如何使用 Pandas 读取 csv 文件时跳过行
Python 有一个内置方法 read_csv,可用于在使用 Pandas 读取 csv 文件时设置跳过行。CSV 代表逗号分隔值,是包含数据库的文件的扩展名。此技术可用于任何涉及从 CSV 文件读取和处理数据的应用程序。各种应用程序都使用数据过滤、excel 工具等。
语法
示例中使用了以下语法 -
read_csv('file_name.csv', skiprows= 根据用户选择设置条件)
这是 pandas 模块的内置函数,可以读取 CSV 文件的数据。它接受两个参数 -
filename.csv - csv 是文件扩展名的简单表示。
skiprows - 此参数允许用户根据跳过/删除行设置条件。
示例 1
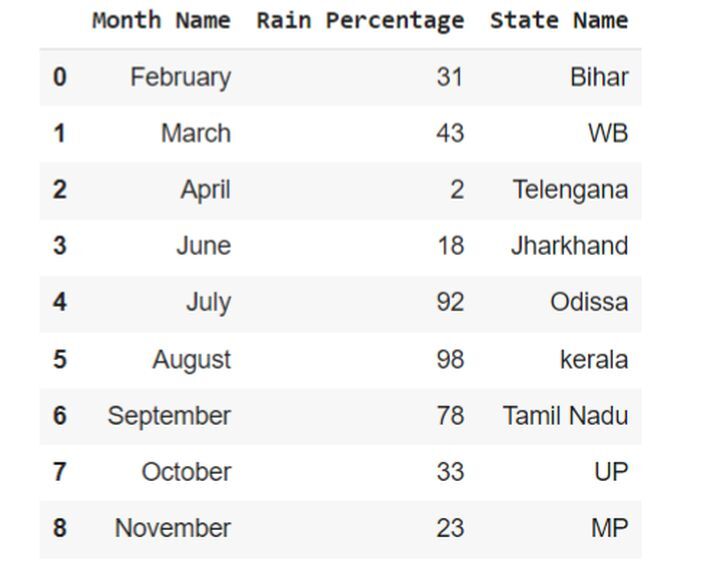
在下面的示例中,我们将通过导入名为 pandas 的模块并将引用对象作为 pd 来启动程序。然后初始化名为 df 的变量,该变量通过内置方法 read_csv() 存储值,该方法接受两个参数 - demo.csv(文件的名称)和 skiprows(设置特定索引行)。skiprows 使用列表推导来设置行。最后,我们只使用变量 df 以表格形式获取数据。
#跳过多行
import pandas as pd
df = pd.read_csv('demo.csv',skiprows=[1,5,12])
df
输出
示例 2
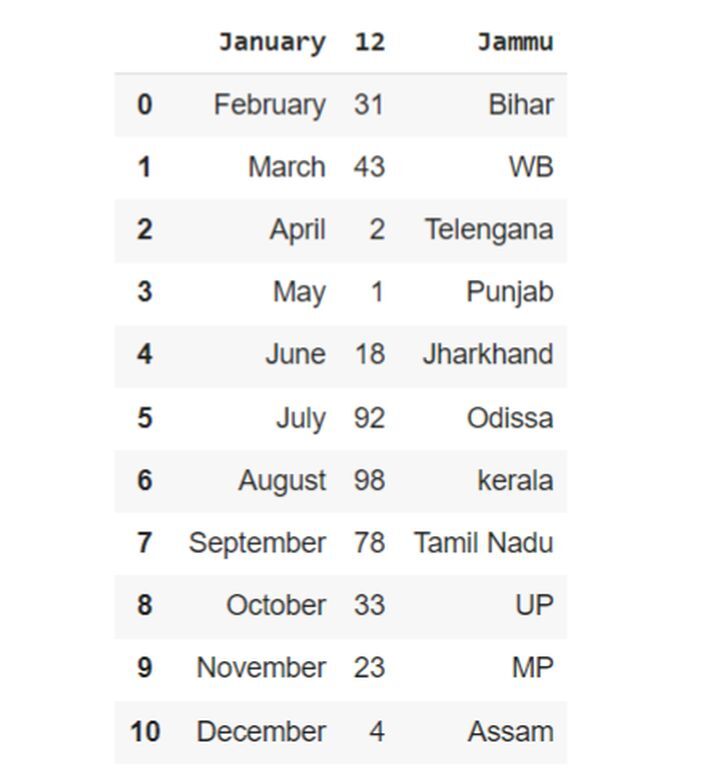
在下面的示例中,我们将展示如何从数据中跳过一行。首先,导入 pandas 模块,该模块有助于设置读取数据的操作。将 pd 作为将用于分配 read_csv 的对象引用。通过使用此内置函数,它接受两个参数 - 'demo.csv'(文件名)和 skiprows(设置为值 1,从表中删除第一行)。
#skip only single rows
import pandas as pd
df = pd.read_csv('demo.csv',skiprows=1)
