H2O - 安装
H2O 可以配置并使用以下五种不同的选项 −
使用 Python 安装
使用 R 安装
基于 Web 的 Flow GUI
Hadoop
Anaconda Cloud
在我们后续的部分中,您将看到基于可用选项的 H2O 安装说明。您可能会使用其中一个选项。
使用 Python 安装
要使用 Python 运行 H2O,安装需要几个依赖项。因此,让我们开始安装运行 H2O 所需的最小依赖项集。
安装依赖项
要安装依赖项,请执行以下 pip 命令 −
$ pip install request
打开控制台窗口并输入上述命令以安装请求包。以下屏幕截图显示了在我们的 Mac 机器上执行上述命令的情况 −
安装请求后,您需要再安装三个包,如下所示 −
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
最新的依赖项列表可在 H2O GitHub 页面上找到。在撰写本文时,页面上列出了以下依赖项。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
删除旧版本
安装上述依赖项后,您需要删除任何现有的 H2O 安装。为此,请运行以下命令 −
$ pip uninstall h2o
安装最新版本
现在,让我们使用以下命令安装最新版本的 H2O −
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
安装成功后,您应该会在屏幕上看到以下消息 −
正在安装收集的软件包:h2o 已成功安装 h2o-3.26.0.1
测试安装
为了测试安装,我们将运行 H2O 安装中提供的示例应用程序之一。首先通过输入以下命令启动 Python 提示符 −
$ Python3
Python 解释器启动后,在 Python 命令提示符上输入以下 Python 语句 −
>>>import h2o
上述命令将 H2O 包导入到您的程序中。接下来,使用以下命令初始化 H2O 系统 −
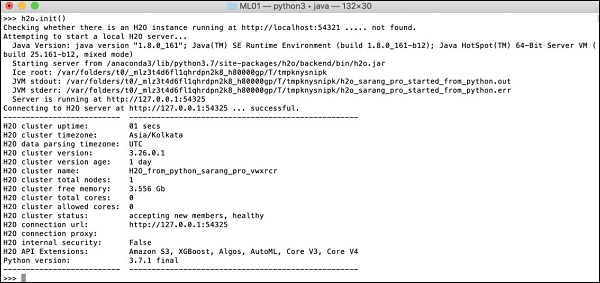
>>>h2o.init()
您的屏幕将显示集群信息,此时应如下所示 −
现在,您可以运行示例代码了。在 Python 提示符下输入以下命令并执行。
>>>h2o.demo("glm")
演示由一个包含一系列命令的 Python 笔记本组成。执行每个命令后,其输出会立即显示在屏幕上,并要求您按下 键继续下一步。执行笔记本中最后一条语句的部分屏幕截图显示在此处 −
此时,您的 Python 安装已完成,您可以开始自己的实验了。
在 R 中安装
为 R 开发安装 H2O 与为 Python 安装非常相似,只是您将使用 R 提示符进行安装。
启动 R 控制台
通过单击计算机上的 R 应用程序图标来启动 R 控制台。控制台屏幕将如以下屏幕截图所示 −
您的 H2O 安装将在上面的 R 提示符上完成。如果您更喜欢使用 RStudio,请在 R 控制台子窗口中键入命令。
删除旧版本
首先,使用 R 提示符上的以下命令删除旧版本 −
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
下载依赖项
使用以下代码下载 H2O 的依赖项 −
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
安装 H2O
通过在 R 提示符下输入以下命令来安装 H2O −
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
