 orientdb 命令和 Orient 服务器。
$ export ORIENTDB_HoME = /opt/orientdb $ export PATH = $PATH:$ORIENTDB_HOME/bin
在 Windows 中
下载后,您将在 Downloads 文件夹中获得 orientdb-community-2.1.9.zip 文件。使用 zip 提取器提取 zip 文件。
将提取的文件夹移动到 C:\ 目录中。
使用以下给定值创建两个环境变量 ORIENTDB_HOME 和 PATH 变量。
ORIENT_HOME = C:\orientdb-community-2.1.9 PATH = C:\orientdb-community-2.1.9\bin
步骤 3 −将 OrientDB 服务器配置为服务
按照上述步骤,您可以使用 OrientDB 的桌面版本。您可以使用以下步骤将 OrientDB 数据库服务器作为服务启动。具体过程因操作系统而异。
在 Linux 中
OrientDB 提供了一个名为 orientdb.sh 的脚本文件,用于将数据库作为守护进程运行。您可以在 OrientDB 安装目录的 bin/ 目录中找到它,即 $ORIENTDB_HOME/bin/orientdb.sh。
在运行脚本文件之前,您必须编辑 orientdb.sh 文件以定义两个变量。一个是 ORIENTDB_DIR,它定义安装目录 (/opt/orientdb) 的路径,第二个是 ORIENTDB_USER,它定义要为其运行 OrientDB 的用户名,如下所示。
ORIENTDB_DIR = "/opt/orientdb" ORIENTDB_USER = "<username you want to run OrientDB>"
使用以下命令将 orientdb.sh 文件复制到 /etc/init.d/ 目录中,以初始化并运行脚本。这里我们使用超级用户命令(sudo),因此您必须提供超级用户密码才能执行以下命令。
$ sudo cp $ORIENTDB_HOME/bin/orientdb.sh /etc/init.d/orientdb
使用以下命令将 console.sh 文件从 OrientDB 安装目录 $ORIENTDB_HOME/bin 复制到系统 bin 目录 /usr/bin,以访问 Orient DB 的控制台。
$ sudo cp $ ORIENTDB_HOME/bin/console.sh /usr/bin/orientdb
使用以下命令将 ORIENTDB 数据库服务器启动为服务。在这里,您必须提供在 orientdb.sh 文件中提到的相应用户的密码才能启动服务器。
$ service orientdb start
使用以下命令了解 OrientDB 服务器守护程序在哪个 PID 上运行。
$ service orientdb status
使用以下命令停止 OrientDB 服务器守护程序。在这里,您必须提供相应用户的密码,您在 orientdb.sh 文件中提到该密码以停止服务器。
$ service orientdb stop
在 Windows 中
OrientDB 是一个服务器应用程序,因此它必须在开始关闭 Java 虚拟机进程之前执行多项任务。如果您想手动关闭 OrientDB 服务器,则必须执行 shutdown.bat 文件。但是,当系统突然关闭而不执行上述脚本时,服务器实例无法正确停止。由操作系统使用一组指定信号控制的程序在 Windows 中称为 services。
我们必须使用 Apache Common Daemon,它允许 Windows 用户将 Java 应用程序包装为 Windows 服务。以下是下载和注册 Apache 通用守护程序的步骤。
单击以下链接获取 适用于 Windows 的 Apache 通用守护程序。
单击 common-daemon-1.0.15-bin-windows 进行下载。
解压 common-daemon-1.0.15-bin-windows 目录。解压后,您将在目录中找到 prunsrv.exe 和 prunmgr.exe 文件。在这些 −
prunsrv.exe 文件是一个用于将应用程序作为服务运行的服务应用程序。
prunmgr.exe 文件是一个用于监视和配置 Windows 服务的应用程序。
转到 OrientDB 安装文件夹 →创建一个新目录并将其命名为 service。
将 prunsrv.exe 和 prunmgr .exe 复制并粘贴到服务目录中。
为了将 OrientDB 配置为 Windows 服务,您必须执行一个使用 prusrv.exe 作为 Windows 服务的简短脚本。
在定义 Windows 服务之前,您必须根据服务的名称重命名 prunsrv 和 prunmgr。例如,分别为 OrientDBGraph 和 OrientDBGraphw。这里 OrientDBGraph 是服务的名称。
将以下脚本复制到名为 installService.bat 的文件中,并将其放入 %ORIENTDB_HOME%\service\ 目录中。
:: OrientDB Windows Service Installation @echo off rem Remove surrounding quotes from the first parameter set str=%~1 rem Check JVM DLL location parameter if "%str%" == "" goto missingJVM set JVM_DLL=%str% rem Remove surrounding quotes from the second parameter set str=%~2 rem Check OrientDB Home location parameter if "%str%" == "" goto missingOrientDBHome set ORIENTDB_HOME=%str% set CONFIG_FILE=%ORIENTDB_HOME%/config/orientdb-server-config.xml set LOG_FILE = %ORIENTDB_HOME%/config/orientdb-server-log.properties set LOG_CONSOLE_LEVEL = info set LOG_FILE_LEVEL = fine set WWW_PATH = %ORIENTDB_HOME%/www set ORIENTDB_ENCODING = UTF8 set ORIENTDB_SETTINGS = -Dprofiler.enabled = true -Dcache.level1.enabled = false Dcache.level2.strategy = 1 set JAVA_OPTS_SCRIPT = -XX:+HeapDumpOnOutOfMemoryError rem Install service OrientDBGraphX.X.X.exe //IS --DisplayName="OrientDB GraphEd X.X.X" ^ --Description = "OrientDB Graph Edition, aka GraphEd, contains OrientDB server integrated with the latest release of the TinkerPop Open Source technology stack supporting property graph data model." ^ --StartClass = com.orientechnologies.orient.server.OServerMain -StopClass = com.orientechnologies.orient.server.OServerShutdownMain ^ --Classpath = "%ORIENTDB_HOME%\lib\*" --JvmOptions "Dfile.Encoding = %ORIENTDB_ENCODING%; Djava.util.logging.config.file = "%LOG_FILE%"; Dorientdb.config.file = "%CONFIG_FILE%"; -Dorientdb.www.path = "%WWW_PATH%"; Dlog.console.level = %LOG_CONSOLE_LEVEL%; -Dlog.file.level = %LOG_FILE_LEVEL%; Dorientdb.build.number = "@BUILD@"; -DORIENTDB_HOME = %ORIENTDB_HOME%" ^ --StartMode = jvm --StartPath = "%ORIENTDB_HOME%\bin" --StopMode = jvm -StopPath = "%ORIENTDB_HOME%\bin" --Jvm = "%JVM_DLL%" -LogPath = "%ORIENTDB_HOME%\log" --Startup = auto EXIT /B :missingJVM echo Insert the JVM DLL location goto printUsage :missingOrientDBHome echo Insert the OrientDB Home goto printUsage :printUsage echo usage: echo installService JVM_DLL_location OrientDB_Home EXIT /B
该脚本需要两个参数 −
jvm.dll 的位置,例如 C:\ProgramFiles\java\jdk1.8.0_66\jre\bin\server\jvm.dll
OrientDB 安装的位置,例如 C:\orientdb-community-2.1.9
执行 OrientDBGraph.exe 文件(原始 prunsrv)并双击时,将安装该服务。
使用以下命令将服务安装到 Windows 中。
> Cd %ORIENTDB_HOME%\service > installService.bat "C:\Program Files\Java\jdk1.8.0_66\jre\bin\server \jvm.dll" C:\orientdb-community-2.1.9
打开任务管理器服务,您将看到以下屏幕截图,其中包含已注册的服务名称。
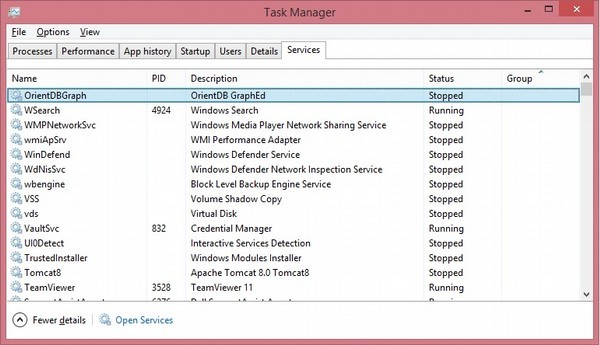
步骤 4 − 验证 OrientDB 安装
此步骤使用以下步骤验证 OrientDB 数据库服务器安装。
- 运行服务器。
- 运行控制台。
- 运行工作室。
根据操作系统的不同,这是唯一的。
在 Linux 中
按照给定的步骤验证 Linux 中的 OrientDB 安装。
运行服务器 −您可以使用以下命令启动服务器。
$ cd $ORIENTDB_HOME/bin $ ./server.sh
或者您可以使用以下命令将 OrientDB 服务器作为 UNIX 守护进程启动。
$ service orientdb start
如果安装成功,您将收到以下输出。
.
.` `
, `:.
`,` ,:`
.,. :,,
.,, ,,,
. .,.::::: ```` ::::::::: :::::::::
,` .::,,,,::.,,,,,,`;; .: :::::::::: ::: :::
`,. ::,,,,,,,:.,,.` ` .: ::: ::: ::: :::
,,:,:,,,,,,,,::. ` ` `` .: ::: ::: ::: :::
,,:.,,,,,,,,,: `::, ,, ::,::` : :,::` :::: ::: ::: ::: :::
,:,,,,,,,,,,::,: ,, :. : :: : .: ::: ::: :::::::
:,,,,,,,,,,:,:: ,, : : : : .: ::: ::: :::::::::
` :,,,,,,,,,,:,::, ,, .:::::::: : : .: ::: ::: ::: :::
`,...,,:,,,,,,,,,: .:,. ,, ,, : : .: ::: ::: ::: :::
.,,,,::,,,,,,,: `: , ,, : ` : : .: ::: ::: ::: :::
...,::,,,,::.. `: .,, :, : : : .: ::::::::::: ::: :::
,::::,,,. `: ,, ::::: : : .: ::::::::: ::::::::::
,,:` `,,.
,,, .,`
,,. `, GRAPH DATABASE
`` `.
`` orientdb.com
`
2016-01-20 19:17:21:547 INFO OrientDB auto-config DISKCACHE = 1,
649MB (heap = 494MB os = 4, 192MB disk = 199, 595MB) [orientechnologies]
2016-01-20 19:17:21:816 INFO Loading configuration from:
/opt/orientdb/config/orientdb-server-config.xml... [OServerConfigurationLoaderXml]
2016-01-20 19:17:22:213 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is starting up... [OServer]
2016-01-20 19:17:22:220 INFO Databases directory: /opt/orientdb/databases [OServer]
2016-01-20 19:17:22:361 INFO Port 0.0.0.0:2424 busy,
trying the next available... [OServerNetworkListener]
2016-01-20 19:17:22:362 INFO Listening binary connections on 0.0.0.0:2425
(protocol v.32, socket = default) [OServerNetworkListener]
...
2016-01-20 19:17:22:614 INFO Installing Script interpreter. WARN:
authenticated clients can execute any kind of code into the server
by using the following allowed languages:
[sql] [OServerSideScriptInterpreter]
2016-01-20 19:17:22:615 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is active. [OServer]
运行控制台 − 您可以使用以下命令在控制台下运行 OrientDB。
$ orientdb
如果安装成功,您将收到以下输出。
OrientDB console v.2.1.9-SNAPSHOT (build 2.1.x@r; 2016-01-07 10:51:24+0000) www.orientdb.com Type 'help' to display all the supported commands. Installing extensions for GREMLIN language v.2.6.0 orientdb>
运行 Studio − 启动服务器后,您可以在浏览器上使用以下 URL (http://localhost:2480/)。您将获得以下屏幕截图。
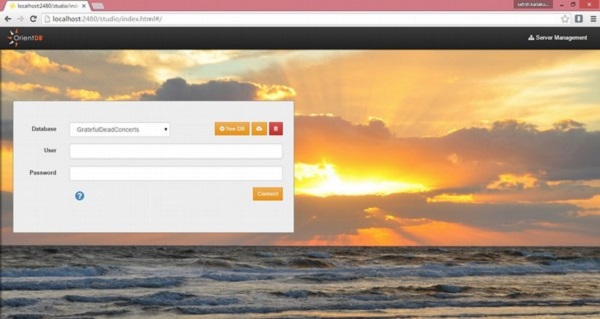
在 Windows 中
按照给定的步骤验证 Windows 中的 OrientDB 安装。
运行服务器 − 您可以使用以下命令启动服务器。
> cd %ORIENTDB_HOME%\bin > ./server.bat
如果安装成功,您将收到以下输出。
.
.` `
, `:.
`,` ,:`
.,. :,,
.,, ,,,
. .,.::::: ```` ::::::::: :::::::::
,` .::,,,,::.,,,,,,`;; .: :::::::::: ::: :::
`,. ::,,,,,,,:.,,.` ` .: ::: ::: ::: :::
,,:,:,,,,,,,,::. ` ` `` .: ::: ::: ::: :::
,,:.,,,,,,,,,: `::, ,, ::,::` : :,::` :::: ::: ::: ::: :::
,:,,,,,,,,,,::,: ,, :. : :: : .: ::: ::: :::::::
:,,,,,,,,,,:,:: ,, : : : : .: ::: ::: :::::::::
` :,,,,,,,,,,:,::, ,, .:::::::: : : .: ::: ::: ::: :::
`,...,,:,,,,,,,,,: .:,. ,, ,, : : .: ::: ::: ::: :::
.,,,,::,,,,,,,: `: , ,, : ` : : .: ::: ::: ::: :::
...,::,,,,::.. `: .,, :, : : : .: ::::::::::: ::: :::
,::::,,,. `: ,, ::::: : : .: ::::::::: ::::::::::
,,:` `,,.
,,, .,`
,,. `, GRAPH DATABASE
`` `.
`` orientdb.com
`
2016-01-20 19:17:21:547 INFO OrientDB auto-config DISKCACHE = 1,649MB
(heap = 494MB os = 4, 192MB disk = 199, 595MB) [orientechnologies]
2016-01-20 19:17:21:816 INFO Loading configuration from:
/opt/orientdb/config/orientdb-server-config.xml...
[OServerConfigurationLoaderXml]
...
2016-01-20 19:17:22:615 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is active. [OServer]
运行控制台 − 您可以使用以下命令在控制台下运行 OrientDB。
> %ORIENTDB_HOME%\bin\console.bat
如果安装成功,您将收到以下输出。
OrientDB console v.2.1.9-SNAPSHOT (build 2.1.x@r; 2016-01-07 10:51:24+0000) www.orientdb.com Type 'help' to display all the supported commands. Installing extensions for GREMLIN language v.2.6.0 orientdb\>
运行 Studio − 启动服务器后,您可以在浏览器中使用以下 URL (http://localhost:2480/)。您将获得以下屏幕截图。
OrientDB - 基本概念
OrientDB 的主要功能是支持多模型对象,即它支持不同的模型,如文档、图形、键/值和真实对象。它包含一个单独的 API 来支持所有这四种模型。
文档模型
术语文档模型属于 NoSQL 数据库。这意味着数据存储在文档中,文档组称为集合。从技术上讲,文档是指一组键/值对,也称为字段或属性。
OrientDB 使用类、集群和链接等概念来存储、分组和分析文档。
下表说明了关系模型、文档模型和 OrientDB 文档模型之间的比较 −
| 关系模型 | 文档模型 | OrientDB 文档模型 |
|---|---|---|
| 表 | 集合 | 类或集群 |
| 行 | 文档 | 文档 |
| 列 | 键/值对 | 文档字段 |
| 关系 | 不可用 | 链接 |
图形模型
图形数据结构是一种数据模型,可以以由边(弧)互连的顶点(节点)的形式存储数据。OrientDB 图形数据库的理念源自属性图。顶点和边是图形模型的主要构件。它们包含属性,可以使它们看起来与文档相似。
下表显示了图形模型、关系数据模型和 OrientDB 图形模型之间的比较。
| 关系模型 | 图形模型 | OrientDB 图形模型 |
|---|---|---|
| 表 | 顶点和边类 | 扩展"V"(表示顶点)和"E"(表示边)的类 |
| 行 | 顶点 | 顶点 |
| 列 | 顶点和边属性 | 顶点和边属性 |
| 关系 | 边 | 边 |
键/值模型
键/值模型意味着数据可以以键/值对的形式存储,其中值可以是简单类型或复杂类型。它可以支持文档和图形元素作为值。
下表说明了关系模型、键/值模型和 OrientDB 键/值模型之间的比较。
| 关系模型 | 键/值模型 | OrientDB 键/值模型 |
|---|---|---|
| 表 | 桶 | 类或集群 |
| 行 | 键/值对 | 文档 |
| 列 | 不可用 | 文档字段或顶点/边属性 |
| 关系 | 不可用 | 链接 |
对象模型
该模型已被面向对象编程继承,并支持类型之间的继承(子类型扩展了超类型)、引用基类时的多态性以及编程语言中使用的对象的直接绑定。
下表说明了关系模型、对象模型和 OrientDB 对象模型之间的比较。
| 关系模型 | 对象模型 | OrientDB 对象模型 |
|---|---|---|
| 表 | 类 | 类或集群 |
| 行 | 对象 | 文档或顶点 |
| 列 | 对象属性 | 文档字段或顶点/边属性 |
| 关系 | 指针 | 链接 |
在详细了解之前,最好先了解与 OrientDB 相关的基本术语。以下是一些重要术语。
记录
您可以加载并存储在数据库中的最小单位。记录可以存储在四种类型中。
- 文档
- 记录字节
- 顶点
- 边
记录 ID
当 OrientDB 生成记录时,数据库服务器会自动为该记录分配一个单元标识符,称为 RecordID (RID)。RID 看起来像 #<cluster>:<position>。<cluster> 表示簇标识号,<position>表示记录在集群中的绝对位置。
文档
文档是 OrientDB 中最灵活的记录类型。文档是软类型的,由具有定义约束的模式类定义,但您也可以插入没有任何模式的文档,即它也支持无模式模式。
可以通过 JSON 格式的导出和导入轻松处理文档。例如,查看以下 JSON 示例文档。它定义了文档详细信息。
{
"id" : "1201",
"name" : "Jay",
"job" : "Developer",
"creations" : [
{
"name" : "Amiga",
"company" : "Commodore Inc."
},
{
"name" : "Amiga 500",
"company" : "Commodore Inc."
