AVRO - 序列化
数据序列化有两个目的 −
用于持久存储
通过网络传输数据
什么是序列化?
序列化是将数据结构或对象状态转换为二进制或文本形式以通过网络传输数据或存储在某些持久存储中的过程。一旦数据通过网络传输或从持久存储中检索,就需要再次对其进行反序列化。序列化称为编组,反序列化称为解组。
Java 中的序列化
Java 提供了一种称为对象序列化的机制,其中对象可以表示为字节序列,其中包括对象的数据以及有关对象类型和存储在对象中的数据类型的信息。
将序列化对象写入文件后,可以从文件中读取并反序列化。也就是说,可以使用表示对象及其数据的类型信息和字节在内存中重新创建对象。
ObjectInputStream 和 ObjectOutputStream 类分别用于在 Java 中序列化和反序列化对象。
Hadoop 中的序列化
通常在像 Hadoop 这样的分布式系统中,序列化的概念用于进程间通信和持久存储。
进程间通信
为了在网络中连接的节点之间建立进程间通信,使用了 RPC 技术。
RPC 使用内部序列化将消息转换为二进制格式,然后通过网络将其发送到远程节点。在另一端,远程系统将二进制流反序列化为原始消息。
RPC 序列化格式要求如下 −
紧凑 − 充分利用网络带宽,而网络带宽是数据中心最稀缺的资源。
快速 − 由于节点之间的通信在分布式系统中至关重要,因此序列化和反序列化过程应该快速,从而减少开销。
可扩展 − 协议会随着时间的推移而发生变化以满足新的要求,因此应该可以直接以受控的方式为客户端和服务器改进协议。
可互操作 −消息格式应支持使用不同语言编写的节点。
持久存储
持久存储是一种数字存储设施,不会因断电而丢失数据。文件、文件夹、数据库是持久存储的示例。
可写接口
这是 Hadoop 中的接口,提供序列化和反序列化的方法。下表描述了这些方法−
| S.No. | 方法和说明 |
|---|---|
| 1 | void readFields(DataInput in) 此方法用于反序列化给定对象的字段。 |
| 2 | void write(DataOutput out) 此方法用于序列化给定对象的字段。 |
Writable Comparable 接口
它是 Writable 和 Comparable 接口的组合。此接口继承了 Hadoop 的 Writable 接口以及 Java 的 Comparable 接口。因此,它提供了数据序列化、反序列化和比较的方法。
| S.No. | 方法和说明 |
|---|---|
| 1 | int compareTo(class obj) 此方法将当前对象与给定对象 obj 进行比较。 |
除了这些类之外,Hadoop 还支持许多实现 WritableComparable 接口的包装器类。每个类都包装一个 Java 原始类型。 Hadoop 序列化的类层次结构如下所示 −
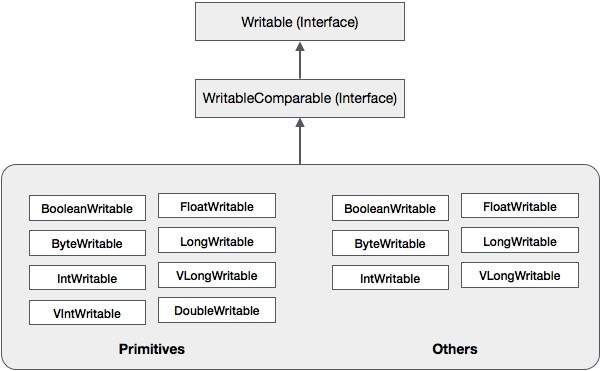
这些类可用于序列化 Hadoop 中的各种类型的数据。例如,让我们考虑 IntWritable 类。让我们看看如何使用此类序列化和反序列化 Hadoop 中的数据。
IntWritable 类
此类实现 Writable、Comparable 和 WritableComparable 接口。它在其中包装了一个整数数据类型。此类提供用于序列化和反序列化整数类型数据的方法。
构造函数
| S.No. | 摘要 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
方法
| S.No. | 摘要 |
|---|---|
| 1 | int get() 使用此方法,您可以获取当前对象。 |
| 2 | void readFields(DataInput in) 此方法用于反序列化给定的DataInput对象中的数据。 |
| 3 | void set(int value) 此方法用于设置当前IntWritable对象的值。 |
| 4 | void write(DataOutput out) 此方法用于将当前对象中的数据序列化到给定的DataOutput对象。 |
在 Hadoop 中序列化数据
下面讨论了序列化整数类型数据的过程。
通过将整数值包装在其中来实例化 IntWritable 类。
实例化 ByteArrayOutputStream 类。
实例化 DataOutputStream 类并将 ByteArrayOutputStream 类的对象传递给它。
使用 write() 方法序列化 IntWritable 对象中的整数值。此方法需要 DataOutputStream 类的对象。
序列化的数据将存储在字节数组对象中,该对象在实例化时作为参数传递给 DataOutputStream 类。将对象中的数据转换为字节数组。
示例
以下示例显示如何在 Hadoop 中序列化整数类型的数据 −
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//实例化 IntWritable 对象
IntWritable intwritable = new IntWritable(12);
//实例化 ByteArrayOutputStream 对象
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//实例化 DataOutputStream 对象
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//序列化数据
intwritable.write(dataOutputStream);
//将序列化的对象存储在字节数组中
byte[] byteArray = byteoutputStream.toByteArray();
//关闭 OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}
在 Hadoop 中反序列化数据
下面讨论了反序列化整数类型数据的过程 −
通过将整数值包装在其中来实例化 IntWritable 类。
实例化 ByteArrayOutputStream 类。
实例化 DataOutputStream 类并将 ByteArrayOutputStream 类的对象传递给它。
使用 IntWritable 类的 readFields() 方法反序列化 DataInputStream 对象中的数据。
反序列化的数据将存储在 IntWritable 类的对象中。您可以使用此类的 get() 方法检索此数据。
示例
以下示例显示如何在 Hadoop 中反序列化整数类型的数据 −
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//实例化 IntWritable 类
IntWritable intwritable =new IntWritable();
//实例化 ByteArrayInputStream 对象
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//实例化 DataInputStream 对象
DataInputStream datainputstream=new DataInputStream(InputStream);
//反序列化 DataInputStream 中的数据
intwritable.readFields(datainputstream);
//打印序列化的数据
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}
Hadoop 相对于 Java 序列化的优势
Hadoop 的基于 Writable 的序列化能够通过重用 Writable 对象来减少对象创建开销,而 Java 的本机序列化框架则无法做到这一点。
Hadoop 序列化的缺点
要序列化 Hadoop 数据,有两种方法 −
您可以使用 Hadoop 本机库提供的 Writable 类。
您还可以使用以二进制格式存储数据的 Sequence Files。
这两种机制的主要缺点是 Writables 和 SequenceFiles 只有 Java API,无法用任何其他语言写入或读取。
因此,任何文件使用上述两种机制在 Hadoop 中创建的数据无法被任何其他第三种语言读取,这使得 Hadoop 成为一个受限的盒子。为了解决这一缺陷,Doug Cutting 创建了 Avro,它是一种独立于语言的数据结构。