以下屏幕截图显示预期输出 −
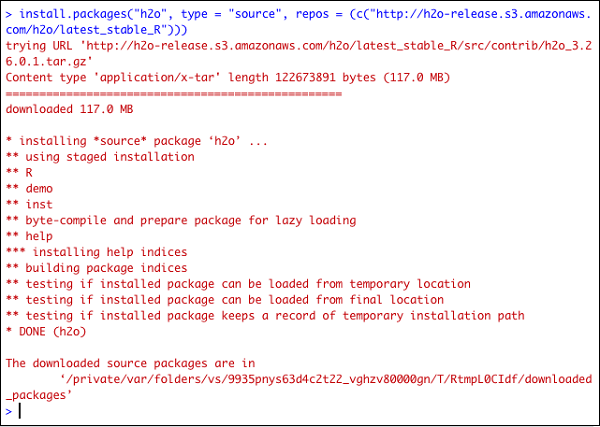
还有另一种在 R 中安装 H2O 的方法。
从 CRAN 在 R 中安装
要从 CRAN 安装 R,请在 R 提示符下使用以下命令 −
> install.packages("h2o")
系统将要求您选择镜像 −
--- 请选择用于此会话的 CRAN 镜像 ---
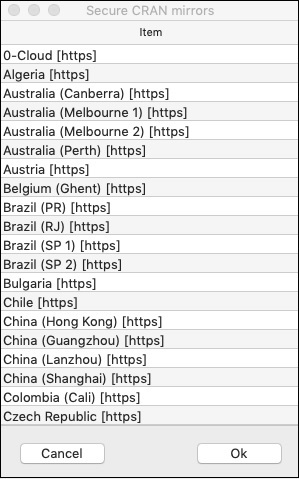
屏幕上将显示一个对话框,其中显示镜像站点列表。选择最近的位置或您选择的镜像。
测试安装
在 R 提示符下,键入并运行以下代码 −
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的输出将如以下屏幕截图所示 −
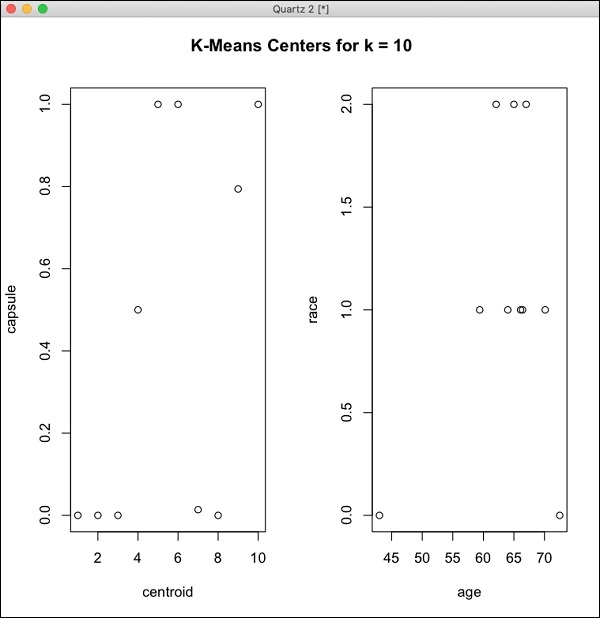
您在 R 中的 H2O 安装现已完成。
安装 Web GUI Flow
要安装 GUI Flow,请从 H20 站点下载安装文件。将下载的文件解压到您喜欢的文件夹中。请注意安装中存在 h2o.jar 文件。使用以下命令在命令窗口中运行此文件 −
$ java -jar h2o.jar
一段时间后,以下内容将出现在您的控制台窗口中。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: 在您的网络浏览器中打开 H2O Flow: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要启动 Flow,请在浏览器中打开给定的 URL http://localhost:54321。将出现以下屏幕 −
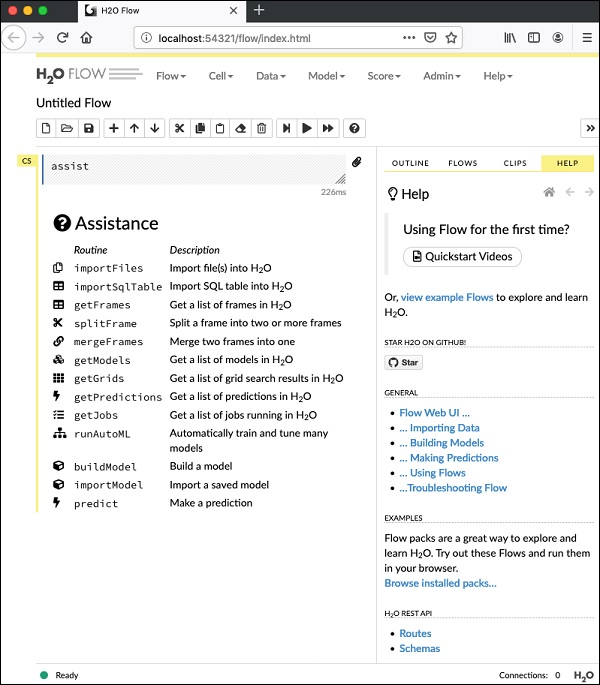
此时,您的 Flow 安装已完成。
在 Hadoop / Anaconda Cloud 上安装
除非您是经验丰富的开发人员,否则您不会考虑在大数据上使用 H2O。这里只需说 H2O 模型可以在几 TB 的大型数据库上高效运行。如果您的数据位于 Hadoop 安装中或云中,请按照 H2O 网站上给出的步骤将其安装到相应的数据库中。
现在您已成功安装并在机器上测试了 H2O,您可以进行真正的开发了。首先,我们将从命令提示符中看到开发。在后续课程中,我们将学习如何在 H2O Flow 中进行模型测试。
在命令提示符中开发
现在让我们考虑使用 H2O 对众所周知的鸢尾花数据集的植物进行分类,该数据集可免费用于开发机器学习应用程序。
通过在 shell 窗口中键入以下命令启动 Python 解释器 −
$ Python3
这将启动 Python 解释器。使用以下命令导入 h2o 平台 −
>>> import h2o
我们将使用随机森林算法进行分类。这是在 H2ORandomForestEstimator 包中提供的。我们使用 import 语句导入此包,如下所示 −
>>> from h2o.estimators import H2ORandomForestEstimator
我们通过调用其 init 方法来初始化 H2o 环境。
>>> h2o.init()
初始化成功后,您应该在控制台上看到以下消息以及集群信息。
检查 http://localhost:54321 上是否有正在运行的 H2O 实例。已连接。
现在,我们将使用 H2O 中的 import_file 方法导入虹膜数据。
>>> data = h2o.import_file('iris.csv')
进度将显示如下屏幕截图所示 −