}
]
}
记录字节
记录类型与 RDBMS 中的 BLOB 类型相同。OrientDB 可以加载和存储文档记录类型以及二进制数据。
顶点
OrientDB 数据库不仅是文档数据库,也是图形数据库。使用顶点和边等新概念以图形形式存储数据。在图形数据库中,最基本的数据单元是节点,在 OrientDB 中称为顶点。顶点存储数据库的信息。
边
有一种单独的记录类型称为边,它将一个顶点连接到另一个顶点。边是双向的,只能连接两个顶点。OrientDB 中有两种类型的边,一种是常规的,另一种是轻量级的。
类
类是一种数据模型,也是从面向对象编程范式中得出的概念。基于传统的文档数据库模型,数据以集合的形式存储,而在关系数据库模型中,数据存储在表中。OrientDB 遵循文档 API 和 OPPS 范式。作为一个概念,OrientDB 中的类与关系数据库中的表具有最密切的关系,但(与表不同)类可以是无模式、全模式或混合模式。类可以从其他类继承,从而创建类树。每个类都有自己的一个或多个集群(如果未定义,则默认创建)。
集群
集群是一个重要的概念,用于存储记录、文档或顶点。简而言之,集群是存储一组记录的地方。默认情况下,OrientDB 将为每个类创建一个集群。类的所有记录都存储在与类同名的同一集群中。您可以在数据库中创建最多 32,767 (2^15-1) 个集群。
CREATE 类是用于创建具有特定名称的集群的命令。创建集群后,您可以在创建任何数据模型时指定名称,从而使用该集群保存记录。
关系
OrientDB 支持两种关系:引用和嵌入。引用关系表示它将直接链接存储到关系的目标对象中。嵌入关系表示它将关系存储在嵌入它的记录中。这种关系比引用关系更强。
数据库
数据库是访问实际存储的接口。IT 了解查询、模式、元数据、索引等高级概念。OrientDB 还提供多种数据库类型。有关这些类型的更多信息,请参阅数据库类型。
OrientDB - 数据类型
OrientDB 原生支持多种数据类型。以下是完整的表格。
| Sr.编号 | 类型 | 描述 |
|---|---|---|
| 1 | 布尔值 | 仅处理 True 或 False 值。 Java 类型:java.lang.Boolean 最小值:0 最大值:1 |
| 2 | Integer | 32 位有符号整数。 Java 类型:java.lang.Interger 最小值:-2,147,483,648 最大值:+2,147,483,647 |
| 3 | Short | 小的 16 位有符号整数。 Java 类型:java.lang.short 最小值:-32,768 最大值:32,767 |
| 4 | Long | 大 64 位有符号整数。 Java 类型:java.lang.Long 最小值:-263 最大值:+263-1 |
| 5 | Float | 十进制数。 Java 类型:java.lang.Float 最小值:2-149 最大值:(2-2-23)*2,127 |
| 6 | Double | 高精度十进制数。 Java 类型:Java.lang.Double。 最小值:2-1074 最大值:(2-2-52)*21023 |
| 7 | Date-time | 任何日期,精度可达毫秒。 Java 类型:java.util.Date |
| 8 | String | 任何字符串,以字符的字母数字序列表示。 Java 类型:java.lang.String |
| 9 | Binary | 可以包含任何值作为字节数组。 Java 类型:byte[ ] 最小值:0 最大值:2,147,483,647 |
| 10 | Embedded | 记录包含在所有者内。所包含的记录没有 RecordId。 Java 类型:ORecord |
| 11 | Embedded list | 记录包含在所有者内。所包含的记录没有 RecordId,只能通过导航所有者记录才能访问。 Java 类型:List<objects> 最小值:0 最大值:41,000,000 个项目 |
| 12 | Embedded set | 记录包含在所有者内。所包含的记录没有 RecordId,只能通过导航所有者记录才能访问。 Java 类型:set<objects> 最小值:0 最大值:41,000,000 个项目 |
| 13 | Embedded map | 记录作为条目的值包含在所有者中,而键只能是字符串。所包含的记录没有 RecordId,只能通过导航所有者记录才能访问。 Java 类型:Map<String, ORecord> 最小值:0 最大值:41,000,000 个项目 |
| 14 | Link | 链接到另一条记录。这是一种常见的一对一关系 Java 类型:ORID,<? extends ORecord> 最小值:1 最大值:32767:2^63-1 |
| 15 | Link list | 链接到其他记录。这是一种常见的一对多关系,其中仅存储 RecordId。 Java 类型:列表<?扩展 ORecord> 最小值:0 最大值:41,000,000 个项目 |
| 16 | Link set | 链接到其他记录。这是一种常见的一对多关系。 Java 类型:Set<? extends ORecord> 最小值:0 最大值:41,000,000 个项目 |
| 17 | Link map | 链接到其他记录作为条目的值,而键只能是字符串。这是一种常见的一对多关系。仅存储 RecordId。 Java 类型:Map<String, ? extends Record> 最小值:0 最大值:41,000,000 个项目 |
| 18 | Byte | 单个字节。可用于存储小型 8 位有符号整数。 Java 类型:java.lang.Byte 最小值:-128 最大值:+127 |
| 19 | Transient | 任何未存储在数据库中的值。 |
| 20 | Date | 任何日期,如年、月和日。 Java 类型: java.util.Date |
| 21 | Custom | 用于存储提供 Marshall 和 Unmarshall 方法的自定义类型。 Java 类型:OSerializableStream 最小值:0 最大值:x |
| 22 | Decimal | 不四舍五入的十进制数。 Java 类型: java.math.BigDecimal |
| 23 | LinkBag | 作为特定 RidBag 的 RecordIds 列表。 Java 类型:ORidBag |
| 24 | Any | 不确定类型,用于指定混合类型的集合,以及 null。 |
在以下章节中,将讨论如何在 OrientDB 中使用这些数据类型。
OrientDB - 控制台模式
OrientDB 控制台是一个 Java 应用程序,用于处理 OrientDB 数据库和服务器实例。OrientDB 支持多种控制台模式。
交互模式
这是默认模式。只需执行以下脚本 bin/console.sh(或 MS Windows 系统中的 bin/console.bat)即可启动控制台。确保对其具有执行权限。
OrientDB console v.1.6.6 www.orientechnologies.com Type 'help' to display all the commands supported. orientdb>
完成后,控制台即可接受命令。
批处理模式
要在批处理模式下执行命令,请运行以下 bin/console.sh(或 MS Windows 系统中的 bin/console.bat)脚本,传递所有用分号";"分隔的命令。
orientdb> console.bat "connect remote:localhost/demo;select * from profile"
或者调用控制台脚本,传递包含要执行的命令列表的文本格式的文件名称。命令必须用分号";"分隔。
示例
Command.txt 包含您要通过 OrientDB 控制台执行的命令列表。以下命令从 command.txt 文件中接受一批命令。
orientdb> console.bat commands.txt
在批处理模式下,您可以通过将"ignoreErrors"变量设置为 true 来忽略错误,让脚本继续执行。
orientdb> set ignoreErrors true
启用 Echo
在管道中运行控制台命令时,您需要显示它们。通过在开头将其设置为属性来启用命令的"echo"。以下是在 OrientDB 控制台中启用 echo 属性的语法。
orientdb> set echo true
OrientDB - 创建数据库
OrientDB 数据库的 SQL 参考提供了几个命令来创建、更改和删除数据库。
以下语句是创建数据库命令的基本语法。
CREATE DATABASE <database-url> [<user> <password> <storage-type> [<db-type>]]
以下是有关上述语法中选项的详细信息。
<database-url> − 定义数据库的 URL。URL 包含两部分,一部分是 <mode>,第二部分是 <path>。
<mode> −定义模式,即本地模式或远程模式。
<path> − 定义数据库的路径。
<user> − 定义要连接到数据库的用户。
<password> − 定义连接到数据库的密码。
<storage-type> − 定义存储类型。您可以在 PLOCAL 和 MEMORY 之间进行选择。
示例
您可以使用以下命令创建名为 demo 的本地数据库。
Orientdb> CREATE DATABASE PLOCAL:/opt/orientdb/databses/demo
如果数据库创建成功,您将获得以下输出。
Database created successfully.
Current database is: plocal: /opt/orientdb/databases/demo
orientdb {db = demo}>
OrientDB - Alter Database 更改数据库
数据库是重要的数据模型之一,具有不同的属性,您可以根据需要进行修改。
以下语句是更改数据库命令的基本语法。
ALTER DATABASE <attribute-name> <attribute-value>
其中 <attribute-name> 定义要修改的属性,<attribute-value> 定义要为该属性设置的值。
下表定义了用于更改数据库的支持属性列表。
| Sr.No. | 属性名称 | 描述 |
|---|---|---|
| 1 | STATUS | 定义不同属性之间的数据库状态。 |
| 2 | IMPORTING | 设置导入状态。 |
| 3 | DEFAULTCLUSTERID | 使用 ID 设置默认集群。默认情况下为 2。 |
| 4 | DATEFORMAT | 将特定日期格式设置为默认格式。默认情况下为"yyyy-MM-dd"。 |
| 5 | DATETIMEFORMAT | 将特定日期时间格式设置为默认格式。默认情况下为"yyyy-MM-dd HH:mm:ss"。 |
| 6 | TIMEZONE | 设置特定时区。默认情况下,它是 Java 虚拟机 (JVM) 的默认时区。 |
| 7 | LOCALECOUNTRY | 设置默认语言环境国家/地区。默认情况下,它是 JVM 的默认语言环境国家/地区。例如:"GB"。 |
| 8 | LOCALELANGUAGE | 设置默认语言环境语言。默认情况下,它是 JVM 的默认语言环境语言。例如:"en"。 |
| 9 | CHARSET | 设置字符集的类型。默认情况下,它是 JVM 的默认字符集。例如:"utf8"。 |
| 10 | CLUSTERSELECTION | 设置用于选择集群的默认策略。这些策略与类创建一起创建。支持的策略包括默认、循环和平衡。 |
| 11 | MINIMUMCLUSTERS | 设置创建新类时自动创建的最小聚类数。默认情况下为 1。 |
| 12 | CUSTOM | 设置自定义属性。 |
| 13 | VALIDATION | 禁用或启用整个数据库的验证。 |
示例
从 OrientDB-2.2 版本开始,添加了新的 SQL 解析器,在某些情况下不允许使用常规语法。因此,在某些情况下我们必须禁用新的 SQL 解析器 (StrictSQL)。您可以使用以下 Alter database 命令禁用 StrictSQL 解析器。
orientdb> ALTER DATABASE custom strictSQL = false
如果命令执行成功,您将获得以下输出。
Database updated successfully
OrientDB - 备份数据库
与 RDBMS 一样,OrientDB 也支持备份和恢复操作。执行备份操作时,它将使用 ZIP 算法将当前数据库的所有文件压缩为 zip 格式。启用自动备份服务器插件即可自动使用此功能(备份)。
备份数据库或导出数据库是相同的,但是,根据程序,我们必须知道何时使用备份以及何时使用导出。
备份时,它将创建数据库的一致副本,所有进一步的写入操作都将被锁定并等待完成备份过程。在此操作中,它将创建只读备份文件。
如果您在备份时需要并发读写操作,则必须选择导出数据库而不是备份数据库。导出不会锁定数据库,并允许在导出过程中并发写入。
以下语句是数据库备份的基本语法。
./backup.sh <dburl> <user> <password> <destination> [<type>]
以下是有关上述语法中选项的详细信息。
<dburl> − 数据库所在的数据库 URL,无论是本地还是远程位置。
<user> − 指定运行备份的用户名。
<password> −为特定用户提供密码。
<destination> − 目标文件位置,说明存储备份 zip 文件的位置。
<type> − 可选备份类型。它有两个选项之一。
默认 − 在备份期间锁定数据库。
LVM −在后台使用 LVM 写时复制快照。
示例
将位于本地文件系统 /opt/orientdb/databases/demo 中的数据库 demo 备份到名为 sample-demo.zip 的文件中,并位于当前目录中。
您可以使用以下命令备份数据库 demo。
$ backup.sh plocal: opt/orientdb/database/demo admin admin ./backup-demo.zip
使用控制台
您可以使用 OrientDB 控制台执行相同操作。在备份特定数据库之前,您必须先连接到数据库。您可以使用以下命令连接到名为 demo 的数据库。
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin admin
连接后,您可以使用以下命令将数据库备份到当前目录中名为"backup-demo.zip"的文件中。
orientdb {db=demo}> BACKUP DATABASE ./backup-demo.zip
如果此命令执行成功,您将收到一些成功通知以及以下消息。
Backup executed in 0.30 seconds
OrientDB - 恢复数据库
与 RDBMS 一样,OrientDB 也支持恢复操作。只有从控制台模式,您才能成功执行此操作。
以下语句是恢复操作的基本语法。
orientdb> RESTORE DATABSE <url of the backup zip file>
示例
您只能从控制台模式执行此操作。因此,首先您必须使用以下 OrientDB 命令启动 OrientDB 控制台。
$ orientdb
然后,连接到相应的数据库以恢复备份。您可以使用以下命令连接到名为 demo 的数据库。
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin admin
连接成功后,您可以使用以下命令从"backup-demo.zip"文件恢复备份。执行前,请确保 backup-demo.zip 文件位于当前目录中。
Orientdb {db = demo}> RESTORE DATABASE backup-demo.zip
如果此命令执行成功,您将收到一些成功通知以及以下消息。
Database restored in 0.26 seconds
OrientDB - 连接数据库
本章介绍如何从 OrientDB 命令行连接到特定数据库。它打开一个数据库。
以下语句是 Connect 命令的基本语法。
CONNECT <database-url> <user> <password>
以下是有关上述语法中选项的详细信息。
<database-url> − 定义数据库的 URL。URL 包含两部分,一部分是 <mode>,第二部分是 <path>。
<mode> −定义模式,即本地模式或远程模式。
<path> − 定义数据库的路径。
<user> − 定义要连接到数据库的用户。
<password> − 定义连接到数据库的密码。
示例
在前面的章节中,我们已经创建了一个名为"demo"的数据库。在此示例中,我们将使用用户 admin 连接到该数据库。
您可以使用以下命令连接到 demo 数据库。
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin admin
如果连接成功,您将得到以下输出 −
Connecting to database [plocal:/opt/orientdb/databases/demo] with user 'admin'…OK
Orientdb {db = demo}>
OrientDB - 断开数据库连接
本章介绍如何从 OrientDB 命令行断开与特定数据库的连接。它将关闭当前打开的数据库。
以下语句是 Disconnect 命令的基本语法。
DISCONNECT
注意 − 您只能在连接到特定数据库后使用此命令,并且它只会关闭当前正在运行的数据库。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将断开与 demo 数据库的连接。
您可以使用以下命令断开数据库连接。
orientdb {db = demo}> DISCONNECT
如果成功断开连接,您将获得以下输出 −
Disconnecting to database [plocal:/opt/orientdb/databases/demo] with user 'admin'…OK orientdb>
OrientDB - Info 数据库
本章介绍如何从 OrientDB 命令行获取特定数据库的信息。
以下语句是 Info 命令的基本语法。
info
注意 − 您只能在连接到特定数据库后使用此命令,并且它将仅检索当前正在运行的数据库的信息。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将从 demo 数据库中检索基本信息。
您可以使用以下命令断开数据库连接。
orientdb {db = demo}> info
如果成功断开连接,您将获得以下输出。
Current database: demo (url = plocal:/opt/orientdb/databases/demo) DATABASE PROPERTIES --------------------------------+---------------------------------------------+ NAME | VALUE | --------------------------------+---------------------------------------------+ Name | null | Version | 14 | Conflict Strategy | version | Date format | yyyy-MM-dd | Datetime format | yyyy-MM-dd HH:mm:ss | Timezone | Asia/Kolkata | Locale Country | IN | Locale Language | en | Charset | UTF-8 | Schema RID | #0:1 | Index Manager RID | #0:2 | Dictionary RID | null | --------------------------------+---------------------------------------------+ DATABASE CUSTOM PROPERTIES: +-------------------------------+--------------------------------------------+ | NAME | VALUE | +-------------------------------+--------------------------------------------+ | strictSql | true | +-------------------------------+--------------------------------------------+ CLUSTERS (collections) ---------------------------------+-------+-------------------+----------------+ NAME | ID | CONFLICT STRATEGY | RECORDS | ---------------------------------+-------+-------------------+----------------+
OrientDB - 列出数据库
本章介绍如何从 OrientDB 命令行获取实例中所有数据库的列表。
以下语句是 info 命令的基本语法。
LIST DATABASES
注意 − 只有在连接到本地或远程服务器后才能使用此命令。
示例
在检索数据库列表之前,我们必须通过远程服务器连接到本地服务器。需要提醒的是,连接localhost实例的用户名和密码分别是guest和guest,在orintdb/config/orientdb-server-config.xml文件中配置。
您可以使用以下命令连接到localhost数据库服务器实例。
orientdb> connect remote:localhost guest
它会询问密码。根据配置文件,guest的密码也是guest。如果连接成功,您将得到以下输出。
Connecting to remote Server instance [remote:localhost] with user 'guest'...OK
orientdb {server = remote:localhost/}>
连接到localhost数据库服务器后,您可以使用以下命令列出数据库。
orientdb {server = remote:localhost/}> list databases
如果成功执行,你将得到以下输出 −
Found 6 databases:
* demo (plocal)
* s2 (plocal)
* s1 (plocal)
* GratefulDeadConcerts (plocal)
* s3 (plocal)
* sample (plocal)
orientdb {server = remote:localhost/}>
OrientDB - 冻结数据库
每当您想将数据库状态设为静态时,这意味着数据库不响应任何读写操作的状态。简而言之,数据库处于冻结状态。
在本章中,您可以了解如何从 OrientDB 命令行冻结数据库。
以下语句是冻结数据库命令的基本语法。
FREEZE DATABASE
注意 − 只有在连接到远程或本地数据库中的特定数据库后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将从 CLI 冻结此数据库。
您可以使用以下命令冻结数据库。
Orientdb {db = demo}> FREEZE DATABASE
如果成功执行,您将获得以下输出。
Database 'demo' was frozen successfully
OrientDB - 释放数据库
在本章中,您可以了解如何通过 OrientDB 命令行释放冻结状态的数据库。
以下语句是释放数据库命令的基本语法。
RELEASE DATABASE
注意 − 只有在连接到处于冻结状态的特定数据库后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将释放在上一章中冻结的数据库。
您可以使用以下命令释放数据库。
Orientdb {db = demo}> RELEASE DATABASE
如果成功执行,您将获得以下输出。
Database 'demo' was release successfully
OrientDB - 配置数据库
在本章中,您可以了解如何通过 OrientDB 命令行显示特定数据库的配置。此命令适用于本地和远程数据库。
配置信息包含默认缓存(启用或未启用)、该缓存的大小、负载因子值、映射的最大内存、节点页面大小、池最小和最大大小等。
以下语句是配置数据库命令的基本语法。
CONFIG
注意 −只有在连接到特定数据库后才能使用此命令。
示例
在此示例中,我们将使用上一章中创建的名为"demo"的相同数据库。
您可以使用以下命令显示 demo 数据库的配置。
Orientdb {db = demo}> CONFIG
如果成功执行,您将获得以下输出。
LOCAL SERVER CONFIGURATION:
+---------------------------------------+-------------------------+
| NAME | VALUE |
+---------------------------------------+-------------------------+
| environment.dumpCfgAtStartup | false |
| environment.concurrent | true |
| environment.allowJVMShutdown | true |
| script.pool.maxSize | 20 |
| memory.useUnsafe | true |
| memory.directMemory.safeMode | true |
| memory.directMemory.trackMode | false |
|……………………………….. | |
| storage.lowestFreeListBound | 16 |
| network.binary.debug | false |
| network.http.maxLength | 1000000 |
| network.http.charset | utf-8 |
| network.http.jsonResponseError | true |
| network.http.json | false |
| tx.log.fileType | classic |
| tx.log.synch | false |
| tx.autoRetry | 1 |
| client.channel.minPool | 1 |
| storage.keepOpen | true |
| cache.local.enabled | true |
+---------------------------------------+-------------------------+
orientdb {db = demo}>
在上面的配置参数列表中,如果您想更改任何参数值,那么您可以使用 config set 和 get 命令轻松地从命令行进行更改。
CONFIG SET
您可以使用 CONFIG SET 命令更新配置变量值。
以下语句是 config set 命令的基本语法。
CONFIG SET <config-variable> <config-value>
注意 − 只有在连接到特定数据库后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将'tx.autoRetry'变量值修改为5。
您可以使用以下命令设置demo数据库的配置。
orientdb {db = demo}> CONFIG SET tx.autoRetry 5
如果成功执行,您将得到以下输出。
Local configuration value changed correctly
Config Get
您可以使用 CONFIG GET 命令显示配置变量值。
以下语句是 config get 命令的基本语法。
CONFIG GET <config-variable>
注意 − 只有在连接到特定数据库后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的同一数据库。我们将尝试检索"tx.autoRetry"变量值。
您可以使用以下命令显示 demo 数据库的配置。
orientdb {db = demo}> CONFIG GET tx.autoRetry
如果成功执行,您将获得以下输出。
Local configuration: tx.autoRetry = 5
OrientDB - 导出数据库
与 RDBMS 一样,OrientDB 也提供导出和导入数据库等功能。OrientDB 使用 JSON 格式导出数据。默认情况下,导出命令使用 GZIP 算法压缩文件。