df
输出
示例 3
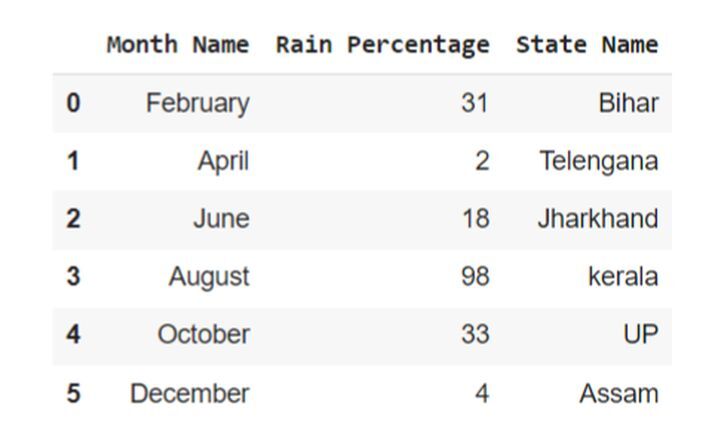
在下面的示例中,我们将首先导入可用于处理其名为 pd 的对象引用的 pandas 模块。接下来,我们将使用 pd 将值存储为内置方法 read_csv,该方法接受两个参数 - 'demo.csv'(文件名)和 skiprows(设置偶数条件的值)。最后,使用变量 df 获取输出。
# 根据偶数条件跳过行
import pandas as pd
df = pd.read_csv('demo.csv', skiprows=lambda x:x%2!=0)
# 按偶数顺序打印月份
df
输出
示例 4
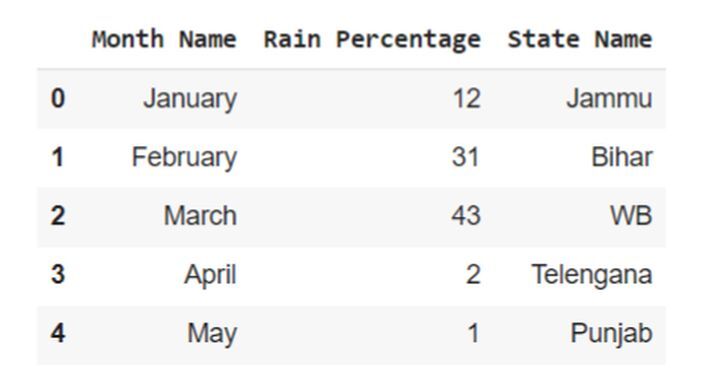
在下面的示例中,通过导入名为 pandas 的模块来开始程序。然后使用内置方法 read_csv 设置两个参数 - 'demo.csv'(文件名)和 skiprows(将值设置为 lamda x:x>5,仅设置前五行)。接下来使用变量df获取5行数据。
# 根据某些行跳过行
import pandas as pd
df = pd.read_csv('demo.csv', skiprows= lambda x:x>5)
df
输出
示例5
在下面的示例中,程序从pandas模块开始,并将对象引用设置为pd。然后使用内置方法初始化存储值的名为 df 的变量,它接受三个参数 - 'demo.csv'(文件的名称)、skiprows(在列表中设置值整数 2 和 10 以从表中删除数据)和 nrows(将值设置为 10,这意味着只有 10 行可用)。
import pandas as pd
df = pd.read_csv('demo.csv', skiprows=[2,10],nrows=10)
df
输出
结论
我们通过对 skiprows 概念应用各种条件进行了讨论。我们使用 skiprows 条件跳过单行、跳过多行、基于偶数条件跳过行、基于特定条件跳过行以及跳过 CSV 文件中的特定行。


