TfLearn 及其在 TensorFlow 中的安装
TFlearn 是一个基于 TensorFlow 框架构建的开源深度学习库。它提供了一个高级 API,可以轻松创建和训练不同的神经网络模型。
它提供了一系列预先存在的模型,例如卷积神经网络 (CNN)、深度神经网络 (DNN) 和许多其他模型。它还包括各种激活函数,例如 ReLU(整流线性单元)、softmax,以及损失函数,例如分类交叉熵等。
TfLearn 是一个理想的初学者库,因为它不需要对 TensorFlow 中的神经网络 API 有广泛的了解。它是一个简单易用的库,我们可以定义输入、隐藏和输出层,而不必构建计算密集型网络架构(如 AlexNet 或 LeNet 架构)。
如何使用 TfLearn?
首先,检查系统中是否存在 Python。可以通过打印系统中存在的版本来检查。
python ---version
如果您的系统中没有安装 Python,您可以访问"python.org"网站安装 Python 3.8 或更高版本。
之后,检查系统中是否安装了 TensorFlow 模块。这可以通过执行
pip install tensorflow
在这种情况下,TensorFlow 已经安装。如果尚不存在,它将在您的系统中安装该模块。
此后,使用以下命令将 TfLearn 模块安装到您的系统中:
pip install tflearn

现在我们已经下载了所有先决条件,让我们看一个使用 TfLearn 的示例。
示例 1
在下面的程序中,MNIST 数据集用于训练和测试我们的模型。TfLearn 默认在其包中提供 MNIST 数据集。因此,我们可以利用这一点。
为了提高预测准确率,也为了让计算机理解图像,我们使用独热编码的概念来定义 [0,...,9] 中的类别。数据集实际上是手写数字的形式。
算法
导入所有库。
加载 MNIST 数据集并将值分配给 x_train、y_train、x_test 和 y_test,其中 x 表示值,y 表示数据集中的标签。
将 x_train 和 x_test 转换为浮点值,并通过除以 255 将其像素值转换为 0 或 1。
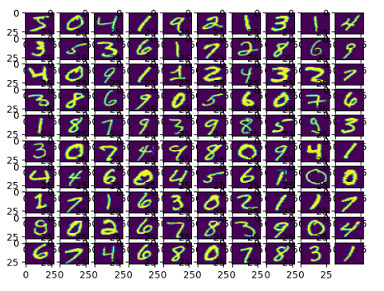
定义 10 个子图,并通过初始化 for 循环自动缩放其图像比例将图像打印到子图上。
打印图像。
import tflearn
from tflearn.datasets import mnist
import matplotlib.pyplot as plt
(x_train, y_train),(x_test,y_test)=mnist.load_data()
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
x_train, x_test=x_train/255.0, x_test/255.0
#显示数据集
fi,ax=plt.subplots(10,10)
k=0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28,28), aspect='auto')
k+=1
plt.show()
我们加载数据集并将其拆分为训练数据和测试数据。然后,我们将训练数据和测试数据的数据类型转换为 float32,并通过除以 255.0 对图像的像素值进行归一化,使其在 0 和 1 的范围内。
我们创建一个 10x10 的网格并初始化一个指针以跟踪图像索引。我们使用循环遍历网格。对于每个网格框,我们都会显示一张来自训练集的图像,该图像将图像从一维数组重塑为尺寸为 28x28 的二维数组。
输出
示例 2
在上一个示例中,我们加载了没有独热编码的 MNIST 数据。在下面的示例中,我们将在应用独热编码后打印训练和测试标签的形状,并打印训练标签的前五行。
算法
使用 tflearn 导入 MNIST 数据集。
使用独热编码值加载 MNIST 数据集。
打印数据集的形状和尺寸。
打印训练标签的前五行。
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
print("训练数据形状: ", x_train.shape)
print("训练标签形状: ", y_train.shape)
print("测试数据形状: ", x_train.shape)
print("测试标签形状: ", y_train.shape)
print("前 5 个训练标签: ")
print(y_train[:5])
在这里,我们加载包含数字手写图像的 MNIST 数据集。然后,我们将训练图像和标签分配给单独的变量,同样将测试图像和标签分配给单独的变量。
one_hot = true 参数确保标签以 one_hot 编码格式表示,该格式是二进制向量格式中所需数据的表示,其中一个元素固定为热(1),其余元素表示为冷(0)。并且,这里的热元素是所需的目标元素。
然后我们打印测试和训练数据(图像和标签)。
输出

构建神经网络模型
现在我们已经知道了我们正在处理什么,让我们构建我们的神经网络模型。神经网络由 3 层组成,即 −
输入层
隐藏层
输出层
示例 3
为了在我们的神经网络中构建这些层,我们使用 TfLearn 模块。
我们定义神经网络,其中隐藏层有 256 层,激活函数为 ReLU,输出层由 10 层和激活函数 softmax 组成。在大多数神经网络架构中,输出层始终具有 softmax 激活函数。
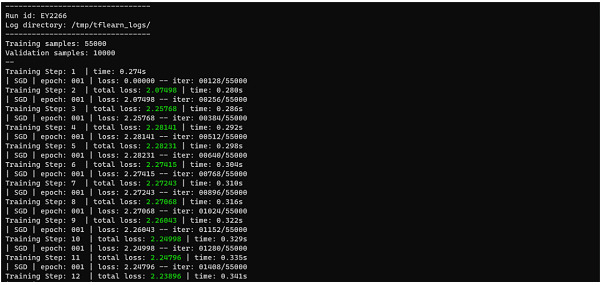