导出数据库时不会锁定数据库,这意味着您可以对其执行并发读写操作。这也意味着您可以创建该数据的精确副本,因为并发读写操作。
在本章中,您可以了解如何从 OrientDB 命令行导出数据库。
以下语句是导出数据库命令的基本语法。
EXPORT DATABASE <output file>
注意 −只有在连接到特定数据库后才能使用此命令。
示例
在此示例中,我们将使用上一章中创建的名为"demo"的相同数据库。您可以使用以下命令将数据库导出到名为"export-demo"的文件中。
orientdb {db = demo}> EXPORT DATABASE ./export-demo.export
如果成功执行,它将根据操作系统创建一个名为"export-demo.zip"或"exportdemo.gz"的文件,您将获得以下输出。
Exporting current database to: DATABASE /home/linuxtp/Desktop/demo.export in GZipped JSON format ... Started export of database 'demo' to /home/linuxtp/Desktop/demo.export.gz... Exporting database info...OK Exporting clusters...OK (12 clusters) Exporting schema...OK (11 classes) Exporting records... - Cluster 'internal' (id = 0)...OK (records = 3/3) - Cluster 'index' (id = 1)...OK (records = 0/0) - Cluster 'manindex' (id = 2)...OK (records = 0/0) - Cluster 'default' (id = 3)...OK (records = 0/0) - Cluster 'orole' (id = 4)...OK (records = 3/3) - Cluster 'ouser' (id = 5)...OK (records = 3/3) - Cluster 'ofunction' (id = 6)...OK (records = 0/0) - Cluster 'oschedule' (id = 7)...OK (records = 0/0) - Cluster 'orids' (id = 8)...OK (records = 0/0) - Cluster 'v' (id = 9)...OK (records = 0/0) - Cluster 'e' (id = 10)...OK (records = 0/0) - Cluster '_studio' (id = 11)...OK (records = 1/1) Done. Exported 10 of total 10 records Exporting index info... - Index dictionary...OK - Index OUser.name...OK - Index ORole.name...OK OK (3 indexes) Exporting manual indexes content... - Exporting index dictionary ...OK (entries = 0) OK (1 manual indexes) Database export completed in 377ms
OrientDB - 导入数据库
每当您想要导入数据库时,您必须使用由 export 命令生成的 JSON 格式导出文件。
在本章中,您可以了解如何从 OrientDB 命令行导入数据库。
以下语句是 Import database 命令的基本语法。
IMPORT DATABASE <input file>
注意 − 只有在连接到特定数据库后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。您可以使用以下命令将数据库导入到名为"export-demo.gz"的文件中。
orientdb {db = demo}> IMPORT DATABASE ./export-demo.export.gz
如果成功执行,您将获得以下输出以及成功通知。
Database import completed in 11612ms
OrientDB - 提交数据库
与 RDBMS 类似,OrientDB 也提供提交和回滚等事务概念。提交 是指通过保存对数据库的所有更改来关闭事务。回滚 是指将数据库状态恢复到打开事务的位置。
以下语句是提交数据库命令的基本语法。
COMMIT
注意 − 只有在连接到特定数据库并开始事务后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将看到提交事务的操作并使用事务存储记录。
首先,使用以下BEGIN命令启动事务。
orientdb {db = demo}> BEGIN
然后,使用以下命令将记录插入员工表中,其值为 id = 12 和 name = satish.P。
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')
您可以使用以下命令提交事务。
orientdb> commit
如果此事务成功提交,您将获得以下输出。
Transaction 2 has been committed in 4ms
OrientDB - 回滚数据库
在本章中,您将学习如何通过 OrientDB 命令行界面回滚未提交的事务。
以下语句是回滚数据库命令的基本语法。
ROLLBACK
注意 − 只有在连接到特定数据库并开始事务后才能使用此命令。
示例
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。我们将看到回滚事务的操作并使用事务存储记录。
首先,使用以下 BEGIN 命令启动事务。
orientdb {db = demo}> BEGIN
然后,使用以下命令将记录插入到雇员表中,其值为 id = 12 和 name = satish.P。
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')
您可以使用以下命令从雇员表中检索记录。
orientdb> SELECT FROM employee WHERE name LIKE '%.P'
如果此命令执行成功,您将获得以下输出。
---+-------+-------------------- # | ID | name ---+-------+-------------------- 0 | 12 | satish.P ---+-------+-------------------- 1 item(s) found. Query executed in 0.076 sec(s).
现在,您可以使用以下命令回滚此事务。
orientdb> ROLLBACK
再次检查选择查询以从员工表中检索相同的记录。
orientdb> SELECT FROM employee WHERE name LIKE '%.P'
如果回滚成功执行,您将在输出中找到 0 条记录。
0 item(s) found. Query executed in 0.037 sec(s).
OrientDB - 优化数据库
根据技术术语,优化 意味着"在最短的时间内实现更好的性能"。对于数据库,优化涉及最大化数据检索的速度和效率。
OrientDB 支持轻量级边缘,这意味着数据实体之间存在直接关系。简单来说,这是一种字段到字段的关系。OrientDB 提供了优化数据库的不同方法。它支持将常规边转换为轻量边。
以下语句是 Optimize 数据库命令的基本语法。
OPTMIZE DATABASE [-lwedges] [-noverbose]
其中 lwedges 将常规边转换为轻量边,noverbose 禁用输出。
示例
在此示例中,我们将使用与上一章中创建的名为"demo"的相同数据库。您可以使用以下 Optimize 数据库命令。
OPTIMIZE DATABASE -lwedges
如果成功执行,您将收到一些成功通知以及完成消息。
Database Optimization completed in 35ms
OrientDB - 删除数据库
与 RDBMS 类似,OrientDB 提供删除数据库的功能。删除数据库是指完全删除数据库。
以下语句是删除数据库命令的基本语法。
DROP DATABASE [<database-name> <server-username> <server-user-password>]
以下是有关上述语法中选项的详细信息。
<database-name> − 您要删除的数据库名称。
<server-username> −有权删除数据库的数据库用户名。
<server-user-password> − 特定用户的密码。
示例
删除数据库有两种方法,一种是删除当前打开的数据库,另一种是通过提供特定名称来删除特定数据库。
在此示例中,我们将使用我们在上一章中创建的名为"demo"的相同数据库。您可以使用以下命令删除数据库demo。
orientdb {db = demo}> DROP DATABASE
如果此命令成功执行,您将获得以下输出。
Database 'demo' deleted successfully
或
您可以使用另一个命令删除数据库,如下所示。
orientdb> DROP DATABASE PLOCAL:/opt/orientdb/databases/demo admin admin
如果此命令成功执行,您将获得以下输出。
Database 'demo' deleted successfully
OrientDB - 插入记录
OrientDB 是一个 NoSQL 数据库,可以存储文档和面向图形的数据。NoSQL 数据库不包含任何表,因此如何将数据插入为记录。在这里,您可以看到类、属性、顶点和边形式的表数据,这意味着类就像表,属性就像表中的文件。
我们可以使用 OrientDB 中的 schema 定义所有这些实体。属性数据可以插入到类中。插入命令在数据库模式中创建新记录。记录可以没有模式,也可以遵循一些指定的规则。
以下语句是插入记录命令的基本语法。
INSERT INTO [class:]<class>|cluster:<cluster>|index:<index>
[(<field>[,]*) VALUES (<expression>[,]*)[,]*]|
[SET <field> = <expression>|<sub-command>[,]*]|
[CONTENT {<JSON>}]
[RETURN <expression>]
[FROM <query>]
以下是有关上述语法中选项的详细信息。
SET − 定义每个字段及其值。
CONTENT − 定义 JSON 数据以设置字段值。这是可选的。
RETURN − 定义要返回的表达式而不是插入的记录数。最常见的用例是 −
@rid − 返回新记录的记录 ID。
@this − 返回整个新记录。
FROM −您想要插入记录或结果集的位置。
示例
让我们考虑一个包含以下字段和类型的客户表。
| Sr.No. | Field Name | Type |
|---|---|---|
| 1 | Id | Integer |
| 2 | Name | String |
| 3 | Age | Integer |
您可以通过执行以下命令来创建模式(表)。
CREATE DATABASE PLOCAL:/opt/orientdb/databases/sales CREATE CLASS Customer CREATE PROPERTY Customer.id integer CREATE PROPERTY Customer.name String CREATE PROPERTY Customer.age integer
执行完所有命令后,您将获得表名 Customer,其中包含 id、name 和 age 字段。您可以通过在 Customer 表中执行 select 查询来检查表。
OrientDB 提供了插入记录的不同方法。请考虑以下包含示例记录的 Customer 表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
以下命令是将第一条记录插入到 Customer 表中。
INSERT INTO Customer (id, name, age) VALUES (01,'satish', 25)
如果上述命令成功执行,您将获得以下输出。
Inserted record 'Customer#11:0{id:1,name:satish,age:25} v1' in 0.069000 sec(s).
以下命令是将第二条记录插入到 Customer 表中。
INSERT INTO Customer SET id = 02, name = 'krishna', age = 26
如果上述命令成功执行,您将获得以下输出。
Inserted record 'Customer#11:1{id:2,age:26,name:krishna} v1' in 0.005000 sec(s).
以下命令是将第三条记录插入到 Customer 表中。
INSERT INTO Customer CONTENT {"id": "03", "name": "kiran", "age": "29"}
如果上述命令成功执行,您将获得以下输出。
Inserted record 'Customer#11:2{id:3,name:kiran,age:29} v1' in 0.004000 sec(s).
以下命令是将接下来的两条记录插入到 Customer 表中。
INSERT INTO Customer (id, name, age) VALUES (04,'javeed', 21), (05,'raja', 29)
如果上述命令成功执行,您将获得以下输出。
Inserted record '[Customer#11:3{id:4,name:javeed,age:21} v1,
Customer#11:4{id:5,name:raja,age:29} v1]' in 0.007000 sec(s).
您可以通过执行以下命令来检查这些记录是否都已插入。
SELECT FROM Customer
如果上述命令成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 2 |#11:2|Customer|3 |kiran |29 3 |#11:3|Customer|4 |javeed |21 4 |#11:4|Customer|5 |raja |29 ----+-----+--------+----+-------+----
OrientDB - 显示记录
与 RDBMS 类似,OrientDB 支持不同类型的 SQL 查询来从数据库中检索记录。在检索记录时,我们有不同的查询变体或选项以及 select 语句。
以下语句是 SELECT 命令的基本语法。
SELECT [ <Projections> ] [ FROM <Target> [ LET <Assignment>* ] ] [ WHERE <Condition>* ] [ GROUP BY <Field>* ] [ ORDER BY <Fields>* [ ASC|DESC ] * ] [ UNWIND <Field>* ] [ SKIP <SkipRecords> ] [ LIMIT <MaxRecords> ] [ FETCHPLAN <FetchPlan> ] [ TIMEOUT <Timeout> [ <STRATEGY> ] ] [ LOCK default|record ] [ PARALLEL ] [ NOCACHE ]
以下是有关上述语法中选项的详细信息。
<Projections> − 表示要从查询中提取的数据作为结果记录集。
FROM − 表示要查询的对象。这可以是类、集群、单个记录 ID、记录 ID 集。您可以将所有这些对象指定为目标。
WHERE − 指定过滤结果集的条件。
LET − 表示在投影、条件或子查询中使用的上下文变量。
GROUP BY − 表示用于对记录进行分组的字段。
ORDER BY −指示按顺序排列记录的字段。
UNWIND − 指定要展开记录集合的字段。
SKIP − 定义要从结果集开头跳过的记录数。
LIMIT − 指示结果集中的最大记录数。
FETCHPLAN − 指定定义如何获取结果的策略。
TIMEOUT − 定义查询的最大时间(以毫秒为单位)。
LOCK − 定义锁定策略。DEFAULT 和 RECORD 是可用的锁定策略。
PARALLEL −针对"x"个并发线程执行查询。
NOCACHE − 定义是否要使用缓存。
示例
让我们考虑上一章中创建的以下客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
尝试使用不同的选择查询从 Customer 表中检索数据记录。
方法 1 − 您可以使用以下查询从 Customer 表中选择所有记录。
orientdb {db = demo}> SELECT FROM Customer
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 2 |#11:2|Customer|3 |kiran |29 3 |#11:3|Customer|4 |javeed |21 4 |#11:4|Customer|5 |raja |29 ----+-----+--------+----+-------+----
方法 2 − 选择名称以字母"k"开头的所有记录。
orientdb {db = demo}> SELECT FROM Customer WHERE name LIKE 'k%'
或者,您可以对上述示例使用以下查询。
orientdb {db = demo}> SELECT FROM Customer WHERE name.left(1) = 'k'
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:1|Customer|2 |krishna|26 1 |#11:2|Customer|3 |kiran |29 ----+-----+--------+----+-------+----
方法 3 − 从 Customer 表中选择 id、name 且名称为大写字母的记录。
orientdb {db = demo}> SELECT id, name.toUpperCase() FROM Customer
如果上述查询成功执行,您将获得以下输出。
----+--------+----+------- # |@CLASS |id |name ----+--------+----+------- 0 |null |1 |SATISH 1 |null |2 |KRISHNA 2 |null |3 |KIRAN 3 |null |4 |JAVEED 4 |null |5 |RAJA ----+--------+----+-------
方法 4 − 从 Customer 表中选择年龄在 25 至 29 范围内的所有记录。
orientdb {db = demo}> SELECT FROM Customer WHERE age in [25,29]
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:2|Customer|3 |kiran |29 2 |#11:4|Customer|5 |raja |29 ----+-----+--------+----+-------+----
方法 5 − 从 Customer 表中选择所有字段包含单词 'sh' 的记录。
orientdb {db = demo}> SELECT FROM Customer WHERE ANY() LIKE '%sh%'
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 ----+-----+--------+----+-------+----
方法 6 − 从 Customer 表中选择所有记录,按年龄降序排列。
orientdb {db = demo}> SELECT FROM Customer ORDER BY age DESC
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:2|Customer|3 |kiran |29 1 |#11:4|Customer|5 |raja |29 2 |#11:1|Customer|2 |krishna|26 3 |#11:0|Customer|1 |satish |25 4 |#11:3|Customer|4 |javeed |21 ----+-----+--------+----+-------+----
OrientDB - Load Record
Load Record 用于从架构中加载特定记录。加载记录将借助记录 ID 加载记录。它在结果集中用 @rid 符号表示。
以下语句是加载记录命令的基本语法。
Load Record <record-id>
其中 <record-id> 定义要加载的记录的记录 ID。
如果您不知道特定记录的记录 ID,则可以针对表执行任何查询。在结果集中,您将找到相应记录的记录 ID (@rid)。
示例
让我们考虑在前几章中使用的相同客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
尝试以下查询来检索具有记录 ID @rid: #11:0 的记录。
orientdb {db = demo}> LOAD RECORD #11:0
如果上述查询成功执行,您将获得以下输出。
+---------------------------------------------------------------------------+ | Document - @class: Customer @rid: #11:0 @version: 1 | +---------------------------------------------------------------------------+ | Name | Value | +---------------------------------------------------------------------------+ | id | 1 | | name | satish | | age | 25 | +---------------------------------------------------------------------------+
OrientDB - Reload Record
Reload Record 的工作方式与加载记录命令类似,也用于从模式中加载特定记录。加载记录将借助记录 ID 加载记录。它在结果集中用 @rid 符号表示。主要区别在于重新加载记录会忽略缓存,这在应用外部并发事务来更改记录时很有用。它将提供最新更新。
以下语句是 RELOAD 记录命令的基本语法。
Reload Record <record-id>
其中 <record-id> 定义要重新加载的记录的记录 ID。
如果您不知道特定记录的记录 ID,则可以针对表执行任何查询。在结果集中,您将找到相应记录的记录 ID (@rid)。
示例
让我们考虑上一章中使用的相同客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
尝试以下查询来检索记录 ID 为 @rid: #11:0 的记录。
orientdb {db = demo}> LOAD RECORD #11:0
如果上述查询成功执行,您将获得以下输出。
+---------------------------------------------------------------------------+ | Document - @class: Customer @rid: #11:0 @version: 1 | +---------------------------------------------------------------------------+ | Name | Value | +---------------------------------------------------------------------------+ | id | 1 | | name | satish | | age | 25 | +---------------------------------------------------------------------------+
OrientDB - Export Record 导出记录
Export Record 是用于将加载的记录导出为请求和支持的格式的命令。如果您执行了任何错误的语法,它将提供支持的格式列表。OrientDB 是文档数据库系列,因此 JSON 是默认支持的格式。
以下语句是导出记录命令的基本语法。
Export Record <format>
其中 <Format> 定义您想要获取记录的格式。
注意 − 导出命令将根据记录 ID 导出加载的记录。
示例
让我们考虑上一章中使用的相同客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
尝试以下查询来检索具有记录 ID @rid: #11:0 的记录。
orientdb {db = demo}> LOAD RECORD #11:0
如果上述查询成功执行,您将获得以下输出。
+---------------------------------------------------------------------------+ | Document - @class: Customer @rid: #11:0 @version: 1 | +---------------------------------------------------------------------------+ | Name | Value | +---------------------------------------------------------------------------+ | id | 1 | | name | satish | | age | 25 | +---------------------------------------------------------------------------+
使用以下查询将已加载的记录 (#11:0) 导出为 JSON 格式。
orientdb {db = demo}> EXPORT RECORD json
如果上述查询成功执行,您将获得以下输出。
{
"@type": "d",
"@rid": "#11:0",
"@version": 1,
"@class": "Customer",
"id": 1,
"name": "satish",
"age": 25
}
OrientDB - 更新记录
UPDATE更新记录命令用于修改特定记录的值。SET 是更新特定字段值的基本命令。
以下语句是更新命令的基本语法。
UPDATE <class>|cluster:<cluster>|<recordID> [SET|INCREMENT|ADD|REMOVE|PUT <field-name> = <field-value>[,]*] |[CONTENT| MERGE <JSON>] [UPSERT] [RETURN <returning> [<returning-expression>]] [WHERE <conditions>] [LOCK default|record] [LIMIT <max-records>] [TIMEOUT <timeout>]
以下是有关上述语法中选项的详细信息。
SET − 定义要更新的字段。
INCREMENT − 将指定字段值增加给定值。
ADD − 在集合字段中添加新项目。
REMOVE − 从集合字段中删除一个项目。
PUT − 将条目放入映射字段。
CONTENT − 用 JSON 文档内容替换记录内容。
MERGE − 将记录内容与 JSON 文档合并。
LOCK − 指定如何在加载和更新之间锁定记录。我们有两个选项来指定Default和Record。
UPSERT − 如果记录存在则更新记录,如果不存在则插入新记录。它有助于执行单个查询而不是执行两个查询。
RETURN − 指定要返回的表达式而不是记录数。
LIMIT − 定义要更新的最大记录数。
TIMEOUT − 定义在超时之前允许更新运行的时间。
示例
让我们考虑上一章中使用的相同客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 29 |
尝试以下查询来更新客户"Raja"的年龄。
Orientdb {db = demo}> UPDATE Customer SET age = 28 WHERE name = 'Raja'
如果上述查询成功执行,您将获得以下输出。
Updated 1 record(s) in 0.008000 sec(s).
