在 Pandas Dataframe 中用红色突出显示负值,用黑色突出显示正值
分析数据是任何数据科学或分析任务的基本方面,数据探索期间的一个常见要求是快速识别 Pandas Dataframe 中的负值和正值,以便进行有效解释。
在本文中,我们将探索一种强大的技术,使用 Python 中的 Pandas 库在 DataFrame 中以红色突出显示负值,以黑色突出显示正值。通过采用这种方法,数据分析师和研究人员可以有效地区分正趋势和负趋势,从而有助于进行有洞察力的数据解释和决策。
如何在 Pandas Dataframe 中用红色突出显示负值,用黑色突出显示正值?
有几种方法可以在 Pandas DataFrame 中用红色突出显示负值,用黑色突出显示正值。这里介绍三种常用技巧
方法一:使用 Styler 和 Styler.applymap()
Pandas 中的 Styler 类允许我们将格式应用于 DataFrame 元素。我们可以定义一个格式化函数,检查每个值的符号并返回适当的 CSS 样式。然后,我们可以使用 Styler.applymap() 方法将此函数应用于 DataFrame 的每个元素。
方法二:使用 Styler 和 Styler.background_gradient()
Styler.background_gradient() 方法根据值将渐变色图应用于 DataFrame。我们可以指定颜色范围,例如从红色到黑色,并将中点设置为零。此方法将自动分配颜色,负值显示为红色,正值显示为黑色。
方法 3:使用 numpy.where()
我们可以使用 numpy.where() 函数创建一个新的 DataFrame,其中的值将根据其符号替换为颜色代码。我们可以将红色分配给负值,将黑色分配给正值。然后,我们可以用所需的颜色格式显示 DataFrame。
我们将使用一个程序示例来理解这些方法,但首先,让我们看看我们将遵循的步骤
导入必要的库 −
导入 Pandas 以使用 DataFrames。
导入 numpy 以处理数值计算。
定义格式化函数 −
highlight_values 函数将值作为输入并返回用于格式化的 CSS 样式属性。它会检查值是否小于零并返回"color: red",否则返回"color: black"。
gradient_color 函数将数据系列作为输入并使用该系列的绝对值计算最大值 (norm)。然后,它会返回该系列中每个元素的 CSS 背景颜色样式列表,为负值分配"red",为正值分配"black"。
where_color 函数使用 numpy.where() 创建一个新 DataFrame,其中的值将根据其符号替换为颜色代码。它为负值分配"color: red",为正值分配"color: black"。
创建一个示例 DataFrame −
该程序创建一个带有一些数值的示例 DataFrame df。
应用格式化方法 −
方法 1:使用 Styler 和 Styler.applymap()−
使用 df.style 设置 DataFrame df 的样式。
将 applymap() 方法应用于已设置样式的 DataFrame,并将 highlight_values 函数作为参数传递。
生成的已设置样式的DataFrame 保存为名为 highlighted_values_method1.xlsx.
的 Excel 文件。
方法 2:使用 Styler 和 Styler.background_gradient() −
使用 df.style.
设置 DataFrame df 的样式。
将 apply() 方法应用于设置样式的 DataFrame,并将 gradient_color 函数作为参数传递。
生成的设置样式的 DataFrame 保存为名为 highlighted_values_method2.xlsx.
的 Excel 文件。
方法 3:使用 numpy.where() −
DataFrame df 使用 df.style 进行样式化。
将 apply() 方法应用于样式化的 DataFrame,并将 where_color 函数作为参数传递。
生成的样式化的 DataFrame 保存为名为 highlighted_values_method3.xlsx 的 Excel 文件。
示例
import pandas as pd
import numpy as np
# 方法 1:使用 Styler 和 Styler.applymap()
def highlight_values(x):
if x < 0:
return 'color: red'
else:
return 'color: black'
# 方法 2:使用 Styler 和 Styler.background_gradient()
def gradient_color(data):
norm = abs(data.values).max()
return ['background-color: {0}'.format('red' if x < 0 else 'black') for x in data]
# 方法 3: :使用 numpy.where()
def where_color(df):
return np.where(df < 0, 'color: red', 'color: black')
# 创建示例 DataFrame
data = {'A': [-2, 4, -1, 5, 0],
'B': [3, -6, 2, 7, -4],
'C': [-3, -2, 1, 6, -5]}
df = pd.DataFrame(data)
# 方法 1:使用 Styler 和 Styler.applymap()
styled_df = df.style.applymap(highlight_values)
styled_df.to_excel('highlighted_values_method1.xlsx', engine='openpyxl', index=False)
# 方法 2:使用 Styler 和 Styler.background_gradient()
styled_df = df.style.apply(gradient_color)
styled_df.to_excel('highlighted_values_method2.xlsx', engine='openpyxl', index=False)
# 方法 3:使用 numpy.where()
styled_df = df.style.apply(where_color)
styled_df.to_excel('highlighted_values_method3.xlsx', engine='openpyxl', index=False)
输出
highlighted_values_method1.xlsx −
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
'highlighted_values_method2.xlsx −
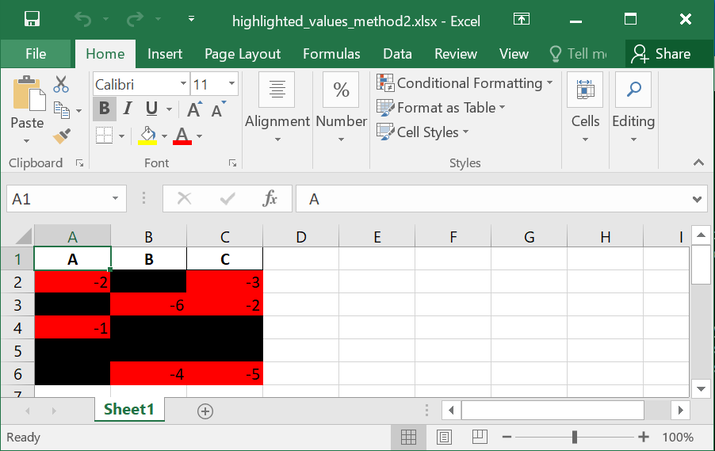
highlighted_values_method3.xlsx −
A B C -2 3 -3 4 -6 -2 -1 2 1 5 7 6 0 -4 -5
结论
总之,使用 Pandas 中的各种技术,例如 Styler 类和 numpy.where(),我们可以轻松地在 DataFrame 中用红色突出显示负值,用黑色突出显示正值。这些方法提供了有效的方法来直观地解释数据并识别趋势或异常。


