CatBoost - 过度拟合检测
过度拟合是用来描述模型在训练数据上表现良好但在未知数据上表现不佳的术语。CatBoost 提供了评估过度拟合的指标。
以下是一些常见的 CatBoost 指标来解释过度拟合保护 −
交叉验证
交叉验证是用于查找和降低过度拟合的最重要的机器学习方法之一。通过比较训练和验证性能,交叉验证有助于检测过度拟合。
此方法使用 Iris 数据集上的交叉验证来分析 CatBoostClassifier 模型的性能。使用交叉验证是一种常见的方法来阻止过度拟合,这是一种模型在新数据上执行的情况,因为它对训练数据进行了过度调整。此外,交叉验证提高了我们对模型实际性能的理解。为了确定模型的性能水平,它确定了许多措施。
# 导入所需的库
import numpy as np
from catboost import CatBoostClassifier, Pool, cv
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载所需的数据集
iris = load_iris()
X, y = iris.data, iris.target
# 生成 CatBoost Pool 对象
data_pool = Pool(X, label=y)
# 定义 CatBoostClassifier 参数
params = {
'iterations': 100,
'learning_rate': 0.1,
'depth': 6,
'loss_function': 'MultiClass',
'verbose': 0
}
# 进行交叉验证
cv_results = cv(pool=data_pool,
params=params,
fold_count=5,
shuffle=True,
partition_random_seed=42,
verbose_eval=False)
# 打印结果
for metric_name in cv_results.columns:
if 'test-' in metric_name:
mean_score = cv_results[metric_name].iloc[-1]
print(f'{metric_name}: {mean_score:.4f}')
输出
这将产生以下结果 −
Training on fold [0/5] bestTest = 0.1226007055 bestIteration = 72 Training on fold [1/5] bestTest = 0.09388296402 bestIteration = 99 Training on fold [2/5] bestTest = 0.05707644554 bestIteration = 99 Training on fold [3/5] bestTest = 0.1341533772 bestIteration = 93 Training on fold [4/5] bestTest = 0.19934632 bestIteration = 94 test-MultiClass-mean: 0.1221 test-MultiClass-std: 0.0531
特征重要性