然后,我们使用 SGD(随机梯度下降)优化器和分类交叉熵损失函数以及 0.1 的学习率来定义模型。利用这些,我们构建了我们的模型,并将其与我们的训练数据和测试数据进行拟合,然后打印出模型的准确率。
算法
导入所有库。
加载 MNIST 数据集并将值分配给 x_train、y_train、x_test 和 y_test,其中 x 表示值,y 表示数据集中的标签。
导入数据集时设置 one_hot=True。
打印所有变量的形状。
将输入层定义为 [None,784]。
对于隐藏层,将输入层与 ReLU 激活函数一起等同于 256 层。
对于输出层,添加 10 层以及 softmax 激活函数。
使用必要的优化器和损失函数编译模型并打印准确度。
import tflearn
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
print("Training Data shape: ", x_train.shape)
print("Training Labels shape: ", y_train.shape)
print("Testing Data shape: ", x_train.shape)
print("Testing Labels shape: ", y_train.shape)
print("First 5 training labels: ")
print(y_train[:5])
i_layer=tflearn.input_data(shape=[None,784])
h_layer=tflearn.fully_connected(i_layer, 256, activation='relu')
o_layer=tflearn.fully_connected(h_layer, 10, activation='softmax')
net=tflearn.regression(o_layer, optimizer='sgd', learning_rate=0.1,
loss='categorical_crossentropy')
model=tflearn.DNN(net)
model.fit(x_train, y_train, validation_set=(x_test,y_test),
n_epoch=20, batch_size=128)
acc=model.evaluate(x_test,y_test)
print("Accuracy: ", acc)
我们通过从 MNIST 加载数据集将数据分为训练数据和测试数据。然后,我们将独热编码格式应用于标签。然后,我们定义神经网络的架构并设置网络的训练参数,如学习率、损失函数等。
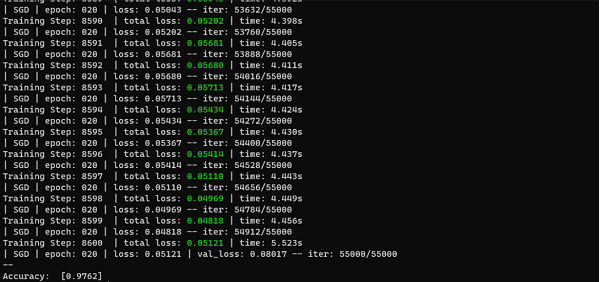
然后,我们在训练数据上对模型进行 20 个时期的训练,并在训练期间验证模型在测试数据上的性能。然后,我们在测试数据上评估训练后的模型并计算准确率。
输出
示例 4
在上面的例子中,我们可以看到准确率为 97.5%,这已经很不错了。这样,我们可以通过改变优化器和损失函数来微调模型的准确率。在此示例中,我们看到使用 Adam 优化器。
算法
导入所有库。
加载 MNIST 数据集并将值分配给 x_train、y_train、x_test 和 y_test,其中 x 表示值,y 表示数据集中的标签。
导入数据集时设置 one_hot=True。
打印所有变量的形状。
将输入层定义为 [None,784]。
对于隐藏层,将输入层与 ReLU 激活函数一起等同于 256 层。
对于输出层,添加 10 层以及 softmax 激活函数。
使用必要的优化器和损失函数编译模型并打印准确率。
import tflearn
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
i_layer=tflearn.input_data(shape=[None,784])
h_layer=tflearn.fully_connected(i_layer, 256, activation='relu')
o_layer=tflearn.fully_connected(h_layer, 10, activation='softmax')
net=tflearn.regression(o_layer, optimizer='adam', learning_rate=0.1,
loss='categorical_crossentropy')
model=tflearn.DNN(net)
model.fit(x_train, y_train, validation_set=(x_test,y_test),
n_epoch=20, batch_size=128)
acc=model.evaluate(x_test,y_test)
输出
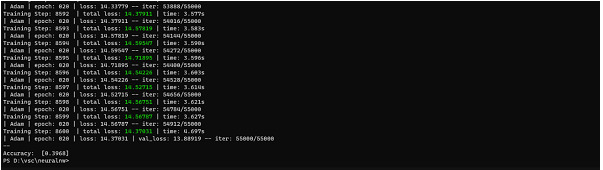
如图所示,这对于模型来说非常低,因此我们使用 SGD 优化器来实现我们的目的。
结论
如上所示,TfLearn 是一个非常简单且易于理解的库,用于构建深度学习模型。但是,由于它是一个非常简单的库,它不支持像 TensorFlow 或 PyTorch 提供的库那样多的激活函数或损失函数。与上面提到的库相比,它在模型定制方面也明显不足。
该库在计算机视觉中用于借助卷积神经网络完成图像分割、对象检测等任务,并在教育和研究中用于在教育环境中构建和教授算法。


