集中式系统中的查询优化
一旦导出用于计算关系代数表达式的替代访问路径,就可以确定最佳访问路径。 本章我们将研究集中式系统中的查询优化,下一章我们将研究分布式系统中的查询优化。
在集中式系统中,查询处理的目的如下 −
最小化查询响应时间(为用户查询生成结果所需的时间)。
最大化系统吞吐量(给定时间内处理的请求数)。
减少处理所需的内存和存储量。
增加并行性。
查询解析与转换
最初,扫描 SQL 查询。 然后对其进行解析以查找语法错误和数据类型的正确性。 如果查询通过了此步骤,则查询将被分解为更小的查询块。 然后将每个块转换为等效的关系代数表达式。
查询优化步骤
查询优化涉及三个步骤,即查询树生成、计划生成、查询计划代码生成。
步骤 1 − 查询树生成
查询树是表示关系代数表达式的树数据结构。 查询的表表示为叶节点。 关系代数运算表示为内部节点。 根代表整个查询。
在执行期间,只要内部节点的操作数表可用,就会执行内部节点。 然后该节点将被结果表替换。 此过程对所有内部节点持续进行,直到根节点被执行并被结果表替换。
例如,让我们考虑以下模式 −
EMPLOYEE(员工)
| EmpID | EName | Salary | DeptNo | DateOfJoining |
DEPARTMENT(部门)
| DNo | DName | Location |
示例 1
让我们考虑如下查询。
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
The corresponding query tree will be −
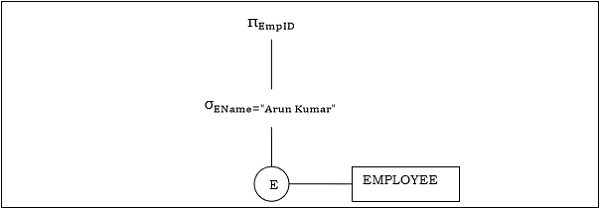
示例 2
让我们考虑另一个涉及连接的查询。
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
以下是上述查询的查询树。
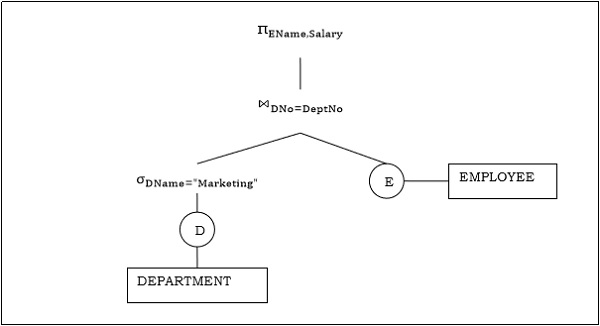
步骤 2 − 查询计划生成
生成查询树后,就制定了查询计划。 查询计划是一个扩展的查询树,其中包括查询树中所有操作的访问路径。 访问路径指定应如何执行树中的关系操作。 例如,选择操作可以有一个访问路径,该路径提供有关使用 B+ 树索引进行选择的详细信息。
此外,查询计划还规定了中间表应如何从一个运算符传递到下一个运算符、应如何使用临时表以及应如何管道化/组合操作。
步骤 3 − 代码生成
代码生成是查询优化的最后一步。 它是查询的可执行形式,其形式取决于底层操作系统的类型。 生成查询代码后,执行管理器就会运行它并生成结果。
查询优化方法
在查询优化方法中,最常用的是穷举搜索和启发式算法。
详尽的搜索优化
在这些技术中,对于查询,首先生成所有可能的查询计划,然后选择最佳计划。 尽管这些技术提供了最佳解决方案,但由于解决方案空间较大,因此其时间和空间复杂度呈指数级增长。 例如,动态规划技术。
基于启发式的优化
基于启发式的优化使用基于规则的优化方法来进行查询优化。 这些算法具有多项式时间和空间复杂度,低于基于穷举搜索的算法的指数复杂度。 然而,这些算法并不一定能产生最佳的查询计划。
一些常见的启发式规则是 −
在连接操作之前执行选择和项目操作。 这是通过将选择和项目操作移到查询树中来完成的。 这减少了可用于连接的元组数量。
首先执行最严格的选择/项目操作,然后再执行其他操作。
避免交叉积操作,因为它们会导致非常大的中间表。