要检查 Customer 表的记录,您可以使用以下查询。
orientdb {db = demo}> SELECT FROM Customer
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 2 |#11:2|Customer|3 |kiran |29 3 |#11:3|Customer|4 |javeed |21 4 |#11:4|Customer|5 |raja |28 ----+-----+--------+----+-------+----
OrientDB - Truncate Record
Truncate Record 命令用于删除特定记录的值。
以下语句是 Truncate 命令的基本语法。
TRUNCATE RECORD <rid>*
其中 <rid>* 表示要截断的记录 ID。您可以使用逗号分隔的多个 Rid 来截断多个记录。它返回截断的记录数。
示例
让我们考虑上一章中使用的相同 Customer 表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Raja | 28 |
尝试以下查询来截断记录 ID 为 #11:4 的记录。
Orientdb {db = demo}> TRUNCATE RECORD #11:4
如果上述查询成功执行,您将获得以下输出。
Truncated 1 record(s) in 0.008000 sec(s).
要检查 Customer 表的记录,您可以使用以下查询。
Orientdb {db = demo}> SELECT FROM Customer
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 2 |#11:2|Customer|3 |kiran |29 3 |#11:3|Customer|4 |javeed |21 ----+-----+--------+----+-------+----
OrientDB - 删除记录
Delete 删除记录命令用于从数据库中彻底删除一条或多条记录。
以下语句是 Delete 命令的基本语法。
DELETE FROM <Class>|cluster:<cluster>|index:<index> [LOCK <default|record>] [RETURN <returning>] [WHERE <Condition>*] [LIMIT <MaxRecords>] [TIMEOUT <timeout>]
以下是有关上述语法中选项的详细信息。
LOCK − 指定如何在加载和更新之间锁定记录。我们有两个选项来指定Default和Record。
RETURN − 指定要返回的表达式而不是记录数。
LIMIT − 定义要更新的最大记录数。
TIMEOUT − 定义在超时之前允许更新运行的时间。
注意 − 不要使用 DELETE 删除顶点或边,因为它会影响图的完整性。
示例
让我们考虑客户表。
| Sr.No. | Name | Age |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
尝试以下查询来删除 id = 4 的记录。
orientdb {db = demo}> DELETE FROM Customer WHERE id = 4
如果上述查询成功执行,您将获得以下输出。
Delete 1 record(s) in 0.008000 sec(s).
要检查客户表的记录,您可以使用以下查询。
Orientdb {db = demo}> SELECT FROM Customer
如果上述查询成功执行,您将获得以下输出。
----+-----+--------+----+-------+---- # |@RID |@CLASS |id |name |age ----+-----+--------+----+-------+---- 0 |#11:0|Customer|1 |satish |25 1 |#11:1|Customer|2 |krishna|26 2 |#11:2|Customer|3 |kiran |29 ----+-----+--------+----+-------+----
OrientDB - Create Class 创建类
OrientDB 支持多模型功能,并提供不同的方式来处理和理解数据库的基本概念。但是,我们可以从文档数据库 API 的角度轻松访问这些模型。与 RDBMS 一样,OrientDB 也使用记录作为存储元素,但它使用的是文档类型。文档以键/值对的形式存储。我们将字段和属性存储为属于概念类的键/值对。
类是一种数据模型,其概念源自面向对象编程范式。基于传统的文档数据库模型,数据以集合的形式存储,而在关系数据库模型中,数据存储在表中。OrientDB 遵循文档 API 和 OPPS 范式。作为一个概念,OrientDB 中的类与关系数据库中的表关系最密切,但(与表不同)类可以是无模式、全模式或混合模式。类可以从其他类继承,从而创建类树。每个类都有自己的一个或多个集群(如果未定义,则默认创建)。
以下语句是创建类命令的基本语法。
CREATE CLASS <class> [EXTENDS <super-class>] [CLUSTER <cluster-id>*] [CLUSTERS <total-cluster-number>] [ABSTRACT]
以下是有关上述语法中选项的详细信息。
<class> − 定义要创建的类的名称。
<super-class> −定义要使用此类扩展的超类。
<total-cluster-number> − 定义此类中使用的集群总数。默认值为 1。
ABSTARCT − 定义类是抽象的。这是可选的。
示例
如前所述,类是与表相关的概念。因此,我们将在这里创建一个表 Account。但是,在创建类时,我们无法定义字段,即基于 OOPS 范例的属性。
以下命令用于创建一个名为 Account 的类。
orientdb> CREATE CLASS Account
如果上述命令执行成功,您将得到以下输出。
Class created successfully
您可以使用以下命令创建一个类 Car,该类扩展为类 Vehicle。
orientdb> CREATE CLASS Car EXTENDS Vehicle
如果上述命令执行成功,您将得到以下输出。
Class created successfully
您可以使用以下命令创建一个类 Person 作为抽象。
orientdb> CREATE CLASS Person ABSTRACT
如果上述命令执行成功,您将得到以下输出。
Class created successfully
注意 − 如果没有属性,类就是无用的,无法构建真正的对象。在后续章节中,您可以了解如何为特定类创建属性。
OrientDB - Alter Class 更改类
OrientDB 中的类和属性用于构建具有相应属性(如类名、超类、集群、集群数量、摘要等)的模式。如果要修改或更新模式中现有类的任何属性,则必须使用 Alter Class 命令。
以下语句是更改类命令的基本语法。
ALTER CLASS <class> <attribute-name> <attribute-value>
以下是有关上述语法中选项的详细信息。
<class> − 定义类名。
<attribute-name> −定义您想要更改的属性。
<attribute-value> −定义要为属性设置的值。
下表定义了支持 Alter Class 命令的属性列表。
| 属性 | 类型 | 描述 |
|---|---|---|
| NAME | String | 更改类名。 |
| SHORTNAME | String | 定义一个短名称类的名称(即别名)。使用 NULL 删除短名称分配。 |
| SUPERCLASS | String | 为类定义超类。要添加新类,可以使用语法 +<class>,要删除它,请使用 -<class>。 |
| OVERSIZE | 十进制数 | 定义超大因子。 |
| ADDCLUSTER | String | 向类添加集群。如果集群不存在,则创建一个物理集群。将集群添加到类中对于在分布式服务器中存储记录也很有用。 |
| REMOVECLUSTER | String | 从类中删除集群。它不会删除集群,只会将其从类中删除。 |
| STRICTMODE | - | 启用或禁用严格模式。在严格模式下,您将在架构完整模式下工作,并且如果新属性是类架构定义的一部分,则无法向记录添加新属性。 |
| CLUSTERSELECTION | - | 定义选择策略,以选择用于新记录的集群。 |
| CUSTOM | - | 定义自定义属性。属性名称和值必须遵循语法 <propertyname>=<value>名称和值之间没有空格。 |
| ABSTRACT | Boolean | 将类转换为抽象类或反之。 |
示例
让我们尝试几个更新或修改现有类的属性的示例。
以下查询用于为现有类"Employee"定义超类"Person"。
orientdb> ALTER CLASS Employee SUPERCLASS Person
如果上述查询成功执行,您将获得以下输出。
Class altered successfully
以下查询用于为现有类'Employee'添加超类'Person'。
orientdb> ALTER CLASS Employee SUPERCLASS +Person
如果上述查询成功执行,您将获得以下输出。
Class altered successfully
OrientDB - 截断类
截断类将删除定义为类一部分的集群的所有记录。在 OrientDB 中,每个类都有一个同名的关联集群。如果您还想从类层次结构中删除所有记录,则需要使用 POLYMORPHIC 关键字。
以下语句是截断类命令的基本语法。
TRUNCATE CLASS <class> [ POLYMORPHIC ] [ UNSAFE ]
以下是有关上述语法中选项的详细信息。
<class> − 定义要截断的类。
POLYMORPHIC −定义命令是否也截断层次结构。
UNSAFE − 定义命令强制截断顶点或边类。
示例
以下查询用于截断类 Profile。
orientdb> TRUNCATE CLASS Profile
如果上述查询成功执行,您将获得以下输出。
Class truncated successfully
OrientDB - Drop Class
Drop Class 命令从架构中删除一个类。注意并保持一致的架构非常重要。例如,避免删除其他类的超类。关联的集群不会被删除。
以下语句是 Drop Class 命令的基本语法。
DROP CLASS <class>
删除具有类名的类。
示例
尝试以下查询以删除类 Employee。
Orientdb> DROP CLASS Employee
如果上述查询成功执行,您将获得以下输出。
Class dropped successfully
OrientDB - 创建集群
集群是 OrientDB 中的一个重要概念,用于存储记录、文档或顶点。简单来说,集群是存储一组记录的地方。默认情况下,OrientDB 将为每个类创建一个集群。一个类的所有记录都存储在同一个集群中,该集群与该类同名。您可以在数据库中创建最多 32,767 (2^15-1) 个集群。
CREATE 类是用于创建具有特定名称的集群的命令。创建集群后,您可以在创建任何数据模型时指定名称,从而使用该集群保存记录。如果要向类中添加新集群,请使用 Alter Class 命令和 ADDCLUSTER 命令。
以下语句是 Create Cluster 命令的基本语法。
CREATE CLUSTER <cluster> [ID <cluster-id>]
其中 <cluster> 定义要创建的集群的名称,<cluster-id> 定义要用于集群的数字 ID。
下表提供了集群选择策略的列表。
| Sr.No. | 策略 &描述 |
|---|---|
| 1 | 默认 使用类属性默认 ClusterId 选择集群。 |
| 2 | 循环 按循环顺序选择下一个集群。完成后重新启动。 |
| 3 | 平衡 选择最小的集群。允许类使所有底层集群在大小上保持平衡。当向现有类添加新集群时,它会首先填充新集群。 |
示例
让我们举一个例子来创建一个名为sales的集群。
orientdb> CREATE CLUSTER sales
如果上述查询成功执行,您将获得以下输出。
Cluster created correctly with id #12
OrientDB - Alter Cluster
Alter Cluster 命令用于更新现有集群上的属性。在本章中,您可以了解如何添加或修改集群的属性。
以下语句是 Alter Cluster 命令的基本语法。
ALTER CLUSTER <cluster> <attribute-name> <attribute-value>
以下是有关上述语法中选项的详细信息。
<cluster> − 定义集群名称。
<attribute-name> − 定义要更改的属性。
<attribute-value> −定义要为此属性设置的值。
以下表格格式提供了可与 Alter cluster 命令一起使用的受支持属性列表。
| 名称 | 类型 | 描述 |
|---|---|---|
| NAME | String | 更改集群名称。 |
| STATUS | String | 更改集群状态。允许的值为 ONLINE 和 OFFLINE。默认情况下,集群处于在线状态。 |
| COMPRESSION | String | 定义要使用的压缩类型。允许的值包括 NOTHING、SNAPPY、GZIP 以及在 OCompressionFactory 类中注册的任何其他压缩类型。 |
| USE_WAL | Boolean | 定义 OrientDB 针对集群操作时是否使用日志 |
| RECORD_GROW_FACTO R | Integer | 定义增长因子以在创建记录时节省更多空间。当您使用附加信息更新记录时,您可能会发现这很有用。 |
| RECORD_OVERFLOW_GR OW_FACTOR | 整数 | 定义更新时的增长因子。当达到大小限制时,将使用此设置来获取更多空间(因子 > 1)。 |
| CONFLICTSTRATEGY | String | 定义在 OrientDB MVCC 发现针对旧记录执行的更新或删除操作时用于处理冲突的策略。 |
下表提供了冲突策略的列表。
| Sr.No. | 策略和描述 |
|---|---|
| 1 | 版本 版本不同时抛出异常。这是默认设置。 |
| 2 | 内容 如果版本不同,它会检查内容中的更改,否则它会使用最高版本以避免引发异常。 |
| 3 | 自动合并 合并更改。 |
示例
尝试以下示例查询以了解更改集群命令。
执行以下命令将集群的名称从 Employee 更改为 Employee2。
orientdb {db = demo}> ALTER CLUSTER Employee NAME Employee2
如果上述命令执行成功,您将获得以下输出。
Cluster updated successfully
执行以下命令,使用集群 ID 将集群名称从 Employee2 更改为 Employee。
orientdb {db = demo}> ALTER CLUSTER 12 NAME Employee
如果上述命令执行成功,您将得到以下输出。
Cluster updated successfully
执行以下命令将集群冲突策略更改为自动合并。
orientdb {db = demo}> ALTER CLUSTER V CONFICTSTRATEGY automerge
如果上述命令执行成功,您将得到以下输出。
Cluster updated successfully
OrientDB - 截断集群
截断集群命令删除集群的所有记录。
以下语句是截断集群命令的基本语法。
TRUNCATE CLUSTER <cluster-name>
其中 <cluster-name> 是集群的名称。
示例
尝试以下查询以截断名为 sales 的集群。
Orientdb {db = demo}> TRUNCATE CLUSTER Profile
如果上述查询成功执行,您将获得以下输出。
Cluster truncated successfully.