将文件加载到内存中后,您可以通过显示加载表的前 10 行来验证这一点。您可以使用 head 方法执行此操作 −
>>> data.head()
您将看到以下表格格式的输出。
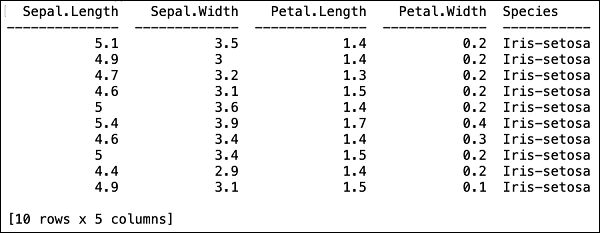
该表还显示列名。我们将使用前四列作为 ML 算法的特征,最后一列类作为预测输出。我们在调用 ML 算法时通过首先创建以下两个变量来指定这一点。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下来,我们通过调用 split_frame 方法将数据拆分为训练和测试。
>>> train, test = data.split_frame(ratios = [0.8])
数据按 80:20 的比例分割。我们使用 80% 的数据进行训练,20% 的数据进行测试。
现在,我们将内置的随机森林模型加载到系统中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上面的调用中,我们将树的数量设置为 50,将树的最大深度设置为 20,将交叉验证的折叠数设置为 10。我们现在需要训练模型。我们通过调用 train 方法来实现,如下所示 −
>>> model.train(x = features, y = output, training_frame = train)
train 方法接收我们之前创建的特征和输出作为前两个参数。训练数据集设置为 train,占我们完整数据集的 80%。在训练期间,您将看到进度,如下所示 −
现在,随着模型构建过程的结束,是时候测试模型了。我们通过在训练后的模型对象上调用 model_performance 方法来执行此操作。
>>> performance = model.model_performance(test_data=test)
在上面的方法调用中,我们发送了测试数据作为参数。
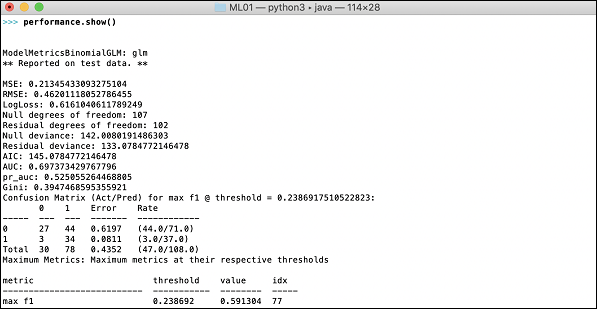
现在是时候查看输出,即我们模型的性能。您只需打印性能即可做到这一点。
>>> print (performance)
这将为您提供以下输出 −
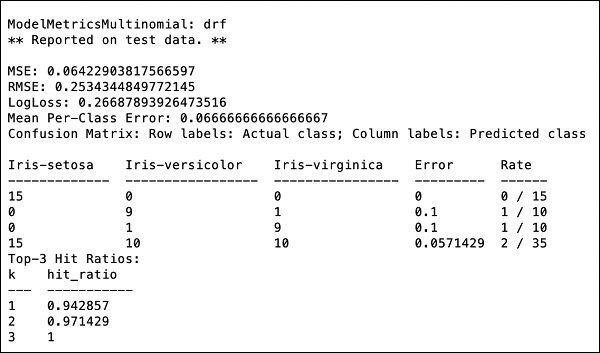
输出显示均方误差 (MSE)、均方根误差 (RMSE)、对数损失甚至混淆矩阵。
在 Jupyter 中运行
我们已经看到了命令的执行,也了解了每行代码的用途。您可以在 Jupyter 环境中逐行或一次运行整个程序来运行整个代码。完整列表在此处给出 −
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
运行代码并观察输出。现在,您可以体会到在数据集上应用和测试随机森林算法是多么容易。H20 的强大功能远不止于此。如果您想在同一数据集上尝试另一个模型,看看是否可以获得更好的性能,该怎么办?这将在我们后续部分中解释。
应用不同的算法
现在,我们将学习如何将梯度提升算法应用于我们之前的数据集,看看它的表现如何。在上面的完整列表中,您只需进行以下代码中突出显示的两处小更改 −
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (性能)
运行代码,您将获得以下输出 −
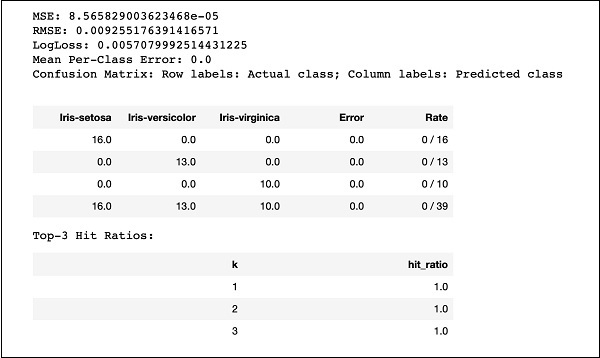
只需将 MSE、RMSE、混淆矩阵等结果与之前的输出进行比较,然后决定使用哪一个进行生产部署。事实上,您可以应用几种不同的算法来决定最适合您目的的算法。