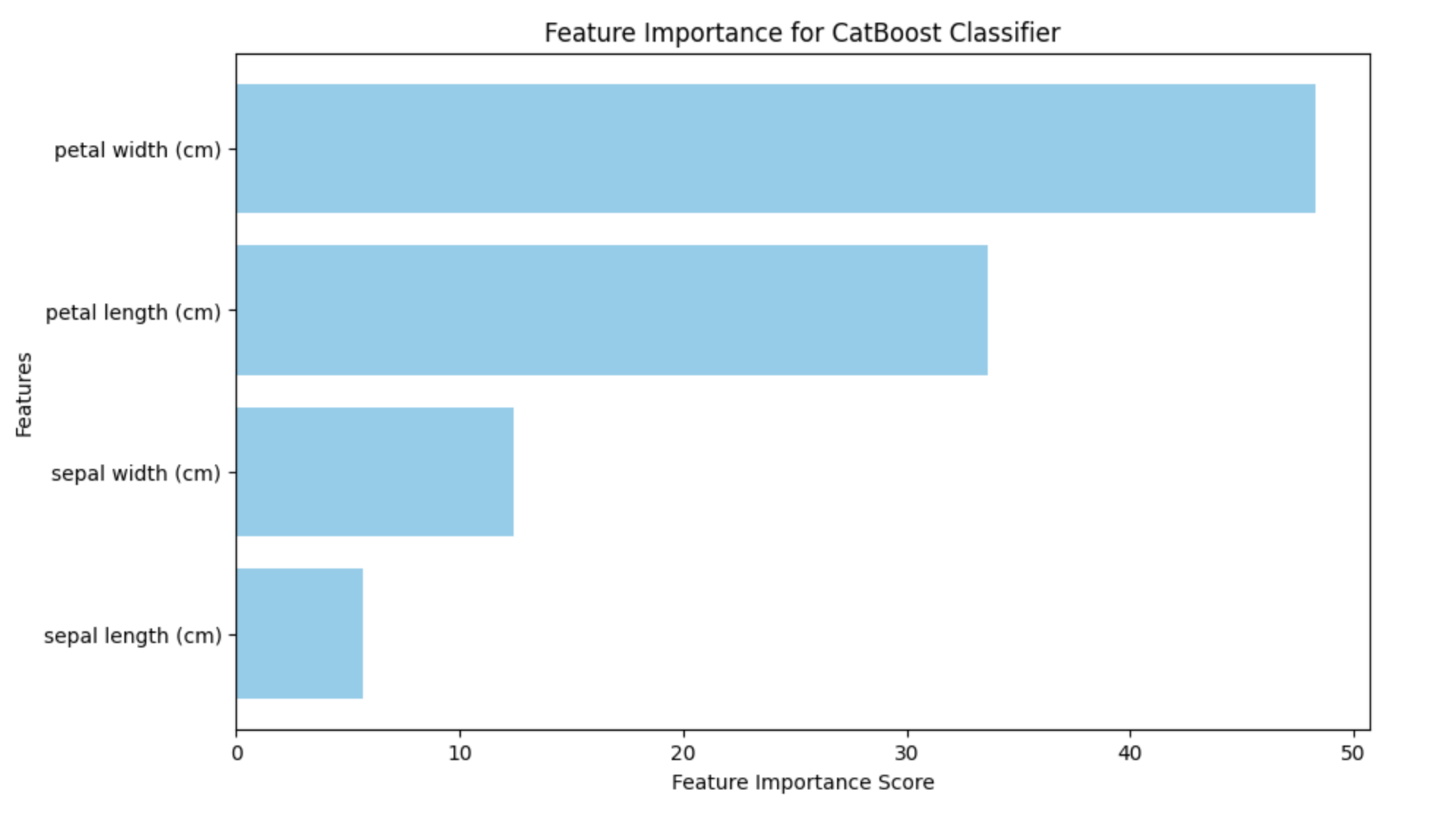
CatBoost 还提供特征重要性分数。它可用于确定特征的重要性和实用性以及它们如何影响模型的预测。使用特征重要性可以通过突出显示对模型预测有影响的变量来检测过度拟合。如果某个特征对模型的预测没有影响,则它可能会过度拟合模型。
生成的条形图将突出显示每个特征在模型预测中的重要性。借助这些数据,可以确定对分类过程最重要的特征,从而对工程或特征选择工作进行排名。
import numpy as np
import matplotlib.pyplot as plt
from catboost import CatBoostClassifier, Pool
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载 Iris 数据集
iris_dataset = load_iris()
X_data, y_labels = iris_dataset.data, iris_dataset.target
# 将数据拆分为训练集和测试集
X_train_data, X_test_data, y_train_labels, y_test_labels = train_test_split(X_data, y_labels, test_size=0.2, random_state=42)
# 创建一个CatBoostClassifier
catboost_model = CatBoostClassifier(iterations=100, learning_rate=0.1,depth=6,loss_function='MultiClass',verbose=0)
# 训练模型
catboost_model.fit(X_train_data,y_train_labels)
# 为测试数据创建一个 Pool 对象
test_data_pool = Pool(X_test_data)
# 获取特征重要性分数
feature_importance_scores = catboost_model.get_feature_importance(test_data_pool)
# 获取特征名称
feature_labels = iris_dataset.feature_names
# 绘制具有变化颜色的特征重要性
plt.figure(figsize=(10, 6))
plt.barh(range(len(feature_importance_scores)), feature_importance_scores, color='skyblue', tick_label=feature_labels)
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title('Feature Importance for CatBoost Classifier')
plt.show()
输出
这是使用上述代码生成的结果 −
识别过度拟合也在很大程度上取决于学习曲线。CatBoost 中没有不同的学习曲线绘图技术。但是,可以使用其他 Python 程序(如 matplotlib)绘制它。