OrientDB - Drop Cluster
Drop Cluster 命令会删除集群及其所有相关内容。此操作是永久性的,可回滚。
以下语句是 Drop Cluster 命令的基本语法。
DROP CLUSTER <cluster-name>|<cluster-id>
其中 <cluster-name> 定义要删除的集群的名称,<cluster-id> 定义要删除的集群的 ID。
示例
尝试以下命令删除 Sales 集群。
orientdb> DROP CLUSTER Sales
如果上述查询成功执行,您将获得以下输出。
Cluster dropped successfully
OrientDB - Create Property 创建属性
OrientDB 中的属性类似于数据库表中的类和列的字段。创建属性是用于为特定类创建属性的命令。您在命令中使用的类名必须存在。
以下语句是创建属性命令的基本语法。
CREATE PROPERTY <class-name>.<property-name> <property-type> [<linked-type>][ <linked-class>]
以下是有关上述语法中选项的详细信息。
<class-name> −定义要在其中创建属性的类。
<property-name> − 定义属性的逻辑名称。
<property-type> − 定义要创建的属性的类型。
<linked-type> − 定义容器类型,用于容器属性类型。
<linked-class> −定义容器类,用于容器属性类型。
下表提供了属性的数据类型,以便 OrientDB 知道要存储的数据类型。
| BOOLEAN | INTEGER | SHORT | LONG |
| FLOAT | DATE | STRING | EMBEDDED |
| LINK | BYTE | BINARY | DOUBLE |
除此之外,还有其他几种可用作容器的属性类型。
| EMBEDDEDLIST | EMBEDDEDSET | EMBEDDEDMAP |
| LINKLIST | LINKSET | LINKMAP |
示例
尝试以下示例在 Employee 类上创建一个 String 类型的属性名称。
orientdb> CREATE PROPERTY Employee.name STRING
如果上述查询成功执行,您将获得以下输出。
Property created successfully with id = 1
OrientDB - Alter Property 更改属性
Alter Property是用于修改或更新特定类的属性的命令。更改属性意味着修改表的字段。在本章中,您可以了解如何更新属性。
以下语句是更改属性命令的基本语法。
ALTER PROPERTY <class>.<property> <attribute-name> <attribute-value>
以下是有关上述语法中选项的详细信息。
<class> − 定义属性所属的类。
<property> −定义要更新的属性。
<attribute-name> − 定义要更新的属性的属性。
<attribute-value> − 定义要在属性上设置的值。
下表定义了用于更改属性的属性列表。
| 属性 | 类型 | 描述 |
|---|---|---|
| LINKEDCLASS | String | 定义链接类名称。使用 NULL 删除现有值。 |
| LINKEDTYPE | String | 定义链接类型。使用 NULL 删除现有值。 |
| MIN | Integer | 将最小值定义为约束。使用 NULL 删除现有约束。 |
| MANDATORY | Boolean | 定义属性是否需要值。 |
| MAX | Integer | 将最大值定义为约束。使用 NULL 删除现有约束。 |
| NAME | String | 定义属性名称。 |
| NOTNULL | Boolean | 定义属性是否可以具有 NULL 值。 |
| REGEX | String | 将正则表达式定义为约束。使用 NULL 删除现有约束。 |
| TYPE | String | 定义属性类型。 |
| COLLATE | String | 将 collate 设置为定义的比较策略之一。默认情况下,它设置为区分大小写 (cs)。您也可以将其设置为不区分大小写 (ci)。 |
| READONLY | Boolean | 定义属性值是否不可变。也就是说,是否可以在第一次赋值后更改它。与 DEFAULT 一起使用可在创建时获得不可变的值。 |
| CUSTOM | String | 定义自定义属性。自定义属性的语法为 <custom-name> = <custom-value>,例如 stereotype = icon。 |
| DEFAULT | 定义默认值或函数。 |
注意 −如果您要更改 NAME 或 TYPE,此命令将需要一些时间来更新,具体取决于数据量。
示例
尝试下面给出的一些查询以了解 Alter 属性。
执行以下查询以将 Customer 类中的属性名称从"age"更改为"born"。
orinetdb {db = demo}> ALTER PROPERTY Customer.age NAME born
如果上述查询成功执行,您将获得以下输出。
Property altered successfully
执行以下查询以将"name"作为类"Customer"的强制属性。
orientdb {db = demo}> ALTER PROPERTY Customer.name MANDATORY TRUE
如果上述查询成功执行,您将获得以下输出。
Property altered successfully
OrientDB - 删除属性
删除属性命令从架构中删除属性。它不会从记录中删除属性值,只会更改架构。
以下语句是删除属性命令的基本语法。
DROP PROPERTY <class>.<property> [FORCE]
以下是有关上述语法中选项的详细信息。
<class> − 定义属性所在的类。
<property> − 定义要删除的属性。
[Force] −如果在属性上定义了一个或多个索引。
示例
尝试以下命令从类"Customer"中删除"age"属性。
orientdb> DROP PROPERTY Customer.age
如果上述命令执行成功,您将获得以下输出。
Property dropped successfully
OrientDB - Create Vertex 创建顶点
OrientDB 数据库不仅是一个文档数据库,也是一个图形数据库。使用顶点和边等新概念以图形形式存储数据。它在顶点上应用多态性。Vertex 的基类是 V。
在本章中,您可以学习如何创建顶点来存储图形数据。
以下语句是创建顶点命令的基本语法。
CREATE VERTEX [<class>] [CLUSTER <cluster>] [SET <field> = <expression>[,]*]
以下是有关上述语法中选项的详细信息。
<class> −定义顶点所属的类。
<cluster> − 定义存储顶点的集群。
<field> − 定义要设置的字段。
<expression> − 定义要为字段设置的表达式。
示例
尝试以下示例以了解如何创建顶点。
执行以下查询以在基类 V 上创建不带"名称"的顶点。
orientdb> CREATE VERTEX
如果上述查询成功执行,您将获得以下输出。
Created vertex 'V#9:0 v1' in 0.118000 sec(s)
执行以下查询以创建一个名为 v1 的新顶点类,然后在该类中创建顶点。
orientdb> CREATE CLASS V1 EXTENDS V orientdb> CREATE VERTEX V1
如果上述查询成功执行,您将获得以下输出。
Created vertex 'V1#14:0 v1' in 0.004000 sec(s)
执行以下查询以创建名为 v1 的类的新顶点,并定义其属性,例如 brand = 'Maruti' 和 name = 'Swift'。
orientdb> CREATE VERTEX V1 SET brand = 'maruti', name = 'swift'
如果上述查询成功执行,您将获得以下输出。
Created vertex 'V1#14:1{brand:maruti,name:swift} v1' in 0.004000 sec(s)
OrientDB - Move Vertex
OrientDB 中的移动顶点命令是将一个或多个顶点从当前位置移动到不同的类或集群。如果您在特定顶点上应用移动命令,那么它将更新连接到此顶点的所有边。如果您指定集群来移动顶点,那么它会将顶点移动到目标集群的服务器所有者。
以下语句是移动顶点命令的基本语法。
MOVE VERTEX <source> TO <destination> [SET [<field>=<value>]* [,]] [MERGE <JSON>] [BATCH <batch-size>]
以下是有关上述语法中选项的详细信息。
<source> − 定义要移动的顶点。它接受特定顶点的记录 ID 或顶点的记录 ID 数组。
<destination> − 定义要将顶点移动到的位置。它支持类或集群作为目标。
SET − 将值设置为字段。
MERGE −通过 JSON 将值设置为字段。
BATCH − 定义批次大小。
注意 − 此命令更新所有连接的边,但不更新链接。使用 Graph API 时,建议使用连接到顶点的边。
示例
尝试以下示例以了解如何移动顶点。
执行以下查询以将具有记录 ID #11:2 的单个顶点从其当前位置移动到 Class Employee。
orientdb> MOVE VERTEX #11:2 TO CLASS:Employee
如果上述查询成功执行,您将获得以下输出 −
Move vertex command executed with result '[{old:#11:2, new:#13:0}]' in 0.022000 sec(s)
执行以下查询将顶点集从"Customer"类移动到"Employee"类。
orientdb> MOVE VERTEX (SELECT FROM Customer) TO CLASS:Employee
如果上述查询成功执行,您将获得以下输出。
Move vertex command executed with result '[{old:#11:0,
new:#13:1},{old:#11:1, new:#13:2},{old:#11:2, new:#13:3}]' in 0.011000 sec(s)
OrientDB - Delete Vertex
Delete Vertex命令用于从数据库中删除顶点。删除时,它会检查并维护与边的一致性,并删除对已删除顶点的所有交叉引用(与边)。
以下语句是删除顶点命令的基本语法。
DELETE VERTEX <vertex> [WHERE <conditions>] [LIMIT <MaxRecords>>] [BATCH <batch-size>]
以下是有关上述语法中选项的详细信息。
<vertex> −使用其类、记录 ID 或通过子查询定义要删除的顶点。
WHERE − 过滤条件以确定命令删除哪些记录。
LIMIT − 定义要删除的最大记录数。
BATCH − 定义命令一次删除多少条记录,允许您将大型事务分解为较小的块以节省内存使用量。
示例
尝试以下命令了解如何删除单个顶点或多个顶点。
执行以下命令删除顶点"#14:1"。
orientdb> DELETE VERTEX #14:1
如果上述命令执行成功,您将得到以下输出。
Delete record(s) '1' in 0.005000 sec(s)
执行以下命令从类"Customer"中删除所有标记为属性"isSpam"的顶点。
orientdb> DELETE VERTEX Customer WHERE isSpam = TRUE
如果上述命令执行成功,您将得到以下输出。
Delete record(s) '3' in 0.005000 sec(s)
OrientDB - Create Edge 创建边
在 OrientDB 中,边这个概念借助一些属性,就像顶点之间的关系一样。边和顶点是图形数据库的主要组成部分。它在边上应用多态性。边的基类是 E。在实现边时,如果源或目标顶点缺失或不存在,则事务将回滚。
以下语句是创建边命令的基本语法。
CREATE EDGE <class> [CLUSTER <cluster>] FROM <rid>|(<query>)|[<rid>]* TO <rid>|(<query>)|[<rid>]*
[SET <field> = <expression>[,]*]|CONTENT {<JSON>}
[RETRY <retry> [WAIT <pauseBetweenRetriesInMs]] [BATCH <batch-size>]
以下是有关上述语法中选项的详细信息。
<class> − 定义边缘的类名。
<cluster> − 定义要存储边缘的集群。
JSON − 提供要设置为记录的 JSON 内容。
RETRY − 定义发生冲突时尝试重试的次数。
WAIT − 定义重试之间的延迟时间(以毫秒为单位)。
BATCH −定义是否将命令分解为更小的块以及批次的大小。
示例
执行以下查询以在两个顶点 #9:0 和 #14:0 之间创建边 E。
orientdb> CREATE EDGE FROM #11:4 TO #13:2
如果上述查询成功执行,您将获得以下输出。
Created edge '[e[#10:0][#9:0->#14:0]]' in 0.012000 sec(s)
执行以下查询以创建新的边类型和新类型的边。
orientdb> CREATE CLASS E1 EXTENDS E orientdb> CREATE EDGE E1 FROM #10:3 TO #11:4
如果上述查询成功执行,您将获得以下输出。
Created edge '[e[#10:1][#10:3->#11:4]]' in 0.011000 sec(s)
OrientDB - UPDATE EDGE
UPDATE EDGE命令用于更新当前数据库中的边记录。如果您更新 out 和 in 属性,这相当于实际的更新命令,此外还检查和维护与顶点的图形一致性。
以下语句是更新边命令的基本语法。
UPDATE EDGE <edge> [SET|INCREMENT|ADD|REMOVE|PUT <field-name> = <field-value> [,]*]|[CONTENT|MERGE <JSON>] [RETURN <returning> [<returning-expression>]] [WHERE <conditions>] [LOCK default|record] [LIMIT <max-records>] [TIMEOUT <timeout>]
以下是有关上述语法中选项的详细信息。
<edge> − 定义要更新的边。您可以选择 Class(按类更新边)、Cluster(使用 CLUSTER 前缀按群集更新边)或 Record ID(按记录 ID 更新边)。
SET − 将字段更新为给定值。
INCREMENT − 将给定字段的值增加。
ADD − 定义要添加到字段集合的项目。
REMOVE − 定义要从字段集合中删除的项目。
PUT −定义要放入映射字段的条目。
RETURN − 定义运行更新后要返回的表达式。
WHERE − 定义过滤条件。
LOCK − 定义记录在加载和更新之间如何锁定。
LIMIT −定义最大记录数。
示例
让我们考虑一个示例,通过从区域 ID = 001 且人员名称 = Krishna 的地址表中获取数据来更新人员类中名为"address"的边。
orientdb> UPDATE EDGE address SET out = (SELECT FROM Address WHERE areaID = 001) WHERE name = 'krishna'
如果上述查询成功执行,您将获得以下输出。
Updated edge '[address[#10:3][#11:3->#14:2]]' in 0.012000 sec(s)
OrientDB - Delete Edge 删除边
Delete Edge命令用于删除数据库。这相当于删除命令,但增加了检查和维护与顶点的一致性的功能,方法是从"入"和"出"顶点属性中删除对边的所有交叉引用。
以下语句是删除边命令的基本语法。
DELETE EDGE
( <rid>
|
[<rid> (, <rid>)*]
|
( [ FROM (<rid> | <select_statement> ) ] [ TO ( <rid> | <select_statement> ) ] )
|
[<class>]
(
[WHERE <conditions>]
[LIMIT <MaxRecords>]
[BATCH <batch-size>]
))
以下是有关上述语法中选项的详细信息。
FROM − 定义要删除的边的起点顶点。
To − 定义要删除的边的终点顶点。
WHERE − 定义过滤条件。
LIMIT − 定义要删除的最大边数。
BATCH − 定义操作的块大小。
示例
尝试以下示例以了解如何删除边。
执行以下查询以删除两个顶点(#11:2、#11:10)之间的边。但两个顶点之间可能存在一条或多条边。因此我们使用日期属性来实现正确的功能。此查询将删除在"2015-01-15"及以后创建的边。
orientdb {db = demo}> DELETE EDGE FROM #11:2 TO #11:10 WHERE date >= "2012-01-15"
如果上述查询成功执行,您将获得以下输出。
Delete record(s) '2' in 0.00200 sec(s)
执行以下查询以删除从顶点'#11:5'到顶点'#11:10'并与'class = Customer'相关的边。
orientdb {db = demo}> DELETE EDGE FROM #11:5 TO #11:10 WHERE @class = 'Customer'
如果上述查询成功执行,您将获得以下输出。
Delete record(s) '2' in 0.00200 sec(s)
OrientDB - 函数
本章介绍了 OrientDB 中不同类型函数的完整参考。下表定义了按功能分类的函数列表。
图形函数
| Sr.No. | 函数名称 &描述 |
|---|---|
| 1 | Out(): 从当前记录开始获取相邻的传出顶点作为顶点。 语法 − out([<label-1>][,<label-n>]*) |
| 2 | In(): 从当前记录开始获取相邻的传入顶点作为顶点。 语法 − in([<label-1>][,<label-n>]*) |
| 3 | Both(): 从当前记录开始获取相邻的传出和传入顶点作为顶点。 语法 − both([<label1>][,<label-n>]*) |
| 4 | outE(): 从当前记录开始获取相邻的传出边作为顶点。 语法 − outE([<label1>][,<label-n>]*) |
| 5 | inE(): 从当前记录开始获取相邻的传入边作为顶点。 语法 − inE([<label1>][,<label-n>]*) |
| 6 | bothE(): 从当前记录开始获取相邻的传出和传入边作为顶点。 语法 − bothE([<label1>][,<label-n>]*) |
| 7 | outV(): 从当前记录开始获取传出的顶点作为 Edge。 语法 − outV() |
| 8 | inV(): 从当前记录开始获取传入的顶点作为 Edge。 语法 − inV() |
| 9 | traversedElement(): 返回 Traverse 命令中遍历的元素。 语法 − traversedElement(<index> [,<items>]) |
| 10 | traversedVertex(): 返回 Traverse 命令中遍历的顶点。 语法 − traversedVertex(<index> [,<items>]) |
| 11 | traversedEdge(): 返回 Traverse 命令中遍历的边。 语法 − traversedEdge(<index> [,<items>]) |
| 12 | shortestPath(): 返回两个顶点之间的最短路径。 Direction 可以是 OUT(默认)、IN 或 BOTH。 Synatx − shortestPath( <sourceVertex>, <destinationVertex> [, <direction> [, <edgeClassName>]]) |
| 13 | dijkstra(): 使用 Dijkstra 算法返回两个顶点之间的最近路径。 Syntax − dijkstra(<sourceVertex>, <destinationVertex>, <weightEdgeFieldName> [, <direction>]) |
尝试一些图形函数以及以下查询。
执行以下查询以获取所有车辆顶点的所有传出顶点。
orientdb {db = demo}>SELECT out() from Vehicle
如果上述查询成功执行,您将获得以下输出。
---+----------+--------- # | @class | out ---+----------+--------- 0 | Vehicle | #11:2 1 | Vehicle | #13:1 2 | Vehicle | #13:4 ---+----------+---------
执行以下查询以从顶点 #11:3 获取传入和传出的顶点。
orientdb {db = demo}>SELECT both() FROM #11:3
如果上述查询成功执行,您将获得以下输出。
---+----------+--------+------- # | @class | out | in ---+----------+--------+------- 0 | Vehicle | #13:2 | #10:2 ---+----------+-------+-------
数学函数
| Sr.No. | 函数名称和说明 |
|---|---|
| 1 | eval(): 计算引号(或双引号)之间的表达式。 语法 − eval('<expression>') |
| 2 | min(): 返回最小值。如果使用多个参数调用,则返回所有参数之间的最小参数值。 语法 − min(<field> [, <field-n>]* ) |
| 3 | max(): 返回最大值。如果使用多个参数调用,则返回所有参数之间的最大值。 语法 − max(<field> [, <field-n>]* ) |
| 4 | sum() 返回所有返回值的总和。 语法 − sum(<field>) |
| 5 | abs(): 返回绝对值。它适用于 Integer、Long、Short、Double、Float、BigInteger、BigDecimal、null。 语法 − abs(<field>) |
| 6 | avg(): 返回平均值。 语法 − avg(<field>) |
| 7 | count(): 统计符合查询条件的记录,若字段未使用*,则内容不为空时,记录才被统计。 语法 − count(<field>) |
| 8 | mode(): 返回出现频率最高的值。计算中会忽略空值。 语法 − mode(<field>) |
| 9 | median(): 返回中间值或表示排序后中间值的插值。计算中会忽略空值。 语法 − median(<field>) |
| 10 | percentile(): 返回第 n 个百分位数。计算时将忽略空值。 语法 − percentile(<field> [, <quantile-n>]*) |
| 11 | variance() 返回中间方差:与均值的平方差的平均值。
Syntax − variance(<field>) |
| 12 | stddev() 返回标准偏差:衡量值的分散程度。计算中忽略空值。 语法 − stddev(<field>) |
使用以下查询尝试一些数学函数。
执行以下查询以获取所有员工的工资总和。
orientdb {db = demo}>SELECT SUM(salary) FROM Employee
如果上述查询成功执行,您将获得以下输出。
---+----------+--------- # | @CLASS | sum ---+----------+--------- 0 | null | 150000 ---+----------+---------
执行以下查询以获取所有员工的平均工资。
orientdb {db = demo}>SELECT avg(salary) FROM Employee
如果上述查询成功执行,您将获得以下输出。
---+----------+--------- # | @CLASS | avg ---+----------+--------- 0 | null | 25 ---+----------+---------
集合函数
| Sr.No. | 函数名称和说明 |
|---|---|
| 1 | set(): 向集合添加一个值。如果该值是一个集合,则将其与集合合并,否则 <value>已添加。 语法 − set(<field>) |
| 2 | map(): 首次创建地图时向地图添加一个值。如果 <value> 是地图,则将其与地图合并,否则将 <key> 和 <value> 对作为新条目添加到地图中。 语法 − map(<key>, <value>) |
| 3 | ist(): 首次创建列表时,向列表添加一个值。如果 <value> 是一个集合,则将其与列表合并,否则将 <value> 添加到列表中。 语法 − list(<field>) |
| 4 | difference(): 用作聚合或内联。如果仅传递一个参数,则聚合,否则执行,并返回作为参数接收的集合之间的差异。 语法 − difference(<field> [,<field-n>]*) |
| 5 | first(): 仅检索多值字段(数组、集合和映射)的第一项。对于非多值类型,仅返回值。 语法 − first(<field>) |
| 6 | intersect(): 用作聚合或内联。如果只传递一个参数,则聚合,否则执行并返回作为参数接收的集合的交互。 语法 − intersect(<field> [,<field-n>]*) |
| 7 | distinct(): 根据您指定为参数的字段仅检索唯一数据条目。与标准 SQL DISTINCT 相比,主要区别在于,使用 OrientDB,可以指定带括号且仅一个字段的函数。 语法 − distinct(<field>) |
| 8 | expand(): 此函数有两个含义−
语法 − expand(<field>) |
| 9 | unionall(): 用作聚合或内联。如果仅传递一个参数,则聚合,否则执行并返回作为参数接收的所有集合的 UNION。也可以在没有集合值的情况下工作。 语法 − unionall(<field> [,<field-n>]*) |
| 10 | flatten(): 提取字段中的集合并将其用作结果。它已被弃用,请改用 expand()。 语法 − flatten(<field>) |
| 11 | last(): 仅检索多值字段(数组、集合和映射)的最后一项。对于非多值类型,仅返回值。 语法 − last(<field>) |
| 12 | symmetricDifference(): 用作聚合或内联。如果仅传递一个参数,则聚合,否则执行并返回作为参数接收的集合之间的对称差异。 语法 − symmetricDifference(<field> [,<field-n>]*) |
使用以下查询尝试一些集合函数。
执行以下查询以获取一组教授 9 年级的教师。
orientdb {db = demo}>SELECT ID, set(teacher.id) AS teacherID from classess where class_id = 9
如果上述查询成功执行,您将获得以下输出。
---+----------+--------+-------------------------- # | @CLASS | id | TeacherID ---+----------+--------+-------------------------- 0 | null | 9 | 1201, 1202, 1205, 1208 ---+----------+-------+---------------------------
杂项函数
| Sr.No. | 函数名称和说明 |
|---|---|
| 1 | date(): 返回格式化字符串的日期。<date-as-string> 是字符串格式的日期,<format>是遵循这些规则的日期格式。 语法 − date( <date-as-string> [<format>] [,<timezone>] ) |
| 2 | sysdate(): 返回当前日期和时间。 语法 − sysdate( [<format>] [,<timezone>] ) |
| 3 | format(): 使用 String.format() 约定格式化值。 语法 − format( <format> [,<arg1> ](,<arg-n>]*.md) |
| 4 | distance(): 使用 Haversine 算法返回地球上两点之间的距离。坐标必须为度。 语法 − distance( <x-field>, <y-field>, <x-value>, <y-value> ) |
| 5 | ifnull(): 返回传递的字段/值(或可选参数 return_value_if_not_null)。如果字段/值不为空,则返回 return_value_if_null。 语法 − ifnull(<field|value>, <return_value_if_null> [,<return_value_if_not_null>](,<field&.md#124;value>]*) |
| 6 | coalesce(): 返回第一个非空字段/值参数。如果没有非空字段/值,则返回空值。 语法 − coalesce(<field|value> [, <field-n|value-n>]*) |
| 7 | uuid(): 使用 Leach-Salz 变体生成 128 位值的 UUID。 语法 − uuid() |
| 8 | if(): 评估条件(第一个参数),如果条件为真,则返回第二个参数,否则返回第三个参数。 语法 − if(<expression>, <result-if-true>, <result-if-false>) |
使用以下查询尝试一些 Misc 函数。
执行以下查询以了解如何执行 if 表达式。
orientdb {db = demo}> SELECT if(eval("name = 'satish'"), "My name is satish",
"My name is not satish") FROM Employee
如果上述查询成功执行,您将获得以下输出。
----+--------+----------------------- # |@CLASS | IF ----+--------+----------------------- 0 |null |My name is satish 1 |null |My name is not satish 2 |null |My name is not satish 3 |null |My name is not satish 4 |null |My name is not satish ----+--------+------------------------
执行以下查询以获取系统日期。
orientdb {db = demo}> SELECT SYSDATE() FROM Employee
如果上述查询成功执行,您将获得以下输出。
----+--------+----------------------- # |@CLASS | SYSDATE ----+--------+----------------------- 0 |null |2016-02-10 12:05:06 1 |null |2016-02-10 12:05:06 2 |null |2016-02-10 12:05:06 3 |null |2016-02-10 12:05:06 4 |null |2016-02-10 12:05:06 ----+--------+------------------------
通过充分利用此功能,您可以轻松地操作OrientDB数据。
OrientDB - 序列
序列 是自动增量机制中使用的概念,它在 OrientDB v2.2 中引入。在数据库术语中,序列是一种管理计数器字段的结构。简单地说,序列主要用于需要始终递增的数字时。它支持两种类型−
ORDERED − 每次指针调用 .next 方法时都会返回一个新值。
CACHED − 序列将在每个节点上缓存"N"个项目。要调用每个项目,我们使用 .next(),当缓存包含多个项目时,这是首选。
创建序列
序列通常用于自动增加人员的 ID 值。与 OrientDB 的其他 SQL 概念一样,它也执行与 RDBMS 中的序列类似的操作。
以下语句是创建序列的基本语法。
CREATE SEQUENCE <sequence> TYPE <CACHED|ORDERED> [START <start>] [INCREMENT <increment>] [CACHE <cache>]
以下是有关上述语法中选项的详细信息。
<Sequence> − 序列的本地名称。
TYPE − 定义序列类型 ORDERED 或 CACHED。
START −定义初始值。
INCREMENT − 定义每次 .next 方法调用的增量。
CACHE −定义要预缓存的值的数量,以防您用于缓存序列类型。
让我们创建一个名为"seqid"的序列,以数字 1201 开头。尝试以下查询以使用序列实现此示例。
CREATE SEQUENCE seqid START 1201
如果上述查询成功执行,您将获得以下输出。
序列创建成功
尝试以下查询以使用序列"seqid"插入 Account 表的 id 值。
INSERT INTO Account SET id = serial('seqid').next()
如果上述查询成功执行,您将获得以下输出。
Insert 1 record(s) in 0.001000 sec(s)
Alter Sequence
Alter Sequence 是用于更改序列属性的命令。它将修改除序列类型之外的所有序列选项。
以下语句是修改序列的基本语法。
ALTER SEQUENCE <sequence> [START <start-point>] [INCREMENT <increment>] [CACHE <cache>]
以下是有关上述语法中选项的详细信息。
<Sequence> − 定义要更改的序列。
START − 定义初始值。
INCREMENT −定义每次 .next 方法调用的增量。
CACHE − 定义在您用于缓存序列类型的情况下预缓存的值的数量。
尝试以下查询以将名为 seqid 的序列的起始值从"1201 更改为 1000"。
ALTER SEQUENCE seqid START 1000
如果上述查询成功执行,您将获得以下输出。
Altered sequence successfully
Drop Sequence
Drop Sequence 是用于删除序列的命令。
以下语句是删除序列的基本语法。
DROP SEQUENCE <sequence>
其中 <Sequence> 定义要删除的序列。
尝试以下查询以删除名为"seqid"的序列。
DROP SEQUENCE seqid
如果上述查询成功执行,您将获得以下输出。
Sequence dropped successfully
OrientDB - 索引
索引是指向数据库中数据位置的指针。索引是一种用于快速定位数据而不必搜索数据库中的每条记录的概念。OrientDB 支持四种索引算法,每种算法都有几种类型。
四种类型的索引是 −
SB-Tree 索引
它提供了其他索引类型提供的良好功能组合。最好将其用于一般用途。它耐用、事务性强并支持范围查询。它是默认索引类型。支持此算法的不同类型插件是 −
UNIQUE − 这些索引不允许重复键。对于复合索引,这指的是复合键的唯一性。
NOTUNIQUE −这些索引允许重复的键。
FULLTEXT − 这些索引基于任何单个文本单词。您可以通过 CONTAINSTEXT 运算符在查询中使用它们。
DICTIONARY − 这些索引与使用 UNIQUE 的索引类似,但在重复键的情况下,它们会用新记录替换现有记录。
哈希索引
它执行速度更快,磁盘使用量非常小。它耐用、事务性强,但不支持范围查询。它的工作原理类似于 HASHMAP,这使得它在准时查找时速度更快,并且比其他索引类型消耗的资源更少。支持此算法的不同类型插件是 −
UNIQUE_HASH_INDEX −这些索引不允许重复的键。对于复合索引,这指的是复合键的唯一性。
NOTUNIQUE_HASH_INDEX − 这些索引允许重复的键。
FULLTEXT_HASH_INDEX − 这些索引基于任何单个文本单词。您可以通过 CONTAINSTEXT 运算符在查询中使用它们。
DICTIONARY_HASH_INDEX − 这些索引类似于使用 UNIQUE_HASH_INDEX 的索引,但在重复键的情况下,它们会用新记录替换现有记录。
Lucene 全文索引
它提供了良好的全文索引,但不能用于索引其他类型。它具有持久性、事务性,并支持范围查询。
Lucene 空间索引
它提供了良好的空间索引,但不能用于索引其他类型。它具有持久性、事务性,并支持范围查询。
创建索引
Create index 是在特定架构上创建索引的命令。
以下语句是创建索引的基本语法。
CREATE INDEX <name> [ON <class-name> (prop-names)] <type> [<key-type>]
[METADATA {<metadata>}]
以下是有关上述语法中选项的详细信息。
<name> −定义索引的逻辑名称。您还可以使用 <class.property> 表示法创建绑定到架构属性的自动索引。<class> 使用架构的类,而 <property> 使用在类中创建的属性。
<class-name> − 提供您正在创建自动索引以进行索引的类的名称。此类必须存在于数据库中。
<prop-names> − 提供您希望自动索引进行索引的属性列表。这些属性必须已存在于架构中。
<type> − 提供您想要创建的索引的算法和类型。
<key-type> −提供带有自动索引的可选键类型。
<metadata> − 提供 JSON 表示。
示例
尝试以下查询来创建绑定到用户 sales_user 的属性"ID"的自动索引。
orientdb> CREATE INDEX indexforID ON sales_user (id) UNIQUE
如果上述查询成功执行,您将获得以下输出。
Creating index... Index created successfully with 4 entries in 0.021000 sec(s)
查询索引
您可以使用选择查询来获取索引中的记录。
尝试以下查询来检索名为"indexforId"的索引的键。
SELECT FROM INDEX:indexforId
如果上述查询成功执行,您将获得以下输出。
----+------+----+----- # |@CLASS|key |rid ----+------+----+----- 0 |null |1 |#11:7 1 |null |2 |#11:6 2 |null |3 |#11:5 3 |null |4 |#11:8 ----+------+----+-----
删除索引
如果要删除特定索引,可以使用此命令。此操作不会删除链接记录。
以下语句是删除索引的基本语法。
DROP INDEX <name>
其中 <name> 提供要删除的索引的名称。
尝试以下查询以删除用户 sales_user 的名为"ID"的索引。
DROP INDEX sales_users.Id
如果上述查询成功执行,您将获得以下输出。
Index dropped successfully
OrientDB - 事务
与 RDBMS 一样,OrientDB 支持事务 ACID 属性。事务包括在数据库管理系统内执行的工作单元。在数据库环境中维护事务有两个主要原因。
允许并发从故障中恢复,并在系统发生故障时保持数据库的一致性。
在并发访问数据库的程序之间提供隔离。
默认情况下,数据库事务必须遵循 ACID 属性,例如原子性、一致性、隔离性和持久性属性。但 OrientDB 是一个符合 ACID 的数据库,这意味着它不会与 ACID 概念相矛盾或否定 ACID,但它在处理 NoSQL 数据库时会改变其看法。看看 ACID 属性如何与 NoSQL 数据库一起工作。
原子性 −当您执行某些操作来更改数据库时,更改应该有效或整体失败。
一致 − 数据库应保持一致。
隔离 − 如果其他事务执行同时执行,则用户将无法看到并发执行中的记录。
持久 − 如果系统崩溃(硬件或软件),数据库本身应该能够进行备份。
可以使用提交和回滚命令来实现数据库事务。
Commit
提交意味着通过保存对数据库的所有更改来关闭事务。回滚意味着将数据库状态恢复到打开事务的点。
以下语句是 COMMIT 数据库命令的基本语法。
COMMIT
注意 − 只有在连接到特定数据库并开始事务后才能使用此命令。
示例
在此示例中,我们将使用在本教程前面章节中创建的名为"demo"的同一数据库。我们将看到提交事务的操作并使用事务存储记录。
您需要首先使用以下 BEGIN 命令启动事务。
orientdb {db = demo}> BEGIN
使用以下命令将记录插入到雇员表中,其值为 id = 12 和 name = satish.P。
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')
您可以使用以下命令提交事务。
orientdb> commit
如果此事务成功提交,您将获得以下输出。
Transaction 2 has been committed in 4ms
Rollback
回滚意味着将数据库状态恢复到打开事务的点。
以下语句是 ROLLBACK 数据库命令的基本语法。
ROLLBACK
注意 − 只有在连接到特定数据库并开始事务后才能使用此命令。
示例
在此示例中,我们将使用在本教程的前面章节中创建的名为"demo"的同一数据库。我们将看到回滚事务的操作并使用事务存储记录。
您必须首先使用以下 BEGIN 命令启动事务。
orientdb {db = demo}> BEGIN
使用以下命令将记录插入到 employee 表中,其值为 id = 12 和 name = satish.P。
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')
您可以使用以下命令检索表 employee 的记录。
orientdb> SELECT FROM employee WHERE name LIKE '%.P'
如果此命令执行成功,您将获得以下输出。
---+-------+-------------------- # | ID | name ---+-------+-------------------- 0 | 12 | satish.P ---+-------+-------------------- 1 item(s) found. Query executed in 0.076 sec(s).
您可以使用以下命令回滚此事务。
orientdb> ROLLBACK
再次检查选择查询以从 Employee 表中检索相同的记录。
orientdb> SELECT FROM employee WHERE name LIKE '%.P'
如果回滚成功执行,您将在输出中找到 0 条记录。
0 item(s) found. Query executed in 0.037 sec(s).
OrientDB - Hooks
OrientDB Hooks(钩子) 只不过是数据库术语中的触发器,可在用户应用程序中的每个 CRUD 操作之前和之后启用内部事件。您可以使用钩子编写自定义验证规则、强制执行安全性或安排外部事件,例如针对关系 DBMS 进行复制。
OrientDB 支持两种钩子 −
动态钩子 − 触发器,可在类级别和/或文档级别构建。
Java(本机)钩子 −触发器,可以使用 Java 类构建。
动态钩子
动态钩子比 Java 钩子更灵活,因为它们可以在运行时更改,并且可以根据需要在每个文档中运行,但比 Java 钩子慢。
要针对文档执行钩子,首先允许您的类扩展 OTriggered 基类。然后,为感兴趣的事件定义自定义属性。以下是可用的事件。
onBeforeCreate − 在创建新文档之前调用。
onAfterCreate − 在创建新文档之后调用。
onBeforeRead −在读取文档之前调用。
onAfterRead − 在读取文档之后调用。
onBeforeUpdate − 在更新文档之前调用。
onAfterUpdate − 在更新文档之后调用。
onBeforeDelete − 在删除文档之前调用。
onAfterDelete −在删除文档后调用。
动态钩子可以调用 −
用 SQL、Javascript 或 OrientDB 和 JVM 支持的任何语言编写的函数。
Java 静态方法。
类级钩子
类级钩子是为与类相关的所有文档定义的。以下是设置针对发票文档在类级别起作用的钩子的示例。
CREATE CLASS Invoice EXTENDS OTriggered ALTER CLASS Invoice CUSTOM onAfterCreate = invoiceCreated
让我们在 Javascript 中创建函数 invoiceCreated,该函数在服务器控制台中打印创建的发票号码。
CREATE FUNCTION invoiceCreated "print('\nInvoice created: ' + doc.field ('number'));"
LANGUAGE Javascript
现在尝试通过创建新的 Invoice 文档来使用该钩子。
INSERT INTO Invoice CONTENT {number: 100, notes: 'This is a test}
如果此命令执行成功,您将获得以下输出。
Invoice created: 100
文档级钩子
您可以仅针对一个或多个文档定义特殊操作。为此,允许您的类扩展 OTriggered 类。
例如,让我们针对现有的 Profile 类执行一个触发器(作为 Javascript 函数),针对所有具有属性 account = 'Premium' 的文档。将调用该触发器以防止删除文档。
ALTER CLASS Profile SUPERCLASS OTriggered UPDATE Profile SET onBeforeDelete = 'preventDeletion' WHERE account = 'Premium'
让我们创建 preventDeletion() Javascript 函数。
CREATE FUNCTION preventDeletion "throw new java.lang.RuntimeException('Cannot
delete Premium profile ' + doc)" LANGUAGE Javascript
然后尝试删除"Premium"帐户来测试该钩子。
DELETE FROM #12:1
java.lang.RuntimeException: Cannot delete Premium profile
profile#12:1{onBeforeDelete:preventDeletion,account:Premium,name:Jill} v-1
(<Unknown source>#2) in <Unknown source> at line number 2
JAVA Hooks
OrientDB Hooks(触发器)的一个常见用例是管理任何或所有类的创建和更新日期。例如,您可以在创建记录时设置 CreatedDate 字段,并在更新记录时设置 UpdatedDate 字段,并且以一种在数据库层实现一次逻辑的方式执行此操作,而不必在应用程序层再次担心它。
在创建之前,您必须通过访问以下链接下载 orientdb-core.jar 文件 下载 OrientDB 核心。然后将这个 jar 文件复制到你想要存储 Java 源文件的文件夹中。
创建 Hook 文件
创建一个名为 HookTest.java 的 Java 文件,它将使用 Java 语言测试 Hook 机制。
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
import com.orientechnologies.orient.core.hook.ODocumentHookAbstract;
import com.orientechnologies.orient.core.hook.ORecordHook;
import com.orientechnologies.orient.core.hook.ORecordHookAbstract;
import com.orientechnologies.orient.core.db.ODatabaseLifecycleListener;
import com.orientechnologies.orient.core.db.ODatabase;
import com.orientechnologies.orient.core.record.ORecord;
import com.orientechnologies.orient.core.record.impl.ODocument;
public class HookTest extends ODocumentHookAbstract implements ORecordHook {
public HookTest() {
}
@Override
public DISTRIBUTED_EXECUTION_MODE getDistributedExecutionMode() {
return DISTRIBUTED_EXECUTION_MODE.BOTH;
}
public RESULT onRecordBeforeCreate( ODocument iDocument ) {
System.out.println("Ran create hook");
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
public RESULT onRecordBeforeUpdate( ODocument iDocument ) {
System.out.println("Ran update hook");
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}
每次创建或更新该类的记录时,上述示例代码都会打印相应的注释。
让我们再添加一个钩子文件 setCreatedUpdatedDates.java,如下所示 −
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
import com.orientechnologies.orient.core.hook.ODocumentHookAbstract;
import com.orientechnologies.orient.core.hook.ORecordHook;
import com.orientechnologies.orient.core.hook.ORecordHookAbstract;
import com.orientechnologies.orient.core.db.ODatabaseLifecycleListener;
import com.orientechnologies.orient.core.db.ODatabase;
import com.orientechnologies.orient.core.record.ORecord;
import com.orientechnologies.orient.core.record.impl.ODocument;
public class setCreatedUpdatedDates extends ODocumentHookAbstract implements ORecordHook {
public setCreatedUpdatedDates() {
}
@Override
public DISTRIBUTED_EXECUTION_MODE getDistributedExecutionMode() {
return DISTRIBUTED_EXECUTION_MODE.BOTH;
}
public RESULT onRecordBeforeCreate( ODocument iDocument ) {
if ((iDocument.getClassName().charAt(0) == 't') || (iDocument.getClassName().charAt(0)=='r')) {
iDocument.field("CreatedDate", System.currentTimeMillis() / 1000l);
iDocument.field("UpdatedDate", System.currentTimeMillis() / 1000l);
return ORecordHook.RESULT.RECORD_CHANGED;
} else {
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}
public RESULT onRecordBeforeUpdate( ODocument iDocument ) {
if ((iDocument.getClassName().charAt(0) == 't') || (iDocument.getClassName().charAt(0)=='r')) {
iDocument.field("UpdatedDate", System.currentTimeMillis() / 1000l);
return ORecordHook.RESULT.RECORD_CHANGED;
} else {
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}
}
上述代码的作用是查找以字母"r"或"t"开头的任何类,并在创建记录时设置 CreatedDate 和 UpdateDate,每次更新记录时仅设置 UpdateDate。
编译 Java Hooks
使用以下命令编译 Java 代码。注意:将下载的 jar 文件和这些 Java 文件保存到同一文件夹中。
$ jar cf hooks-1.0-SNAPSHOT.jar *.java
将编译后的代码移动到 OrientDB 服务器可以找到它的位置
您需要将完成的 .jar 文件复制到 OrientDB 服务器将查找它们的目录中。这意味着 OrientDB Server 根目录下的'./lib'文件夹将如下所示 −
$ cp hooks-1.0-SNAPSHOT.jar "$ORIENTDB_HOME/lib"
在 OrientDB Server 配置文件中启用测试钩子
编辑 $ORIENTDB_HOME/config/orientdb-server-config.xml 并在文件末尾附近添加以下部分。
<hooks>
<hook class = "HookTest" position = "REGULAR"/>
</hooks>
...
</orient-server>
重新启动 OrientDB 服务器
重新启动 OrientDB 服务器后,您在 orientdb-server-config.xml 中定义的钩子现在处于活动状态。启动 OrientDB 控制台,将其连接到您的数据库,然后运行以下命令 −
INSERT INTO V SET ID = 1;
如果此命令执行成功,您将获得以下输出。
Ran create hook
现在运行以下命令 −
UPDATE V SET ID = 2 WHERE ID = 1;
如果此命令执行成功,您将获得以下输出。
Ran update hook
在 OrientDB 服务器配置文件中启用 Real Hook
编辑 $ORIENTDB_HOME/config/orientdb-server-config.xml 并按如下方式更改 hooks 部分 −
<hooks>
<hook class="setCreatedUpdatedDates" position="REGULAR"/>
</hooks>
...
</orient-server>
重启 OrientDB 服务器
创建一个以字母'r'或't'开头的新类 −
CREATE CLASS tTest EXTENDS V;
现在插入一条记录 −
INSERT INTO tTest SET ID = 1 SELECT FROM tTest
如果此命令执行成功,您将获得以下输出。
----+-----+------+----+-----------+----------- # |@RID |@CLASS|ID |CreatedDate|UpdatedDate ----+-----+------+----+-----------+----------- 0 |#19:0|tTest |1 |1427597275 |1427597275 ----+-----+------+----+-----------+-----------
即使您没有指定要为 CreatedDate 和 UpdatedDate 设置的值,OrientDB 也会自动为您设置这些字段。
接下来,您需要使用以下命令更新记录 −
UPDATE tTest SET ID = 2 WHERE ID = 1; SELECT FROM tTest;
如果此命令执行成功,您将获得以下输出。
----+-----+------+----+-----------+----------- # |@RID |@CLASS|ID |CreatedDate|UpdatedDate ----+-----+------+----+-----------+----------- 0 |#19:0|tTest |2 |1427597275 |1427597306 ----+-----+------+----+-----------+-----------
您可以看到 OrientDB 已更改 UpdatedDate,但让 CreatedDate 保持不变。
OrientDB Java Hooks 是一种非常有价值的工具,可帮助您自动执行原本必须在应用程序代码中执行的工作。由于许多 DBA 并不总是 Java 专家,希望本教程中包含的信息能让您领先一步并让您熟悉该技术,使您能够在需要时成功创建数据库触发器。
OrientDB - 缓存
缓存是一种概念,它将创建数据库表结构的副本,为用户应用程序提供舒适的环境。OrientDB 在不同级别有几种缓存机制。
下图说明了什么是缓存。
在上图中,DB1、DB2、DB3 是应用程序中使用的三个不同的数据库实例。
1 级 缓存是本地缓存,它存储特定会话已知的所有实体。如果此会话中有三个事务,它将保存所有三个事务使用的所有实体。当您关闭会话或执行"清除"方法时,此缓存将被清除。它减少了应用程序和数据库之间的 I/O 操作负担,从而提高了性能。
二级缓存是使用第三方提供商工作的真实缓存。您可以完全控制缓存的内容,即您可以指定应删除哪些条目,应将哪些条目存储更长时间等等。它是多个线程之间的完全共享缓存。
存储模型不过是磁盘、内存或远程服务器等存储设备。
OrientDB 中的缓存如何工作?
OrientDB 缓存在不同的环境中提供不同的方法。缓存主要用于加快数据库事务,减少事务的处理时间并提高性能。以下流程图显示了缓存在本地模式和客户端-服务器模式下的工作方式。
本地模式(嵌入式数据库)
以下流程图告诉您在本地模式下,即当您的数据库服务器位于本地主机时,记录在存储和使用的应用程序之间是如何流动的。
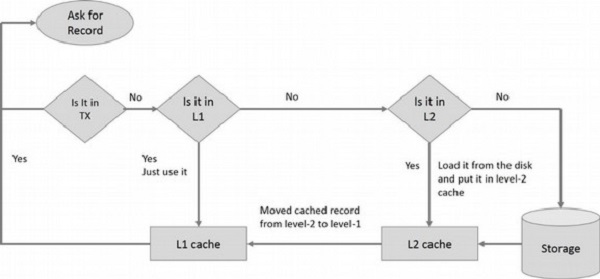
当客户端应用程序请求记录时,OrientDB 会检查以下 −
如果事务已经开始,则它会在事务内部搜索已更改的记录,如果找到则返回。
如果本地缓存已启用并包含请求的记录,则返回它。
如果此时记录不在缓存中,则请求将其发送到存储(磁盘,内存)。
客户端服务器模式(远程数据库)
以下流程图告诉您在客户端-服务器模式下,即当您的数据库服务器位于远程位置时,记录如何在存储和使用的应用程序之间流动。
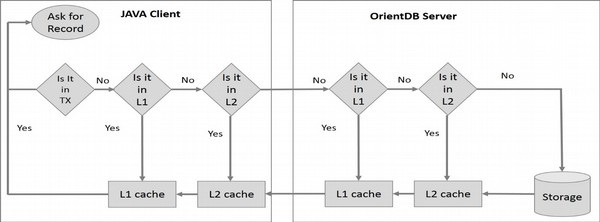
当客户端应用程序请求记录时,OrientDB 会检查以下 −
如果事务已经开始,则它会在事务内部搜索已更改的记录,如果找到则返回。
如果本地缓存已启用并包含请求的记录,则返回它。
此时,如果记录不在缓存中,则通过 TCP/IP 向服务器请求它调用。
在服务器中,如果本地缓存已启用且包含所请求的记录,则返回该记录。
此时,记录仍未缓存在服务器中,则请求将其发送到存储(磁盘、内存)。
OrientDB - 日志记录
OrientDB 使用与 Java 虚拟机捆绑在一起的 Java 日志记录框架。OrientDB 的默认日志格式由 OLogFormatter 类管理。
以下语句是日志记录命令的基本语法。
<date> <level> <message> [<requester>]
以下是有关上述语法中选项的详细信息。
<date> − 它是以下格式的日志日期:yyyy-MM-dd HH:mm:ss:SSS。
<level> −这是 5 个字符输出的日志记录级别。
<message> − 这是日志的文本,可以是任意大小。
[<class>] − 这是记录的 Java 类(可选)。
支持的级别是 JRE 类 java.util.logging.Level 中包含的级别。它们是 −
- SEVERE(最高值)
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST(最低值)
默认情况下,安装了两个记录器 −
Console,作为启动应用程序/服务器的 shell/命令提示符的输出。可以通过设置变量"log.console.level"进行更改。
File,作为日志文件的输出。可以通过设置'log.file.level'进行更改。
配置日志记录
可以使用遵循 Java 的文件配置日志记录策略和策略。
语法 − Java 日志记录配置。
示例
从 orientdb-server-log.properties 文件中复制以下内容并将其放入 $ORIENTDB_HOME/config 文件中。
# 指定要在根记录器中创建的处理程序 #(所有记录器都是根记录器的子级) # 以下创建两个处理程序 handlers = java.util.logging.ConsoleHandler, java.util.logging.FileHandler # 设置根记录器的默认日志记录级别 .level = ALL # 设置新 ConsoleHandler 实例的默认日志记录级别 java.util.logging.ConsoleHandler.level = INFO # 设置新 ConsoleHandler 实例的默认格式化程序 java.util.logging.ConsoleHandler.formatter = com.orientechnologies.common.log.OLogFormatter # 设置新 FileHandler 实例的默认日志记录级别 java.util.logging.FileHandler.level = INFO # 输出文件的命名样式 java.util.logging.FileHandler.pattern =../log/orient-server.log # 设置新FileHandler 实例 java.util.logging.FileHandler.formatter = com.orientechnologies.common.log.OLogFormatter # 限制输出文件的大小(以字节为单位): java.util.logging.FileHandler.limit = 10000000 # 通过在基本文件名后附加一个整数来循环输出文件的数量: java.util.logging.FileHandler.count = 10
要告诉 JVM 属性文件放在哪里,您需要为其设置"java.util.logging.config.file"系统属性。例如,使用以下命令 −
$ java -Djava.util.logging.config.file=mylog.properties ...
设置日志记录级别
要更改日志记录级别而不修改日志记录配置,只需将"log.console.level"和"log.file.level"系统变量设置为请求的级别。
启动时记录
以下是以不同方式设置启动级别日志记录的过程。
在服务器配置中
打开文件 orientdb-server-config.xml 并在文件末尾的 <properties> 内添加或更新这些行部分 −
<entry value = "fine" name = "log.console.level" /> <entry value = "fine" name = "log.file.level" />
在 Server.sh(或 .bat)脚本中
使用 java 的 -D 参数将系统属性"log.console.level"和"log.file.level"设置为所需的级别。
$ java -Dlog.console.level = FINE ...
运行时日志记录
以下是以不同方式在启动级别设置日志记录的过程。
通过使用 Java 代码
可以使用 System.setProperty() API 在启动时设置系统变量。以下代码片段是使用 Java 代码设置日志记录级别的语法。
public void main(String[] args){
System.setProperty("log.console.level", "FINE");
...
}
在远程服务器上
针对 URL 执行 HTTP POST:/server/log.<type>/<level>,其中 −
- <type> 可以是"console"或"file"
- <level> 是受支持的级别之一
示例
以下示例使用 cURL 针对 OrientDB 服务器执行 HTTP POST 命令。使用了服务器的"root"用户和密码,请将其替换为您自己的密码。
启用对控制台的最精细跟踪级别 −
curl -u root:root -X POST http://localhost:2480/server/log.console/FINEST
启用对文件的最精细跟踪级别 −
curl -u root:root -X POST http://localhost:2480/server/log.file/FINEST
OrientDB - 性能调优
在本章中,您可以获得一些关于如何优化使用 OrientDB 的应用程序的一般技巧。有三种方法可以提高不同类型数据库的性能。
文档数据库性能调优 − 它使用一种有助于避免为每个新文档创建文档的技术。
对象数据库性能调优 − 它使用通用技术来提高性能。
分布式配置调优 −它使用不同的方法来提高分布式配置中的性能。
您可以通过更改内存、JVM 和远程连接设置来实现通用性能调整。
内存设置
内存设置中有不同的策略来提高性能。
服务器和嵌入式设置
这些设置对服务器组件和 JVM 均有效,其中 Java 应用程序使用 OrientDB 在嵌入式模式下运行,直接使用 plocal。
调整时最重要的是确保内存设置正确。真正能产生影响的是内存映射所使用的堆和虚拟内存之间的正确平衡,尤其是在大型数据集(GB、TB 等)上,其中内存缓存结构的数量少于原始 IO。
例如,如果您可以为 Java 进程分配最大 8GB,通常最好分配较小的堆和较大的磁盘缓存缓冲区(堆外内存)。
尝试以下命令来增加堆内存。
java -Xmx800m -Dstorage.diskCache.bufferSize=7200 ...
storage.diskCache.bufferSize 设置(对于旧的"本地"存储,它是 file.mmap.maxMemory)以 MB 为单位,并指示磁盘缓存组件要使用多少内存。默认情况下,它是 4GB。
注意 − 如果最大堆和磁盘缓存缓冲区的总和太高,可能会导致操作系统交换并大幅减速。
JVM 设置
JVM 设置编码在 server.sh(和 server.bat)批处理文件中。您可以更改它们以根据您的使用情况和硬件/软件设置调整 JVM。在 server.bat 文件中添加以下行。
-server -XX:+PerfDisableSharedMem
此设置将禁用写入有关 JVM 的调试信息。如果您需要分析 JVM,只需删除此设置即可。
远程连接
使用远程连接访问数据库时,有很多方法可以提高性能。
获取策略
使用远程数据库时,您必须注意使用的获取策略。默认情况下,OrientDB 客户端仅加载结果集中包含的记录。例如,如果查询返回 100 个元素,但如果您从客户端越过这些元素,则 OrientDB 客户端会延迟加载元素,并为每个错过的记录向服务器再进行一次网络调用。
网络连接池
默认情况下,每个客户端仅使用一个网络连接与服务器通信。同一客户端上的多个线程共享同一个网络连接池。
当您有多个线程时,可能会出现瓶颈,因为需要花费大量时间等待空闲的网络连接。这就是配置网络连接池如此重要的原因。
配置非常简单,只有2个参数 −
minPool − 是连接池的初始大小。默认值配置为全局参数"client.channel.minPool"。
maxPool − 是连接池可以达到的最大大小。默认值配置为全局参数"client.channel.maxPool"。
如果所有池连接都处于繁忙状态,则客户端线程将等待第一个空闲连接。
使用数据库属性进行配置的示例命令。
database = new ODatabaseDocumentTx("remote:localhost/demo");
database.setProperty("minPool", 2);
database.setProperty("maxPool", 5);
database.open("admin", "admin");
分布式配置调优
有很多方法可以提高分布式配置的性能。
使用事务
即使更新图表,也应该始终在事务中工作。OrientDB 允许您在事务之外工作。常见情况是只读查询或大规模非并发操作,在发生故障时可以恢复。在分布式配置上运行时,使用事务有助于减少延迟。这是因为分布式操作仅在提交时发生。由于延迟,分发一个大操作比传输多个小操作效率更高。
复制与分片
OrientDB 分布式配置设置为完全复制。拥有具有相同数据库副本的多个节点对于扩展读取非常重要。事实上,每个服务器在执行读取和查询时都是独立的。如果您有 10 个服务器节点,则读取吞吐量是 10 倍。
对于写入,情况正好相反:如果复制是同步的,则具有完全复制的多个节点会减慢操作速度。在这种情况下,跨多个节点分片数据库允许您扩展写入,因为写入时只涉及节点的子集。此外,您可以拥有一个大于一个服务器节点 HD 的数据库。
扩展写入
如果您的网络速度较慢并且您有同步(默认)复制,则可能需要付出延迟成本。事实上,当 OrientDB 同步运行时,它至少会等待 writeQuorum。这意味着,如果 writeQuorum 为 3,并且您有 5 个节点,则协调器服务器节点(启动分布式操作的地方)必须等待至少 3 个节点的答案才能向客户端提供答案。
为了保持一致性,应将 writeQuorum 设置为多数。如果您有 5 个节点,多数是 3。如果有 4 个节点,它仍然是 3。将 writeQuorum 设置为 3 而不是 4 或 5 可以减少延迟成本并保持一致性。
异步复制
为了加快速度,您可以设置异步复制以消除延迟瓶颈。在这种情况下,协调器服务器节点在本地执行操作并将答案提供给客户端。整个复制将在后台进行。如果未达到法定人数,更改将透明地回滚。
扩大读取量
如果您已将 writeQuorum 设置为大多数节点,则可以将 readQuorum 保留为 1(默认值)。这样可以加快所有读取速度。
OrientDB - 升级
升级时,您必须考虑版本号和格式。有三种格式 - MAJOR、MINOR、PATCH。
MAJOR 版本包含不兼容的 API 更改。
MINOR 版本以向后兼容的方式包含功能。
PTCH 版本包含向后兼容的错误修复。
要在次要版本和主要版本之间同步,您可能需要导出和导入数据库。有时您可能需要将数据库从 LOCAL 迁移到 PLOCAL,并且需要将图表迁移到 RidBag。
从 LOCAL 存储引擎迁移到 PLOCAL
从 1.5.x 版本开始,OrientDB 配备了一个全新的存储引擎:PLOCAL(分页 LOCAL)。它像 LOCAL 一样具有持久性,但以不同的方式存储信息。以下几点显示了 PLOCAL 和 LOCAL − 之间的比较
在 PLOCAL 中,记录存储在集群文件中,而在 LOCAL 中,记录被拆分为集群和数据段。
由于采用附加写入模式,PLOCAL 比 LOCAL 更耐用。
PLOCAL 在写入时有较小的争用锁,这意味着更多的并发性。
PLOCAL 不使用内存映射技术 (MMap),因此行为更"可预测"。
要将您的 LOCAL 存储迁移到新的 PLOCAL,您需要使用 PLOCAL 作为存储引擎导出并重新导入数据库。以下是程序。
步骤 1 −打开一个新的 shell (Linux/Mac) 或命令提示符 (Windows)。
第 2 步 − 使用控制台导出数据库。按照给定的命令将数据库演示导出到 demo.json.gzip 文件中。
$ bin/console.sh (or bin/console.bat under Windows) orientdb> CONNECT DATABASE local:/temp/demo admin admin orientdb> EXPORT DATABASE /temp/demo.json.gzip orientdb> DISCONNECT−
orientdb> CREATE DATABASE plocal:/temp/newdb admin admin plocal graph
步骤 4 − 将旧数据库导入新数据库。
orientdb> IMPORT DATABASE /temp/demo.json.gzip -preserveClusterIDs=true orientdb> QUIT
如果您在同一个 JVM 中访问数据库,请记住将 URL 从"local:"更改为"plocal:"
将 Graph 迁移到 RidBag
从 OrientDB 1.7 开始,RidBag 是管理图形中邻接关系的默认集合。虽然由 MVRB-Tree 管理的旧数据库完全兼容,但您可以将数据库更新为较新的格式。
您可以通过控制台或使用 ORidBagMigration 类升级您的图形。
连接到数据库 CONNECT plocal:databases/<graphdb-name>
运行升级图形命令
OrientDB - 安全性
与 RDBMS 一样,OrientDB 也基于众所周知的概念、用户和角色提供安全性。每个数据库都有自己的用户,每个用户都有一个或多个角色。角色是工作模式和权限集的组合。
用户
默认情况下,OrientDB 为服务器中的所有数据库维护三个不同的用户 −
管理员 − 此用户可以无限制地访问数据库上的所有功能。
读者 − 此用户是只读用户。读者可以查询数据库中的任何记录,但不能修改或删除它们。它无权访问内部信息,例如用户和角色本身。
写者 −此用户与用户读取者相同,但也可以创建、更新和删除记录。
使用用户
连接到数据库后,可以使用 OUser 类上的 SELECT 查询来查询数据库中的当前用户。
orientdb> SELECT RID, name, status FROM OUser
如果上述查询成功执行,您将获得以下输出。
---+--------+--------+-------- # | @CLASS | name | status ---+--------+--------+-------- 0 | null | admin | ACTIVE 1 | null | reader | ACTIVE 2 | null | writer | ACTIVE ---+--------+--------+-------- 3 item(s) found. Query executed in 0.005 sec(s).
创建新用户
要创建新用户,请使用 INSERT 命令。请记住,在执行此操作时,您必须将状态设置为 ACTIVE 并为其赋予有效角色。
orientdb> INSERT INTO OUser SET
name = 'jay',
password = 'JaY',
status = 'ACTIVE',
roles = (SELECT FROM ORole WHERE name = 'reader')
更新用户
您可以使用 UPDATE 语句更改用户的名称。
orientdb> UPDATE OUser SET name = 'jay' WHERE name = 'reader'
以同样的方式,您也可以更改用户的密码。
orientdb> UPDATE OUser SET password = 'hello' WHERE name = 'reader'
OrientDB 以哈希格式保存密码。触发器 OUserTrigger 在保存记录之前透明地加密密码。
禁用用户
要禁用用户,请使用 UPDATE 将其状态从 ACTIVE 切换为 SUSPENDED。例如,如果您想要禁用除管理员之外的所有用户,请使用以下命令 −
orientdb> UPDATE OUser SET status = 'SUSPENDED' WHERE name <> 'admin'
角色
角色决定用户可以对资源执行哪些操作。主要地,这个决定取决于工作模式和规则。规则本身的工作方式不同,具体取决于工作模式。
使用角色
连接到数据库时,可以使用 ORole 类上的 SELECT 查询来查询数据库上的当前角色。
orientdb> SELECT RID, mode, name, rules FROM ORole
如果上述查询成功执行,您将获得以下输出。
--+------+----+--------+-------------------------------------------------------
# |@CLASS|mode| name | rules
--+------+----+--------+-------------------------------------------------------
0 | null | 1 | admin | {database.bypassRestricted = 15}
1 | null | 0 | reader | {database.cluster.internal = 2, database.cluster.orole = 0...
2 | null | 0 | writer | {database.cluster.internal = 2, database.cluster.orole = 0...
--+------+----+--------+-------------------------------------------------------
3 item(s) found. Query executed in 0.002 sec(s).
创建新角色
要创建新角色,请使用 INSERT 语句。
orientdb> INSERT INTO ORole SET name = 'developer', mode = 0
使用模式
规则决定属于某些角色的用户可以对数据库执行的操作,而工作模式决定 OrientDB 如何解释这些规则。有两种类型的工作模式,分别用 1 和 0 表示。
允许所有但(规则) − 默认情况下,它是超级用户模式。使用规则指定例外情况。如果 OrientDB 未找到请求资源的规则,则允许用户执行操作。此模式主要供高级用户和管理员使用。默认角色 admin 默认使用此模式,没有例外规则。它在数据库中写为 1。
拒绝所有但(规则) − 默认情况下,此模式不允许任何内容。使用规则指定例外情况。如果 OrientDB 找到请求资源的规则,则允许用户执行操作。将此模式用作所有经典用户的默认模式。默认角色 reader 和 writer 使用此模式。它在数据库中写为 0。
OrientDB - Studio
OrientDB 提供了一个 Web UI,可通过 GUI 执行数据库操作。本章介绍 OrientDB 中可用的不同选项。
Studio 主页
Studio 是 OrientDB 管理的 Web 界面,与 OrientDB 发行版捆绑在一起。
首先,您需要使用以下命令启动 OrientDB 服务器。
$ server.sh
如果您在机器中运行 OrientDB,则可以通过 URL − 访问 Web 界面。
http://localhost:2480
如果命令执行成功,屏幕上将显示以下输出。
连接到现有数据库
要登录,请从数据库列表中选择一个数据库并使用任何数据库用户。默认情况下(用户名/密码)reader/reader 可以从数据库中读取记录,writer/writer 可以读取、创建、更新和删除记录,而 admin/admin 拥有所有权限。
删除现有数据库
从数据库列表中选择一个数据库并单击垃圾图标。Studio 将打开一个确认弹出窗口,您必须在其中插入服务器用户和服务器密码。
然后单击"删除数据库"按钮。您可以在 $ORIENTDB_HOME/config/orientdb-server-config.xml 文件中找到服务器凭据。
<users> <user name = "root" password = "pwd" resources = "*" /> </users>
创建新数据库
要创建新数据库,请单击主页上的"新建数据库"按钮。
创建新数据库需要以下信息 −
- 数据库名称
- 数据库类型(文档/图形)
- 存储类型(plocal/memory)
- 服务器用户
- 服务器密码
您可以在 $ORIENTDB_HOME/config/orientdbserver-config.xml 文件中找到服务器凭据。
<users> <user name = "root" password = "pwd" resources = "*" /> </users>
创建后,Studio 将自动登录到新数据库。
执行查询
Studio 支持自动识别您使用的语言:SQL 和 Gremlin。编写时,按 Ctrl + Space 使用自动完成功能。
查询编辑器中提供以下快捷键 −
Ctrl + Return − 执行查询或只需单击 Run 按钮。
Ctrl/Cmd + Z − 撤消更改。
Ctrl/Cmd + Shift + Z − 重做更改。
Ctrl/Cmd + F −在编辑器中搜索。
Ctrl/Cmd + / − 切换注释。
以下屏幕截图显示了如何执行查询。
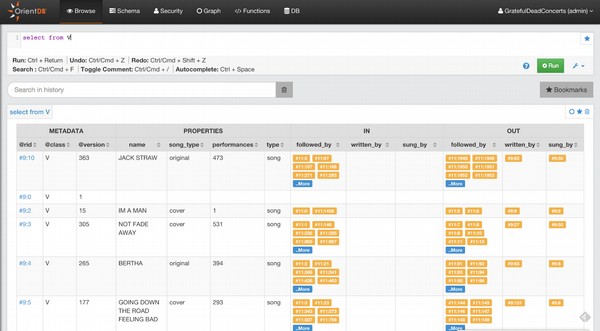
通过单击结果集中的任何 @rid 值,如果记录是文档,您将进入文档编辑模式,否则您将进入顶点编辑。
您可以通过单击结果集或编辑器中的星形图标来为查询添加书签。要浏览已加书签的查询,请单击书签按钮。 Studio 将在左侧打开书签列表,您可以在其中编辑/删除或重新运行查询。
Studio 将执行的查询保存在浏览器的本地存储中。在查询设置中,您可以配置 Studio 将在历史记录中保留多少个查询。您还可以搜索以前执行的查询、从历史记录中删除所有查询或删除单个查询。
编辑顶点
要编辑图形的顶点,请转到"图形"部分。然后运行以下查询。
Select From Customer
成功运行查询后,以下是输出屏幕截图。选择图形画布中的特定顶点进行编辑。
选择特定顶点上的编辑符号。您将看到以下屏幕,其中包含编辑顶点的选项。
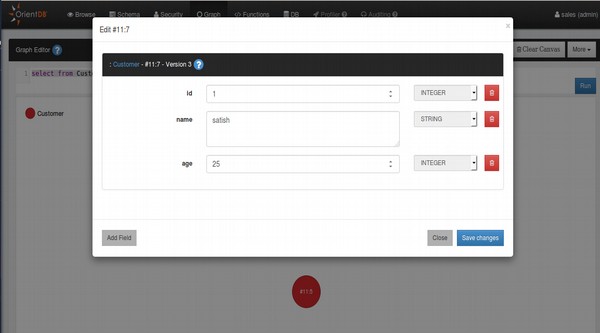
模式管理器
OrientDB 可以在无模式模式、模式模式或两者混合模式下工作。这里我们将讨论模式模式。单击 Web UI 顶部的模式部分。您将获得以下屏幕截图。
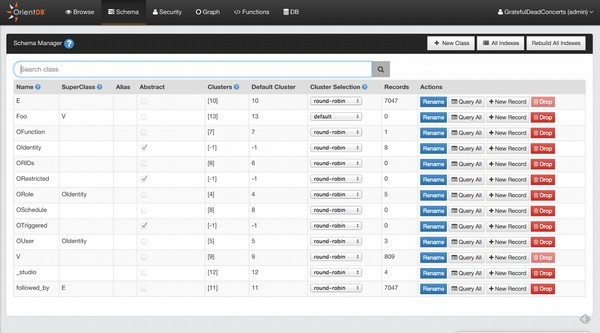
创建新类
要创建新类,只需单击新建类按钮。将出现以下屏幕截图。您必须提供屏幕截图中显示的以下信息才能创建新类。
查看所有索引
当您想要概览数据库中创建的所有索引时,只需单击 Schema UI 中的所有索引按钮。这将提供对有关索引的一些信息的快速访问(名称、类型、属性等),您可以从这里删除或重建它们。
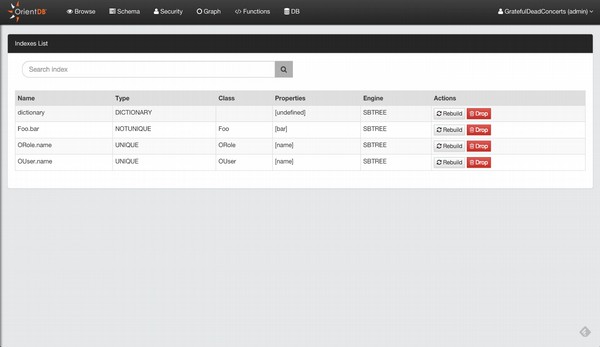
编辑类
单击架构部分上的任何类,您将获得以下屏幕截图。
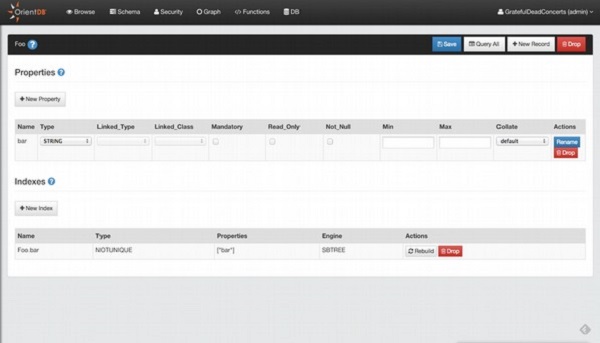
在编辑类时,您可以添加属性或添加新索引。
添加属性
单击新属性按钮以添加属性。您将获得以下屏幕截图。
您必须提供屏幕截图中所示的以下详细信息才能添加属性。
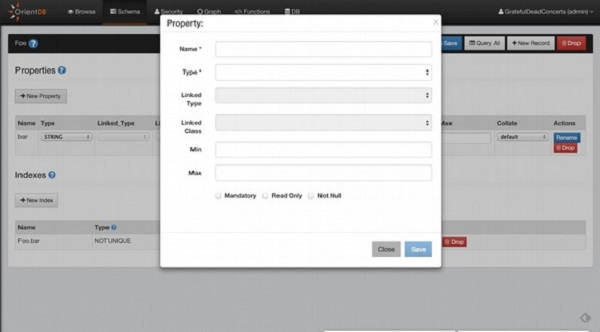
添加索引
单击"新建索引"按钮。您将获得以下屏幕截图。您必须提供屏幕截图中所示的以下详细信息才能添加索引。
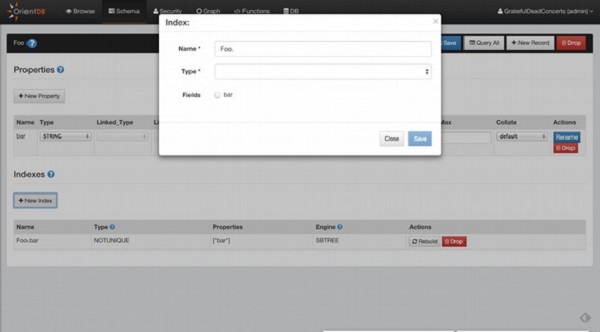
图表编辑器
单击图表部分。您不仅可以以图表样式可视化数据,还可以与图表交互并对其进行修改。
要填充图表区域,请在查询编辑器中键入查询或使用浏览 UI 中的"发送到图表"功能。
添加顶点
要在图形数据库和图形画布区域中添加新顶点,您必须按下按钮添加顶点。此操作分两步完成。
在第一步中,您必须为新顶点选择类,然后单击下一步。
在第二步中,您必须插入新顶点的字段值。您还可以添加自定义字段,因为 OrientDB 支持无模式。要使新顶点持久化,请单击"保存更改",顶点将保存到数据库中并添加到画布区域。
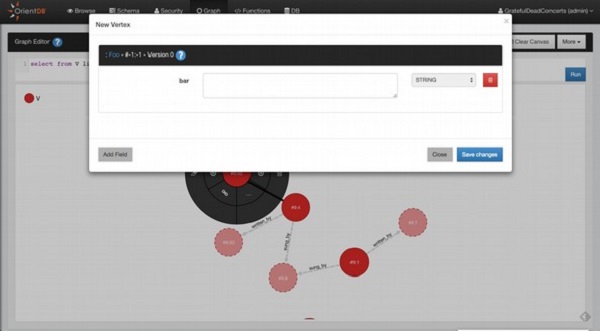
删除顶点
单击要删除的顶点打开圆形菜单。将鼠标悬停在菜单项"更多 (...)"上,然后单击垃圾图标,打开子菜单。
从画布中删除顶点
打开圆形菜单,将鼠标悬停在菜单项"更多 (...)"上,然后单击橡皮擦图标,打开子菜单。
检查顶点
如果要快速查看顶点属性,请单击眼睛图标。
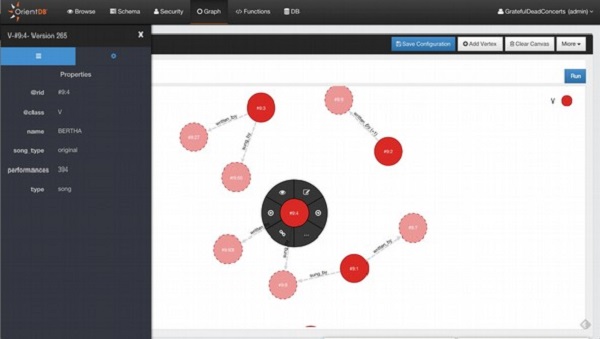
安全
Studio 2.0 包含新的安全管理,您可以在其中以图形方式管理用户和角色。
用户
您可以执行以下操作来管理数据库用户 −
- 搜索用户
- 添加用户
- 删除用户
- 编辑用户:角色可以在线编辑,对于名称、状态和密码,请单击编辑按钮
添加用户
要添加新用户,请单击添加用户按钮,填写新用户的信息(名称、密码、状态、角色),然后保存以将新用户添加到数据库。
角色
您可以执行以下操作来管理数据库角色 −
- 搜索角色
- 添加角色
- 删除角色
- 编辑角色
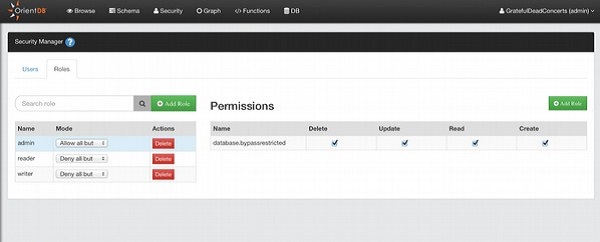
添加角色
要添加新用户,请单击添加角色按钮,填写新角色的信息(名称、父角色、模式),然后保存以将新角色添加到数据库。
向角色添加规则
要为所选角色添加新安全规则,请单击添加规则按钮。这将询问您要保护的资源的字符串。然后,您可以对新创建的资源配置 CRUD 权限。
OrientDB - Java 接口
与 RDBMS 类似,OrientDB 支持 JDBC。为此,我们首先需要配置 JDBC 编程环境。以下是在应用程序和数据库之间创建连接的过程。
首先,我们需要下载 JDBC 驱动程序。访问以下链接 https://code.google.com/archive/p/orient/downloads 下载 OrientDB-JDBC。
以下是实现 OrientDB-jdbc 连接的基本五个步骤。
- 加载 JDBC 驱动程序
- 创建连接
- 创建语句
- 执行语句
- 关闭连接
示例
尝试以下示例以了解 OrientDB-JDBC 连接。假设我们有一个员工表,其中包含以下字段及其类型。
| Sr.No. | 字段名称 | 类型 |
|---|---|---|
| 1 | Id | Integer |
| 2 | Name | String |
| 3 | Salary | Integer |
| 4 | Join date | Date |
您可以通过执行以下命令来创建 Schema(表)。
CREATE DATABASE PLOCAL:/opt/orientdb/databases/testdb CREATE CLASS Employee CREATE PROPERTY Customer.id integer CREATE PROPERTY Customer.name String CREATE PROPERTY Customer.salary integer CREATE PROPERTY Customer.join_date date
执行完所有命令后,您将获得包含以下字段的 Employee 表,员工姓名(带 id)、年龄和 join_date 字段。
将以下代码保存到 OrientJdbcDemo.java 文件中。
import com.orientechnologies.common.log.OLogManager;
import com.orientechnologies.orient.core.db.document.ODatabaseDocumentTx;
import org.junit.After;
import org.junit.Before;
import org.junit.BeforeClass;
import java.io.File;
import java.sql.DriverManager;
import java.util.Properties;
import static com.orientechnologies.orient.jdbc.OrientDbCreationHelper.createSchemaDB;
import static com.orientechnologies.orient.jdbc.OrientDbCreationHelper.loadDB;
import static java.lang.Class.forName;
public abstract class OrientJdbcDemo {
protected OrientJdbcConnection conn;
public static void main(String ar[]){
//load Driver
forName(OrientJdbcDriver.class.getName());
String dbUrl = "memory:testdb";
ODatabaseDocumentTx db = new ODatabaseDocumentTx(dbUrl);
String username = "admin";
String password = "admin";
createSchemaDB(db);
loadDB(db, 20);
dbtx.create();
//Create Connection
Properties info = new Properties();
info.put("user", username);
info.put("password", password);
conn = (OrientJdbcConnection) DriverManager.getConnection("jdbc:orient:" + dbUrl, info);
//create and execute statement
Statement stmt = conn.createStatement();
int updated = stmt.executeUpdate("INSERT into emplyoee
(intKey, text, salary, date) values ('001','satish','25000','"
+ date.toString() + "')");
int updated = stmt.executeUpdate("INSERT into emplyoee
(intKey, text, salary, date) values ('002','krishna','25000','"
+ date.toString() + "')");
System.out.println("Records successfully inserted");
//Close Connection
if (conn != null && !conn.isClosed())
conn.close();
}
}
以下命令用于编译上述程序。
$ javac –classpath:.:orientdb-jdbc-1.0-SNAPSHOT.jar OrientJdbcDemo.java $ java –classpath:.:orientdb-jdbc-1.0-SNAPSHOT.jar OrientJdbcDemo
如果上述命令执行成功,您将得到以下输出。
Records Successfully Inserted
OrientDB - Python 接口
OrientDB Python 驱动程序使用二进制协议。PyOrient 是 git hub 项目名称,可帮助将 OrientDB 与 Python 连接起来。它适用于 OrientDB 1.7 版及更高版本。
以下命令用于安装 PyOrient。
pip install pyorient
您可以使用名为 demo.py 的脚本文件执行以下任务 −
创建客户端实例意味着创建连接。
创建名为 DB_Demo 的数据库。
打开名为 DB_Demo 的数据库。
创建类 my_class。
创建属性 id 和 name。
将记录插入我的类。
//创建连接
client = pyorient.OrientDB("localhost", 2424)
session_id = client.connect( "admin", "admin" )
//创建数据库
client.db_create( db_name, pyorient.DB_TYPE_GRAPH, pyorient.STORAGE_TYPE_MEMORY )
//打开数据库
client.db_open( DB_Demo, "admin", "admin" )
//创建类
cluster_id = client.command( "create class my_class extends V" )
//创建属性
cluster_id = client.command( "create property my_class.id Integer" )
cluster_id = client.command( "create property my_class.name String" )
//插入记录
client.command("insert into my_class ( 'id',''name' ) values( 1201, 'satish')")
使用以下命令执行上述脚本。
$ python demo.py


